
Ví dụ này được chuyển từ PyMC3 dụ notebook Một Primer về phương pháp Bayes cho đa cấp Modeling
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub |
Phụ thuộc & Điều kiện tiên quyết
Nhập khẩu
import collections
import os
from six.moves import urllib
import daft as daft
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import warnings
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_datasets as tfds
import tensorflow_probability as tfp
tfk = tf.keras
tfkl = tf.keras.layers
tfpl = tfp.layers
tfd = tfp.distributions
tfb = tfp.bijectors
warnings.simplefilter('ignore')
1. Giới thiệu
Trong colab này, chúng tôi sẽ phù hợp với mô hình tuyến tính thứ bậc (HLMs) của mức độ khác nhau của mô hình phức tạp bằng cách sử dụng Radon bộ dữ liệu phổ biến. Chúng tôi sẽ sử dụng các nguyên thủy TFP và bộ công cụ Markov Chain Monte Carlo của nó.
Để phù hợp hơn với dữ liệu, mục tiêu của chúng tôi là sử dụng cấu trúc phân cấp tự nhiên có trong tập dữ liệu. Chúng tôi bắt đầu với các phương pháp tiếp cận thông thường: các mô hình được tổng hợp hoàn toàn và không được chia sẻ. Chúng tôi tiếp tục với các mô hình đa cấp: khám phá các mô hình gộp từng phần, các công cụ dự đoán cấp nhóm và các hiệu ứng theo ngữ cảnh.
Đối với một máy tính xách tay có liên quan cũng phù hợp HLMs sử dụng TFP vào dataset Radon, hãy kiểm tra tuyến tính Mixed-Effect Regression trong {TF Xác suất, R, Stan} .
Nếu bạn có thắc mắc về vật liệu ở đây, đừng ngần ngại liên lạc (hoặc tham gia) trong danh sách gửi thư xác suất TensorFlow . Chúng tôi rất vui khi được trợ giúp.
2 Tổng quan về Mô hình Đa cấp
Sơ lược về các phương pháp Bayesian để tạo mô hình đa cấp
Mô hình phân cấp hoặc đa cấp là một tổng quát của mô hình hồi quy.
Mô hình đa cấp là mô hình hồi quy trong đó các tham số của mô hình cấu thành là các phân phối xác suất. Điều này ngụ ý rằng các thông số mô hình được phép thay đổi theo nhóm. Các đơn vị quan sát thường được nhóm lại một cách tự nhiên. Phân cụm gây ra sự phụ thuộc giữa các quan sát, mặc dù lấy mẫu ngẫu nhiên của các cụm và lấy mẫu ngẫu nhiên trong các cụm.
Mô hình phân cấp là một mô hình đa cấp cụ thể trong đó các tham số được lồng vào nhau. Một số cấu trúc đa cấp không phân cấp.
ví dụ: "quốc gia" và "năm" không được lồng vào nhau, nhưng có thể đại diện cho các cụm tham số riêng biệt, nhưng chồng chéo Chúng tôi sẽ thúc đẩy chủ đề này bằng cách sử dụng một ví dụ dịch tễ học môi trường.
Ví dụ: Ô nhiễm radon (Gelman và Hill 2006)
Radon là một loại khí phóng xạ xâm nhập vào nhà thông qua các điểm tiếp xúc với mặt đất. Nó là một chất gây ung thư là nguyên nhân chính gây ung thư phổi ở những người không hút thuốc. Mức độ radon khác nhau rất nhiều giữa các hộ gia đình.
EPA đã thực hiện một nghiên cứu về mức radon trong 80.000 ngôi nhà. Hai yếu tố dự báo quan trọng là: 1. Phép đo ở tầng hầm hoặc tầng một (radon cao hơn trong tầng hầm) 2. Mức uranium của hạt (tương quan thuận với mức radon)
Chúng tôi sẽ tập trung vào mô hình hóa mức radon ở Minnesota. Hệ thống phân cấp trong ví dụ này là các hộ gia đình trong mỗi quận.
3 Dữ liệu Munging
Trong phần này, chúng tôi có được radon bộ dữ liệu và làm một số tiền xử lý tối thiểu.
def load_and_preprocess_radon_dataset(state='MN'):
"""Preprocess Radon dataset as done in "Bayesian Data Analysis" book.
We filter to Minnesota data (919 examples) and preprocess to obtain the
following features:
- `log_uranium_ppm`: Log of soil uranium measurements.
- `county`: Name of county in which the measurement was taken.
- `floor`: Floor of house (0 for basement, 1 for first floor) on which the
measurement was taken.
The target variable is `log_radon`, the log of the Radon measurement in the
house.
