
A biblioteca TensorFlow Ranking ajuda você a criar aprendizado escalonável para classificar modelos de aprendizado de máquina usando abordagens e técnicas bem estabelecidas de pesquisas recentes. Um modelo de classificação pega uma lista de itens semelhantes, como páginas da web, e gera uma lista otimizada desses itens, por exemplo, os mais relevantes para as páginas menos relevantes. Aprender a classificar modelos tem aplicações em pesquisa, resposta a perguntas, sistemas de recomendação e sistemas de diálogo. Você pode usar esta biblioteca para acelerar a construção de um modelo de classificação para seu aplicativo usando a API Keras . A biblioteca Ranking também fornece utilitários de fluxo de trabalho para facilitar a expansão da implementação do seu modelo para trabalhar de forma eficaz com grandes conjuntos de dados usando estratégias de processamento distribuído.
Esta visão geral fornece um breve resumo do desenvolvimento do aprendizado para classificar modelos com esta biblioteca, apresenta algumas técnicas avançadas suportadas pela biblioteca e discute os utilitários de fluxo de trabalho fornecidos para suportar o processamento distribuído para aplicativos de classificação.
Desenvolvendo aprendizado para classificar modelos
A construção do modelo com a biblioteca TensorFlow Ranking segue estas etapas gerais:
- Especifique uma função de pontuação usando camadas Keras (
tf.keras.layers) - Defina as métricas que você deseja usar para avaliação, como
tfr.keras.metrics.NDCGMetric - Especifique uma função de perda, como
tfr.keras.losses.SoftmaxLoss - Compile o modelo com
tf.keras.Model.compile()e treine-o com seus dados
O tutorial Recomendar filmes orienta você nos princípios básicos da construção de um modelo de aprendizado para classificação com esta biblioteca. Confira a seção Suporte para classificação distribuída para obter mais informações sobre a construção de modelos de classificação em grande escala.
Técnicas avançadas de classificação
A biblioteca TensorFlow Ranking fornece suporte para a aplicação de técnicas avançadas de classificação pesquisadas e implementadas por pesquisadores e engenheiros do Google. As seções a seguir fornecem uma visão geral de algumas dessas técnicas e como começar a usá-las em seu aplicativo.
Ordenação de entrada da lista BERT
A biblioteca Ranking fornece uma implementação de TFR-BERT, uma arquitetura de pontuação que combina BERT com modelagem LTR para otimizar a ordenação das entradas da lista. Como exemplo de aplicação dessa abordagem, considere uma consulta e uma lista de n documentos que você deseja classificar em resposta a essa consulta. Em vez de aprender uma representação BERT pontuada independentemente entre pares <query, document> , os modelos LTR aplicam uma perda de classificação para aprender conjuntamente uma representação BERT que maximiza a utilidade de toda a lista classificada em relação aos rótulos de verdade. A figura a seguir ilustra esta técnica:
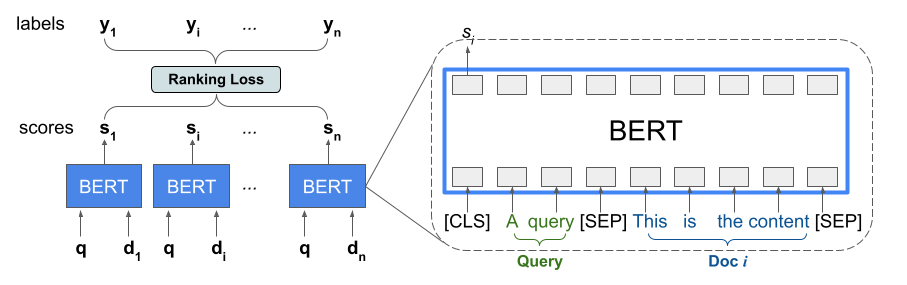
Essa abordagem nivela uma lista de documentos para classificar em resposta a uma consulta em uma lista de tuplas <query, document> . Essas tuplas são então alimentadas em um modelo de linguagem pré-treinado BERT. Os resultados agrupados do BERT para toda a lista de documentos são então ajustados em conjunto com uma das perdas de classificação especializadas disponíveis no TensorFlow Ranking.
