
La bibliothèque TensorFlow Ranking vous aide à créer un apprentissage évolutif pour classer les modèles d'apprentissage automatique à l'aide d'approches et de techniques bien établies issues de recherches récentes. Un modèle de classement prend une liste d'éléments similaires, tels que des pages Web, et génère une liste optimisée de ces éléments, par exemple les pages les plus pertinentes aux moins pertinentes. Apprendre à classer les modèles a des applications dans la recherche, la réponse aux questions, les systèmes de recommandation et les systèmes de dialogue. Vous pouvez utiliser cette bibliothèque pour accélérer la création d'un modèle de classement pour votre application à l'aide de l' API Keras . La bibliothèque Ranking fournit également des utilitaires de flux de travail pour faciliter la mise à l'échelle de la mise en œuvre de votre modèle afin de travailler efficacement avec de grands ensembles de données à l'aide de stratégies de traitement distribué.
Cette présentation fournit un bref résumé du développement de l'apprentissage du classement des modèles avec cette bibliothèque, présente certaines techniques avancées prises en charge par la bibliothèque et discute des utilitaires de flux de travail fournis pour prendre en charge le traitement distribué pour les applications de classement.
Développer l’apprentissage du classement des modèles
La création d'un modèle avec la bibliothèque TensorFlow Ranking suit ces étapes générales :
- Spécifiez une fonction de notation à l'aide des couches Keras (
tf.keras.layers) - Définissez les métriques que vous souhaitez utiliser pour l'évaluation, telles que
tfr.keras.metrics.NDCGMetric - Spécifiez une fonction de perte, telle que
tfr.keras.losses.SoftmaxLoss - Compilez le modèle avec
tf.keras.Model.compile()et entraînez-le avec vos données
Le didacticiel Recommander des films vous explique les bases de la création d'un modèle d'apprentissage du classement avec cette bibliothèque. Consultez la section Prise en charge du classement distribué pour plus d'informations sur la création de modèles de classement à grande échelle.
Techniques de classement avancées
La bibliothèque TensorFlow Ranking prend en charge l'application de techniques de classement avancées recherchées et mises en œuvre par les chercheurs et ingénieurs de Google. Les sections suivantes donnent un aperçu de certaines de ces techniques et expliquent comment commencer à les utiliser dans votre application.
Ordre d'entrée de la liste BERT
La bibliothèque Ranking fournit une implémentation de TFR-BERT, une architecture de notation qui associe BERT à la modélisation LTR pour optimiser l'ordre des entrées de liste. À titre d'exemple d'application de cette approche, considérons une requête et une liste de n documents que vous souhaitez classer en réponse à cette requête. Au lieu d'apprendre une représentation BERT notée indépendamment sur les paires <query, document> , les modèles LTR appliquent une perte de classement pour apprendre conjointement une représentation BERT qui maximise l'utilité de l'ensemble de la liste classée par rapport aux étiquettes de vérité terrain. La figure suivante illustre cette technique :
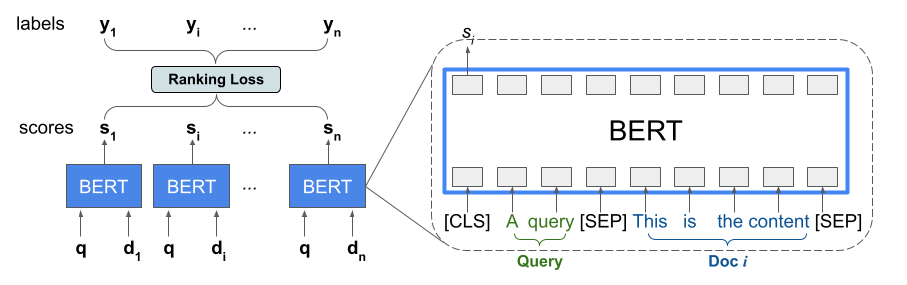
Cette approche aplatit une liste de documents à classer en réponse à une requête en une liste de tuples <query, document> . Ces tuples sont ensuite introduits dans un modèle de langage pré-entraîné BERT. Les sorties BERT regroupées pour l'ensemble de la liste de documents sont ensuite affinées conjointement avec l'une des pertes de classement spécialisées disponibles dans TensorFlow Ranking.