"""
ds = tfds.load('radon', split='train')
radon_data = tfds.as_dataframe(ds)
radon_data.rename(lambda s: s[9:] if s.startswith('feat') else s, axis=1, inplace=True)
df = radon_data[radon_data.state==state.encode()].copy()
# For any missing or invalid activity readings, we'll use a value of `0.1`.
df['radon'] = df.activity.apply(lambda x: x if x > 0. else 0.1)
# Make county names look nice.
df['county'] = df.county.apply(lambda s: s.decode()).str.strip().str.title()
# Remap categories to start from 0 and end at max(category).
county_name = sorted(df.county.unique())
df['county'] = df.county.astype(
pd.api.types.CategoricalDtype(categories=county_name)).cat.codes
county_name = list(map(str.strip, county_name))
df['log_radon'] = df['radon'].apply(np.log)
df['log_uranium_ppm'] = df['Uppm'].apply(np.log)
df = df[['idnum', 'log_radon', 'floor', 'county', 'log_uranium_ppm']]
return df, county_name
radon, county_name = load_and_preprocess_radon_dataset()
num_counties = len(county_name)
num_observations = len(radon)
# Create copies of variables as Tensors.
county = tf.convert_to_tensor(radon['county'], dtype=tf.int32)
floor = tf.convert_to_tensor(radon['floor'], dtype=tf.float32)
log_radon = tf.convert_to_tensor(radon['log_radon'], dtype=tf.float32)
log_uranium = tf.convert_to_tensor(radon['log_uranium_ppm'], dtype=tf.float32)
radon.head()
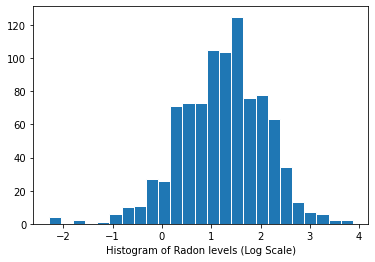
Phân bố các mức radon (thang log):
plt.hist(log_radon.numpy(), bins=25, edgecolor='white')
plt.xlabel("Histogram of Radon levels (Log Scale)")
plt.show()
4 Cách tiếp cận Thông thường
Hai lựa chọn thay thế thông thường để lập mô hình phơi nhiễm radon đại diện cho hai thái cực của sự cân bằng phương sai lệch:
Hoàn thành tổng hợp:
Đối xử với tất cả các hạt như nhau và ước tính một mức radon duy nhất.
\[y_i = \alpha + \beta x_i + \epsilon_i\]
Không gộp chung:
Mô hình radon ở mỗi quận một cách độc lập.
\(y_i = \alpha_{j[i]} + \beta x_i + \epsilon_i\) nơi \(j = 1,\ldots,85\)
Các lỗi \(\epsilon_i\) có thể đại diện cho sai số đo, thời gian dao động trong phạm vi nội bộ, hoặc sự thay đổi giữa nhà.
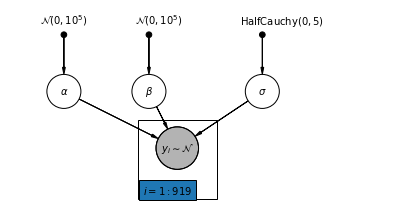
4.1 Mô hình tổng hợp hoàn chỉnh
pgm = daft.PGM([7, 3.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"alpha_prior",
r"$\mathcal{N}(0, 10^5)$",
1,
3,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"beta_prior",
r"$\mathcal{N}(0, 10^5)$",
2.5,
3,
fixed=True,
offset=(10, 5)))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
4.5,
3,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("alpha", r"$\alpha$", 1, 2))
pgm.add_node(daft.Node("beta", r"$\beta$", 2.5, 2))
pgm.add_node(daft.Node("sigma", r"$\sigma$", 4.5, 2))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 3, 1, scale=1.25, observed=True))
pgm.add_edge("alpha_prior", "alpha")
pgm.add_edge("beta_prior", "beta")
pgm.add_edge("sigma_prior", "sigma")
pgm.add_edge("sigma", "y_i")
pgm.add_edge("alpha", "y_i")
pgm.add_edge("beta", "y_i")
pgm.add_plate(daft.Plate([2.3, 0.1, 1.4, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
Dưới đây, chúng tôi phù hợp với mô hình tổng hợp hoàn chỉnh bằng cách sử dụng Hamiltonian Monte Carlo.
