|
|
|
 View source on GitHub View source on GitHub
|
|
This tutorial implements a simplified Quantum Convolutional Neural Network (QCNN), a proposed quantum analogue to a classical convolutional neural network that is also translationally invariant.
This example demonstrates how to detect certain properties of a quantum data source, such as a quantum sensor or a complex simulation from a device. The quantum data source being a cluster state that may or may not have an excitation—what the QCNN will learn to detect (The dataset used in the paper was SPT phase classification).
Setup
Install TensorFlow and TensorFlow Quantum:
# In Colab, you will be asked to restart the session after this finishes.pip install tensorflow==2.18.1 tensorflow-quantum==0.7.6
Configure the use of Keras 2:
# Keras 2 must be selected before importing TensorFlow or TensorFlow Quantum:
import os
os.environ["TF_USE_LEGACY_KERAS"] = "1"
Now import TensorFlow, TensorFlow Quantum, and other modules needed:
import tensorflow as tf
import tensorflow_quantum as tfq
import cirq
import sympy
import numpy as np
# visualization tools
%matplotlib inline
import matplotlib.pyplot as plt
from cirq.contrib.svg import SVGCircuit
2026-03-03 07:14:25.955508: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered WARNING: All log messages before absl::InitializeLog() is called are written to STDERR E0000 00:00:1772540065.980603 16980 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered E0000 00:00:1772540065.988367 16980 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered 2026-03-03 07:14:30.781959: E external/local_xla/xla/stream_executor/cuda/cuda_driver.cc:152] failed call to cuInit: INTERNAL: CUDA error: Failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
