
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
La inferencia variacional (VI) arroja una inferencia bayesiana aproximada como un problema de optimización y busca una distribución posterior "sustituta" que minimice la divergencia KL con la parte posterior verdadera. El VI basado en gradientes suele ser más rápido que los métodos MCMC, se compone de forma natural con la optimización de los parámetros del modelo y proporciona un límite inferior en la evidencia del modelo que se puede utilizar directamente para la comparación de modelos, el diagnóstico de convergencia y la inferencia componible.
TensorFlow Probability ofrece herramientas para VI rápidos, flexibles y escalables que encajan naturalmente en la pila de TFP. Estas herramientas permiten la construcción de posteriores sustitutos con estructuras de covarianza inducidas por transformaciones lineales o flujos de normalización.
VI puede ser utilizado para estimar bayesianos intervalos de credibilidad para parámetros de un modelo de regresión para estimar los efectos de diversos tratamientos o características observadas en un resultado de interés. Los intervalos creíbles delimitan los valores de un parámetro no observado con una cierta probabilidad, de acuerdo con la distribución posterior del parámetro condicionada a los datos observados y dado un supuesto sobre la distribución previa del parámetro.
En este Colab, demostramos cómo utilizar VI para obtener intervalos de credibilidad para parámetros de un Bayesiano lineales modelo de regresión para los niveles de radón medidos en los hogares (utilizando Gelman et al (2007) Radon conjunto de datos. ; Ver ejemplos similares en Stan). Demostramos cómo PTF JointDistribution s combinan con bijectors para construir y colocar dos tipos de sustitutos posteriores expresivos:
- una distribución Normal estándar transformada por una matriz de bloques. La matriz puede reflejar independencia entre algunos componentes del posterior y dependencia entre otros, relajando la suposición de un posterior de campo medio o de covarianza total.
- una más compleja, de mayor capacidad inversa flujo autorregresivo .
Los posteriores sustitutos se entrenan y comparan con los resultados de una línea de base posterior sustitutiva de campo medio, así como con muestras de verdad del terreno de Hamiltonian Monte Carlo.
Descripción general de la inferencia variacional bayesiana
Supongamos que tenemos el siguiente proceso generativo, donde \(\theta\) representa parámetros aleatorios, \(\omega\) representa parámetros deterministas y los \(x_i\) son características y las \(y_i\) son valores objetivo para \(i=1,\ldots,n\) observó puntos de datos: \ begin {align } & \ theta \ sim r (\ Theta) && \ text {(Prior)} \ & \ text {para} i = 1 \ ldots n: \ nonumber \ & \ quad y_i \ sim p (Y_i | x_i, \ theta , \ omega) && \ text {(Likelihood)} \ end {align}
El VI se caracteriza entonces por: $ \ newcommand {\ E} {\ operatorname {\ mathbb {E}}} \ newcommand {\ K} {\ operatorname {\ mathbb {K}}} \ newcommand {\ defeq} {\ overset {\ tiny \ text {def}} {=}} \ DeclareMathOperator * {\ argmin} {arg \, min} $
\ begin {align} - \ log p ({y_i} _i ^ n | {x_i} _i ^ n, \ omega) y \ defeq - \ log \ int \ textrm {d} \ theta \, r (\ theta) \ prod_i ^ np (y_i | x_i, \ theta, \ omega) && \ text {(Integral realmente difícil)} \ & = - \ log \ int \ textrm {d} \ theta \, q (\ theta) \ frac {1 } {q (\ theta)} r (\ theta) \ prod_i ^ np (y_i | x_i, \ theta, \ omega) && \ text {(Multiplicar por 1)} \ & \ le - \ int \ textrm {d} \ theta \, q (\ theta) \ log \ frac {r (\ theta) \ prod_i ^ np (y_i | x i, \ theta, \ omega)} {q (\ theta)} && \ text {(desigualdad de Jensen )} \ & \ defeq \ E {q (\ Theta)} [- \ log p (y_i | x_i, \ theta, \ omega)] + \ K [q (\ Theta), r (\ theta)] \ & \ defeq \text{expected negative log likelihood"} + \ text {regularizador kl"} \ end {align}
(Técnicamente estamos asumiendo \(q\) es absolutamente continua con respecto a \(r\). Véase también, la desigualdad de Jensen .)
Dado que el límite se cumple para todo q, obviamente es más estrecho para:
\[q^*,w^* = \argmin_{q \in \mathcal{Q},\omega\in\mathbb{R}^d} \left\{ \sum_i^n\E_{q(\Theta)}\left[ -\log p(y_i|x_i,\Theta, \omega) \right] + \K[q(\Theta), r(\Theta)] \right\}\]
En cuanto a terminología, llamamos
- \(q^*\) la "posterior sustituta", y,
- \(\mathcal{Q}\) la "familia sustituta".