@tf.function
def affine(x, kernel_diag, bias=tf.zeros([])):
"""`kernel_diag * x + bias` with broadcasting."""
kernel_diag = tf.ones_like(x) * kernel_diag
bias = tf.ones_like(x) * bias
return x * kernel_diag + bias
def pooled_model(floor):
"""Creates a joint distribution representing our generative process."""
return tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=1e5), # alpha
tfd.Normal(loc=0., scale=1e5), # beta
tfd.HalfCauchy(loc=0., scale=5), # sigma
lambda s, b1, b0: tfd.MultivariateNormalDiag( # y
loc=affine(floor, b1[..., tf.newaxis], b0[..., tf.newaxis]),
scale_identity_multiplier=s)
])
@tf.function
def pooled_log_prob(alpha, beta, sigma):
"""Computes `joint_log_prob` pinned at `log_radon`."""
return pooled_model(floor).log_prob([alpha, beta, sigma, log_radon])
@tf.function
def sample_pooled(num_chains, num_results, num_burnin_steps, num_observations):
"""Samples from the pooled model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=pooled_log_prob,
num_leapfrog_steps=10,
step_size=0.005)
initial_state = [
tf.zeros([num_chains], name='init_alpha'),
tf.zeros([num_chains], name='init_beta'),
tf.ones([num_chains], name='init_sigma')
]
# Constrain `sigma` to the positive real axis. Other variables are
# unconstrained.
unconstraining_bijectors = [
tfb.Identity(), # alpha
tfb.Identity(), # beta
tfb.Exp() # sigma
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
PooledModel = collections.namedtuple('PooledModel', ['alpha', 'beta', 'sigma'])
samples, acceptance_probs = sample_pooled(
num_chains=4,
num_results=1000,
num_burnin_steps=1000,
num_observations=num_observations)
print('Acceptance Probabilities for each chain: ', acceptance_probs.numpy())
pooled_samples = PooledModel._make(samples)
Acceptance Probabilities for each chain: [0.997 0.99 0.997 0.995]
for var, var_samples in pooled_samples._asdict().items():
print('R-hat for ', var, ':\t',
tfp.mcmc.potential_scale_reduction(var_samples).numpy())
R-hat for alpha : 1.0046891 R-hat for beta : 1.0128309 R-hat for sigma : 1.0010641
def reduce_samples(var_samples, reduce_fn):
"""Reduces across leading two dims using reduce_fn."""
# Collapse the first two dimensions, typically (num_chains, num_samples), and
# compute np.mean or np.std along the remaining axis.
if isinstance(var_samples, tf.Tensor):
var_samples = var_samples.numpy() # convert to numpy array
var_samples = np.reshape(var_samples, (-1,) + var_samples.shape[2:])
return np.apply_along_axis(reduce_fn, axis=0, arr=var_samples)
sample_mean = lambda samples : reduce_samples(samples, np.mean)
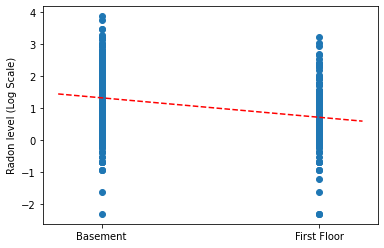
Vẽ đồ thị ước tính điểm của độ dốc và điểm chặn cho mô hình tổng hợp hoàn chỉnh.
LinearEstimates = collections.namedtuple('LinearEstimates',
['intercept', 'slope'])
pooled_estimate = LinearEstimates(
intercept=sample_mean(pooled_samples.alpha),
slope=sample_mean(pooled_samples.beta)
)
plt.scatter(radon.floor, radon.log_radon)
xvals = np.linspace(-0.2, 1.2)
plt.ylabel('Radon level (Log Scale)')
plt.xticks([0, 1], ['Basement', 'First Floor'])
plt.plot(xvals, pooled_estimate.intercept + pooled_estimate.slope * xvals, 'r--')
plt.show()
Hàm tiện ích để vẽ dấu vết của các biến được lấy mẫu.
def plot_traces(var_name, samples, num_chains):
if isinstance(samples, tf.Tensor):
samples = samples.numpy() # convert to numpy array
fig, axes = plt.subplots(1, 2, figsize=(14, 1.5), sharex='col', sharey='col')
for chain in range(num_chains):
axes[0].plot(samples[:, chain], alpha=0.7)
axes[0].title.set_text("'{}' trace".format(var_name))
sns.kdeplot(samples[:, chain], ax=axes[1], shade=False)
axes[1].title.set_text("'{}' distribution".format(var_name))
axes[0].set_xlabel('Iteration')
axes[1].set_xlabel(var_name)
plt.show()
for var, var_samples in pooled_samples._asdict().items():
plot_traces(var, samples=var_samples, num_chains=4)



Tiếp theo, chúng tôi ước tính mức radon cho mỗi quận trong mô hình không chia sẻ.