Essa arquitetura pode oferecer melhorias significativas no desempenho do modelo de linguagem pré-treinado, produzindo desempenho de última geração para diversas tarefas de classificação populares, especialmente quando vários modelos de linguagem pré-treinados são combinados. Para obter mais informações sobre esta técnica, consulte a pesquisa relacionada. Você pode começar com uma implementação simples no código de exemplo do TensorFlow Ranking.
Modelos Aditivos Generalizados de Classificação Neural (GAM)
Para alguns sistemas de classificação, como avaliação de elegibilidade para empréstimos, direcionamento de anúncios ou orientação para tratamento médico, a transparência e a explicabilidade são considerações críticas. A aplicação de modelos aditivos generalizados (GAMs) com fatores de ponderação bem compreendidos pode ajudar seu modelo de classificação a ser mais explicável e interpretável.
Os GAMs têm sido extensivamente estudados com tarefas de regressão e classificação, mas é menos claro como aplicá-los a uma aplicação de classificação. Por exemplo, embora os GAMs possam ser simplesmente aplicados para modelar cada item individual da lista, modelar tanto as interações dos itens quanto o contexto em que esses itens são classificados é um problema mais desafiador. O TensorFlow Ranking fornece uma implementação de classificação neural GAM , uma extensão de modelos aditivos generalizados projetados para problemas de classificação. A implementação de GAMs do TensorFlow Ranking permite adicionar peso específico aos recursos do seu modelo.
A ilustração a seguir de um sistema de classificação de hotéis usa relevância, preço e distância como recursos principais de classificação. Este modelo aplica uma técnica GAM para pesar essas dimensões de forma diferente, com base no contexto do dispositivo do usuário. Por exemplo, se a consulta vier de um telefone, a distância terá um peso maior, presumindo que os usuários estejam procurando um hotel próximo.
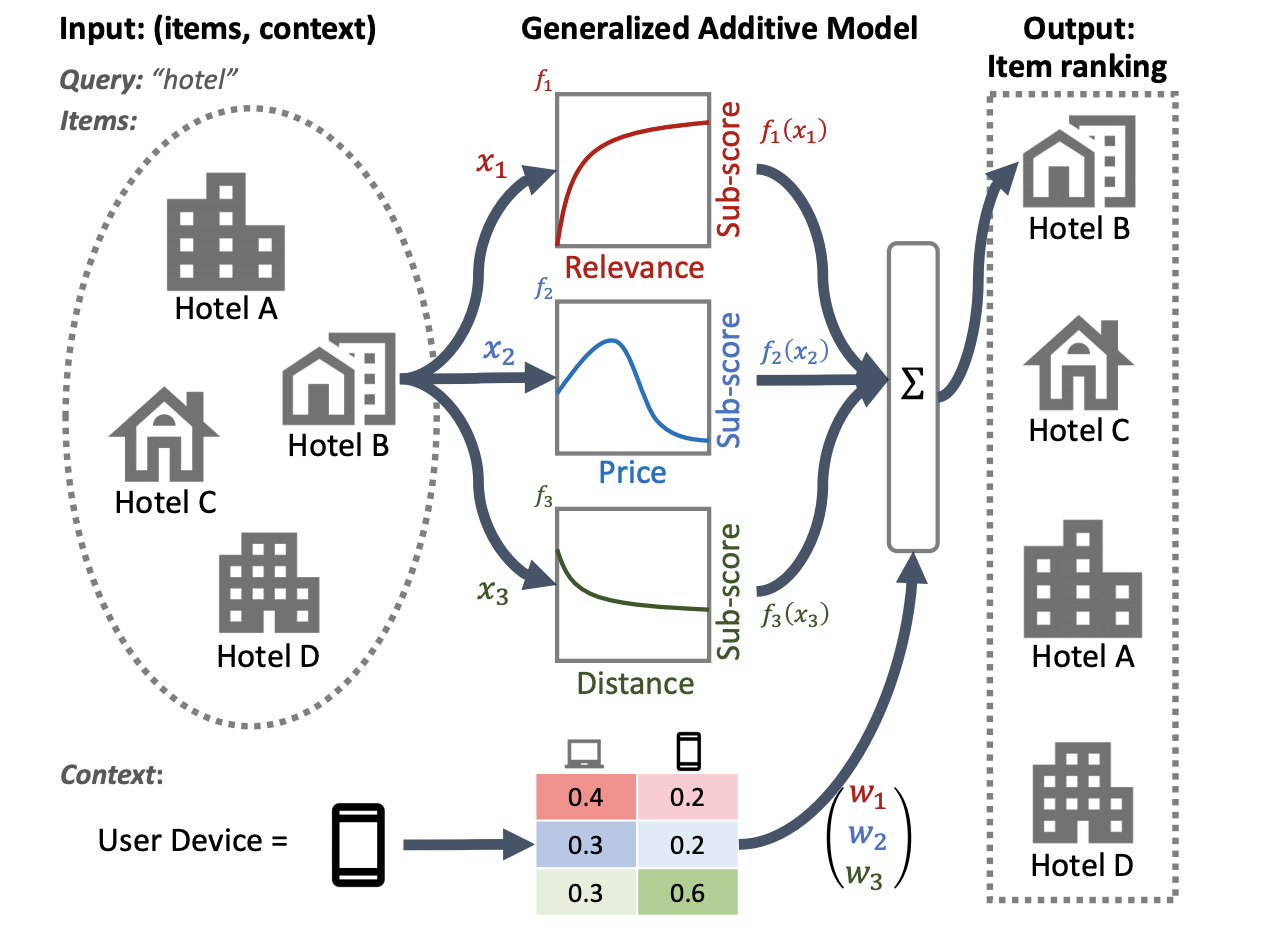
Para obter mais informações sobre o uso de GAMs com modelos de classificação, consulte a pesquisa relacionada. Você pode começar com um exemplo de implementação dessa técnica no código de exemplo do TensorFlow Ranking.