\(\omega^*\) representa los valores de máxima verosimilitud de los parámetros deterministas en la pérdida de VI. Ver esta encuesta para obtener más información sobre la inferencia variacional.
Ejemplo: regresión lineal jerárquica bayesiana en mediciones de radón
El radón es un gas radiactivo que ingresa a los hogares a través de puntos de contacto con el suelo. Es un carcinógeno que es la principal causa de cáncer de pulmón en los no fumadores. Los niveles de radón varían mucho de un hogar a otro.
La EPA hizo un estudio de los niveles de radón en 80.000 casas. Dos predictores importantes son:
- Piso en el que se tomó la medición (radón más alto en sótanos)
- Nivel de uranio del condado (correlación positiva con los niveles de radón)
La predicción de los niveles de radón en las casas agrupadas por condado es un problema clásico en el modelado jerárquico bayesiano, introducido por Gelman y Hill (2006) . Construiremos un modelo lineal jerárquico para predecir las mediciones de radón en las casas, en el que la jerarquía es la agrupación de casas por condado. Estamos interesados en intervalos creíbles para el efecto de la ubicación (condado) en el nivel de radón de las casas en Minnesota. Para aislar este efecto, también se incluyen en el modelo los efectos del suelo y el nivel de uranio. Adicionalmente, incorporaremos un efecto contextual correspondiente al piso medio en el que se tomó la medición, por comarca, de modo que si hay variación entre comarcas del piso en el que se tomaron las mediciones, esto no se atribuya al efecto condado.
pip3 install -q tf-nightly tfp-nightly
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_probability as tfp
import warnings
tfd = tfp.distributions
tfb = tfp.bijectors
plt.rcParams['figure.facecolor'] = '1.'
# Load the Radon dataset from `tensorflow_datasets` and filter to data from
# Minnesota.
dataset = tfds.as_numpy(
tfds.load('radon', split='train').filter(
lambda x: x['features']['state'] == 'MN').batch(10**9))
# Dependent variable: Radon measurements by house.
dataset = next(iter(dataset))
radon_measurement = dataset['activity'].astype(np.float32)
radon_measurement[radon_measurement <= 0.] = 0.1
log_radon = np.log(radon_measurement)
# Measured uranium concentrations in surrounding soil.
uranium_measurement = dataset['features']['Uppm'].astype(np.float32)
log_uranium = np.log(uranium_measurement)
# County indicator.
county_strings = dataset['features']['county'].astype('U13')
unique_counties, county = np.unique(county_strings, return_inverse=True)
county = county.astype(np.int32)
num_counties = unique_counties.size
# Floor on which the measurement was taken.
floor_of_house = dataset['features']['floor'].astype(np.int32)
# Average floor by county (contextual effect).
county_mean_floor = []
for i in range(num_counties):
county_mean_floor.append(floor_of_house[county == i].mean())
county_mean_floor = np.array(county_mean_floor, dtype=log_radon.dtype)
floor_by_county = county_mean_floor[county]
El modelo de regresión se especifica de la siguiente manera:
\(\newcommand{\Normal}{\operatorname{\sf Normal} }\)\ begin {align} & \ text {uranium_weight} \ sim \ Normal (0, 1) \ & \ text {county_floor_weight} \ sim \ Normal (0, 1) \ & \ text {for} j = 1 \ ldots \ text {num_counties}: \ & \ quad \ text {condado_effect} _j \ sim \ Normal (0, \ sigma_c) \ & \ text {for} i = 1 \ ldots n: \ & \ quad \ mu_i = (\ y \ quad \ quad \ text {sesgo} \ & \ quad \ quad + \ text {efecto condado} {\ text {condado} _i} \ & \ quad \ quad + \ text {log_uranium} _i \ tiempos \ text {uranium_weight } \ & \ quad \ quad + \ text {floor_of_house} _i \ tiempos \ text {floor_weight} \ & \ quad \ quad + \ text {condado floor_by} {\ text {condado} _i} \ tiempos \ text {county_floor_weight}) \ & \ quad \ text {log_radon} _i \ sim \ normal (\ mu_i, \ sigma_y) \ end {align} en la que \(i\) índices de las observaciones y \(\text{county}_i\) es el condado en el que el \(i\)ésima observación fue tomado.