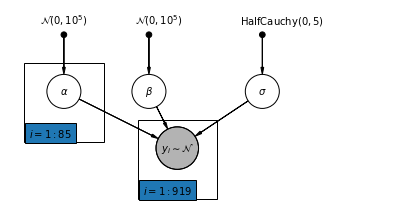
4.2 Mô hình không chia sẻ
pgm = daft.PGM([7, 3.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"alpha_prior",
r"$\mathcal{N}(0, 10^5)$",
1,
3,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"beta_prior",
r"$\mathcal{N}(0, 10^5)$",
2.5,
3,
fixed=True,
offset=(10, 5)))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
4.5,
3,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("alpha", r"$\alpha$", 1, 2))
pgm.add_node(daft.Node("beta", r"$\beta$", 2.5, 2))
pgm.add_node(daft.Node("sigma", r"$\sigma$", 4.5, 2))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 3, 1, scale=1.25, observed=True))
pgm.add_edge("alpha_prior", "alpha")
pgm.add_edge("beta_prior", "beta")
pgm.add_edge("sigma_prior", "sigma")
pgm.add_edge("sigma", "y_i")
pgm.add_edge("alpha", "y_i")
pgm.add_edge("beta", "y_i")
pgm.add_plate(daft.Plate([0.3, 1.1, 1.4, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([2.3, 0.1, 1.4, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
def unpooled_model(floor, county):
"""Creates a joint distribution for the unpooled model."""
return tfd.JointDistributionSequential([
tfd.MultivariateNormalDiag( # alpha
loc=tf.zeros([num_counties]), scale_identity_multiplier=1e5),
tfd.Normal(loc=0., scale=1e5), # beta
tfd.HalfCauchy(loc=0., scale=5), # sigma
lambda s, b1, b0: tfd.MultivariateNormalDiag( # y
loc=affine(
floor, b1[..., tf.newaxis], tf.gather(b0, county, axis=-1)),
scale_identity_multiplier=s)
])
@tf.function
def unpooled_log_prob(beta0, beta1, sigma):
"""Computes `joint_log_prob` pinned at `log_radon`."""
return (
unpooled_model(floor, county).log_prob([beta0, beta1, sigma, log_radon]))
@tf.function
def sample_unpooled(num_chains, num_results, num_burnin_steps):
"""Samples from the unpooled model."""
# Initialize the HMC transition kernel.
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=unpooled_log_prob,
num_leapfrog_steps=10,
step_size=0.025)
initial_state = [
tf.zeros([num_chains, num_counties], name='init_beta0'),
tf.zeros([num_chains], name='init_beta1'),
tf.ones([num_chains], name='init_sigma')
]
# Contrain `sigma` to the positive real axis. Other variables are
# unconstrained.
unconstraining_bijectors = [
tfb.Identity(), # alpha
tfb.Identity(), # beta
tfb.Exp() # sigma
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
UnpooledModel = collections.namedtuple('UnpooledModel',
['alpha', 'beta', 'sigma'])
samples, acceptance_probs = sample_unpooled(
num_chains=4, num_results=1000, num_burnin_steps=1000)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
unpooled_samples = UnpooledModel._make(samples)
print('R-hat for beta:',
tfp.mcmc.potential_scale_reduction(unpooled_samples.beta).numpy())
print('R-hat for sigma:',
tfp.mcmc.potential_scale_reduction(unpooled_samples.sigma).numpy())
Acceptance Probabilities: [0.892 0.897 0.911 0.91 ] R-hat for beta: 1.0079623 R-hat for sigma: 1.0059084
plot_traces(var_name='beta', samples=unpooled_samples.beta, num_chains=4)
plot_traces(var_name='sigma', samples=unpooled_samples.sigma, num_chains=4)


Dưới đây là các giá trị dự kiến của quận không được chia sẻ cho điểm chặn cùng với khoảng thời gian đáng tin cậy 95% cho mỗi chuỗi. Chúng tôi cũng báo cáo giá trị R-hat cho ước tính của mỗi quận.
Chức năng tiện ích cho các lô rừng.