1. Build a QCNN
1.1 Assemble circuits in a TensorFlow graph
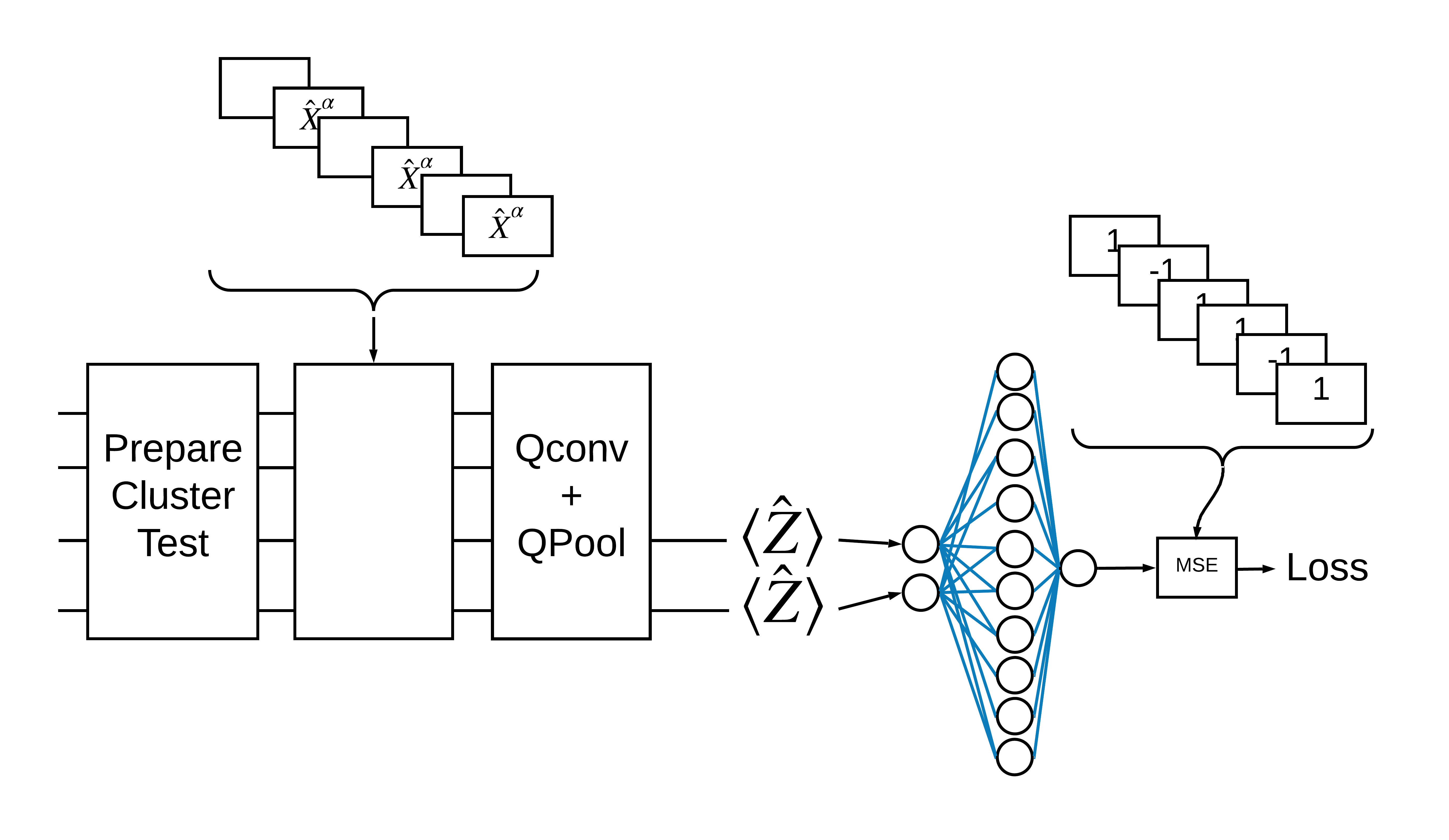
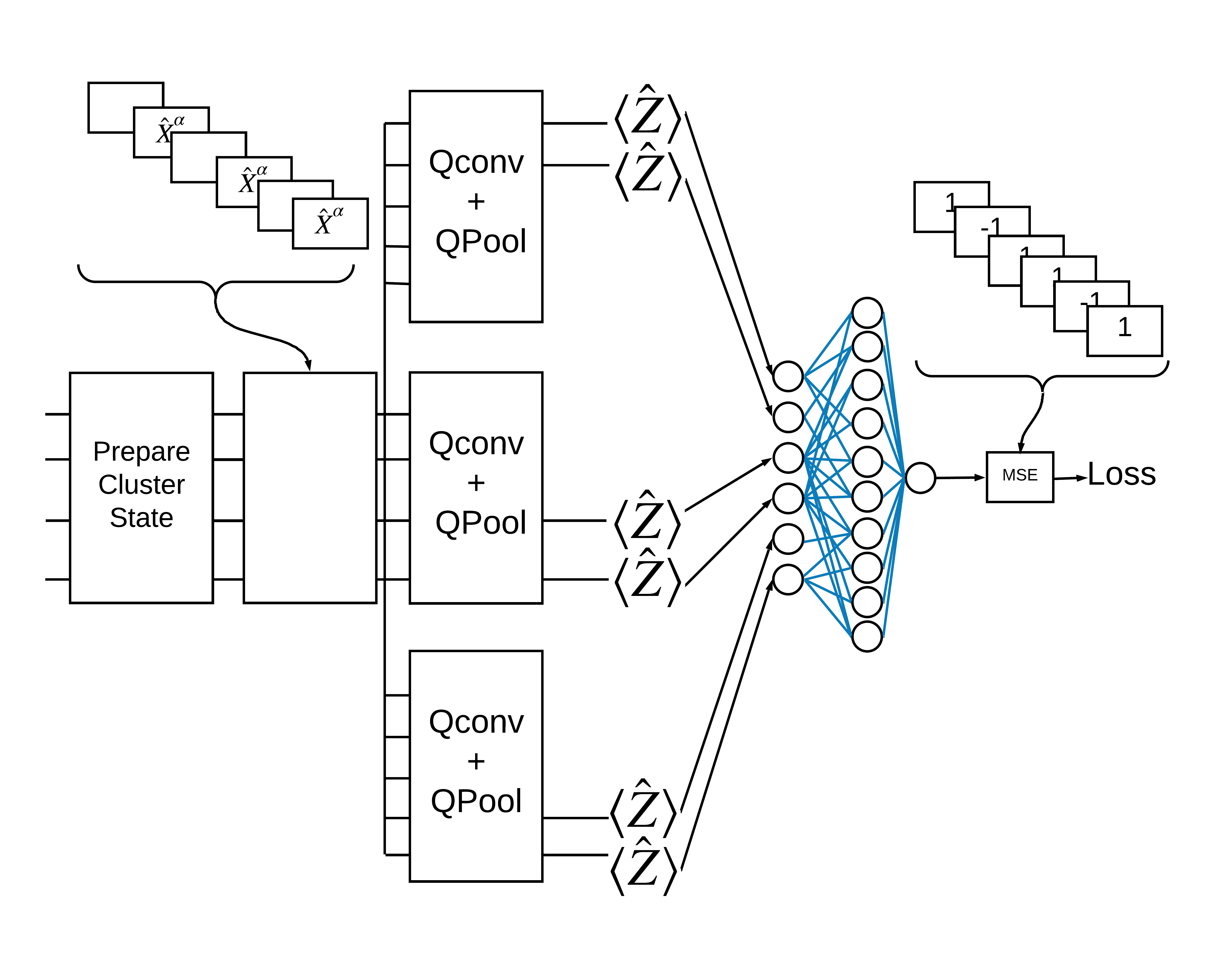
TensorFlow Quantum (TFQ) provides layer classes designed for in-graph circuit construction. One example is the tfq.layers.AddCircuit layer that inherits from tf.keras.Layer. This layer can either prepend or append to the input batch of circuits, as shown in the following figure.
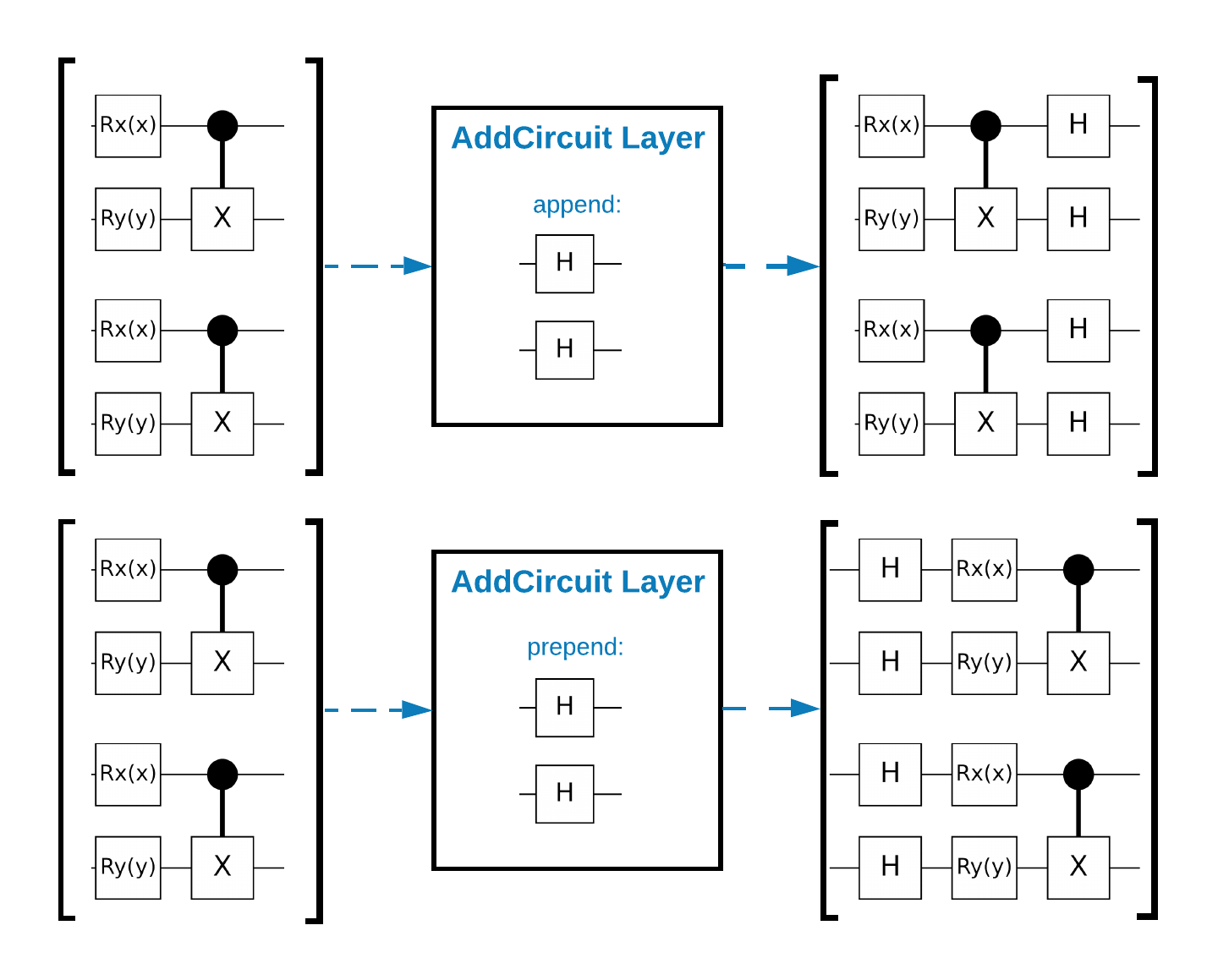
The following snippet uses this layer:
qubit = cirq.GridQubit(0, 0)
# Define some circuits.
circuit1 = cirq.Circuit(cirq.X(qubit))
circuit2 = cirq.Circuit(cirq.H(qubit))
# Convert to a tensor.
input_circuit_tensor = tfq.convert_to_tensor([circuit1, circuit2])
# Define a circuit that we want to append
y_circuit = cirq.Circuit(cirq.Y(qubit))
# Instantiate our layer
y_appender = tfq.layers.AddCircuit()
# Run our circuit tensor through the layer and save the output.
output_circuit_tensor = y_appender(input_circuit_tensor, append=y_circuit)
Examine the input tensor:
print(tfq.from_tensor(input_circuit_tensor))
[cirq.Circuit([
cirq.Moment(
cirq.X(cirq.GridQubit(0, 0)),
),
])
cirq.Circuit([
cirq.Moment(
cirq.H(cirq.GridQubit(0, 0)),
),
]) ]
And examine the output tensor:
print(tfq.from_tensor(output_circuit_tensor))
[cirq.Circuit([
cirq.Moment(
cirq.X(cirq.GridQubit(0, 0)),
),
cirq.Moment(
cirq.Y(cirq.GridQubit(0, 0)),
),
])
cirq.Circuit([
cirq.Moment(
cirq.H(cirq.GridQubit(0, 0)),
),
cirq.Moment(
cirq.Y(cirq.GridQubit(0, 0)),
),
]) ]
While it is possible to run the examples below without using tfq.layers.AddCircuit, it's a good opportunity to understand how complex functionality can be embedded into TensorFlow compute graphs.
