
TL;DR : Mengurangi kode boilerplate untuk membuat, melatih, dan menyajikan model TensorFlow Ranking dengan TensorFlow Ranking Pipelines; Gunakan strategi terdistribusi yang tepat untuk aplikasi pemeringkatan skala besar dengan mempertimbangkan kasus penggunaan dan sumber daya.
Perkenalan
TensorFlow Ranking Pipeline terdiri dari serangkaian proses pemrosesan data, pembuatan model, pelatihan, dan penyajian yang memungkinkan Anda membuat, melatih, dan menyajikan model peringkat berbasis jaringan neural yang dapat diskalakan dari log data dengan upaya minimal. Pipeline paling efisien ketika skala sistem ditingkatkan. Secara umum, jika model Anda memerlukan waktu 10 menit atau lebih untuk dijalankan pada satu mesin, pertimbangkan untuk menggunakan kerangka alur ini untuk mendistribusikan beban dan mempercepat pemrosesan.
TensorFlow Ranking Pipeline telah dijalankan secara konstan dan stabil dalam eksperimen dan produksi skala besar dengan data besar (terabyte+) dan model besar (FLOP 100+ juta) pada sistem terdistribusi (1K+ CPU dan 100+ GPU dan TPU). Setelah model TensorFlow dibuktikan dengan model.fit pada sebagian kecil data, pipeline direkomendasikan untuk pemindaian hyper-parameter, pelatihan berkelanjutan, dan situasi berskala besar lainnya.
Saluran Pemeringkatan
Di TensorFlow, pipeline tipikal untuk membuat, melatih, dan menyajikan model peringkat mencakup langkah-langkah umum berikut.
- Tentukan struktur model:
- Buat masukan;
- Buat lapisan pra-pemrosesan;
- Buat arsitektur jaringan saraf;
- Model kereta api:
- Menghasilkan kumpulan data pelatihan dan validasi dari log data;
- Siapkan model dengan hyper-parameter yang tepat:
- Pengoptimal;
- Kerugian peringkat;
- Metrik Peringkat;
- Konfigurasikan strategi terdistribusi untuk dilatih di beberapa perangkat.
- Konfigurasikan panggilan balik untuk berbagai pembukuan.
- Ekspor model untuk penayangan;
- Model penyajian:
- Menentukan format data pada saat penyajian;
- Pilih dan muat model terlatih;
- Proses dengan model yang dimuat.
Salah satu tujuan utama pipeline TensorFlow Ranking adalah untuk mengurangi kode boilerplate dalam langkah-langkahnya, seperti pemuatan set data dan prapemrosesan, kompatibilitas data listwise dan fungsi penilaian pointwise, serta ekspor model. Tujuan penting lainnya adalah untuk menegakkan desain yang konsisten dari banyak proses yang berkorelasi secara inheren, misalnya, masukan model harus kompatibel dengan kumpulan data pelatihan dan format data saat penyajian.
Gunakan Panduan
Dengan semua desain di atas, peluncuran model pemeringkatan TF dilakukan melalui langkah-langkah berikut, seperti yang ditunjukkan pada Gambar 1.
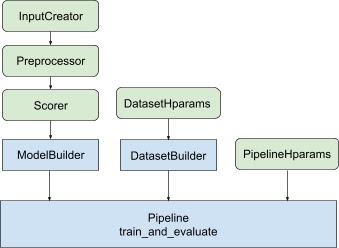
Contoh menggunakan jaringan saraf terdistribusi
Dalam contoh ini, Anda akan memanfaatkan tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder , dan tfr.keras.pipeline.SimplePipeline bawaan yang menggunakan feature_spec untuk secara konsisten mendefinisikan fitur input dalam input model dan server kumpulan data. Versi buku catatan dengan panduan langkah demi langkah dapat ditemukan di tutorial pemeringkatan terdistribusi .
Pertama-tama tentukan feature_spec untuk fitur konteks dan contoh.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Ikuti langkah-langkah yang diilustrasikan pada Gambar 1:
Tentukan input_creator dari feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Kemudian tentukan transformasi fitur prapemrosesan untuk kumpulan fitur masukan yang sama.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Tentukan pencetak gol dengan model DNN feedforward bawaan.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Buat model_builder dengan input_creator , preprocessor , dan scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Sekarang atur hyperparameter untuk dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Buat dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Atur juga hyperparameter untuk pipeline.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Buat ranking_pipeline dan latih.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Desain Pipeline Pemeringkatan TensorFlow
TensorFlow Ranking Pipeline membantu menghemat waktu teknis dengan kode boilerplate, sekaligus memungkinkan fleksibilitas penyesuaian melalui penggantian dan subkelas. Untuk mencapai hal ini, pipeline memperkenalkan kelas tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder , dan tfr.keras.pipeline.AbstractPipeline yang dapat disesuaikan untuk menyiapkan pipeline TensorFlow Ranking.

