
TL; DR : Zredukuj standardowy kod, aby budować, szkolić i obsługiwać modele rankingowe TensorFlow za pomocą potoków rankingowych TensorFlow; Stosuj odpowiednie strategie rozproszone w przypadku aplikacji rankingowych na dużą skalę, biorąc pod uwagę przypadek użycia i zasoby.
Wstęp
Potok rankingowy TensorFlow składa się z szeregu procesów przetwarzania danych, budowania modeli, uczenia i obsługi, które umożliwiają konstruowanie, trenowanie i udostępnianie skalowalnych modeli rankingowych opartych na sieci neuronowej na podstawie dzienników danych przy minimalnym wysiłku. Potok jest najbardziej wydajny, gdy system jest skalowany w górę. Ogólnie rzecz biorąc, jeśli uruchomienie modelu na jednej maszynie zajmuje co najmniej 10 minut, rozważ użycie tej struktury potoku w celu rozłożenia obciążenia i przyspieszenia przetwarzania.
Potok rankingowy TensorFlow był stale i stabilnie stosowany w eksperymentach i produkcjach na dużą skalę z dużymi zbiorami danych (+ terabajty) i dużymi modelami (ponad 100 mln FLOP) w systemach rozproszonych (ponad 1 tys. procesorów i ponad 100 procesorów graficznych i TPU). Po sprawdzeniu modelu TensorFlow za pomocą model.fit na małej części danych, potok jest zalecany do skanowania hiperparametrowego, ciągłego szkolenia i innych sytuacji na dużą skalę.
Rurociąg rankingowy
W TensorFlow typowy potok tworzenia, uczenia i obsługi modelu rankingowego obejmuje następujące typowe kroki.
- Zdefiniuj strukturę modelu:
- Utwórz dane wejściowe;
- Twórz warstwy wstępnego przetwarzania;
- Tworzenie architektury sieci neuronowej;
- Model pociągu:
- Generowanie zbiorów danych dotyczących pociągów i walidacji na podstawie dzienników danych;
- Przygotuj model z odpowiednimi hiperparametrami:
- Optymalizator;
- Straty rankingowe;
- Metryki rankingowe;
- Skonfiguruj rozproszone strategie , aby trenować na wielu urządzeniach.
- Skonfiguruj wywołania zwrotne dla różnych księgowości.
- Eksportuj model do serwowania;
- Podaj model:
- Określ format danych podczas udostępniania;
- Wybierz i załaduj przeszkolony model;
- Proces z załadowanym modelem.
Jednym z głównych celów potoku rankingu TensorFlow jest ograniczenie standardowego kodu w etapach, takich jak ładowanie i wstępne przetwarzanie zestawu danych, zgodność danych listowych i funkcji punktowej punktacji oraz eksport modelu. Innym ważnym celem jest wymuszenie spójnego projektu wielu nieodłącznie skorelowanych procesów, np. dane wejściowe modelu muszą być kompatybilne zarówno ze zbiorami danych szkoleniowych, jak i formatem danych w momencie udostępniania.
Skorzystaj z Przewodnika
W przypadku całego powyższego projektu uruchomienie modelu rankingu TF składa się z następujących kroków, jak pokazano na rysunku 1.
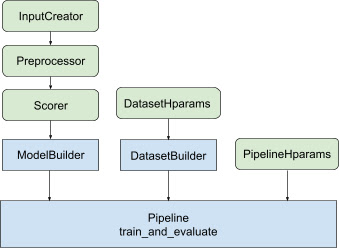
Przykład wykorzystania rozproszonej sieci neuronowej
W tym przykładzie wykorzystasz wbudowane funkcje tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder i tfr.keras.pipeline.SimplePipeline , które pobierają feature_spec w celu spójnego definiowania funkcji wejściowych w danych wejściowych modelu i serwer zbioru danych. Wersję notatkową z instrukcją krok po kroku znajdziesz w samouczku dotyczącym rankingu rozproszonego .
Najpierw zdefiniuj feature_spec zarówno dla funkcji kontekstowych, jak i przykładowych.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Postępuj zgodnie z krokami przedstawionymi na rysunku 1:
Zdefiniuj input_creator z feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Następnie zdefiniuj transformacje cech przetwarzania wstępnego dla tego samego zestawu cech wejściowych.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Zdefiniuj strzelca dzięki wbudowanemu modelowi DNN z wyprzedzeniem.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Utwórz model_builder z input_creator , preprocessor i scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Teraz ustaw hiperparametry dla dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Utwórz plik dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Ustaw także hiperparametry potoku.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Utwórz ranking_pipeline i trenuj.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Projekt rurociągu rankingowego TensorFlow
Potok rankingowy TensorFlow pomaga zaoszczędzić czas inżynierii dzięki standardowemu kodowi, a jednocześnie umożliwia elastyczność dostosowywania poprzez zastępowanie i podklasowanie. Aby to osiągnąć, potok wprowadza konfigurowalne klasy tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder i tfr.keras.pipeline.AbstractPipeline w celu skonfigurowania potoku rankingu TensorFlow.

