
TL;DR : تقليل التعليمات البرمجية المعيارية لإنشاء نماذج TensorFlow Ranking وتدريبها وتقديمها باستخدام خطوط أنابيب TensorFlow Ranking؛ استخدم الاستراتيجيات الموزعة المناسبة لتطبيقات التصنيف واسعة النطاق بالنظر إلى حالة الاستخدام والموارد.
مقدمة
يتكون TensorFlow Ranking Pipeline من سلسلة من عمليات معالجة البيانات وبناء النماذج والتدريب والخدمة التي تتيح لك إنشاء نماذج تصنيف قائمة على الشبكة العصبية قابلة للتطوير وتدريبها وتقديمها من سجلات البيانات بأقل جهد. يكون خط الأنابيب أكثر كفاءة عندما يتم توسيع نطاق النظام. بشكل عام، إذا كان النموذج الخاص بك يستغرق 10 دقائق أو أكثر للتشغيل على جهاز واحد، ففكر في استخدام إطار عمل خط الأنابيب هذا لتوزيع الحمل وتسريع المعالجة.
تم تشغيل خط أنابيب TensorFlow Ranking بشكل مستمر وثابت في تجارب وإنتاج واسعة النطاق باستخدام البيانات الضخمة (تيرابايت+) والنماذج الكبيرة (100 مليون+ من FLOPs) على الأنظمة الموزعة (1K+ CPU و100+ GPU وTPUs). بمجرد إثبات نموذج TensorFlow مع model.fit على جزء صغير من البيانات، يوصى باستخدام خط الأنابيب لمسح المعلمات الفائقة والتدريب المستمر والمواقف الأخرى واسعة النطاق.
خط أنابيب الترتيب
في TensorFlow، يشتمل المسار النموذجي لبناء نموذج التصنيف وتدريبه وخدمته على الخطوات النموذجية التالية.
- تحديد هيكل النموذج:
- إنشاء المدخلات.
- إنشاء طبقات ما قبل المعالجة؛
- إنشاء بنية الشبكة العصبية.
- نموذج القطار:
- إنشاء مجموعات بيانات التدريب والتحقق من سجلات البيانات؛
- قم بإعداد النموذج باستخدام المعلمات الفائقة المناسبة:
- محسن.
- خسائر الترتيب
- مقاييس الترتيب؛
- قم بتكوين الاستراتيجيات الموزعة للتدريب عبر أجهزة متعددة.
- تكوين عمليات الاسترجاعات لمختلف مسك الدفاتر.
- نموذج التصدير للخدمة؛
- نموذج الخدمة:
- تحديد تنسيق البيانات عند التقديم؛
- اختيار وتحميل النموذج المدرب؛
- العملية مع النموذج المحمل.
أحد الأهداف الرئيسية لخط أنابيب TensorFlow Ranking هو تقليل التعليمات البرمجية النمطية في الخطوات، مثل تحميل مجموعة البيانات والمعالجة المسبقة، وتوافق بيانات القائمة ووظيفة التسجيل النقطي، وتصدير النموذج. والهدف المهم الآخر هو فرض التصميم المتسق للعديد من العمليات المترابطة بطبيعتها، على سبيل المثال، يجب أن تكون مدخلات النموذج متوافقة مع كل من مجموعات بيانات التدريب وتنسيق البيانات في الخدمة.
استخدم الدليل
مع كل التصميم المذكور أعلاه، فإن إطلاق نموذج تصنيف TF يقع في الخطوات التالية، كما هو موضح في الشكل 1.
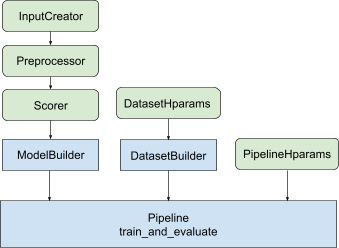
مثال باستخدام الشبكة العصبية الموزعة
في هذا المثال، ستستفيد من tfr.keras.model.FeatureSpecInputCreator و tfr.keras.pipeline.SimpleDatasetBuilder و tfr.keras.pipeline.SimplePipeline التي تستخدم feature_spec لتحديد ميزات الإدخال بشكل متسق في مدخلات النموذج و خادم مجموعة البيانات. يمكن العثور على نسخة دفتر الملاحظات مع الإرشادات التفصيلية خطوة بخطوة في البرنامج التعليمي الموزع للتصنيف .
قم أولاً بتعريف feature_spec s لكل من ميزات السياق والأمثلة.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
اتبع الخطوات الموضحة في الشكل 1:
حدد input_creator من feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
ثم حدد تحويلات ميزات المعالجة المسبقة لنفس مجموعة ميزات الإدخال.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
تحديد الهداف باستخدام نموذج DNN المغذّي المدمج.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
قم بإنشاء model_builder باستخدام input_creator preprocessor scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
الآن قم بتعيين المعلمات الفائقة لـ dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
قم بإنشاء dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
قم أيضًا بتعيين المعلمات الفائقة لخط الأنابيب.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
اصنع ranking_pipeline وتدرب.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
تصميم خط أنابيب تصنيف TensorFlow
يساعد خط أنابيب TensorFlow Ranking Pipeline على توفير الوقت الهندسي من خلال التعليمات البرمجية المعيارية، وفي الوقت نفسه، يسمح بمرونة التخصيص من خلال التجاوز والتصنيف الفرعي. ولتحقيق ذلك، يقدم المسار فئات قابلة للتخصيص tfr.keras.model.AbstractModelBuilder و tfr.keras.pipeline.AbstractDatasetBuilder و tfr.keras.pipeline.AbstractPipeline لإعداد خط أنابيب TensorFlow Ranking.