1.2 Problem overview
You will prepare a cluster state and train a quantum classifier to detect if it is "excited" or not. The cluster state is highly entangled but not necessarily difficult for a classical computer. For clarity, this is a simpler dataset than the one used in the paper.
For this classification task you will implement a deep MERA-like QCNN architecture since:
- Like the QCNN, the cluster state on a ring is translationally invariant.
- The cluster state is highly entangled.
This architecture should be effective at reducing entanglement, obtaining the classification by reading out a single qubit.
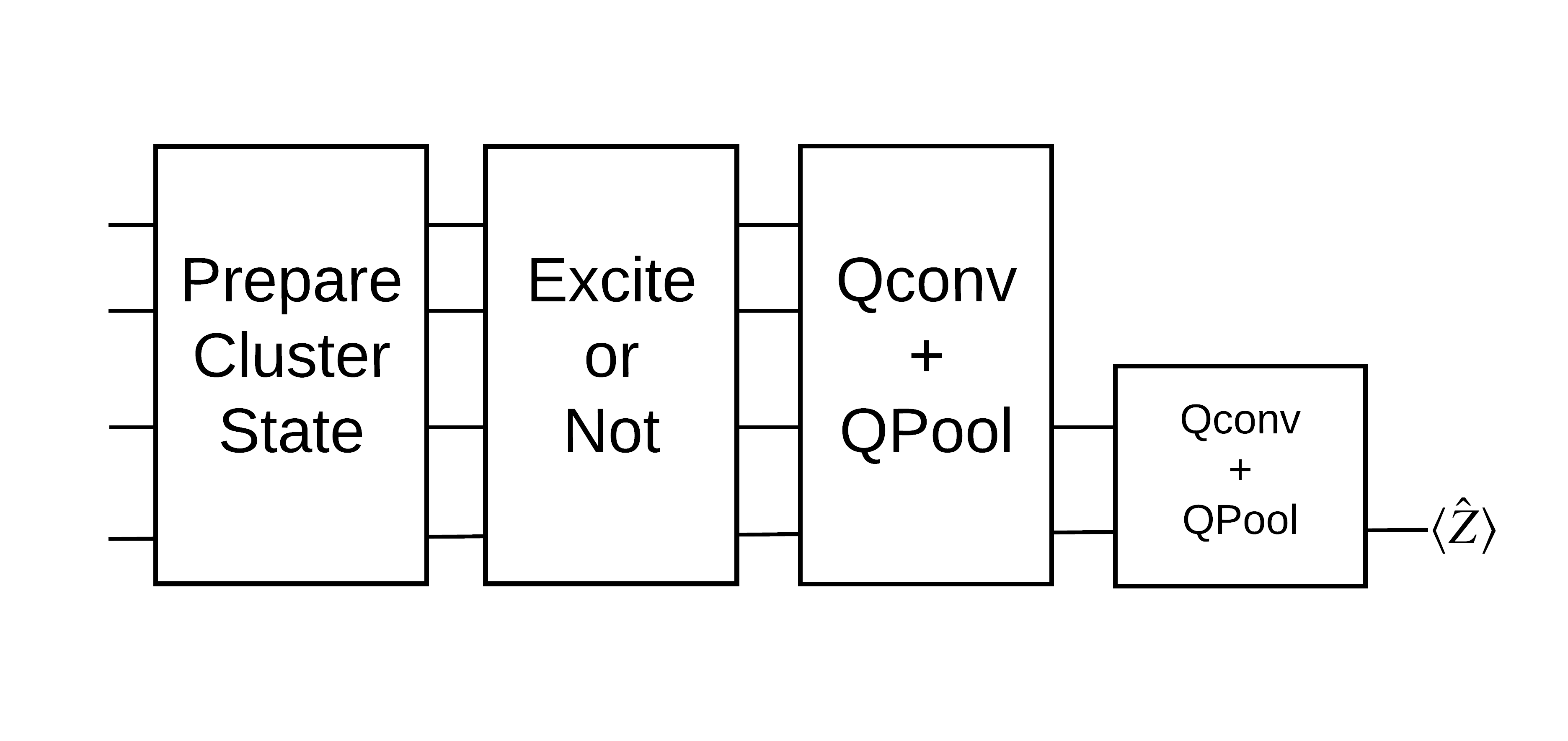
An "excited" cluster state is defined as a cluster state that had a cirq.rx gate applied to any of its qubits. Qconv and QPool are discussed later in this tutorial.
1.3 Building blocks for TensorFlow
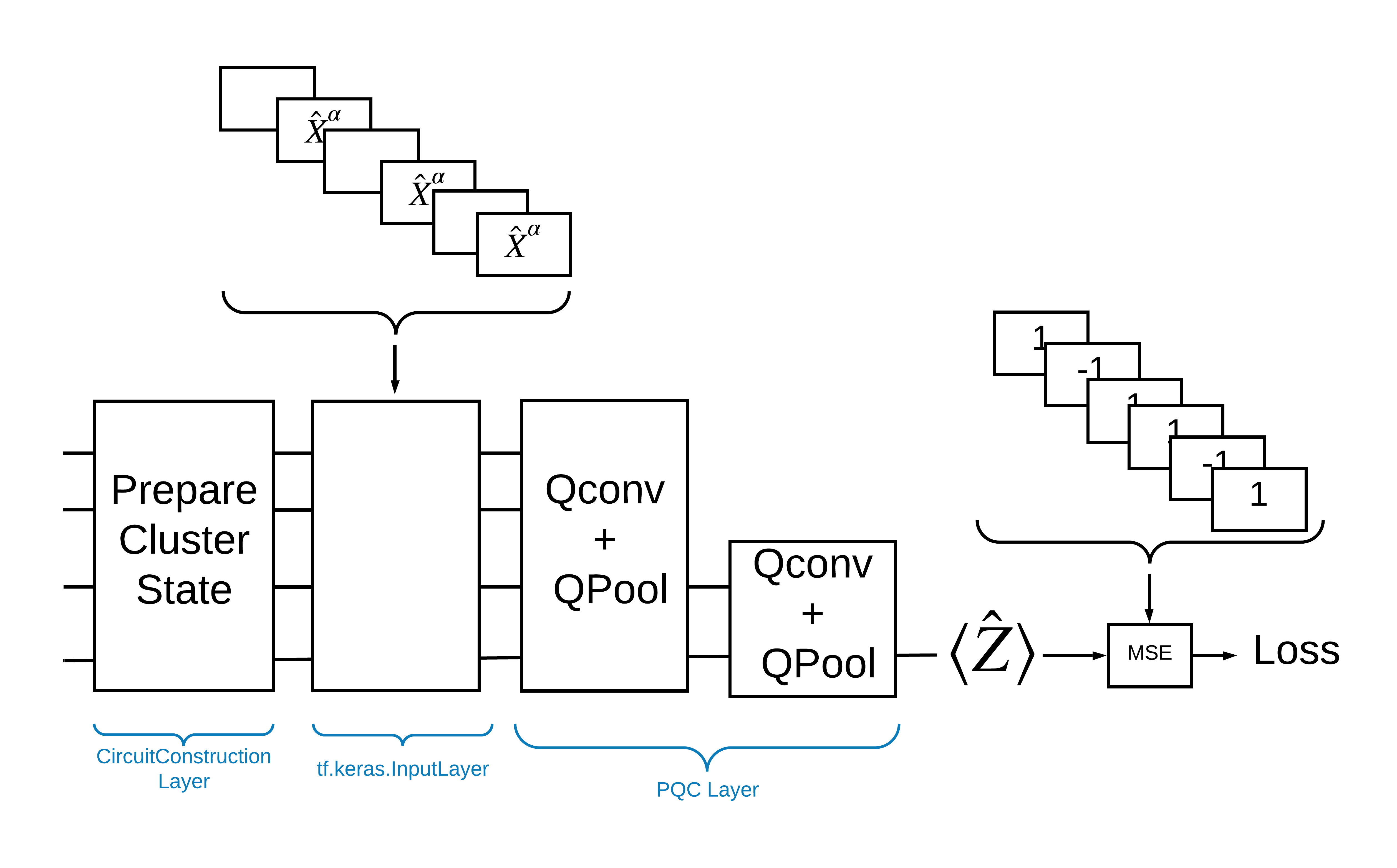
One way to solve this problem with TensorFlow Quantum is to implement the following:
- The input to the model is a circuit tensor—either an empty circuit or an X gate on a particular qubit indicating an excitation.
