
DR : Reduza o código padrão para construir, treinar e servir modelos do TensorFlow Ranking com TensorFlow Ranking Pipelines; Use estratégias distribuídas adequadas para aplicações de classificação em grande escala, de acordo com o caso de uso e os recursos.
Introdução
O TensorFlow Ranking Pipeline consiste em uma série de processos de processamento de dados, criação de modelos, treinamento e atendimento que permitem construir, treinar e fornecer modelos de classificação escalonáveis baseados em redes neurais a partir de registros de dados com esforço mínimo. O pipeline é mais eficiente quando o sistema é ampliado. Em geral, se o seu modelo levar 10 minutos ou mais para ser executado em uma única máquina, considere usar esta estrutura de pipeline para distribuir a carga e acelerar o processamento.
O TensorFlow Ranking Pipeline tem sido executado de forma constante e estável em experimentos e produções em grande escala com big data (terabytes+) e grandes modelos (100 milhões+ de FLOPs) em sistemas distribuídos (1K+ CPU e mais de 100 GPU e TPUs). Depois que um modelo do TensorFlow é comprovado com model.fit em uma pequena parte dos dados, o pipeline é recomendado para verificação de hiperparâmetros, treinamento contínuo e outras situações de grande escala.
Pipeline de classificação
No TensorFlow, um pipeline típico para criar, treinar e fornecer um modelo de classificação inclui as etapas típicas a seguir.
- Defina a estrutura do modelo:
- Criar insumos;
- Crie camadas de pré-processamento;
- Criar arquitetura de rede neural;
- Modelo de trem:
- Gere conjuntos de dados de treinamento e validação a partir de logs de dados;
- Prepare o modelo com hiperparâmetros adequados:
- Otimizador;
- Perdas de classificação;
- Métricas de Classificação;
- Configure estratégias distribuídas para treinar em vários dispositivos.
- Configure retornos de chamada para diversas escriturações contábeis.
- Modelo de exportação para atendimento;
- Modelo de serviço:
- Determine o formato dos dados na veiculação;
- Escolha e carregue o modelo treinado;
- Processo com modelo carregado.
Um dos principais objetivos do pipeline do TensorFlow Ranking é reduzir o código clichê nas etapas, como carregamento e pré-processamento do conjunto de dados, compatibilidade de dados listwise e função de pontuação pontual e exportação de modelo. O outro objetivo importante é impor o design consistente de muitos processos inerentemente correlacionados, por exemplo, as entradas do modelo devem ser compatíveis com os conjuntos de dados de treinamento e com o formato dos dados no serviço.
Guia de uso
Com todo o design acima, o lançamento de um modelo de classificação TF se enquadra nas etapas a seguir, conforme mostrado na Figura 1.
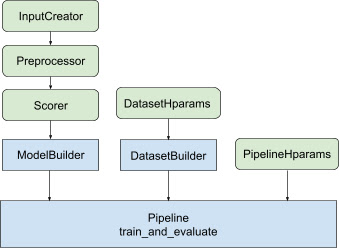
Exemplo usando uma rede neural distribuída
Neste exemplo, você aproveitará os recursos integrados tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder e tfr.keras.pipeline.SimplePipeline que utilizam feature_spec s para definir consistentemente os recursos de entrada nas entradas do modelo e servidor de conjunto de dados. A versão em notebook com passo a passo pode ser encontrada no tutorial de classificação distribuída .
Primeiro defina feature_spec s para recursos de contexto e de exemplo.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Siga as etapas ilustradas na Figura 1:
Defina input_creator de feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Em seguida, defina transformações de recursos de pré-processamento para o mesmo conjunto de recursos de entrada.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Defina o marcador com modelo DNN feedforward integrado.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Faça o model_builder com input_creator , preprocessor e scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Agora defina os hiperparâmetros para dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Faça o dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Defina também os hiperparâmetros para o pipeline.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Faça o ranking_pipeline e treine.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Projeto do pipeline de classificação do TensorFlow
O TensorFlow Ranking Pipeline ajuda a economizar tempo de engenharia com código padrão e, ao mesmo tempo, permite flexibilidade de personalização por meio de substituição e subclasse. Para conseguir isso, o pipeline introduz classes personalizáveis tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder e tfr.keras.pipeline.AbstractPipeline para configurar o pipeline do TensorFlow Ranking.