def forest_plot(num_chains, num_vars, var_name, var_labels, samples):
fig, axes = plt.subplots(
1, 2, figsize=(12, 15), sharey=True, gridspec_kw={'width_ratios': [3, 1]})
for var_idx in range(num_vars):
values = samples[..., var_idx]
rhat = tfp.mcmc.diagnostic.potential_scale_reduction(values).numpy()
meds = np.median(values, axis=-2)
los = np.percentile(values, 5, axis=-2)
his = np.percentile(values, 95, axis=-2)
for i in range(num_chains):
height = 0.1 + 0.3 * var_idx + 0.05 * i
axes[0].plot([los[i], his[i]], [height, height], 'C0-', lw=2, alpha=0.5)
axes[0].plot([meds[i]], [height], 'C0o', ms=1.5)
axes[1].plot([rhat], [height], 'C0o', ms=4)
axes[0].set_yticks(np.linspace(0.2, 0.3, num_vars))
axes[0].set_ylim(0, 26)
axes[0].grid(which='both')
axes[0].invert_yaxis()
axes[0].set_yticklabels(var_labels)
axes[0].xaxis.set_label_position('top')
axes[0].set(xlabel='95% Credible Intervals for {}'.format(var_name))
axes[1].set_xticks([1, 2])
axes[1].set_xlim(0.95, 2.05)
axes[1].grid(which='both')
axes[1].set(xlabel='R-hat')
axes[1].xaxis.set_label_position('top')
plt.show()
forest_plot(
num_chains=4,
num_vars=num_counties,
var_name='alpha',
var_labels=county_name,
samples=unpooled_samples.alpha.numpy())

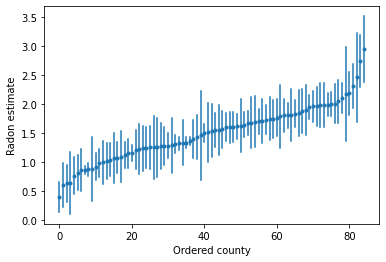
Chúng ta có thể vẽ các ước tính theo thứ tự để xác định các hạt có mức radon cao:
unpooled_intercepts = reduce_samples(unpooled_samples.alpha, np.mean)
unpooled_intercepts_se = reduce_samples(unpooled_samples.alpha, np.std)
def plot_ordered_estimates():
means = pd.Series(unpooled_intercepts, index=county_name)
std_errors = pd.Series(unpooled_intercepts_se, index=county_name)
order = means.sort_values().index
plt.plot(range(num_counties), means[order], '.')
for i, m, se in zip(range(num_counties), means[order], std_errors[order]):
plt.plot([i, i], [m - se, m + se], 'C0-')
plt.xlabel('Ordered county')
plt.ylabel('Radon estimate')
plt.show()
plot_ordered_estimates()
Chức năng tiện ích để vẽ các ước tính cho một tập mẫu các hạt.
def plot_estimates(linear_estimates, labels, sample_counties):
fig, axes = plt.subplots(2, 4, figsize=(12, 6), sharey=True, sharex=True)
axes = axes.ravel()
intercepts_indexed = []
slopes_indexed = []
for intercepts, slopes in linear_estimates:
intercepts_indexed.append(pd.Series(intercepts, index=county_name))
slopes_indexed.append(pd.Series(slopes, index=county_name))
markers = ['-', 'r--', 'k:']
sample_county_codes = [county_name.index(c) for c in sample_counties]
for i, c in enumerate(sample_county_codes):
y = radon.log_radon[radon.county == c]
x = radon.floor[radon.county == c]
axes[i].scatter(
x + np.random.randn(len(x)) * 0.01, y, alpha=0.4, label='Log Radon')
# Plot both models and data
xvals = np.linspace(-0.2, 1.2)
for k in range(len(intercepts_indexed)):
axes[i].plot(
xvals,
intercepts_indexed[k][c] + slopes_indexed[k][c] * xvals,
markers[k],
label=labels[k])
axes[i].set_xticks([0, 1])
axes[i].set_xticklabels(['Basement', 'First Floor'])
axes[i].set_ylim(-1, 3)
axes[i].set_title(sample_counties[i])
if not i % 2:
axes[i].set_ylabel('Log Radon level')
axes[3].legend(bbox_to_anchor=(1.05, 0.9), borderaxespad=0.)
plt.show()
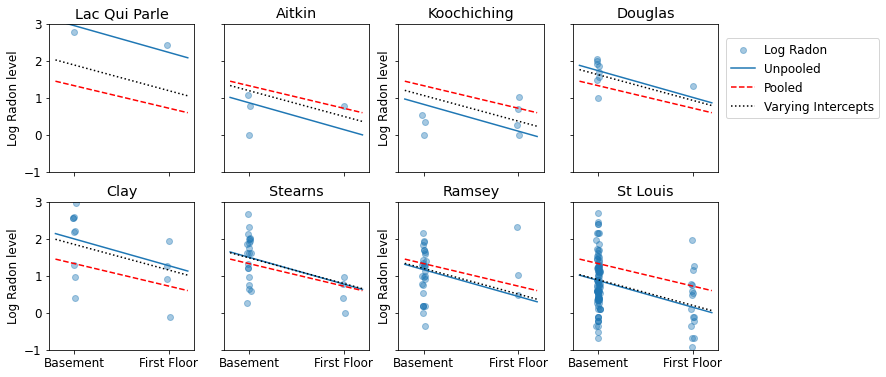
Dưới đây là các so sánh trực quan giữa các ước tính được tổng hợp và không được chia sẻ cho một tập hợp con các hạt đại diện cho một loạt các kích thước mẫu.