- The rest of the model's quantum components are constructed with
tfq.layers.AddCircuitlayers. - For inference a
tfq.layers.PQClayer is used. This reads \(\langle \hat{Z} \rangle\) and compares it to a label of 1 for an excited state, or -1 for a non-excited state.
1.4 Data
Before building your model, you can generate your data. In this case it's going to be excitations to the cluster state (The original paper uses a more complicated dataset). Excitations are represented with cirq.rx gates. A large enough rotation is deemed an excitation and is labeled 1 and a rotation that isn't large enough is labeled -1 and deemed not an excitation.
def generate_data(qubits):
"""Generate training and testing data."""
n_rounds = 20 # Produces n_rounds * n_qubits datapoints.
excitations = []
labels = []
for n in range(n_rounds):
for bit in qubits:
rng = np.random.uniform(-np.pi, np.pi)
excitations.append(cirq.Circuit(cirq.rx(rng)(bit)))
labels.append(1 if (-np.pi / 2) <= rng <= (np.pi / 2) else -1)
split_ind = int(len(excitations) * 0.7)
train_excitations = excitations[:split_ind]
test_excitations = excitations[split_ind:]
train_labels = labels[:split_ind]
test_labels = labels[split_ind:]
return tfq.convert_to_tensor(train_excitations), np.array(train_labels), \
tfq.convert_to_tensor(test_excitations), np.array(test_labels)
You can see that just like with regular machine learning you create a training and testing set to use to benchmark the model. You can quickly look at some datapoints with:
sample_points, sample_labels, _, __ = generate_data(cirq.GridQubit.rect(1, 4))
print('Input:', tfq.from_tensor(sample_points)[0], 'Output:', sample_labels[0])
print('Input:', tfq.from_tensor(sample_points)[1], 'Output:', sample_labels[1])
Input: (0, 0): ───X^0.824─── Output: -1 Input: (0, 1): ───X^0.041─── Output: 1
1.5 Define layers
Now define the layers shown in the figure above in TensorFlow.
1.5.1 Cluster state
The first step is to define the cluster state using Cirq, a Google-provided framework for programming quantum circuits. Since this is a static part of the model, embed it using the tfq.layers.AddCircuit functionality.
def cluster_state_circuit(bits):
"""Return a cluster state on the qubits in `bits`."""
circuit = cirq.Circuit()
circuit.append(cirq.H.on_each(bits))
for this_bit, next_bit in zip(bits, bits[1:] + [bits[0]]):
circuit.append(cirq.CZ(this_bit, next_bit))
return circuit
Display a cluster state circuit for a rectangle of cirq.GridQubits:
SVGCircuit(cluster_state_circuit(cirq.GridQubit.rect(1, 4)))

1.5.2 QCNN layers
Define the layers that make up the model using the Cong and Lukin QCNN paper. There are a few prerequisites:
- The one- and two-qubit parameterized unitary matrices from the Tucci paper.
- A general parameterized two-qubit pooling operation.
def one_qubit_unitary(bit, symbols):
"""Make a Cirq circuit enacting a rotation of the bloch sphere about the X,
Y and Z axis, that depends on the values in `symbols`.
"""
return cirq.Circuit(
cirq.X(bit)**symbols[0],
cirq.Y(bit)**symbols[1],
cirq.Z(bit)**symbols[2])
def two_qubit_unitary(bits, symbols):
"""Make a Cirq circuit that creates an arbitrary two qubit unitary."""
circuit = cirq.Circuit()
circuit += one_qubit_unitary(bits[0], symbols[0:3])
circuit += one_qubit_unitary(bits[1], symbols[3:6])
circuit += [cirq.ZZ(*bits)**symbols[6]]
circuit += [cirq.YY(*bits)**symbols[7]]
circuit += [cirq.XX(*bits)**symbols[8]]
circuit += one_qubit_unitary(bits[0], symbols[9:12])
circuit += one_qubit_unitary(bits[1], symbols[12:])
return circuit
def two_qubit_pool(source_qubit, sink_qubit, symbols):
"""Make a Cirq circuit to do a parameterized 'pooling' operation, which
attempts to reduce entanglement down from two qubits to just one."""
pool_circuit = cirq.Circuit()
sink_basis_selector = one_qubit_unitary(sink_qubit, symbols[0:3])
source_basis_selector = one_qubit_unitary(source_qubit, symbols[3:6])
pool_circuit.append(sink_basis_selector)
pool_circuit.append(source_basis_selector)
pool_circuit.append(cirq.CNOT(source_qubit, sink_qubit))
pool_circuit.append(sink_basis_selector**-1)
return pool_circuit
To see what you created, print out the one-qubit unitary circuit:
SVGCircuit(one_qubit_unitary(cirq.GridQubit(0, 0), sympy.symbols('x0:3')))

And the two-qubit unitary circuit:
SVGCircuit(two_qubit_unitary(cirq.GridQubit.rect(1, 2), sympy.symbols('x0:15')))

And the two-qubit pooling circuit:
SVGCircuit(two_qubit_pool(*cirq.GridQubit.rect(1, 2), sympy.symbols('x0:6')))

1.5.2.1 Quantum convolution
As in the Cong and Lukin paper, define the 1D quantum convolution as the application of a two-qubit parameterized unitary to every pair of adjacent qubits with a stride of one.
def quantum_conv_circuit(bits, symbols):
"""Quantum Convolution Layer following the above diagram.
Return a Cirq circuit with the cascade of `two_qubit_unitary` applied
to all pairs of qubits in `bits` as in the diagram above.