Usamos un efecto aleatorio a nivel de condado para capturar la variación geográfica. Los parámetros uranium_weight y county_floor_weight se modelan probabilísticamente, y floor_weight y la constante de bias son deterministas. Estas elecciones de modelado son en gran parte arbitrarias y se hacen con el propósito de demostrar VI en un modelo probabilístico de complejidad razonable. Para una discusión más a fondo de los modelos multinivel con efectos fijos y aleatorios en la PTF, utilizando el conjunto de datos radón, ver multinivel de modelado Primer y Montaje lineales generalizados de efectos mixtos modelos usando variacional inferencia .
# Create variables for fixed effects.
floor_weight = tf.Variable(0.)
bias = tf.Variable(0.)
# Variables for scale parameters.
log_radon_scale = tfp.util.TransformedVariable(1., tfb.Exp())
county_effect_scale = tfp.util.TransformedVariable(1., tfb.Exp())
# Define the probabilistic graphical model as a JointDistribution.
@tfd.JointDistributionCoroutineAutoBatched
def model():
uranium_weight = yield tfd.Normal(0., scale=1., name='uranium_weight')
county_floor_weight = yield tfd.Normal(
0., scale=1., name='county_floor_weight')
county_effect = yield tfd.Sample(
tfd.Normal(0., scale=county_effect_scale),
sample_shape=[num_counties], name='county_effect')
yield tfd.Normal(
loc=(log_uranium * uranium_weight + floor_of_house* floor_weight
+ floor_by_county * county_floor_weight
+ tf.gather(county_effect, county, axis=-1)
+ bias),
scale=log_radon_scale[..., tf.newaxis],
name='log_radon')
# Pin the observed `log_radon` values to model the un-normalized posterior.
target_model = model.experimental_pin(log_radon=log_radon)
Posteriores sustitutos expresivos
A continuación, estimamos las distribuciones posteriores de los efectos aleatorios utilizando VI con dos tipos diferentes de posteriores sustitutos:
- Una distribución normal multivariada restringida, con una estructura de covarianza inducida por una transformación matricial en bloques.
- Una distribución normal multivariante estándar transformado por un autorregresivo de flujo inverso , que luego se divide y se reestructuró para que coincida con el apoyo de la parte posterior.
Posterior sustituto normal multivariante
Para construir este posterior sustituto, se utiliza un operador lineal entrenable para inducir la correlación entre los componentes del posterior.
# Determine the `event_shape` of the posterior, and calculate the size of each
# `event_shape` component. These determine the sizes of the components of the
# underlying standard Normal distribution, and the dimensions of the blocks in
# the blockwise matrix transformation.
event_shape = target_model.event_shape_tensor()
flat_event_shape = tf.nest.flatten(event_shape)
flat_event_size = tf.nest.map_structure(tf.reduce_prod, flat_event_shape)
# The `event_space_bijector` maps unconstrained values (in R^n) to the support
# of the prior -- we'll need this at the end to constrain Multivariate Normal
# samples to the prior's support.
event_space_bijector = target_model.experimental_default_event_space_bijector()
Construir un JointDistribution con componentes normal estándar con valores vectoriales, con tamaños determinados por los componentes anteriores correspondientes. Los componentes deben tener valores vectoriales para que el operador lineal pueda transformarlos.
base_standard_dist = tfd.JointDistributionSequential(
[tfd.Sample(tfd.Normal(0., 1.), s) for s in flat_event_size])
Construya un operador lineal triangular inferior en bloque entrenable. Lo aplicaremos a la distribución Normal estándar para implementar una transformación de matriz en bloque (entrenable) e inducir la estructura de correlación de la parte posterior.
Dentro del operador a modo de bloques lineal, un bloque de matriz completa entrenable representa completo covarianza entre dos componentes de la posterior, mientras que un bloque de ceros (o None ) expresa la independencia. Los bloques en la diagonal son matrices triangulares inferiores o diagonales, de modo que toda la estructura de bloques representa una matriz triangular inferior.
La aplicación de este biyector a la distribución base da como resultado una distribución normal multivariante con media 0 y covarianza (factorizada por Cholesky) igual a la matriz de bloques triangular inferior.
operators = (
(tf.linalg.LinearOperatorDiag,), # Variance of uranium weight (scalar).
(tf.linalg.LinearOperatorFullMatrix, # Covariance between uranium and floor-by-county weights.
tf.linalg.LinearOperatorDiag), # Variance of floor-by-county weight (scalar).
(None, # Independence between uranium weight and county effects.
None, # Independence between floor-by-county and county effects.
tf.linalg.LinearOperatorDiag) # Independence among the 85 county effects.
