
تساعدك مكتبة TensorFlow Ranking على بناء تعلم قابل للتطوير لتصنيف نماذج التعلم الآلي باستخدام أساليب وتقنيات راسخة من الأبحاث الحديثة. يأخذ نموذج التصنيف قائمة بالعناصر المتشابهة، مثل صفحات الويب، ويقوم بإنشاء قائمة محسنة لتلك العناصر، على سبيل المثال، الأكثر صلة بالصفحات الأقل صلة. تعلم كيفية تصنيف النماذج له تطبيقات في البحث، والإجابة على الأسئلة، وأنظمة التوصية، وأنظمة الحوار. يمكنك استخدام هذه المكتبة لتسريع إنشاء نموذج تصنيف لتطبيقك باستخدام Keras API . توفر مكتبة التصنيف أيضًا أدوات مساعدة لسير العمل لتسهيل توسيع نطاق تنفيذ النموذج الخاص بك للعمل بفعالية مع مجموعات البيانات الكبيرة باستخدام استراتيجيات المعالجة الموزعة.
توفر هذه النظرة العامة ملخصًا موجزًا لتطوير التعلم لتصنيف النماذج باستخدام هذه المكتبة، وتقدم بعض التقنيات المتقدمة التي تدعمها المكتبة، وتناقش الأدوات المساعدة لسير العمل المقدمة لدعم المعالجة الموزعة لتطبيقات التصنيف.
تطوير التعلم لتصنيف النماذج
يتبع بناء النموذج باستخدام مكتبة TensorFlow Ranking الخطوات العامة التالية:
- حدد وظيفة التسجيل باستخدام طبقات Keras (
tf.keras.layers) - حدد المقاييس التي تريد استخدامها للتقييم، مثل
tfr.keras.metrics.NDCGMetric - حدد دالة خسارة، مثل
tfr.keras.losses.SoftmaxLoss - قم بتجميع النموذج باستخدام
tf.keras.Model.compile()وقم بتدريبه باستخدام بياناتك
يرشدك البرنامج التعليمي الموصى به للأفلام إلى أساسيات إنشاء نموذج تعلم التصنيف باستخدام هذه المكتبة. راجع قسم دعم التصنيف الموزع لمزيد من المعلومات حول إنشاء نماذج تصنيف واسعة النطاق.
تقنيات التصنيف المتقدمة
توفر مكتبة TensorFlow Ranking الدعم لتطبيق تقنيات التصنيف المتقدمة التي بحثها ونفذها باحثون ومهندسون في Google. توفر الأقسام التالية نظرة عامة على بعض هذه التقنيات وكيفية البدء في استخدامها في تطبيقك.
ترتيب إدخال قائمة BERT
توفر مكتبة التصنيف تطبيقًا لـ TFR-BERT، وهي بنية تسجيل تجمع بين BERT ونمذجة LTR لتحسين ترتيب مدخلات القائمة. كمثال لتطبيق هذا الأسلوب، فكر في استعلام وقائمة بعدد n من المستندات التي تريد تصنيفها استجابةً لهذا الاستعلام. بدلاً من تعلم تمثيل BERT الذي تم تسجيله بشكل مستقل عبر أزواج <query, document> ، تطبق نماذج LTR خسارة التصنيف لتعلم مشترك لتمثيل BERT الذي يزيد من فائدة القائمة المرتبة بأكملها فيما يتعلق بتسميات الحقيقة الأرضية. والشكل التالي يوضح هذه التقنية:
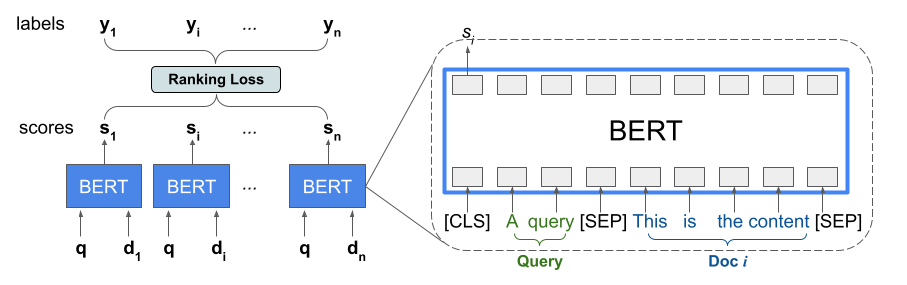
يقوم هذا الأسلوب بتسوية قائمة المستندات التي سيتم ترتيبها استجابة لاستعلام ما في قائمة مجموعات <query, document> . يتم بعد ذلك تغذية هذه الصفوف في نموذج لغة BERT مُدرب مسبقًا. يتم بعد ذلك ضبط مخرجات BERT المجمعة لقائمة المستندات بأكملها بشكل مشترك مع إحدى خسائر التصنيف المتخصصة المتوفرة في تصنيف TensorFlow.