"""
circuit = cirq.Circuit()
for first, second in zip(bits[0::2], bits[1::2]):
circuit += two_qubit_unitary([first, second], symbols)
for first, second in zip(bits[1::2], bits[2::2] + [bits[0]]):
circuit += two_qubit_unitary([first, second], symbols)
return circuit
Display the (very horizontal) circuit:
SVGCircuit(
quantum_conv_circuit(cirq.GridQubit.rect(1, 8), sympy.symbols('x0:15')))

1.5.2.2 Quantum pooling
A quantum pooling layer pools from \(N\) qubits to \(\frac{N}{2}\) qubits using the two-qubit pool defined above.
def quantum_pool_circuit(source_bits, sink_bits, symbols):
"""A layer that specifies a quantum pooling operation.
A Quantum pool tries to learn to pool the relevant information from two
qubits onto 1.
"""
circuit = cirq.Circuit()
for source, sink in zip(source_bits, sink_bits):
circuit += two_qubit_pool(source, sink, symbols)
return circuit
Examine a pooling component circuit:
test_bits = cirq.GridQubit.rect(1, 8)
SVGCircuit(
quantum_pool_circuit(test_bits[:4], test_bits[4:], sympy.symbols('x0:6')))

1.6 Model definition
Now use the defined layers to construct a purely quantum CNN. Start with eight qubits, pool down to one, then measure \(\langle \hat{Z} \rangle\).
def create_model_circuit(qubits):
"""Create sequence of alternating convolution and pooling operators
which gradually shrink over time."""
model_circuit = cirq.Circuit()
symbols = sympy.symbols('qconv0:63')
# Cirq uses sympy.Symbols to map learnable variables. TensorFlow Quantum
# scans incoming circuits and replaces these with TensorFlow variables.
model_circuit += quantum_conv_circuit(qubits, symbols[0:15])
model_circuit += quantum_pool_circuit(qubits[:4], qubits[4:],
symbols[15:21])
model_circuit += quantum_conv_circuit(qubits[4:], symbols[21:36])
model_circuit += quantum_pool_circuit(qubits[4:6], qubits[6:],
symbols[36:42])
model_circuit += quantum_conv_circuit(qubits[6:], symbols[42:57])
model_circuit += quantum_pool_circuit([qubits[6]], [qubits[7]],
symbols[57:63])
return model_circuit
# Create our qubits and readout operators in Cirq.
cluster_state_bits = cirq.GridQubit.rect(1, 8)
readout_operators = cirq.Z(cluster_state_bits[-1])
# Build a sequential model enacting the logic in 1.3 of this notebook.
# Here you are making the static cluster state prep as a part of the AddCircuit and the
# "quantum datapoints" are coming in the form of excitation
excitation_input = tf.keras.Input(shape=(), dtype=tf.dtypes.string)
cluster_state = tfq.layers.AddCircuit()(
excitation_input, prepend=cluster_state_circuit(cluster_state_bits))
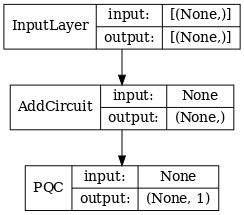
quantum_model = tfq.layers.PQC(create_model_circuit(cluster_state_bits),
readout_operators)(cluster_state)
qcnn_model = tf.keras.Model(inputs=[excitation_input], outputs=[quantum_model])
# Show the keras plot of the model
tf.keras.utils.plot_model(qcnn_model,
show_shapes=True,
show_layer_names=False,
dpi=70)
1.7 Train the model
Train the model over the full batch to simplify this example.
# Generate some training data.
train_excitations, train_labels, test_excitations, test_labels = generate_data(
cluster_state_bits)
# Custom accuracy metric.
@tf.function
def custom_accuracy(y_true, y_pred):
y_true = tf.squeeze(y_true)
y_pred = tf.map_fn(lambda x: 1.0 if x >= 0 else -1.0, y_pred)
return tf.keras.backend.mean(tf.keras.backend.equal(y_true, y_pred))
qcnn_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.02),
loss=tf.losses.mse,
metrics=[custom_accuracy])
history = qcnn_model.fit(x=train_excitations,
y=train_labels,
batch_size=16,
epochs=25,
verbose=1,
validation_data=(test_excitations, test_labels))
Epoch 1/25 7/7 [==============================] - 2s 150ms/step - loss: 0.8610 - custom_accuracy: 0.7589 - val_loss: 0.7861 - val_custom_accuracy: 0.7500 Epoch 2/25 7/7 [==============================] - 1s 113ms/step - loss: 0.7791 - custom_accuracy: 0.6964 - val_loss: 0.6988 - val_custom_accuracy: 0.7917 Epoch 3/25 7/7 [==============================] - 1s 111ms/step - loss: 0.7671 - custom_accuracy: 0.7411 - val_loss: 0.7188 - val_custom_accuracy: 0.7708 Epoch 4/25 7/7 [==============================] - 1s 111ms/step - loss: 0.7231 - custom_accuracy: 0.7500 - val_loss: 0.6550 - val_custom_accuracy: 0.7917 Epoch 5/25 7/7 [==============================] - 1s 112ms/step - loss: 0.6706 - custom_accuracy: 0.8036 - val_loss: 0.6163 - val_custom_accuracy: 0.7917 Epoch 6/25 7/7 [==============================] - 1s 109ms/step - loss: 0.6147 - custom_accuracy: 0.7946 - val_loss: 0.5437 - val_custom_accuracy: 0.7917 Epoch 7/25 7/7 [==============================] - 1s 112ms/step - loss: 0.5385 - custom_accuracy: 0.7946 - val_loss: 0.4495 - val_custom_accuracy: 0.8750 Epoch 8/25 7/7 [==============================] - 1s 113ms/step - loss: 0.5145 - custom_accuracy: 0.8482 - val_loss: 0.5220 - val_custom_accuracy: 0.8750 Epoch 9/25 7/7 [==============================] - 1s 113ms/step - loss: 0.5014 - custom_accuracy: 0.9018 - val_loss: 0.4995 - val_custom_accuracy: 0.8750 Epoch 10/25 7/7 [==============================] - 1s 112ms/step - loss: 0.4955 - custom_accuracy: 0.8750 - val_loss: 0.4738 - val_custom_accuracy: 0.8542 Epoch 11/25 7/7 [==============================] - 1s 110ms/step - loss: 0.4783 - custom_accuracy: 0.8304 - val_loss: 0.3910 - val_custom_accuracy: 0.9375 Epoch 12/25 7/7 [==============================] - 1s 114ms/step - loss: 0.4375 - custom_accuracy: 0.8661 - val_loss: 0.3787 - val_custom_accuracy: 0.9375 Epoch 13/25 7/7 [==============================] - 1s 112ms/step - loss: 0.4023 - custom_accuracy: 0.9286 - val_loss: 0.3310 - val_custom_accuracy: 0.9167 Epoch 14/25 7/7 [==============================] - 1s 111ms/step - loss: 0.3639 - custom_accuracy: 0.9375 - val_loss: 0.2914 - val_custom_accuracy: 0.9583 Epoch 15/25 7/7 [==============================] - 1s 110ms/step - loss: 0.3485 - custom_accuracy: 0.9554 - val_loss: 0.3086 - val_custom_accuracy: 0.9167 Epoch 16/25 7/7 [==============================] - 1s 112ms/step - loss: 0.3354 - custom_accuracy: 0.9464 - val_loss: 0.2927 - val_custom_accuracy: 0.9375 Epoch 17/25 7/7 [==============================] - 1s 110ms/step - loss: 0.3173 - custom_accuracy: 0.9821 - val_loss: 0.2651 - val_custom_accuracy: 0.9375 Epoch 18/25 7/7 [==============================] - 1s 112ms/step - loss: 0.3114 - custom_accuracy: 0.9821 - val_loss: 0.2575 - val_custom_accuracy: 0.9375 Epoch 19/25 7/7 [==============================] - 1s 122ms/step - loss: 0.3035 - custom_accuracy: 0.9732 - val_loss: 0.2550 - val_custom_accuracy: 0.9375 Epoch 20/25 7/7 [==============================] - 1s 110ms/step - loss: 0.2986 - custom_accuracy: 0.9821 - val_loss: 0.2485 - val_custom_accuracy: 0.9375 Epoch 21/25 7/7 [==============================] - 1s 112ms/step - loss: 0.2984 - custom_accuracy: 0.9911 - val_loss: 0.2366 - val_custom_accuracy: 0.9583 Epoch 22/25 7/7 [==============================] - 1s 110ms/step - loss: 0.2841 - custom_accuracy: 0.9821 - val_loss: 0.2248 - val_custom_accuracy: 0.9583 Epoch 23/25 7/7 [==============================] - 1s 111ms/step - loss: 0.2700 - custom_accuracy: 0.9911 - val_loss: 0.1964 - val_custom_accuracy: 0.9792 Epoch 24/25 7/7 [==============================] - 1s 111ms/step - loss: 0.2609 - custom_accuracy: 1.0000 - val_loss: 0.1742 - val_custom_accuracy: 0.9792 Epoch 25/25 7/7 [==============================] - 1s 112ms/step - loss: 0.2528 - custom_accuracy: 1.0000 - val_loss: 0.1705 - val_custom_accuracy: 0.9792
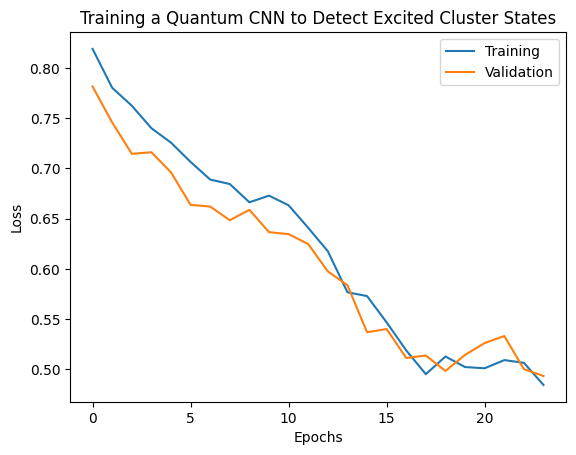
plt.plot(history.history['loss'][1:], label='Training')
plt.plot(history.history['val_loss'][1:], label='Validation')
plt.title('Training a Quantum CNN to Detect Excited Cluster States')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
2. Hybrid models
You don't have to go from eight qubits to one qubit using quantum convolution—you could have done one or two rounds of quantum convolution and fed the results into a classical neural network. This section explores quantum-classical hybrid models.
2.1 Hybrid model with a single quantum filter
Apply one layer of quantum convolution, reading out \(\langle \hat{Z}_n \rangle\) on all bits, followed by a densely-connected neural network.
2.1.1 Model definition
# 1-local operators to read out
readouts = [cirq.Z(bit) for bit in cluster_state_bits[4:]]
def multi_readout_model_circuit(qubits):
"""Make a model circuit with less quantum pool and conv operations."""
model_circuit = cirq.Circuit()
symbols = sympy.symbols('qconv0:21')
model_circuit += quantum_conv_circuit(qubits, symbols[0:15])
model_circuit += quantum_pool_circuit(qubits[:4], qubits[4:],
symbols[15:21])
return model_circuit
# Build a model enacting the logic in 2.1 of this notebook.
excitation_input_dual = tf.keras.Input(shape=(), dtype=tf.dtypes.string)
cluster_state_dual = tfq.layers.AddCircuit()(
excitation_input_dual, prepend=cluster_state_circuit(cluster_state_bits))
quantum_model_dual = tfq.layers.PQC(
multi_readout_model_circuit(cluster_state_bits),
readouts)(cluster_state_dual)
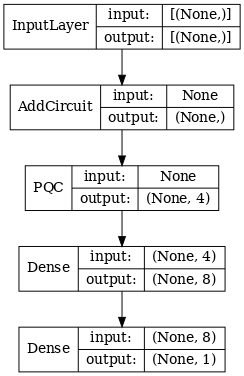
d1_dual = tf.keras.layers.Dense(8)(quantum_model_dual)
d2_dual = tf.keras.layers.Dense(1)(d1_dual)
hybrid_model = tf.keras.Model(inputs=[excitation_input_dual], outputs=[d2_dual])
# Display the model architecture
tf.keras.utils.plot_model(hybrid_model,
show_shapes=True,
show_layer_names=False,
dpi=70)
/tmpfs/src/tf_docs_env/lib/python3.10/site-packages/tf_keras/src/initializers/initializers.py:121: UserWarning: The initializer RandomUniform is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once. warnings.warn(
2.1.2 Train the model
