
핵심요약 : TensorFlow Ranking Pipelines를 사용하여 TensorFlow Ranking 모델을 구축, 학습 및 제공하기 위한 상용구 코드를 줄입니다. 사용 사례와 리소스를 고려하여 대규모 순위 애플리케이션에 적절한 분산 전략을 사용하세요.
소개
TensorFlow Ranking Pipeline은 최소한의 노력으로 데이터 로그에서 확장 가능한 신경망 기반 순위 모델을 구성, 훈련 및 제공할 수 있는 일련의 데이터 처리, 모델 구축, 훈련 및 제공 프로세스로 구성됩니다. 파이프라인은 시스템이 확장될 때 가장 효율적입니다. 일반적으로 단일 시스템에서 모델을 실행하는 데 10분 이상 걸리는 경우 이 파이프라인 프레임워크를 사용하여 로드를 분산하고 처리 속도를 높이는 것이 좋습니다.
TensorFlow Ranking Pipeline은 분산 시스템(1K+ CPU 및 100+ GPU 및 TPU)에서 빅 데이터(테라바이트 이상) 및 빅 모델(1억 개 이상의 FLOP)을 사용하는 대규모 실험 및 프로덕션에서 지속적이고 안정적으로 실행되었습니다. TensorFlow 모델이 데이터의 작은 부분에 대한 model.fit 으로 입증되면 하이퍼 매개변수 스캐닝, 지속적인 훈련 및 기타 대규모 상황에 파이프라인이 권장됩니다.
순위 파이프라인
TensorFlow에서 순위 모델을 구축, 학습 및 제공하는 일반적인 파이프라인에는 다음과 같은 일반적인 단계가 포함됩니다.
- 모델 구조 정의:
- 입력 생성
- 전처리 레이어를 생성합니다.
- 신경망 아키텍처를 만듭니다.
- 열차 모델:
- 서브 모델:
- 제공 시 데이터 형식을 결정합니다.
- 훈련된 모델을 선택하고 로드합니다.
- 로드된 모델을 사용하여 처리합니다.
TensorFlow Ranking 파이프라인의 주요 목표 중 하나는 데이터세트 로드 및 전처리, 목록별 데이터 호환성 및 포인트별 채점 기능, 모델 내보내기와 같은 단계에서 상용구 코드를 줄이는 것입니다. 또 다른 중요한 목표는 본질적으로 상호 연관된 많은 프로세스의 일관된 설계를 시행하는 것입니다. 예를 들어 모델 입력은 제공 시 학습 데이터 세트 및 데이터 형식 모두와 호환되어야 합니다.
이용안내
위의 모든 설계를 통해 TF 순위 모델 출시는 그림 1과 같이 다음 단계로 구성됩니다.
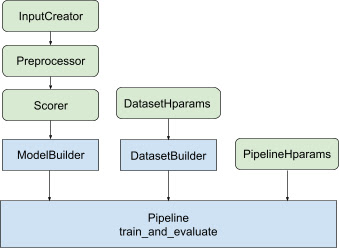
분산 신경망을 사용한 예
이 예에서는 모델 입력의 입력 기능을 일관되게 정의하기 위해 feature_spec 을 사용하는 내장 tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder 및 tfr.keras.pipeline.SimplePipeline 을 활용합니다. 데이터세트 서버. 단계별 연습이 포함된 노트북 버전은 분산 순위 튜토리얼 에서 찾을 수 있습니다.
먼저 컨텍스트 및 예제 기능 모두에 대해 feature_spec 을 정의합니다.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
그림 1에 설명된 단계를 따르세요.
feature_spec 에서 input_creator 정의합니다.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
그런 다음 동일한 입력 특성 세트에 대한 전처리 특성 변환을 정의합니다.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
내장된 피드포워드 DNN 모델로 득점자를 정의합니다.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
input_creator , preprocessor 및 scorer 사용하여 model_builder 만듭니다.
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
이제 dataset_builder 에 대한 하이퍼파라미터를 설정합니다.
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
dataset_builder 를 만듭니다.
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
또한 파이프라인에 대한 하이퍼매개변수를 설정합니다.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
ranking_pipeline 만들고 훈련하세요.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
TensorFlow 순위 파이프라인 설계
TensorFlow Ranking Pipeline은 상용구 코드를 사용하여 엔지니어링 시간을 절약하는 동시에 재정의 및 하위 클래스화를 통해 사용자 정의의 유연성을 허용합니다. 이를 달성하기 위해 파이프라인은 TensorFlow Ranking 파이프라인을 설정하기 위해 사용자 정의 가능한 클래스 tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder 및 tfr.keras.pipeline.AbstractPipeline 도입합니다.