unpooled_estimates = LinearEstimates(
sample_mean(unpooled_samples.alpha),
sample_mean(unpooled_samples.beta)
)
sample_counties = ('Lac Qui Parle', 'Aitkin', 'Koochiching', 'Douglas', 'Clay',
'Stearns', 'Ramsey', 'St Louis')
plot_estimates(
linear_estimates=[unpooled_estimates, pooled_estimate],
labels=['Unpooled Estimates', 'Pooled Estimates'],
sample_counties=sample_counties)
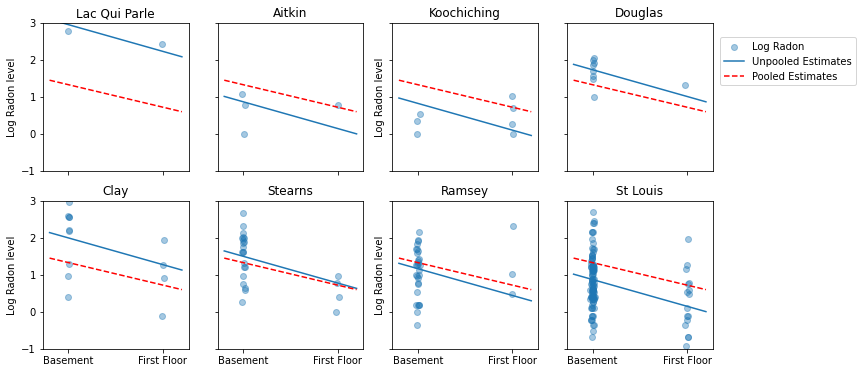
Cả hai mô hình này đều không đạt yêu cầu:
- nếu chúng ta đang cố gắng xác định các hạt có lượng radon cao, việc gộp chung sẽ không hữu ích.
- chúng tôi không tin tưởng vào các ước tính cực đoan không chia sẻ được tạo ra bởi các mô hình sử dụng ít quan sát.
5 Mô hình đa cấp và phân cấp
Khi chúng tôi gộp dữ liệu của mình, chúng tôi sẽ mất thông tin mà các điểm dữ liệu khác nhau đến từ các quận khác nhau. Điều này có nghĩa rằng mỗi radon quan sát -level được lấy mẫu từ phân phối xác suất tương tự. Một mô hình như vậy không thể tìm hiểu bất kỳ sự thay đổi nào trong đơn vị lấy mẫu vốn có trong một nhóm (ví dụ: một quận). Nó chỉ tính đến phương sai lấy mẫu.
mpl.rc("font", size=18)
pgm = daft.PGM([13.6, 2.2], origin=[1.15, 1.0], node_ec="none")
pgm.add_node(daft.Node("parameter", r"parameter", 2.0, 3))
pgm.add_node(daft.Node("observations", r"observations", 2.0, 2))
pgm.add_node(daft.Node("theta", r"$\theta$", 5.5, 3))
pgm.add_node(daft.Node("y_0", r"$y_0$", 4, 2))
pgm.add_node(daft.Node("y_1", r"$y_1$", 5, 2))
pgm.add_node(daft.Node("dots", r"$\cdots$", 6, 2))
pgm.add_node(daft.Node("y_k", r"$y_k$", 7, 2))
pgm.add_edge("theta", "y_0")
pgm.add_edge("theta", "y_1")
pgm.add_edge("theta", "y_k")
pgm.render()
plt.show()
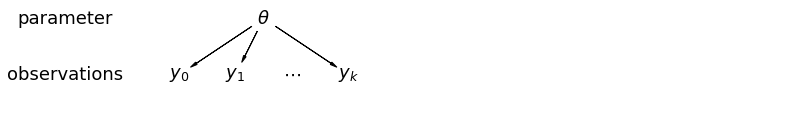
Khi chúng tôi phân tích dữ liệu không được chia sẻ, chúng tôi ngụ ý rằng chúng được lấy mẫu độc lập với các mô hình riêng biệt. Ở cực ngược lại với trường hợp gộp, cách tiếp cận này tuyên bố rằng sự khác biệt giữa các đơn vị lấy mẫu là quá lớn để kết hợp chúng:
mpl.rc("font", size=18)
pgm = daft.PGM([13.6, 2.2], origin=[1.15, 1.0], node_ec="none")
pgm.add_node(daft.Node("parameter", r"parameter", 2.0, 3))
pgm.add_node(daft.Node("observations", r"observations", 2.0, 2))