Konstruktor Modeli
Kod standardowy związany z konstruowaniem modelu Keras jest zintegrowany w AbstractModelBuilder , który jest przekazywany do AbstractPipeline i wywoływany wewnątrz potoku w celu zbudowania modelu w zakresie strategii. Pokazano to na rysunku 1. Metody klas są zdefiniowane w abstrakcyjnej klasie bazowej.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Możesz bezpośrednio podklasować AbstractModelBuilder i zastąpić go konkretnymi metodami dostosowywania, takimi jak
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Jednocześnie powinieneś używać ModelBuilder z funkcjami wejściowymi, transformacjami przetwarzania wstępnego i funkcjami oceniania określonymi jako wejścia funkcji input_creator , preprocessor i scorer w init klasy zamiast podklasy.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Aby ograniczyć schematy tworzenia tych danych wejściowych, zapewniono klasy funkcyjne tfr.keras.model.InputCreator dla input_creator , tfr.keras.model.Preprocessor dla preprocessor i tfr.keras.model.Scorer dla scorer wraz z konkretnymi podklasami tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer i tfr.keras.model.GAMScorer . Powinny one obejmować większość typowych przypadków użycia.
Należy pamiętać, że te klasy funkcji są klasami Keras, więc nie ma potrzeby serializacji. Zalecanym sposobem ich dostosowywania jest podklasa.
Konstruktor zbioru danych
Klasa DatasetBuilder zbiera szablony powiązane ze zbiorem danych. Dane są przekazywane do Pipeline i wywoływane w celu obsługi zestawów danych szkoleniowych i walidacyjnych oraz w celu zdefiniowania podpisów obsługujących dla zapisanych modeli. Jak pokazano na rysunku 1, metody DatasetBuilder są zdefiniowane w klasie bazowej tfr.keras.pipeline.AbstractDatasetBuilder ,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
W konkretnej klasie DatasetBuilder należy zaimplementować build_train_datasets , build_valid_datasets i build_signatures .
Dostępna jest również konkretna klasa, która tworzy zestawy danych z feature_spec s:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
hparams używane w DatasetBuilder są określone w klasie danych tfr.keras.pipeline.DatasetHparams .
Rurociąg
Ranking Pipeline bazuje na klasie tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Dostępna jest również klasa konkretnego potoku, która uczy model za pomocą różnych strategii tf.distribute.strategy zgodnych z model.fit :
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
hparams używane w klasie tfr.keras.pipeline.ModelFitPipeline są określone w klasie danych tfr.keras.pipeline.PipelineHparams . Ta klasa ModelFitPipeline jest wystarczająca w większości przypadków użycia rankingu TF. Klienci mogą łatwo podzielić go na podklasy do określonych celów.
Wsparcie strategii rozproszonej
Szczegółowe wprowadzenie do strategii rozproszonych obsługiwanych przez TensorFlow można znaleźć w szkoleniu rozproszonym . Obecnie potok TensorFlow Ranking obsługuje tf.distribute.MirroredStrategy (domyślnie), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy i tf.distribute.ParameterServerStrategy . Strategia lustrzana jest kompatybilna z większością systemów jednomaszynowych. W przypadku braku strategii rozproszonej ustaw strategy na None .
Ogólnie rzecz biorąc, MirroredStrategy działa w przypadku stosunkowo małych modeli na większości urządzeń z opcjami procesora i karty graficznej. MultiWorkerMirroredStrategy sprawdza się w przypadku dużych modeli, które nie mieszczą się w jednym worku. ParameterServerStrategy przeprowadza szkolenie asynchroniczne i wymaga dostępności wielu pracowników. TPUStrategy jest idealnym rozwiązaniem w przypadku dużych modeli i dużych zbiorów danych, gdy dostępne są TPU, jest jednak mniej elastyczna pod względem obsługiwanych kształtów tensorów.
Często zadawane pytania
Minimalny zestaw komponentów do korzystania z
RankingPipeline
Zobacz przykładowy kod powyżej.A co jeśli mam własny
modelKeras?
Aby można było trenować za pomocą strategiitf.distribute,modelmusi zostać skonstruowany ze wszystkimi możliwymi do wyszkolenia zmiennymi zdefiniowanymi w strategii.scope(). Więc zawiń swój model wModelBuilderjako:
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Następnie wprowadź ten model_builder do potoku w celu dalszego szkolenia.