모델빌더
Keras 모델 구성과 관련된 상용구 코드는 AbstractPipeline 으로 전달되고 파이프라인 내부에서 호출되어 전략 범위에서 모델을 빌드하는 AbstractModelBuilder 에 통합됩니다. 이는 그림 1에 나와 있습니다. 클래스 메서드는 추상 기본 클래스에 정의되어 있습니다.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
AbstractModelBuilder 를 직접 하위 클래스로 분류하고 다음과 같은 사용자 정의를 위한 구체적인 메서드로 덮어쓸 수 있습니다.
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
동시에 서브클래싱 대신 init 클래스의 함수 입력 input_creator , preprocessor 및 scorer 로 지정된 입력 기능, 전처리 변환 및 채점 함수와 함께 ModelBuilder 사용해야 합니다.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
이러한 입력을 생성하는 상용구를 줄이기 위해 input_creator 용 함수 클래스 tfr.keras.model.InputCreator , preprocessor 기용 tfr.keras.model.Preprocessor , scorer 용 tfr.keras.model.Scorer 구체적인 하위 클래스 tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer 및 tfr.keras.model.GAMScorer . 이는 대부분의 일반적인 사용 사례를 다루어야 합니다.
이러한 함수 클래스는 Keras 클래스이므로 직렬화가 필요하지 않습니다. 서브클래싱은 이를 사용자 정의하는 데 권장되는 방법입니다.
데이터 세트 빌더
DatasetBuilder 클래스는 상용구와 관련된 데이터세트를 수집합니다. 데이터는 Pipeline 으로 전달되어 훈련 및 검증 데이터 세트를 제공하고 저장된 모델에 대한 제공 서명을 정의하기 위해 호출됩니다. 그림 1에 표시된 것처럼 DatasetBuilder 메서드는 tfr.keras.pipeline.AbstractDatasetBuilder 기본 클래스에 정의되어 있습니다.
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
구체적인 DatasetBuilder 클래스에서는 build_train_datasets , build_valid_datasets 및 build_signatures 구현해야 합니다.
feature_spec 에서 데이터 세트를 만드는 구체적인 클래스도 제공됩니다.
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
DatasetBuilder 에서 사용되는 hparams tfr.keras.pipeline.DatasetHparams 데이터 클래스에 지정됩니다.
관로
순위 파이프라인은 tfr.keras.pipeline.AbstractPipeline 클래스를 기반으로 합니다.
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
model.fit 과 호환되는 다양한 tf.distribute.strategy 로 모델을 교육하는 구체적인 파이프라인 클래스도 제공됩니다.
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
tfr.keras.pipeline.ModelFitPipeline 에 사용되는 hparams tfr.keras.pipeline.PipelineHparams 데이터 클래스에 지정됩니다. 이 ModelFitPipeline 클래스는 대부분의 TF Ranking 사용 사례에 충분합니다. 클라이언트는 특정 목적을 위해 쉽게 하위 클래스로 분류할 수 있습니다.
분산 전략 지원
TensorFlow 지원 분산 전략에 대한 자세한 소개는 분산 교육 을 참조하세요. 현재 TensorFlow Ranking 파이프라인은 tf.distribute.MirroredStrategy (기본값), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy 및 tf.distribute.ParameterServerStrategy 지원합니다. 미러링 전략은 대부분의 단일 기계 시스템과 호환됩니다. 분산 전략이 없는 경우 strategy None 으로 설정하세요.
일반적으로 MirroredStrategy CPU 및 GPU 옵션이 있는 대부분의 장치에서 상대적으로 작은 모델에 작동합니다. MultiWorkerMirroredStrategy 한 작업자에게 적합하지 않은 대규모 모델에 작동합니다. ParameterServerStrategy 비동기 교육을 수행하며 여러 작업자를 사용할 수 있어야 합니다. TPUStrategy TPU를 사용할 수 있는 경우 빅 모델 및 빅 데이터에 이상적이지만 처리할 수 있는 텐서 형태 측면에서는 유연성이 떨어집니다.
자주 묻는 질문
RankingPipeline사용하기 위한 최소 구성요소 세트
위의 예제 코드를 참조하세요.나만의 Keras
model있으면 어떻게 되나요?
tf.distribute전략으로 훈련하려면 strategy.scope() 아래에 정의된 모든 훈련 가능한 변수를 사용하여model구성해야 합니다. 따라서ModelBuilder에서 모델을 다음과 같이 래핑합니다.
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
그런 다음 추가 교육을 위해 이 model_builder를 파이프라인에 입력합니다.