
ספריית TensorFlow Ranking מסייעת לך לבנות למידה ניתנת להרחבה כדי לדרג מודלים של למידת מכונה באמצעות גישות וטכניקות מבוססות היטב ממחקרים עדכניים. מודל דירוג לוקח רשימה של פריטים דומים, כגון דפי אינטרנט, ומייצר רשימה אופטימלית של אותם פריטים, למשל הרלוונטיים ביותר לדפים הכי פחות רלוונטיים. ללימוד דירוג מודלים יש אפליקציות בחיפוש, מענה לשאלות, מערכות ממליצים ומערכות דיאלוג. אתה יכול להשתמש בספרייה זו כדי להאיץ את בניית מודל דירוג עבור היישום שלך באמצעות Keras API . ספריית הדירוג מספקת גם כלי עזר לזרימת עבודה כדי להקל על הגדלה של יישום המודל שלך לעבודה יעילה עם מערכי נתונים גדולים באמצעות אסטרטגיות עיבוד מבוזרות.
סקירה כללית זו מספקת סיכום קצר של פיתוח למידה לדירוג מודלים עם ספרייה זו, מציגה כמה טכניקות מתקדמות הנתמכות על ידי הספרייה, ודנה בכלי השירות של זרימת העבודה המסופקים לתמיכה בעיבוד מבוזר עבור דירוג יישומים.
פיתוח למידה לדירוג מודלים
בניית מודל עם ספריית דירוג TensorFlow עוקבת אחר השלבים הכלליים הבאים:
- ציין פונקציית ניקוד באמצעות שכבות Keras (
tf.keras.layers) - הגדר את המדדים שבהם ברצונך להשתמש להערכה, כגון
tfr.keras.metrics.NDCGMetric - ציין פונקציית הפסד, כגון
tfr.keras.losses.SoftmaxLoss - הרכיבו את המודל עם
tf.keras.Model.compile()והכשירו אותו עם הנתונים שלכם
המדריך 'המלצה על סרטים' מנחה אותך דרך היסודות של בניית מודל למידה לדירוג עם ספרייה זו. עיין בסעיף התמיכה בדירוג מבוזר למידע נוסף על בניית מודלים של דירוג בקנה מידה גדול.
טכניקות דירוג מתקדמות
ספריית דירוג TensorFlow מספקת תמיכה ביישום טכניקות דירוג מתקדמות שנחקרו ויושמו על ידי חוקרים ומהנדסים של גוגל. הסעיפים הבאים מספקים סקירה כללית של חלק מהטכניקות הללו וכיצד להתחיל להשתמש בהן ביישום שלך.
סדר קלט ברשימת BERT
ספריית הדירוג מספקת יישום של TFR-BERT, ארכיטקטורת ניקוד המשלבת BERT עם מודלים של LTR כדי לייעל את הסדר של כניסות הרשימה. כדוגמה ליישום של גישה זו, שקול שאילתה ורשימה של n מסמכים שברצונך לדרג בתגובה לשאילתה זו. במקום ללמוד ייצוג BERT שקיבל ניקוד עצמאי על פני צמדי <query, document> , מודלים של LTR מיישמים אובדן דירוג כדי ללמוד במשותף ייצוג BERT שממקסם את התועלת של כל הרשימה המדורגת ביחס לתוויות האמת. האיור הבא ממחיש טכניקה זו:
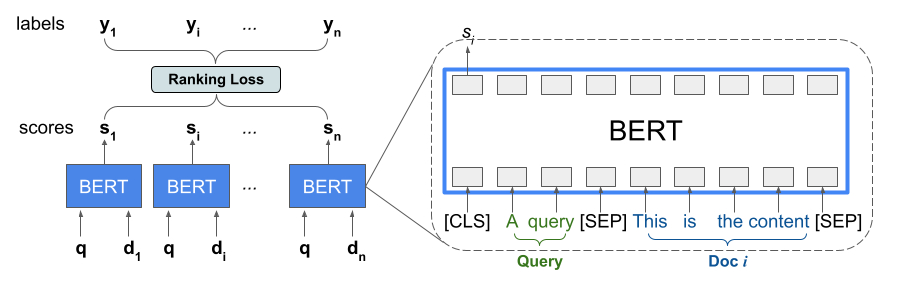
גישה זו משטחת רשימה של מסמכים לדירוג בתגובה לשאילתה לרשימה של <query, document> tuples. טפולים אלה מוזנים לאחר מכן למודל שפה מיומן מראש של BERT. פלטי ה-BERT המאוגדים עבור כל רשימת המסמכים מכוונים יחד עם אחד מהפסדי הדירוג המיוחדים הזמינים בדירוג TensorFlow.