ModelBuilder
تم دمج الكود النمطي المتعلق ببناء نموذج Keras في AbstractModelBuilder ، والذي يتم تمريره إلى AbstractPipeline ويتم استدعاؤه داخل المسار لبناء النموذج ضمن نطاق الإستراتيجية. يظهر هذا في الشكل 1. يتم تعريف أساليب الفصل في الفئة الأساسية المجردة.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
يمكنك مباشرة تصنيف فئة فرعية من AbstractModelBuilder والكتابة فوقها بطرق محددة للتخصيص، مثل
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
في الوقت نفسه، يجب عليك استخدام ModelBuilder مع ميزات الإدخال، وتحويلات المعالجة المسبقة، ووظائف التسجيل المحددة كمدخلات دالة input_creator ، و preprocessor ، و scorer في الفئة init بدلاً من التصنيف الفرعي.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
لتقليل القواعد النمطية لإنشاء هذه المدخلات، يتم توفير فئات الوظائف tfr.keras.model.InputCreator لـ input_creator و tfr.keras.model.Preprocessor للمعالج preprocessor و tfr.keras.model.Scorer لـ scorer ، جنبًا إلى جنب مع الفئات الفرعية الملموسة tfr.keras.model.FeatureSpecInputCreator و tfr.keras.model.TypeSpecInputCreator و tfr.keras.model.PreprocessorWithSpec و tfr.keras.model.UnivariateScorer و tfr.keras.model.DNNScorer و tfr.keras.model.GAMScorer . يجب أن تغطي هذه معظم حالات الاستخدام الشائعة.
لاحظ أن فئات الوظائف هذه هي فئات Keras، لذلك ليست هناك حاجة للتسلسل. التصنيف الفرعي هو الطريقة الموصى بها لتخصيصها.
DatasetBuilder
تقوم فئة DatasetBuilder بجمع البيانات المعيارية ذات الصلة بمجموعة البيانات. يتم تمرير البيانات إلى Pipeline ويتم استدعاؤها لخدمة مجموعات بيانات التدريب والتحقق من الصحة ولتحديد توقيعات الخدمة للنماذج المحفوظة. كما هو موضح في الشكل 1، يتم تعريف أساليب DatasetBuilder في الفئة الأساسية tfr.keras.pipeline.AbstractDatasetBuilder ،
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
في فئة DatasetBuilder الملموسة، يجب عليك تنفيذ build_train_datasets و build_valid_datasets و build_signatures .
يتم أيضًا توفير فئة محددة تصنع مجموعات البيانات من feature_spec s:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
يتم تحديد hparams المستخدمة في DatasetBuilder في فئة البيانات tfr.keras.pipeline.DatasetHparams .
خط أنابيب
يعتمد خط أنابيب التصنيف على فئة tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
يتم أيضًا توفير فئة خطوط الأنابيب الملموسة التي تدرب النموذج باستخدام برامج tf.distribute.strategy المختلفة المتوافقة مع model.fit :
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
يتم تحديد hparams المستخدمة في tfr.keras.pipeline.ModelFitPipeline في فئة بيانات tfr.keras.pipeline.PipelineHparams . تعتبر فئة ModelFitPipeline هذه كافية لمعظم حالات استخدام تصنيف TF. يمكن للعملاء تصنيفها بسهولة لأغراض محددة.
دعم الاستراتيجية الموزعة
يرجى الرجوع إلى التدريب الموزع للحصول على مقدمة تفصيلية عن الاستراتيجيات الموزعة المدعومة بـ TensorFlow. حاليًا، يدعم مسار TensorFlow Ranking tf.distribute.MirroredStrategy (افتراضي)، tf.distribute.TPUStrategy ، و tf.distribute.MultiWorkerMirroredStrategy ، و tf.distribute.ParameterServerStrategy . تتوافق الإستراتيجية المعكوسة مع معظم أنظمة الآلة الفردية. يرجى ضبط strategy على None لعدم وجود إستراتيجية موزعة.
بشكل عام، تعمل MirroredStrategy مع نماذج صغيرة نسبيًا على معظم الأجهزة المزودة بخيارات وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU). تعمل MultiWorkerMirroredStrategy مع النماذج الكبيرة التي لا تتناسب مع عامل واحد. تقوم ParameterServerStrategy بإجراء تدريب غير متزامن وتتطلب توفر العديد من العاملين. تعتبر TPUStrategy مثالية للنماذج الكبيرة والبيانات الضخمة عند توفر وحدات TPU، ومع ذلك، فهي أقل مرونة من حيث أشكال الموتر التي يمكنها التعامل معها.
الأسئلة الشائعة
الحد الأدنى من مجموعة المكونات لاستخدام
RankingPipeline
انظر رمز المثال أعلاه.ماذا لو كان لدي
modelKeras الخاص بي
ليتم تدريبه باستخدام استراتيجياتtf.distribute، يجب إنشاءmodelباستخدام جميع المتغيرات القابلة للتدريب المحددة ضمن Strategy.scope(). لذا قم بلف النموذج الخاص بك فيModelBuilderكـ،
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
ثم أدخل نموذج_builder هذا في خط الأنابيب لمزيد من التدريب.