)
block_tril_linop = (
tfp.experimental.vi.util.build_trainable_linear_operator_block(
operators, flat_event_size))
scale_bijector = tfb.ScaleMatvecLinearOperatorBlock(block_tril_linop)
Después de aplicar el operador lineal a la distribución normal estándar, aplique una multiparte Shift bijector para permitir que la media para tomar valores distintos de cero.
loc_bijector = tfb.JointMap(
tf.nest.map_structure(
lambda s: tfb.Shift(
tf.Variable(tf.random.uniform(
(s,), minval=-2., maxval=2., dtype=tf.float32))),
flat_event_size))
La distribución Normal multivariada resultante, obtenida mediante la transformación de la distribución Normal estándar con los biyectores de escala y ubicación, debe reformarse y reestructurarse para que coincida con la anterior y, finalmente, limitarse al soporte de la anterior.
# Reshape each component to match the prior, using a nested structure of
# `Reshape` bijectors wrapped in `JointMap` to form a multipart bijector.
reshape_bijector = tfb.JointMap(
tf.nest.map_structure(tfb.Reshape, flat_event_shape))
# Restructure the flat list of components to match the prior's structure
unflatten_bijector = tfb.Restructure(
tf.nest.pack_sequence_as(
event_shape, range(len(flat_event_shape))))
Ahora, júntelo todo: encadene los biyectores entrenables y aplíquelos a la distribución normal estándar básica para construir el posterior sustituto.
surrogate_posterior = tfd.TransformedDistribution(
base_standard_dist,
bijector = tfb.Chain( # Note that the chained bijectors are applied in reverse order
[
event_space_bijector, # constrain the surrogate to the support of the prior
unflatten_bijector, # pack the reshaped components into the `event_shape` structure of the posterior
reshape_bijector, # reshape the vector-valued components to match the shapes of the posterior components
loc_bijector, # allow for nonzero mean
scale_bijector # apply the block matrix transformation to the standard Normal distribution
]))
Entrene el posterior sustituto normal multivariado.
optimizer = tf.optimizers.Adam(learning_rate=1e-2)
mvn_loss = tfp.vi.fit_surrogate_posterior(
target_model.unnormalized_log_prob,
surrogate_posterior,
optimizer=optimizer,
num_steps=10**4,
sample_size=16,
jit_compile=True)
mvn_samples = surrogate_posterior.sample(1000)
mvn_final_elbo = tf.reduce_mean(
target_model.unnormalized_log_prob(*mvn_samples)
- surrogate_posterior.log_prob(mvn_samples))
print('Multivariate Normal surrogate posterior ELBO: {}'.format(mvn_final_elbo))
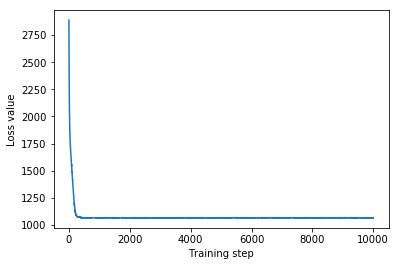
plt.plot(mvn_loss)
plt.xlabel('Training step')
_ = plt.ylabel('Loss value')
Multivariate Normal surrogate posterior ELBO: -1065.705322265625
Dado que la parte posterior sustituta entrenada es una distribución de PTF, podemos tomar muestras de ella y procesarlas para producir intervalos posteriores creíbles para los parámetros.
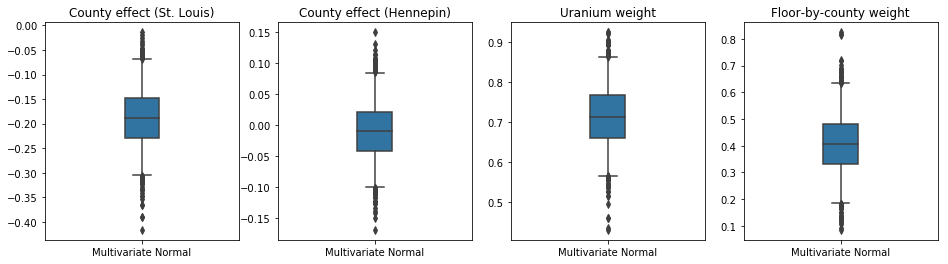
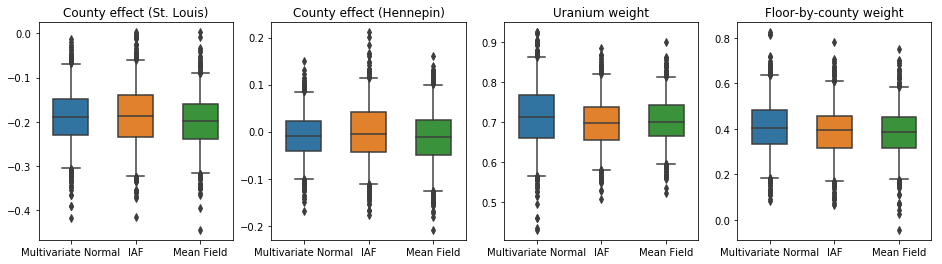
Las parcelas de caja y bigotes a continuación muestran 50% y 95% intervalos de credibilidad para el efecto condado de los dos condados más grandes y los pesos de regresión en las mediciones de uranio del suelo y el piso de media por condado. Los intervalos creíbles posteriores para los efectos del condado indican que la ubicación en el condado de St. Louis está asociada con niveles más bajos de radón, después de considerar otras variables, y que el efecto de la ubicación en el condado de Hennepin es casi neutral.