Suporte de classificação distribuída
O TensorFlow Ranking foi projetado para construir sistemas de classificação em larga escala de ponta a ponta: incluindo processamento de dados, construção de modelo, avaliação e implantação de produção. Ele pode lidar com recursos heterogêneos, densos e esparsos, escalar até milhões de pontos de dados e foi projetado para oferecer suporte ao treinamento distribuído para aplicações de classificação em grande escala.
A biblioteca fornece uma arquitetura de pipeline de classificação otimizada, para evitar códigos repetitivos e padronizados e criar soluções distribuídas que podem ser aplicadas desde o treinamento de seu modelo de classificação até atendê-lo. O pipeline de classificação oferece suporte à maioria das estratégias distribuídas do TensorFlow, incluindo MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy e ParameterServerStrategy . O pipeline de classificação pode exportar o modelo de classificação treinado no formato tf.saved_model , que suporta várias assinaturas de entrada. Além disso, o pipeline de classificação fornece retornos de chamada úteis, incluindo suporte para visualização de dados TensorBoard e BackupAndRestore para ajudar na recuperação de falhas em longa execução operações de treinamento.
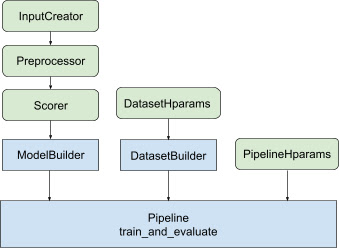
A biblioteca de classificação auxilia na construção de uma implementação de treinamento distribuído, fornecendo um conjunto de classes tfr.keras.pipeline , que usam um construtor de modelo, um construtor de dados e hiperparâmetros como entrada. A classe tfr.keras.ModelBuilder baseada em Keras permite criar um modelo para processamento distribuído e funciona com classes extensíveis InputCreator, Preprocessor e Scorer:
As classes de pipeline do TensorFlow Ranking também funcionam com um DatasetBuilder para configurar dados de treinamento, que podem incorporar hiperparâmetros . Finalmente, o próprio pipeline pode incluir um conjunto de hiperparâmetros como um objeto PipelineHparams .
Comece a construir modelos de classificação distribuída usando o tutorial Classificação distribuída .