
TL;DR : Réduire le code passe-partout pour créer, former et servir des modèles TensorFlow Ranking avec TensorFlow Ranking Pipelines ; Utilisez des stratégies distribuées appropriées pour les applications de classement à grande échelle, en fonction du cas d'utilisation et des ressources.
Introduction
TensorFlow Ranking Pipeline se compose d'une série de processus de traitement de données, de création de modèles, de formation et de diffusion qui vous permettent de construire, de former et de diffuser des modèles de classement évolutifs basés sur un réseau neuronal à partir de journaux de données avec un minimum d'efforts. Le pipeline est plus efficace lorsque le système évolue. En général, si l'exécution de votre modèle prend 10 minutes ou plus sur une seule machine, envisagez d'utiliser cette infrastructure de pipeline pour répartir la charge et accélérer le traitement.
Le pipeline de classement TensorFlow a été exécuté de manière constante et stable dans le cadre d'expériences et de productions à grande échelle avec du Big Data (plus de téraoctets) et de gros modèles (plus de 100 millions de FLOP) sur des systèmes distribués (1 000 CPU et plus et plus de 100 GPU et TPU). Une fois qu'un modèle TensorFlow est éprouvé avec model.fit sur une petite partie des données, le pipeline est recommandé pour l'analyse des hyperparamètres, la formation continue et d'autres situations à grande échelle.
Pipeline de classement
Dans TensorFlow, un pipeline typique pour créer, former et servir un modèle de classement comprend les étapes typiques suivantes.
- Définir la structure du modèle :
- Créer des entrées ;
- Créer des couches de prétraitement ;
- Créer une architecture de réseau neuronal ;
- Modèle de train :
- Générer des ensembles de données d'entraînement et de validation à partir des journaux de données ;
- Préparez le modèle avec les hyper-paramètres appropriés :
- Optimiseur ;
- Pertes de classement ;
- Mesures de classement ;
- Configurez des stratégies distribuées pour vous entraîner sur plusieurs appareils.
- Configurez les rappels pour diverses comptabilités.
- Modèle d'exportation pour le service ;
- Servir le modèle :
- Déterminer le format des données au moment de la diffusion ;
- Choisissez et chargez le modèle formé ;
- Processus avec le modèle chargé.
L'un des principaux objectifs du pipeline TensorFlow Ranking est de réduire le code passe-partout dans les étapes, telles que le chargement et le prétraitement des ensembles de données, la compatibilité des données par liste et de la fonction de notation ponctuelle, ainsi que l'exportation du modèle. L'autre objectif important est d'imposer la conception cohérente de nombreux processus intrinsèquement corrélés, par exemple, les entrées du modèle doivent être compatibles à la fois avec les ensembles de données d'entraînement et le format des données au moment de la diffusion.
Guide d'utilisation
Avec toute la conception ci-dessus, le lancement d'un modèle de classement TF se déroule selon les étapes suivantes, comme le montre la figure 1.
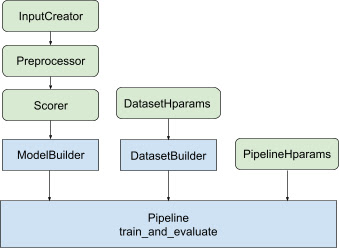
Exemple utilisant un réseau de neurones distribué
Dans cet exemple, vous exploiterez les tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder et tfr.keras.pipeline.SimplePipeline intégrés qui intègrent feature_spec pour définir de manière cohérente les fonctionnalités d'entrée dans les entrées du modèle et serveur de jeux de données. La version notebook avec une procédure pas à pas peut être trouvée dans le didacticiel de classement distribué .
Définissez d’abord feature_spec pour les fonctionnalités de contexte et d’exemple.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Suivez les étapes illustrées dans la figure 1 :
Définissez input_creator à partir de feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Définissez ensuite les transformations d’entités de prétraitement pour le même ensemble d’entités en entrée.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Définissez un marqueur avec le modèle DNN à rétroaction intégré.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Créez le model_builder avec input_creator , preprocessor et scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Définissez maintenant les hyperparamètres pour dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Créez le dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Définissez également les hyperparamètres du pipeline.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Créez le ranking_pipeline et entraînez-vous.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Conception du pipeline de classement TensorFlow
Le pipeline de classement TensorFlow permet de gagner du temps d'ingénierie grâce au code passe-partout, tout en offrant une flexibilité de personnalisation grâce au remplacement et au sous-classement. Pour y parvenir, le pipeline introduit les classes personnalisables tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder et tfr.keras.pipeline.AbstractPipeline pour configurer le pipeline TensorFlow Ranking.