hybrid_model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.02),
loss=tf.losses.mse,
metrics=[custom_accuracy])
hybrid_history = hybrid_model.fit(x=train_excitations,
y=train_labels,
batch_size=16,
epochs=25,
verbose=1,
validation_data=(test_excitations,
test_labels))
Epoch 1/25 7/7 [==============================] - 1s 105ms/step - loss: 1.0445 - custom_accuracy: 0.5268 - val_loss: 0.9631 - val_custom_accuracy: 0.5833 Epoch 2/25 7/7 [==============================] - 0s 71ms/step - loss: 0.9707 - custom_accuracy: 0.5714 - val_loss: 0.9334 - val_custom_accuracy: 0.5625 Epoch 3/25 7/7 [==============================] - 0s 69ms/step - loss: 0.8755 - custom_accuracy: 0.6518 - val_loss: 0.8426 - val_custom_accuracy: 0.7500 Epoch 4/25 7/7 [==============================] - 0s 69ms/step - loss: 0.7335 - custom_accuracy: 0.8036 - val_loss: 0.6234 - val_custom_accuracy: 0.7917 Epoch 5/25 7/7 [==============================] - 0s 69ms/step - loss: 0.5558 - custom_accuracy: 0.8393 - val_loss: 0.3892 - val_custom_accuracy: 0.9167 Epoch 6/25 7/7 [==============================] - 0s 68ms/step - loss: 0.3316 - custom_accuracy: 0.9286 - val_loss: 0.2162 - val_custom_accuracy: 0.9583 Epoch 7/25 7/7 [==============================] - 0s 67ms/step - loss: 0.2798 - custom_accuracy: 0.9732 - val_loss: 0.2009 - val_custom_accuracy: 0.9583 Epoch 8/25 7/7 [==============================] - 0s 68ms/step - loss: 0.2840 - custom_accuracy: 0.9464 - val_loss: 0.2198 - val_custom_accuracy: 0.9583 Epoch 9/25 7/7 [==============================] - 0s 69ms/step - loss: 0.2447 - custom_accuracy: 0.9554 - val_loss: 0.2661 - val_custom_accuracy: 0.9167 Epoch 10/25 7/7 [==============================] - 0s 68ms/step - loss: 0.2550 - custom_accuracy: 0.9554 - val_loss: 0.1435 - val_custom_accuracy: 0.9792 Epoch 11/25 7/7 [==============================] - 0s 68ms/step - loss: 0.2123 - custom_accuracy: 0.9911 - val_loss: 0.2661 - val_custom_accuracy: 0.9792 Epoch 12/25 7/7 [==============================] - 0s 70ms/step - loss: 0.2704 - custom_accuracy: 0.9464 - val_loss: 0.2007 - val_custom_accuracy: 0.9583 Epoch 13/25 7/7 [==============================] - 0s 71ms/step - loss: 0.2523 - custom_accuracy: 0.9732 - val_loss: 0.1460 - val_custom_accuracy: 0.9583 Epoch 14/25 7/7 [==============================] - 0s 69ms/step - loss: 0.2072 - custom_accuracy: 0.9643 - val_loss: 0.2074 - val_custom_accuracy: 0.9583 Epoch 15/25 7/7 [==============================] - 0s 67ms/step - loss: 0.2453 - custom_accuracy: 0.9732 - val_loss: 0.1653 - val_custom_accuracy: 0.9792 Epoch 16/25 7/7 [==============================] - 0s 70ms/step - loss: 0.2264 - custom_accuracy: 0.9732 - val_loss: 0.2213 - val_custom_accuracy: 0.9375 Epoch 17/25 7/7 [==============================] - 0s 65ms/step - loss: 0.2409 - custom_accuracy: 0.9554 - val_loss: 0.2036 - val_custom_accuracy: 0.9375 Epoch 18/25 7/7 [==============================] - 0s 61ms/step - loss: 0.2079 - custom_accuracy: 0.9732 - val_loss: 0.1518 - val_custom_accuracy: 0.9583 Epoch 19/25 7/7 [==============================] - 0s 60ms/step - loss: 0.1949 - custom_accuracy: 0.9821 - val_loss: 0.1651 - val_custom_accuracy: 0.9583 Epoch 20/25 7/7 [==============================] - 0s 61ms/step - loss: 0.1843 - custom_accuracy: 0.9821 - val_loss: 0.1782 - val_custom_accuracy: 0.9583 Epoch 21/25 7/7 [==============================] - 0s 62ms/step - loss: 0.1938 - custom_accuracy: 0.9821 - val_loss: 0.1989 - val_custom_accuracy: 0.9375 Epoch 22/25 7/7 [==============================] - 0s 61ms/step - loss: 0.2051 - custom_accuracy: 0.9732 - val_loss: 0.1708 - val_custom_accuracy: 0.9583 Epoch 23/25 7/7 [==============================] - 0s 61ms/step - loss: 0.1822 - custom_accuracy: 0.9911 - val_loss: 0.1763 - val_custom_accuracy: 0.9792 Epoch 24/25 7/7 [==============================] - 0s 60ms/step - loss: 0.1916 - custom_accuracy: 0.9911 - val_loss: 0.1654 - val_custom_accuracy: 0.9792 Epoch 25/25 7/7 [==============================] - 0s 60ms/step - loss: 0.1807 - custom_accuracy: 0.9911 - val_loss: 0.1478 - val_custom_accuracy: 0.9792
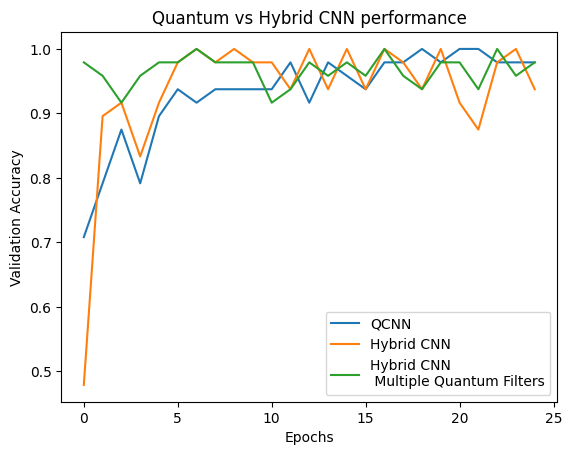
plt.plot(history.history['val_custom_accuracy'], label='QCNN')
plt.plot(hybrid_history.history['val_custom_accuracy'], label='Hybrid CNN')
plt.title('Quantum vs Hybrid CNN performance')
plt.xlabel('Epochs')
plt.legend()
plt.ylabel('Validation Accuracy')
plt.show()
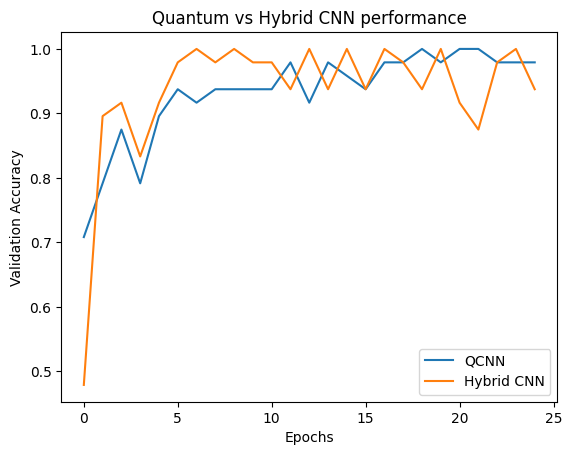
As you can see, with very modest classical assistance, the hybrid model will usually converge faster than the purely quantum version.
2.2 Hybrid convolution with multiple quantum filters
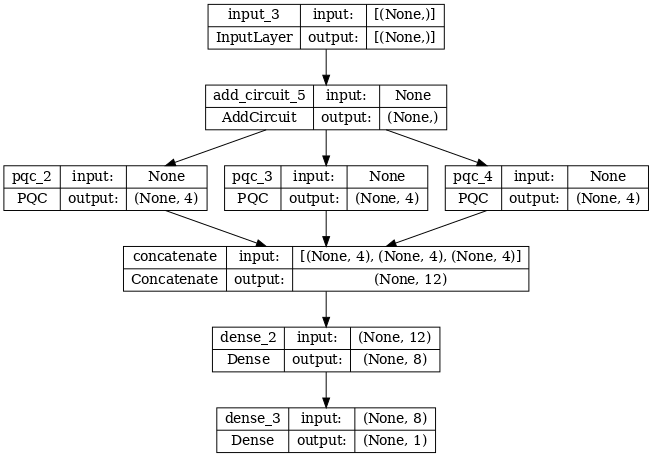
Now let's try an architecture that uses multiple quantum convolutions and a classical neural network to combine them.