Los intervalos creíbles posteriores en los pesos de regresión muestran que niveles más altos de uranio en el suelo están asociados con niveles más altos de radón, y los condados donde se tomaron mediciones en pisos más altos (probablemente porque la casa no tenía un sótano) tienden a tener niveles más altos de radón. lo que podría relacionarse con las propiedades del suelo y su efecto sobre el tipo de estructuras construidas.
El coeficiente (determinista) del piso es negativo, lo que indica que los pisos inferiores tienen niveles de radón más altos, como se esperaba.
st_louis_co = 69 # Index of St. Louis, the county with the most observations.
hennepin_co = 25 # Index of Hennepin, with the second-most observations.
def pack_samples(samples):
return {'County effect (St. Louis)': samples.county_effect[..., st_louis_co],
'County effect (Hennepin)': samples.county_effect[..., hennepin_co],
'Uranium weight': samples.uranium_weight,
'Floor-by-county weight': samples.county_floor_weight}
def plot_boxplot(posterior_samples):
fig, axes = plt.subplots(1, 4, figsize=(16, 4))
# Invert the results dict for easier plotting.
k = list(posterior_samples.values())[0].keys()
plot_results = {
v: {p: posterior_samples[p][v] for p in posterior_samples} for v in k}
for i, (var, var_results) in enumerate(plot_results.items()):
sns.boxplot(data=list(var_results.values()), ax=axes[i],
width=0.18*len(var_results), whis=(2.5, 97.5))
# axes[i].boxplot(list(var_results.values()), whis=(2.5, 97.5))
axes[i].title.set_text(var)
fs = 10 if len(var_results) < 4 else 8
axes[i].set_xticklabels(list(var_results.keys()), fontsize=fs)
results = {'Multivariate Normal': pack_samples(mvn_samples)}
print('Bias is: {:.2f}'.format(bias.numpy()))
print('Floor fixed effect is: {:.2f}'.format(floor_weight.numpy()))
plot_boxplot(results)
Bias is: 1.40 Floor fixed effect is: -0.72
Posterior sustituto de flujo autorregresivo inverso
Los flujos autorregresivos inversos (IAF) son flujos de normalización que utilizan redes neuronales para capturar dependencias complejas y no lineales entre los componentes de la distribución. A continuación, construimos un posterior sustituto de IAF para ver si este modelo más fiexible y de mayor capacidad supera al normal multivariante restringido.
# Build a standard Normal with a vector `event_shape`, with length equal to the
# total number of degrees of freedom in the posterior.
base_distribution = tfd.Sample(
tfd.Normal(0., 1.), sample_shape=[tf.reduce_sum(flat_event_size)])
# Apply an IAF to the base distribution.
num_iafs = 2
iaf_bijectors = [
tfb.Invert(tfb.MaskedAutoregressiveFlow(
shift_and_log_scale_fn=tfb.AutoregressiveNetwork(
params=2, hidden_units=[256, 256], activation='relu')))
for _ in range(num_iafs)
]
# Split the base distribution's `event_shape` into components that are equal
# in size to the prior's components.
split = tfb.Split(flat_event_size)
# Chain these bijectors and apply them to the standard Normal base distribution
# to build the surrogate posterior. `event_space_bijector`,
# `unflatten_bijector`, and `reshape_bijector` are the same as in the
# multivariate Normal surrogate posterior.
iaf_surrogate_posterior = tfd.TransformedDistribution(
base_distribution,
bijector=tfb.Chain([
event_space_bijector, # constrain the surrogate to the support of the prior
unflatten_bijector, # pack the reshaped components into the `event_shape` structure of the prior
reshape_bijector, # reshape the vector-valued components to match the shapes of the prior components
split] + # Split the samples into components of the same size as the prior components
iaf_bijectors # Apply a flow model to the Tensor-valued standard Normal distribution
))
Entrene al posterior sustituto de la IAF.