يمكن لهذه البنية أن تقدم تحسينات كبيرة في أداء نموذج اللغة المدرب مسبقًا، مما يؤدي إلى إنتاج أداء متطور للعديد من مهام التصنيف الشائعة، خاصة عند دمج نماذج لغوية متعددة مدربة مسبقًا. لمزيد من المعلومات حول هذه التقنية، راجع الأبحاث ذات الصلة. يمكنك البدء بتنفيذ بسيط في كود مثال TensorFlow Ranking.
التصنيف العصبي النماذج المضافة المعممة (GAM)
بالنسبة لبعض أنظمة التصنيف، مثل تقييم أهلية القروض، أو استهداف الإعلانات، أو التوجيه للعلاج الطبي، تعد الشفافية وقابلية التفسير من الاعتبارات الحاسمة. يمكن أن يساعد تطبيق النماذج المضافة المعممة (GAMs) مع عوامل الترجيح المفهومة جيدًا في جعل نموذج التصنيف الخاص بك أكثر قابلية للتفسير والتفسير.
تمت دراسة GAMs على نطاق واسع باستخدام مهام الانحدار والتصنيف، ولكن ليس من الواضح كيفية تطبيقها على تطبيق التصنيف. على سبيل المثال، في حين يمكن تطبيق GAMs ببساطة لنمذجة كل عنصر على حدة في القائمة، فإن نمذجة تفاعلات العنصر والسياق الذي يتم فيه ترتيب هذه العناصر يمثل مشكلة أكثر صعوبة. يوفر تصنيف TensorFlow تطبيقًا للتصنيف العصبي GAM ، وهو امتداد للنماذج المضافة المعممة المصممة لمشاكل التصنيف. يتيح لك تطبيق TensorFlow Ranking لـ GAMs إضافة وزن محدد لميزات النموذج الخاص بك.
يستخدم الرسم التوضيحي التالي لنظام تصنيف الفنادق الملاءمة والسعر والمسافة كميزات تصنيف أساسية. يطبق هذا النموذج تقنية GAM لوزن هذه الأبعاد بشكل مختلف، بناءً على سياق جهاز المستخدم. على سبيل المثال، إذا جاء الاستعلام من هاتف، فسيتم ترجيح المسافة بشكل أكبر، على افتراض أن المستخدمين يبحثون عن فندق قريب.
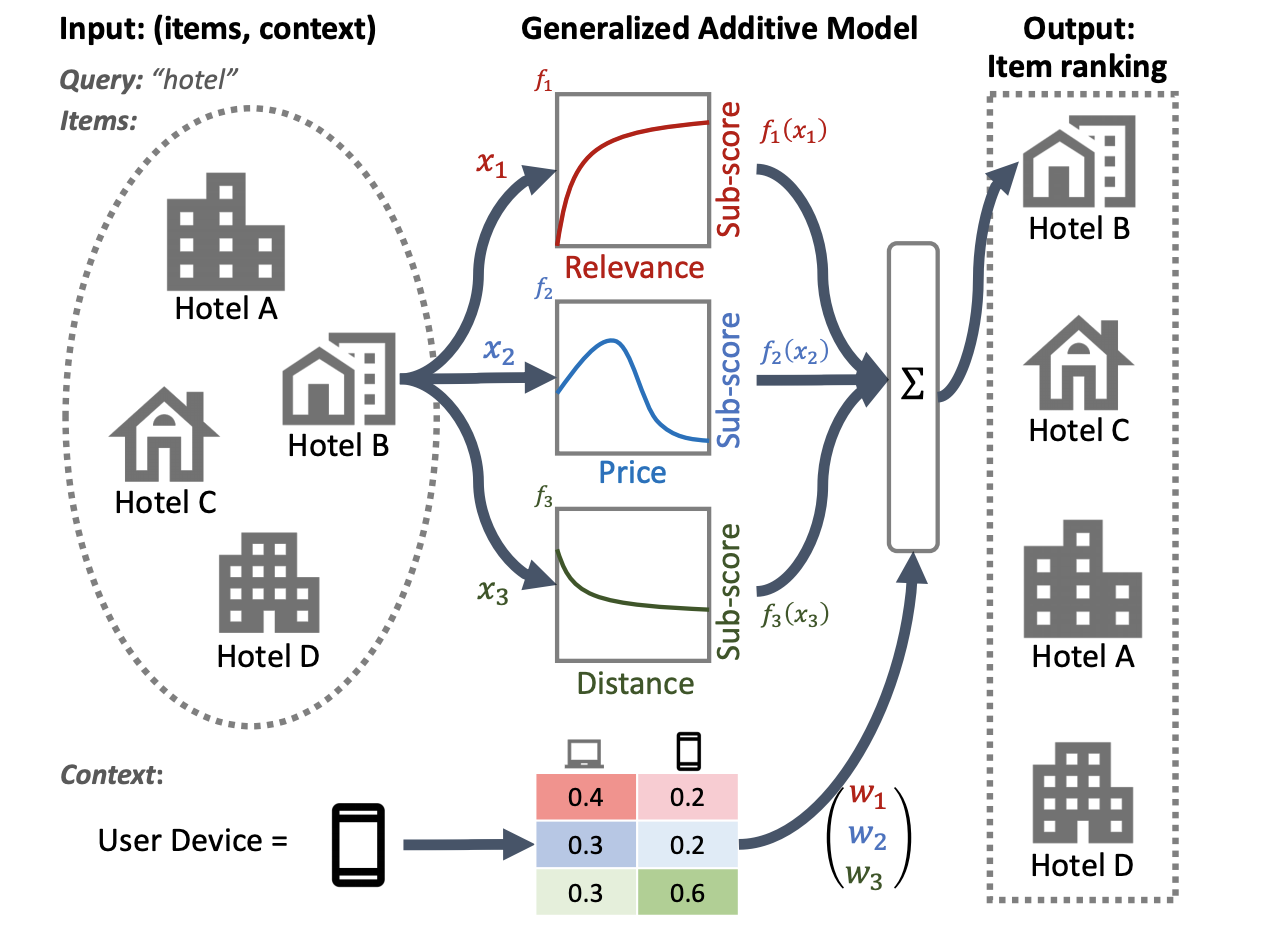
لمزيد من المعلومات حول استخدام GAMs مع نماذج التصنيف، راجع الأبحاث ذات الصلة. يمكنك البدء بتطبيق نموذجي لهذه التقنية في كود مثال TensorFlow Ranking.