Pembuat Model
Kode boilerplate yang terkait dengan pembuatan model Keras diintegrasikan dalam AbstractModelBuilder , yang diteruskan ke AbstractPipeline dan dipanggil di dalam pipeline untuk membangun model di bawah cakupan strategi. Hal ini ditunjukkan pada Gambar 1. Metode kelas didefinisikan dalam kelas dasar abstrak.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Anda dapat langsung membuat subkelas AbstractModelBuilder dan menimpanya dengan metode konkret untuk penyesuaian, seperti
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Pada saat yang sama, Anda harus menggunakan ModelBuilder dengan fitur input, transformasi praproses, dan fungsi penilaian yang ditentukan sebagai input fungsi input_creator , preprocessor , dan scorer di kelas init alih-alih membuat subkelas.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Untuk mengurangi boilerplate dalam pembuatan input ini, kelas fungsi tfr.keras.model.InputCreator untuk input_creator , tfr.keras.model.Preprocessor untuk preprocessor , dan tfr.keras.model.Scorer untuk scorer disediakan, bersama dengan subkelas konkrit tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer , dan tfr.keras.model.GAMScorer . Ini harus mencakup sebagian besar kasus penggunaan umum.
Perhatikan bahwa kelas fungsi ini adalah kelas Keras, jadi tidak diperlukan serialisasi. Subkelas adalah cara yang disarankan untuk menyesuaikannya.
Pembuat Kumpulan Data
Kelas DatasetBuilder mengumpulkan boilerplate terkait kumpulan data. Data diteruskan ke Pipeline dan dipanggil untuk menyajikan set data pelatihan dan validasi serta untuk menentukan tanda tangan penyajian untuk model yang disimpan. Seperti yang ditunjukkan pada Gambar 1, metode DatasetBuilder didefinisikan di kelas dasar tfr.keras.pipeline.AbstractDatasetBuilder ,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
Di kelas DatasetBuilder yang konkret, Anda harus mengimplementasikan build_train_datasets , build_valid_datasets dan build_signatures .
Kelas konkrit yang membuat kumpulan data dari feature_spec juga disediakan:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
hparams yang digunakan di DatasetBuilder ditentukan dalam kelas data tfr.keras.pipeline.DatasetHparams .
Saluran pipa
Ranking Pipeline didasarkan pada kelas tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Kelas pipeline konkret yang melatih model dengan tf.distribute.strategy berbeda yang kompatibel dengan model.fit juga disediakan:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
hparams yang digunakan di tfr.keras.pipeline.ModelFitPipeline ditentukan dalam kelas data tfr.keras.pipeline.PipelineHparams . Kelas ModelFitPipeline ini cukup untuk sebagian besar kasus penggunaan TF Ranking. Klien dapat dengan mudah membuat subkelasnya untuk tujuan tertentu.
Dukungan Strategi Terdistribusi
Silakan merujuk ke pelatihan terdistribusi untuk mengetahui pengenalan mendetail tentang strategi terdistribusi yang didukung TensorFlow. Saat ini, pipeline TensorFlow Ranking mendukung tf.distribute.MirroredStrategy (default), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy , dan tf.distribute.ParameterServerStrategy . Strategi cermin kompatibel dengan sebagian besar sistem mesin tunggal. Harap tetapkan strategy ke None untuk strategi yang tidak terdistribusi.
Secara umum, MirroredStrategy berfungsi untuk model yang relatif kecil di sebagian besar perangkat dengan opsi CPU dan GPU. MultiWorkerMirroredStrategy berfungsi untuk model besar yang tidak muat dalam satu pekerja. ParameterServerStrategy melakukan pelatihan asinkron dan memerlukan banyak pekerja. TPUStrategy ideal untuk model besar dan data besar ketika TPU tersedia, namun kurang fleksibel dalam hal bentuk tensor yang dapat ditanganinya.
FAQ
Kumpulan komponen minimal untuk menggunakan
RankingPipeline
Lihat contoh kode di atas.Bagaimana jika saya memiliki
modelKeras sendiri
Untuk dilatih dengan strategitf.distribute,modelperlu dibuat dengan semua variabel yang dapat dilatih yang ditentukan dalam strategi.scope(). Jadi bungkus model Anda diModelBuildersebagai,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Kemudian masukkan model_builder ini ke pipeline untuk pelatihan lebih lanjut.