optimizer=tf.optimizers.Adam(learning_rate=1e-2)
iaf_loss = tfp.vi.fit_surrogate_posterior(
target_model.unnormalized_log_prob,
iaf_surrogate_posterior,
optimizer=optimizer,
num_steps=10**4,
sample_size=4,
jit_compile=True)
iaf_samples = iaf_surrogate_posterior.sample(1000)
iaf_final_elbo = tf.reduce_mean(
target_model.unnormalized_log_prob(*iaf_samples)
- iaf_surrogate_posterior.log_prob(iaf_samples))
print('IAF surrogate posterior ELBO: {}'.format(iaf_final_elbo))
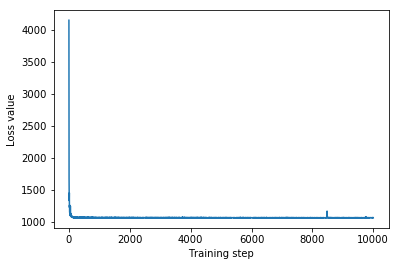
plt.plot(iaf_loss)
plt.xlabel('Training step')
_ = plt.ylabel('Loss value')
IAF surrogate posterior ELBO: -1065.3663330078125
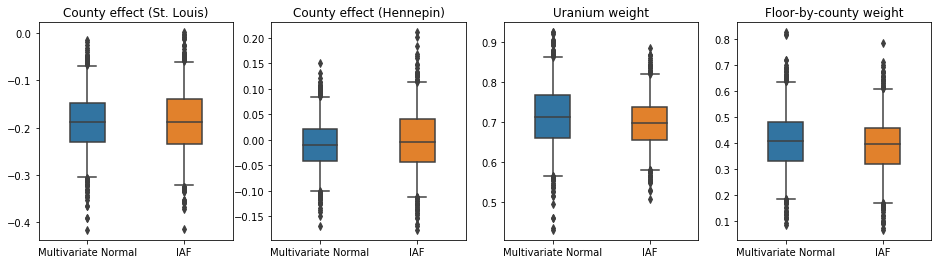
Los intervalos creíbles para el posterior sustituto de la IAF parecen similares a los del Normal multivariante constreñido.
results['IAF'] = pack_samples(iaf_samples)
plot_boxplot(results)
Línea de base: posterior sustituto de campo medio
A menudo se asume que los posteriores sustitutos de VI son distribuciones normales de campo medio (independientes), con medias y varianzas entrenables, que se limitan al apoyo del anterior con una transformación biyectiva. Definimos un posterior sustituto de campo medio además de los dos posteriores sustitutos más expresivos, utilizando la misma fórmula general que el posterior sustituto normal multivariante.
# A block-diagonal linear operator, in which each block is a diagonal operator,
# transforms the standard Normal base distribution to produce a mean-field
# surrogate posterior.
operators = (tf.linalg.LinearOperatorDiag,
tf.linalg.LinearOperatorDiag,
tf.linalg.LinearOperatorDiag)
block_diag_linop = (
tfp.experimental.vi.util.build_trainable_linear_operator_block(
operators, flat_event_size))
mean_field_scale = tfb.ScaleMatvecLinearOperatorBlock(block_diag_linop)
mean_field_loc = tfb.JointMap(
tf.nest.map_structure(
lambda s: tfb.Shift(
tf.Variable(tf.random.uniform(
(s,), minval=-2., maxval=2., dtype=tf.float32))),
flat_event_size))
mean_field_surrogate_posterior = tfd.TransformedDistribution(
base_standard_dist,
bijector = tfb.Chain( # Note that the chained bijectors are applied in reverse order
[
event_space_bijector, # constrain the surrogate to the support of the prior
unflatten_bijector, # pack the reshaped components into the `event_shape` structure of the posterior
reshape_bijector, # reshape the vector-valued components to match the shapes of the posterior components
mean_field_loc, # allow for nonzero mean
mean_field_scale # apply the block matrix transformation to the standard Normal distribution
]))
optimizer=tf.optimizers.Adam(learning_rate=1e-2)
mean_field_loss = tfp.vi.fit_surrogate_posterior(
target_model.unnormalized_log_prob,
mean_field_surrogate_posterior,
optimizer=optimizer,
num_steps=10**4,
sample_size=16,
jit_compile=True)
mean_field_samples = mean_field_surrogate_posterior.sample(1000)
mean_field_final_elbo = tf.reduce_mean(
target_model.unnormalized_log_prob(*mean_field_samples)
- mean_field_surrogate_posterior.log_prob(mean_field_samples))
print('Mean-field surrogate posterior ELBO: {}'.format(mean_field_final_elbo))
plt.plot(mean_field_loss)
plt.xlabel('Training step')
_ = plt.ylabel('Loss value')
Mean-field surrogate posterior ELBO: -1065.7652587890625
En este caso, el posterior sustituto de campo medio da resultados similares a los posteriores sustitutos más expresivos, lo que indica que este modelo más simple puede ser adecuado para la tarea de inferencia.