ארכיטקטורה זו יכולה לספק שיפורים משמעותיים בביצועי מודל שפה מאומנת מראש, לייצר ביצועים מתקדמים עבור מספר משימות דירוג פופולריות, במיוחד כאשר משולבים מודלים מרובים של שפה מאומנת מראש. למידע נוסף על טכניקה זו, עיין במחקר הקשור. אתה יכול להתחיל עם יישום פשוט בקוד לדוגמה של TensorFlow Ranking.
דירוג עצבי מודלים תוספים כלליים (GAM)
עבור מערכות דירוג מסוימות, כגון הערכת זכאות להלוואה, מיקוד פרסומות או הדרכה לטיפול רפואי, שקיפות והסבר הן שיקולים קריטיים. יישום מודלים תוספים כלליים (GAMs) עם גורמי שקלול מובנים היטב יכול לעזור למודל הדירוג שלך להיות ברור יותר וניתן לפרשנות.
GAMs נחקרו בהרחבה עם משימות רגרסיה וסיווג, אך פחות ברור כיצד ליישם אותם ביישום דירוג. לדוגמה, בעוד ש-GAMs ניתן להחיל בפשטות מודל של כל פריט בודד ברשימה, מודלים הן את האינטראקציות של הפריט והן את ההקשר שבו פריטים אלה מדורגים היא בעיה מאתגרת יותר. TensorFlow Ranking מספק יישום של דירוג עצבי GAM , הרחבה של מודלים תוספים כלליים המיועדים לדירוג בעיות. יישום TensorFlow Ranking של GAMs מאפשר לך להוסיף שקלול ספציפי לתכונות של המודל שלך.
ההמחשה הבאה של מערכת דירוג מלונות משתמשת ברלוונטיות, מחיר ומרחק כמאפייני דירוג ראשיים. מודל זה מיישם טכניקת GAM כדי לשקול מידות אלו בצורה שונה, בהתבסס על הקשר המכשיר של המשתמש. לדוגמה, אם השאילתה הגיעה מטלפון, המרחק משוקל בכבדות יותר, בהנחה שמשתמשים מחפשים מלון קרוב.
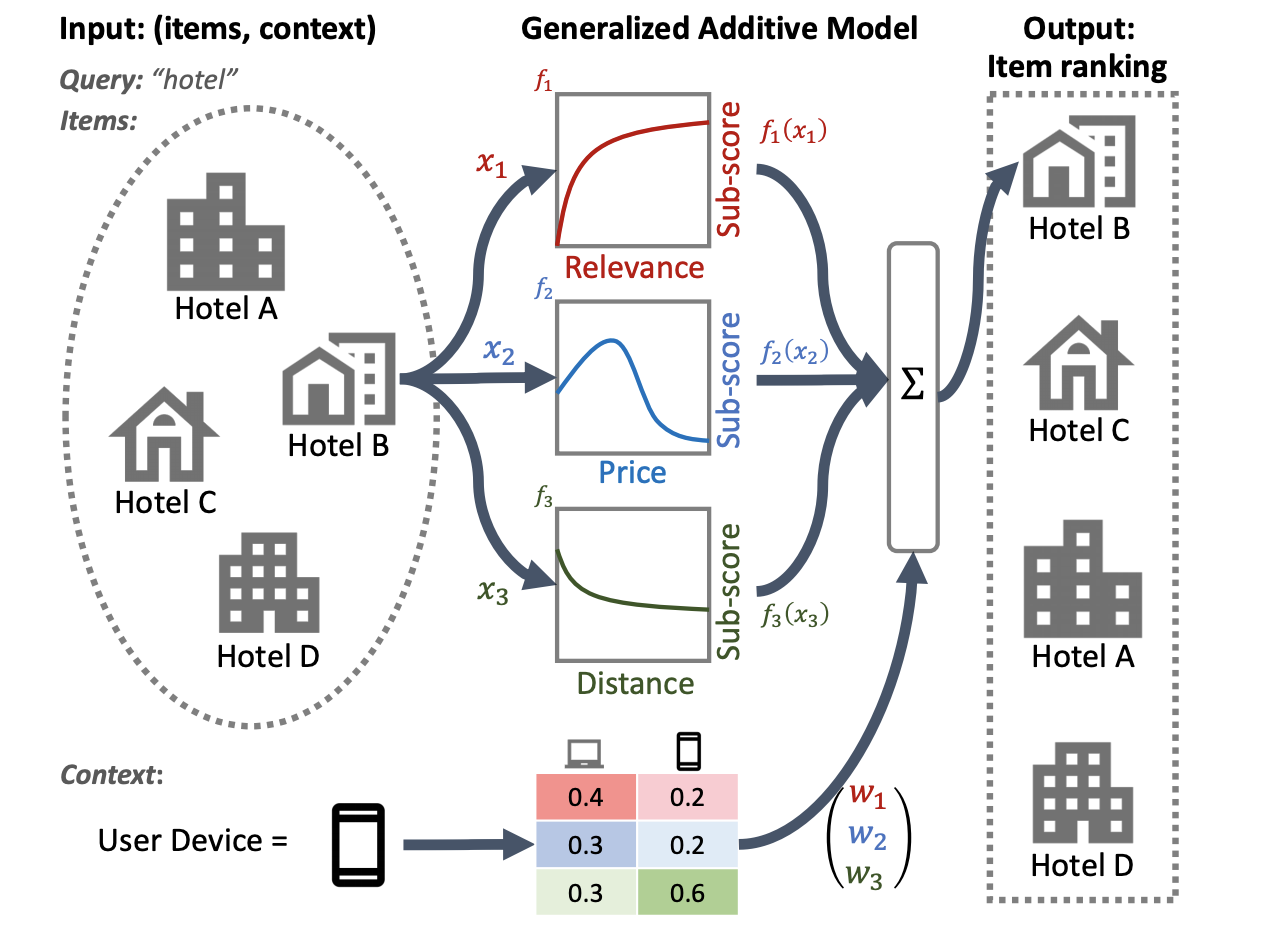
למידע נוסף על שימוש ב-GAMs עם מודלים של דירוג, עיין במחקר הקשור. אתה יכול להתחיל עם יישום לדוגמה של טכניקה זו בקוד לדוגמה של TensorFlow Ranking.