Cette architecture peut apporter des améliorations significatives dans les performances des modèles de langage pré-entraînés, produisant des performances de pointe pour plusieurs tâches de classement courantes, en particulier lorsque plusieurs modèles de langage pré-entraînés sont combinés. Pour plus d'informations sur cette technique, voir la recherche associée. Vous pouvez commencer avec une implémentation simple dans l' exemple de code TensorFlow Ranking .
Modèles additifs généralisés de classement neuronal (GAM)
Pour certains systèmes de classement, tels que l’évaluation de l’éligibilité au prêt, le ciblage publicitaire ou les conseils en matière de traitement médical, la transparence et l’explicabilité sont des considérations cruciales. L'application de modèles additifs généralisés (GAM) avec des facteurs de pondération bien compris peut aider votre modèle de classement à être plus explicable et interprétable.
Les GAM ont été largement étudiés avec des tâches de régression et de classification, mais la manière de les appliquer à une application de classement est moins claire. Par exemple, alors que les GAM peuvent être simplement appliqués pour modéliser chaque élément individuel de la liste, la modélisation à la fois des interactions entre les éléments et du contexte dans lequel ces éléments sont classés est un problème plus difficile. TensorFlow Ranking fournit une implémentation du classement neuronal GAM , une extension des modèles additifs généralisés conçus pour les problèmes de classement. L' implémentation TensorFlow Ranking des GAM vous permet d'ajouter une pondération spécifique aux fonctionnalités de votre modèle.
L'illustration suivante d'un système de classement d'hôtels utilise la pertinence, le prix et la distance comme principales caractéristiques de classement. Ce modèle applique une technique GAM pour pondérer ces dimensions différemment, en fonction du contexte de l'appareil de l'utilisateur. Par exemple, si la requête provient d’un téléphone, la distance est plus importante, en supposant que les utilisateurs recherchent un hôtel à proximité.
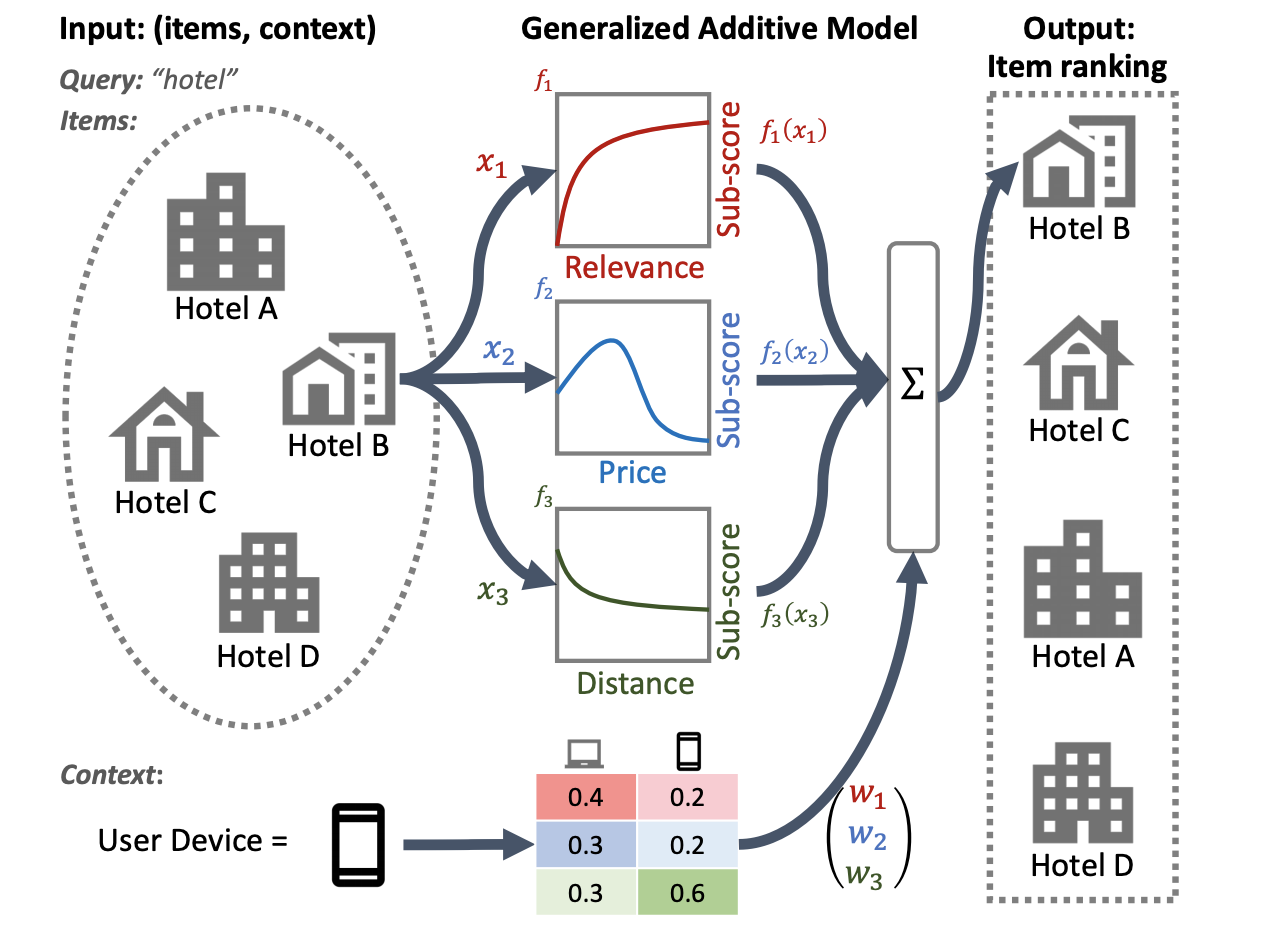
Pour plus d'informations sur l'utilisation des GAM avec des modèles de classement, consultez la recherche associée. Vous pouvez commencer avec un exemple d'implémentation de cette technique dans l' exemple de code TensorFlow Ranking .