results['Mean Field'] = pack_samples(mean_field_samples)
plot_boxplot(results)
Verdad del suelo: Hamiltonian Monte Carlo (HMC)
Usamos HMC para generar muestras de "verdad fundamental" a partir del verdadero posterior, para comparar con los resultados de los posteriores sustitutos.
num_chains = 8
num_leapfrog_steps = 3
step_size = 0.4
num_steps=20000
flat_event_shape = tf.nest.flatten(target_model.event_shape)
enum_components = list(range(len(flat_event_shape)))
bijector = tfb.Restructure(
enum_components,
tf.nest.pack_sequence_as(target_model.event_shape, enum_components))(
target_model.experimental_default_event_space_bijector())
current_state = bijector(
tf.nest.map_structure(
lambda e: tf.zeros([num_chains] + list(e), dtype=tf.float32),
target_model.event_shape))
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_model.unnormalized_log_prob,
num_leapfrog_steps=num_leapfrog_steps,
step_size=[tf.fill(s.shape, step_size) for s in current_state])
hmc = tfp.mcmc.TransformedTransitionKernel(
hmc, bijector)
hmc = tfp.mcmc.DualAveragingStepSizeAdaptation(
hmc,
num_adaptation_steps=int(num_steps // 2 * 0.8),
target_accept_prob=0.9)
chain, is_accepted = tf.function(
lambda current_state: tfp.mcmc.sample_chain(
current_state=current_state,
kernel=hmc,
num_results=num_steps // 2,
num_burnin_steps=num_steps // 2,
trace_fn=lambda _, pkr:
(pkr.inner_results.inner_results.is_accepted),
),
autograph=False,
jit_compile=True)(current_state)
accept_rate = tf.reduce_mean(tf.cast(is_accepted, tf.float32))
ess = tf.nest.map_structure(
lambda c: tfp.mcmc.effective_sample_size(
c,
cross_chain_dims=1,
filter_beyond_positive_pairs=True),
chain)
r_hat = tf.nest.map_structure(tfp.mcmc.potential_scale_reduction, chain)
hmc_samples = pack_samples(
tf.nest.pack_sequence_as(target_model.event_shape, chain))
print('Acceptance rate is {}'.format(accept_rate))
Acceptance rate is 0.9008625149726868
Trazar trazos de muestra para comprobar el estado de los resultados de la HMC.
def plot_traces(var_name, samples):
fig, axes = plt.subplots(1, 2, figsize=(14, 1.5), sharex='col', sharey='col')
for chain in range(num_chains):
s = samples.numpy()[:, chain]
axes[0].plot(s, alpha=0.7)
sns.kdeplot(s, ax=axes[1], shade=False)
axes[0].title.set_text("'{}' trace".format(var_name))
axes[1].title.set_text("'{}' distribution".format(var_name))
axes[0].set_xlabel('Iteration')
warnings.filterwarnings('ignore')
for var, var_samples in hmc_samples.items():
plot_traces(var, var_samples)




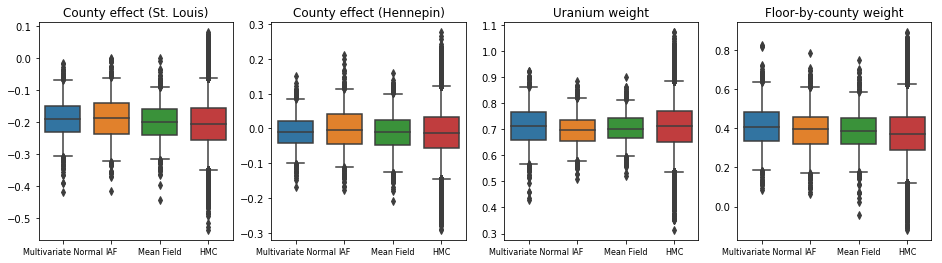
Los tres posteriores sustitutos produjeron intervalos creíbles que son visualmente similares a las muestras de HMC, aunque a veces están poco dispersos debido al efecto de la pérdida de ELBO, como es común en VI.