Construtor de Modelo
O código padrão relacionado à construção do modelo Keras é integrado no AbstractModelBuilder , que é passado para o AbstractPipeline e chamado dentro do pipeline para construir o modelo no escopo da estratégia. Isso é mostrado na Figura 1. Os métodos de classe são definidos na classe base abstrata.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Você pode subclassificar diretamente o AbstractModelBuilder e sobrescrever com os métodos concretos para personalização, como
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Ao mesmo tempo, você deve usar ModelBuilder com recursos de entrada, transformações de pré-processamento e funções de pontuação especificadas como entradas de função input_creator , preprocessor e scorer na classe init em vez de subclassificar.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Para reduzir os padrões de criação dessas entradas, são fornecidas as classes de função tfr.keras.model.InputCreator para input_creator , tfr.keras.model.Preprocessor para preprocessor e tfr.keras.model.Scorer para scorer , juntamente com subclasses concretas tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer e tfr.keras.model.GAMScorer . Eles devem cobrir a maioria dos casos de uso comuns.
Observe que essas classes de função são classes Keras, portanto não há necessidade de serialização. A subclasse é a forma recomendada para personalizá-los.
Construtor de conjunto de dados
A classe DatasetBuilder coleta padrões relacionados ao conjunto de dados. Os dados são passados para o Pipeline e chamados para servir os conjuntos de dados de treinamento e validação e para definir as assinaturas de serviço para modelos salvos. Conforme mostrado na Figura 1, os métodos DatasetBuilder são definidos na classe base tfr.keras.pipeline.AbstractDatasetBuilder ,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
Em uma classe DatasetBuilder concreta, você deve implementar build_train_datasets , build_valid_datasets e build_signatures .
Uma classe concreta que cria conjuntos de dados a partir de feature_spec s também é fornecida:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
Os hparams usados no DatasetBuilder são especificados na classe de dados tfr.keras.pipeline.DatasetHparams .
Gasoduto
O Ranking Pipeline é baseado na classe tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Uma classe de pipeline concreta que treina o modelo com diferentes tf.distribute.strategy s compatíveis com model.fit também é fornecida:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
Os hparams usados no tfr.keras.pipeline.ModelFitPipeline são especificados na classe de dados tfr.keras.pipeline.PipelineHparams . Esta classe ModelFitPipeline é suficiente para a maioria dos casos de uso do TF Ranking. Os clientes podem facilmente subclassificá-lo para fins específicos.
Suporte à estratégia distribuída
Consulte o treinamento distribuído para obter uma introdução detalhada das estratégias distribuídas suportadas pelo TensorFlow. Atualmente, o pipeline do TensorFlow Ranking oferece suporte tf.distribute.MirroredStrategy (padrão), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy e tf.distribute.ParameterServerStrategy . A estratégia espelhada é compatível com a maioria dos sistemas de máquina única. Defina strategy como None para nenhuma estratégia distribuída.
Em geral, MirroredStrategy funciona para modelos relativamente pequenos na maioria dos dispositivos com opções de CPU e GPU. MultiWorkerMirroredStrategy funciona para grandes modelos que não cabem em um trabalhador. ParameterServerStrategy faz treinamento assíncrono e requer vários trabalhadores disponíveis. TPUStrategy é ideal para grandes modelos e big data quando TPUs estão disponíveis, no entanto, é menos flexível em termos de formatos de tensor que pode manipular.
Perguntas frequentes
O conjunto mínimo de componentes para usar o
RankingPipeline
Veja o código de exemplo acima.E se eu tiver meu próprio
modelKeras
Para ser treinado com estratégiastf.distribute,modelprecisa ser construído com todas as variáveis treináveis definidas em strategy.scope(). Então envolva seu modelo noModelBuildercomo,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Em seguida, alimente este model_builder ao pipeline para treinamento adicional.