Prise en charge du classement distribué
TensorFlow Ranking est conçu pour créer des systèmes de classement à grande échelle de bout en bout : y compris le traitement des données, la création de modèles, l'évaluation et le déploiement en production. Il peut gérer des fonctionnalités hétérogènes, denses et clairsemées, évoluer jusqu'à des millions de points de données et est conçu pour prendre en charge la formation distribuée pour les applications de classement à grande échelle.
La bibliothèque fournit une architecture de pipeline de classement optimisée, pour éviter le code passe-partout répétitif et créer des solutions distribuées qui peuvent être appliquées depuis la formation de votre modèle de classement jusqu'à son service. Le pipeline de classement prend en charge la plupart des stratégies distribuées de TensorFlow, notamment MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy et ParameterServerStrategy . Le pipeline de classement peut exporter le modèle de classement formé au format tf.saved_model , qui prend en charge plusieurs signatures d'entrée. De plus, le pipeline de classement fournit des rappels utiles, notamment la prise en charge de la visualisation des données TensorBoard et de BackupAndRestore pour aider à la récupération après des échecs de longue durée. opérations de formation.
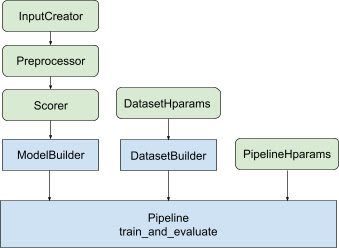
La bibliothèque de classement aide à créer une implémentation de formation distribuée en fournissant un ensemble de classes tfr.keras.pipeline , qui prennent en entrée un générateur de modèles, un générateur de données et des hyperparamètres. La classe tfr.keras.ModelBuilder basée sur Keras vous permet de créer un modèle pour le traitement distribué et fonctionne avec les classes extensibles InputCreator, Preprocessor et Scorer :
Les classes de pipeline TensorFlow Ranking fonctionnent également avec un DatasetBuilder pour configurer des données d'entraînement, qui peuvent incorporer des hyperparamètres . Enfin, le pipeline lui-même peut inclure un ensemble d'hyperparamètres en tant qu'objet PipelineHparams .
Commencez à créer des modèles de classement distribué à l'aide du didacticiel de classement distribué .