Générateur de modèles
Le code passe-partout lié à la construction du modèle Keras est intégré dans AbstractModelBuilder , qui est transmis au AbstractPipeline et appelé à l'intérieur du pipeline pour créer le modèle dans le cadre de la stratégie. Ceci est illustré dans la figure 1. Les méthodes de classe sont définies dans la classe de base abstraite.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Vous pouvez directement sous-classer AbstractModelBuilder et l'écraser avec les méthodes concrètes de personnalisation, comme
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Dans le même temps, vous devez utiliser ModelBuilder avec les fonctionnalités d'entrée, les transformations de prétraitement et les fonctions de notation spécifiées comme entrées de fonction input_creator , preprocessor et scorer dans la classe init au lieu de sous-classer.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Pour réduire les passe-partout liés à la création de ces entrées, les classes de fonctions tfr.keras.model.InputCreator pour input_creator , tfr.keras.model.Preprocessor pour preprocessor et tfr.keras.model.Scorer pour scorer sont fournies, ainsi que des sous-classes concrètes tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer et tfr.keras.model.GAMScorer . Ceux-ci devraient couvrir la plupart des cas d’utilisation courants.
Notez que ces classes de fonctions sont des classes Keras, aucune sérialisation n'est donc nécessaire. Le sous-classement est la méthode recommandée pour les personnaliser.
Générateur d'ensembles de données
La classe DatasetBuilder collecte un modèle standard lié aux ensembles de données. Les données sont transmises au Pipeline et appelées pour servir les ensembles de données de formation et de validation et pour définir les signatures de service pour les modèles enregistrés. Comme le montre la figure 1, les méthodes DatasetBuilder sont définies dans la classe de base tfr.keras.pipeline.AbstractDatasetBuilder ,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
Dans une classe DatasetBuilder concrète, vous devez implémenter build_train_datasets , build_valid_datasets et build_signatures .
Une classe concrète qui crée des ensembles de données à partir de feature_spec s est également fournie :
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
Les hparams utilisés dans DatasetBuilder sont spécifiés dans la classe de données tfr.keras.pipeline.DatasetHparams .
Pipeline
Le pipeline de classement est basé sur la classe tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Une classe de pipeline concrète qui entraîne le modèle avec différents tf.distribute.strategy compatibles avec model.fit est également fournie :
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
Les hparams utilisés dans tfr.keras.pipeline.ModelFitPipeline sont spécifiés dans la classe de données tfr.keras.pipeline.PipelineHparams . Cette classe ModelFitPipeline est suffisante pour la plupart des cas d’utilisation de TF Ranking. Les clients peuvent facilement le sous-classer à des fins spécifiques.
Prise en charge de la stratégie distribuée
Veuillez vous référer à la formation distribuée pour une introduction détaillée des stratégies distribuées prises en charge par TensorFlow. Actuellement, le pipeline TensorFlow Ranking prend en charge tf.distribute.MirroredStrategy (par défaut), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy et tf.distribute.ParameterServerStrategy . La stratégie miroir est compatible avec la plupart des systèmes à machine unique. Veuillez définir strategy sur None pour aucune stratégie distribuée.
En général, MirroredStrategy fonctionne pour des modèles relativement petits sur la plupart des appareils dotés d'options CPU et GPU. MultiWorkerMirroredStrategy fonctionne pour les grands modèles qui ne tiennent pas dans un seul travailleur. ParameterServerStrategy effectue une formation asynchrone et nécessite la disponibilité de plusieurs travailleurs. TPUStrategy est idéal pour les gros modèles et le big data lorsque les TPU sont disponibles, cependant, il est moins flexible en termes de formes de tenseurs qu'il peut gérer.
FAQ
L'ensemble minimal de composants pour utiliser le
RankingPipeline
Voir l'exemple de code ci-dessus.Et si j'ai mon propre
modelKeras
Pour être formé avec les stratégiestf.distribute,modeldoit être construit avec toutes les variables entraînables définies sous stratégie.scope(). Alors enveloppez votre modèle dansModelBuildercomme suit :
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Introduisez ensuite ce model_builder dans le pipeline pour une formation ultérieure.