תמיכה בדירוג מבוזר
TensorFlow Ranking מיועד לבניית מערכות דירוג בקנה מידה גדול מקצה לקצה: כולל עיבוד נתונים, בניית מודלים, הערכה ופריסה של ייצור. הוא יכול להתמודד עם תכונות הטרוגניות צפופות ודלילות, להגדיל עד מיליוני נקודות נתונים, ונועד לתמוך בהדרכה מבוזרת עבור יישומי דירוג בקנה מידה גדול.
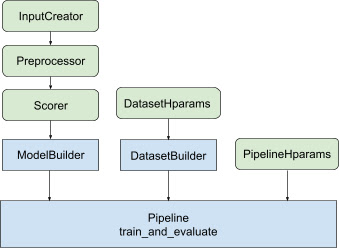
הספרייה מספקת ארכיטקטורת צינור דירוג אופטימלית, כדי למנוע קוד חוזר ונשנה וליצור פתרונות מבוזרים שניתן ליישם מהכשרת מודל הדירוג שלך ועד להגשתו. צינור הדירוג תומך ברוב האסטרטגיות המבוזרות של TensorFlow, כולל MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy ו- ParameterServerStrategy . צינור הדירוג יכול לייצא את מודל הדירוג המאומן בפורמט tf.saved_model , התומך במספר חתימות קלט .. בנוסף, צינור הדירוג מספק התקשרויות שימושיות, כולל תמיכה בהדמיית נתונים של TensorBoard ו- BackupAndRestore כדי לעזור להתאושש מתקלות לאורך זמן. פעולות הדרכה.
ספריית הדירוג מסייעת בבניית יישום הדרכה מבוזר על ידי מתן קבוצה של מחלקות tfr.keras.pipeline , שלוקחות בונה מודלים, בונה נתונים והיפרפרמטרים כקלט. המחלקה tfr.keras.ModelBuilder המבוססת על Keras מאפשרת לך ליצור מודל לעיבוד מבוזר, ועובדת עם מחלקות InputCreator, Preprocessor ו-Scorer הניתנות להרחבה:
שיעורי הצינור של TensorFlow Ranking עובדים גם עם DatasetBuilder כדי להגדיר נתוני אימון, שיכולים לשלב היפרפרמטרים . לבסוף, הצינור עצמו יכול לכלול קבוצה של היפרפרמטרים כאובייקט PipelineHparams .
התחל עם בניית מודלים של דירוג מבוזר באמצעות המדריך לדירוג מבוזר .