results['HMC'] = hmc_samples
plot_boxplot(results)
Resultados adicionales
Graficar funciones
plt.rcParams.update({'axes.titlesize': 'medium', 'xtick.labelsize': 'medium'})
def plot_loss_and_elbo():
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].scatter([0, 1, 2],
[mvn_final_elbo.numpy(),
iaf_final_elbo.numpy(),
mean_field_final_elbo.numpy()])
axes[0].set_xticks(ticks=[0, 1, 2])
axes[0].set_xticklabels(labels=[
'Multivariate Normal', 'IAF', 'Mean Field'])
axes[0].title.set_text('Evidence Lower Bound (ELBO)')
axes[1].plot(mvn_loss, label='Multivariate Normal')
axes[1].plot(iaf_loss, label='IAF')
axes[1].plot(mean_field_loss, label='Mean Field')
axes[1].set_ylim([1000, 4000])
axes[1].set_xlabel('Training step')
axes[1].set_ylabel('Loss (negative ELBO)')
axes[1].title.set_text('Loss')
plt.legend()
plt.show()
plt.rcParams.update({'axes.titlesize': 'medium', 'xtick.labelsize': 'small'})
def plot_kdes(num_chains=8):
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
k = list(results.values())[0].keys()
plot_results = {
v: {p: results[p][v] for p in results} for v in k}
for i, (var, var_results) in enumerate(plot_results.items()):
ax = axes[i % 2, i // 2]
for posterior, posterior_results in var_results.items():
if posterior == 'HMC':
label = posterior
for chain in range(num_chains):
sns.kdeplot(
posterior_results[:, chain],
ax=ax, shade=False, color='k', linestyle=':', label=label)
label=None
else:
sns.kdeplot(
posterior_results, ax=ax, shade=False, label=posterior)
ax.title.set_text('{}'.format(var))
ax.legend()
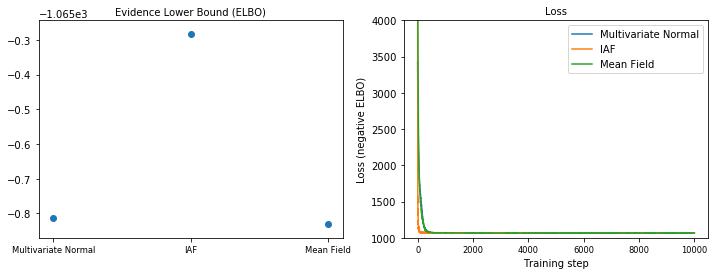
Límite inferior de evidencia (ELBO)
IAF, con mucho el posterior sustituto más grande y flexible, converge con el límite inferior de evidencia más alto (ELBO).
plot_loss_and_elbo()
Muestras posteriores
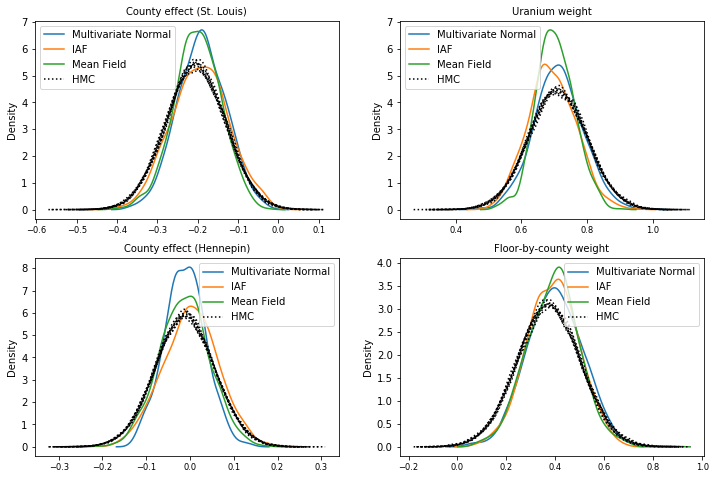
Muestras de cada posterior sustituto, en comparación con muestras de verdad del suelo HMC (una visualización diferente de las muestras que se muestran en los diagramas de caja).
plot_kdes()
Conclusión
En este Colab, construimos VI posteriores sustitutos usando distribuciones conjuntas y biyectores multiparte, y los ajustamos para estimar intervalos creíbles para pesos en un modelo de regresión en el conjunto de datos de radón. Para este modelo simple, los posteriores sustitutos más expresivos se comportaron de manera similar a un posterior sustituto de campo medio. Las herramientas que demostramos, sin embargo, se pueden utilizar para construir una amplia gama de posteriores sustitutos flexibles adecuados para modelos más complejos.