pgm.add_node(daft.Node("theta_0", r"$\theta_0$", 4, 3))
pgm.add_node(daft.Node("theta_1", r"$\theta_1$", 5, 3))
pgm.add_node(daft.Node("theta_dots", r"$\cdots$", 6, 3))
pgm.add_node(daft.Node("theta_k", r"$\theta_k$", 7, 3))
pgm.add_node(daft.Node("y_0", r"$y_0$", 4, 2))
pgm.add_node(daft.Node("y_1", r"$y_1$", 5, 2))
pgm.add_node(daft.Node("y_dots", r"$\cdots$", 6, 2))
pgm.add_node(daft.Node("y_k", r"$y_k$", 7, 2))
pgm.add_edge("theta_0", "y_0")
pgm.add_edge("theta_1", "y_1")
pgm.add_edge("theta_k", "y_k")
pgm.render()
plt.show()
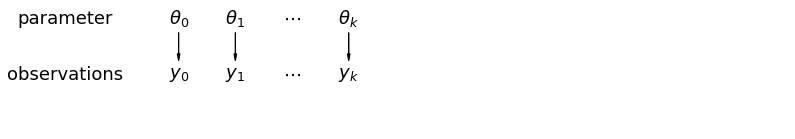
Trong mô hình phân cấp, các tham số được xem như một mẫu từ phân phối tổng thể của các tham số. Do đó, chúng tôi xem chúng không hoàn toàn khác biệt hoặc hoàn toàn giống nhau. Đây được gọi là tổng hợp một phần.
mpl.rc("font", size=18)
pgm = daft.PGM([13.6, 3.4], origin=[1.15, 1.0], node_ec="none")
pgm.add_node(daft.Node("model", r"model", 2.0, 4))
pgm.add_node(daft.Node("parameter", r"parameter", 2.0, 3))
pgm.add_node(daft.Node("observations", r"observations", 2.0, 2))
pgm.add_node(daft.Node("mu_sigma", r"$\mu,\sigma^2$", 5.5, 4))
pgm.add_node(daft.Node("theta_0", r"$\theta_0$", 4, 3))
pgm.add_node(daft.Node("theta_1", r"$\theta_1$", 5, 3))
pgm.add_node(daft.Node("theta_dots", r"$\cdots$", 6, 3))
pgm.add_node(daft.Node("theta_k", r"$\theta_k$", 7, 3))
pgm.add_node(daft.Node("y_0", r"$y_0$", 4, 2))
pgm.add_node(daft.Node("y_1", r"$y_1$", 5, 2))
pgm.add_node(daft.Node("y_dots", r"$\cdots$", 6, 2))
pgm.add_node(daft.Node("y_k", r"$y_k$", 7, 2))
pgm.add_edge("mu_sigma", "theta_0")
pgm.add_edge("mu_sigma", "theta_1")
pgm.add_edge("mu_sigma", "theta_k")
pgm.add_edge("theta_0", "y_0")
pgm.add_edge("theta_1", "y_1")
pgm.add_edge("theta_k", "y_k")
pgm.render()
plt.show()
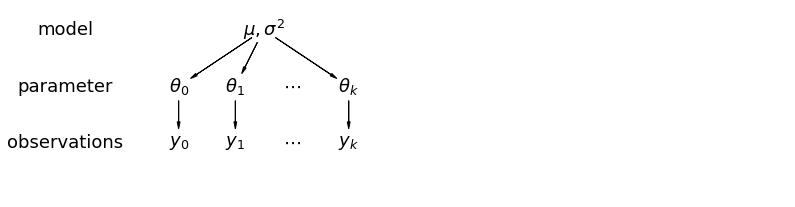
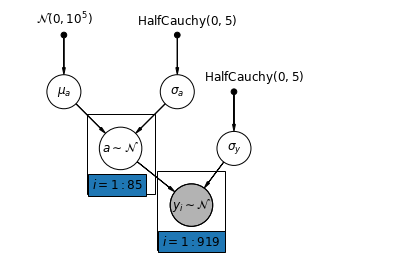
5.1 Tổng hợp một phần
Mô hình tổng hợp từng phần đơn giản nhất cho tập dữ liệu radon hộ gia đình là mô hình đơn giản ước tính mức radon mà không có bất kỳ yếu tố dự báo nào ở cấp độ nhóm hoặc cá nhân. Ví dụ về công cụ dự đoán cấp độ cá nhân là liệu điểm dữ liệu là từ tầng hầm hay tầng một. Một yếu tố dự báo cấp nhóm có thể là mức uranium trung bình của toàn quận.