دعم الترتيب الموزع
تم تصميم TensorFlow Ranking لبناء أنظمة تصنيف واسعة النطاق شاملة: بما في ذلك معالجة البيانات وبناء النماذج والتقييم ونشر الإنتاج. يمكنه التعامل مع الميزات الكثيفة والمتفرقة غير المتجانسة، وتوسيع نطاقه إلى ملايين نقاط البيانات، وهو مصمم لدعم التدريب الموزع لتطبيقات التصنيف واسعة النطاق.
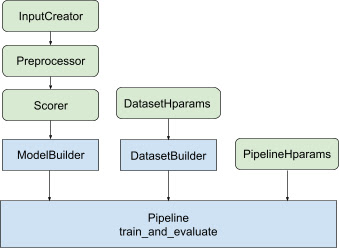
توفر المكتبة بنية محسّنة لخطوط التصنيف، لتجنب التعليمات البرمجية المعيارية المتكررة وإنشاء حلول موزعة يمكن تطبيقها بدءًا من تدريب نموذج التصنيف الخاص بك وحتى تقديمه. يدعم خط أنابيب التصنيف معظم استراتيجيات TensorFlow الموزعة ، بما في ذلك MirroredStrategy و TPUStrategy و MultiWorkerMirroredStrategy و ParameterServerStrategy . يمكن لمسار التصنيف تصدير نموذج التصنيف المُدرب بتنسيق tf.saved_model ، الذي يدعم العديد من توقيعات الإدخال.. بالإضافة إلى ذلك، يوفر مسار التصنيف عمليات رد اتصال مفيدة، بما في ذلك دعم تصور بيانات TensorBoard و BackupAndRestore للمساعدة في التعافي من حالات الفشل في عمليات التشغيل الطويلة عمليات التدريب.
تساعد مكتبة التصنيف في بناء تطبيق تدريبي موزع من خلال توفير مجموعة من فئات tfr.keras.pipeline ، والتي تأخذ منشئ النماذج ومنشئ البيانات والمعلمات الفائقة كمدخلات. تمكنك فئة tfr.keras.ModelBuilder المستندة إلى Keras من إنشاء نموذج للمعالجة الموزعة، وتعمل مع فئات InputCreator وPreprocessor وScorr القابلة للتوسيع:
تعمل فئات مسارات TensorFlow Ranking أيضًا مع DatasetBuilder لإعداد بيانات التدريب، والتي يمكن أن تتضمن معلمات تشعبية . أخيرًا، يمكن أن يتضمن خط الأنابيب نفسه مجموعة من المعلمات الفائقة ككائن PipelineHparams .
ابدأ ببناء نماذج التصنيف الموزعة باستخدام البرنامج التعليمي للتصنيف الموزع .