2.2.1 Model definition
excitation_input_multi = tf.keras.Input(shape=(), dtype=tf.dtypes.string)
cluster_state_multi = tfq.layers.AddCircuit()(
excitation_input_multi, prepend=cluster_state_circuit(cluster_state_bits))
# apply 3 different filters and measure expectation values
quantum_model_multi1 = tfq.layers.PQC(
multi_readout_model_circuit(cluster_state_bits),
readouts)(cluster_state_multi)
quantum_model_multi2 = tfq.layers.PQC(
multi_readout_model_circuit(cluster_state_bits),
readouts)(cluster_state_multi)
quantum_model_multi3 = tfq.layers.PQC(
multi_readout_model_circuit(cluster_state_bits),
readouts)(cluster_state_multi)
# concatenate outputs and feed into a small classical NN
concat_out = tf.keras.layers.concatenate(
[quantum_model_multi1, quantum_model_multi2, quantum_model_multi3])
dense_1 = tf.keras.layers.Dense(8)(concat_out)
dense_2 = tf.keras.layers.Dense(1)(dense_1)
multi_qconv_model = tf.keras.Model(inputs=[excitation_input_multi],
outputs=[dense_2])
# Display the model architecture
tf.keras.utils.plot_model(multi_qconv_model,
show_shapes=True,
show_layer_names=True,
dpi=70)
/tmpfs/src/tf_docs_env/lib/python3.10/site-packages/tf_keras/src/initializers/initializers.py:121: UserWarning: The initializer RandomUniform is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once. warnings.warn( /tmpfs/src/tf_docs_env/lib/python3.10/site-packages/tf_keras/src/initializers/initializers.py:121: UserWarning: The initializer RandomUniform is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once. warnings.warn( /tmpfs/src/tf_docs_env/lib/python3.10/site-packages/tf_keras/src/initializers/initializers.py:121: UserWarning: The initializer RandomUniform is unseeded and being called multiple times, which will return identical values each time (even if the initializer is unseeded). Please update your code to provide a seed to the initializer, or avoid using the same initializer instance more than once. warnings.warn(
2.2.2 Train the model
multi_qconv_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.02),
loss=tf.losses.mse,
metrics=[custom_accuracy])
multi_qconv_history = multi_qconv_model.fit(x=train_excitations,
y=train_labels,
batch_size=16,
epochs=25,
verbose=1,
validation_data=(test_excitations,
test_labels))
Epoch 1/25 7/7 [==============================] - 2s 148ms/step - loss: 0.8817 - custom_accuracy: 0.5625 - val_loss: 0.6717 - val_custom_accuracy: 0.8750 Epoch 2/25 7/7 [==============================] - 1s 105ms/step - loss: 0.4309 - custom_accuracy: 0.9464 - val_loss: 0.1938 - val_custom_accuracy: 0.9792 Epoch 3/25 7/7 [==============================] - 1s 107ms/step - loss: 0.2514 - custom_accuracy: 0.9643 - val_loss: 0.1728 - val_custom_accuracy: 0.9792 Epoch 4/25 7/7 [==============================] - 1s 106ms/step - loss: 0.2201 - custom_accuracy: 0.9821 - val_loss: 0.1732 - val_custom_accuracy: 0.9792 Epoch 5/25 7/7 [==============================] - 1s 107ms/step - loss: 0.1931 - custom_accuracy: 0.9821 - val_loss: 0.1558 - val_custom_accuracy: 0.9792 Epoch 6/25 7/7 [==============================] - 1s 107ms/step - loss: 0.2350 - custom_accuracy: 0.9821 - val_loss: 0.2079 - val_custom_accuracy: 0.9375 Epoch 7/25 7/7 [==============================] - 1s 103ms/step - loss: 0.2030 - custom_accuracy: 0.9732 - val_loss: 0.1617 - val_custom_accuracy: 0.9583 Epoch 8/25 7/7 [==============================] - 1s 106ms/step - loss: 0.1959 - custom_accuracy: 1.0000 - val_loss: 0.1704 - val_custom_accuracy: 0.9792 Epoch 9/25 7/7 [==============================] - 1s 107ms/step - loss: 0.1985 - custom_accuracy: 0.9821 - val_loss: 0.1504 - val_custom_accuracy: 1.0000 Epoch 10/25 7/7 [==============================] - 1s 105ms/step - loss: 0.1945 - custom_accuracy: 0.9911 - val_loss: 0.1608 - val_custom_accuracy: 0.9792 Epoch 11/25 7/7 [==============================] - 1s 104ms/step - loss: 0.1986 - custom_accuracy: 0.9911 - val_loss: 0.1595 - val_custom_accuracy: 0.9792 Epoch 12/25 7/7 [==============================] - 1s 106ms/step - loss: 0.1906 - custom_accuracy: 0.9911 - val_loss: 0.1604 - val_custom_accuracy: 0.9792 Epoch 13/25 7/7 [==============================] - 1s 104ms/step - loss: 0.1699 - custom_accuracy: 0.9911 - val_loss: 0.1634 - val_custom_accuracy: 0.9792 Epoch 14/25 7/7 [==============================] - 1s 107ms/step - loss: 0.1734 - custom_accuracy: 0.9911 - val_loss: 0.1716 - val_custom_accuracy: 0.9792 Epoch 15/25 7/7 [==============================] - 1s 107ms/step - loss: 0.1819 - custom_accuracy: 0.9911 - val_loss: 0.1640 - val_custom_accuracy: 0.9583 Epoch 16/25 7/7 [==============================] - 1s 105ms/step - loss: 0.1818 - custom_accuracy: 0.9821 - val_loss: 0.1595 - val_custom_accuracy: 0.9792 Epoch 17/25 7/7 [==============================] - 1s 106ms/step - loss: 0.1850 - custom_accuracy: 0.9732 - val_loss: 0.1949 - val_custom_accuracy: 0.9583 Epoch 18/25 7/7 [==============================] - 1s 105ms/step - loss: 0.1896 - custom_accuracy: 1.0000 - val_loss: 0.1836 - val_custom_accuracy: 0.9792 Epoch 19/25 7/7 [==============================] - 1s 106ms/step - loss: 0.1819 - custom_accuracy: 0.9821 - val_loss: 0.1729 - val_custom_accuracy: 0.9583 Epoch 20/25 7/7 [==============================] - 1s 106ms/step - loss: 0.1781 - custom_accuracy: 0.9821 - val_loss: 0.1750 - val_custom_accuracy: 0.9792 Epoch 21/25 7/7 [==============================] - 1s 105ms/step - loss: 0.1798 - custom_accuracy: 1.0000 - val_loss: 0.1692 - val_custom_accuracy: 0.9583 Epoch 22/25 7/7 [==============================] - 1s 105ms/step - loss: 0.1947 - custom_accuracy: 0.9911 - val_loss: 0.1973 - val_custom_accuracy: 0.9792 Epoch 23/25 7/7 [==============================] - 1s 106ms/step - loss: 0.1782 - custom_accuracy: 0.9911 - val_loss: 0.1579 - val_custom_accuracy: 0.9792 Epoch 24/25 7/7 [==============================] - 1s 105ms/step - loss: 0.1812 - custom_accuracy: 0.9732 - val_loss: 0.1614 - val_custom_accuracy: 0.9792 Epoch 25/25 7/7 [==============================] - 1s 106ms/step - loss: 0.1739 - custom_accuracy: 1.0000 - val_loss: 0.1924 - val_custom_accuracy: 0.9792
plt.plot(history.history['val_custom_accuracy'][:25], label='QCNN')
plt.plot(hybrid_history.history['val_custom_accuracy'][:25], label='Hybrid CNN')
plt.plot(multi_qconv_history.history['val_custom_accuracy'][:25],
label='Hybrid CNN \n Multiple Quantum Filters')
plt.title('Quantum vs Hybrid CNN performance')
plt.xlabel('Epochs')
plt.legend()
plt.ylabel('Validation Accuracy')
plt.show()