Mô hình gộp chung một phần thể hiện sự thỏa hiệp giữa các thái cực được gộp chung và không được chia sẻ, xấp xỉ trung bình có trọng số (dựa trên kích thước mẫu) của các ước tính của quận không được chia sẻ và các ước tính được gộp chung.
Hãy \(\hat{\alpha}_j\) là mức log-radon ước tính trong quận \(j\). Nó chỉ là một sự đánh chặn; chúng tôi bỏ qua các độ dốc cho bây giờ. \(n_j\) là số quan sát từ quận \(j\). \(\sigma_{\alpha}\) và \(\sigma_y\) là phương sai trong tham số và phương sai lấy mẫu tương ứng. Sau đó, một mô hình tổng hợp một phần có thể đặt ra:
\[\hat{\alpha}_j \approx \frac{(n_j/\sigma_y^2)\bar{y}_j + (1/\sigma_{\alpha}^2)\bar{y} }{(n_j/\sigma_y^2) + (1/\sigma_{\alpha}^2)}\]
Chúng tôi mong đợi những điều sau khi sử dụng gộp một phần:
- Ước tính cho các quận có cỡ mẫu nhỏ hơn sẽ giảm dần về mức trung bình trên toàn tiểu bang.
- Ước tính cho các quận có cỡ mẫu lớn hơn sẽ gần với ước tính quận không chia sẻ.
mpl.rc("font", size=12)
pgm = daft.PGM([7, 4.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"mu_a_prior",
r"$\mathcal{N}(0, 10^5)$",
1,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"sigma_a_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
3,
4,
fixed=True,
offset=(10, 5)))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
4,
3,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("mu_a", r"$\mu_a$", 1, 3))
pgm.add_node(daft.Node("sigma_a", r"$\sigma_a$", 3, 3))
pgm.add_node(daft.Node("a", r"$a \sim \mathcal{N}$", 2, 2, scale=1.25))
pgm.add_node(daft.Node("sigma_y", r"$\sigma_y$", 4, 2))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 3.25, 1, scale=1.25, observed=True))
pgm.add_edge("mu_a_prior", "mu_a")
pgm.add_edge("sigma_a_prior", "sigma_a")
pgm.add_edge("mu_a", "a")
pgm.add_edge("sigma_a", "a")
pgm.add_edge("sigma_prior", "sigma_y")
pgm.add_edge("sigma_y", "y_i")
pgm.add_edge("a", "y_i")
pgm.add_plate(daft.Plate([1.4, 1.2, 1.2, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([2.65, 0.2, 1.2, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
def partial_pooling_model(county):
"""Creates a joint distribution for the partial pooling model."""
return tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=1e5), # mu_a
tfd.HalfCauchy(loc=0., scale=5), # sigma_a
lambda sigma_a, mu_a: tfd.MultivariateNormalDiag( # a
loc=mu_a[..., tf.newaxis] * tf.ones([num_counties])[tf.newaxis, ...],
scale_identity_multiplier=sigma_a),
tfd.HalfCauchy(loc=0., scale=5), # sigma_y
lambda sigma_y, a: tfd.MultivariateNormalDiag( # y
loc=tf.gather(a, county, axis=-1),
scale_identity_multiplier=sigma_y)
])
@tf.function
def partial_pooling_log_prob(mu_a, sigma_a, a, sigma_y):
"""Computes joint log prob pinned at `log_radon`."""
return partial_pooling_model(county).log_prob(
[mu_a, sigma_a, a, sigma_y, log_radon])
@tf.function
def sample_partial_pooling(num_chains, num_results, num_burnin_steps):
"""Samples from the partial pooling model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=partial_pooling_log_prob,
num_leapfrog_steps=10,
step_size=0.01)
initial_state = [
tf.zeros([num_chains], name='init_mu_a'),
tf.ones([num_chains], name='init_sigma_a'),
tf.zeros([num_chains, num_counties], name='init_a'),
tf.ones([num_chains], name='init_sigma_y')
]
unconstraining_bijectors = [
tfb.Identity(), # mu_a
tfb.Exp(), # sigma_a
tfb.Identity(), # a
tfb.Exp() # sigma_y
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
PartialPoolingModel = collections.namedtuple(
'PartialPoolingModel', ['mu_a', 'sigma_a', 'a', 'sigma_y'])
samples, acceptance_probs = sample_partial_pooling(
num_chains=4, num_results=1000, num_burnin_steps=1000)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
partial_pooling_samples = PartialPoolingModel._make(samples)
Acceptance Probabilities: [0.989 0.977 0.988 0.985]
for var in ['mu_a', 'sigma_a', 'sigma_y']:
print(
'R-hat for ', var, '\t:',
tfp.mcmc.potential_scale_reduction(getattr(partial_pooling_samples,
var)).numpy())
R-hat for mu_a : 1.0216417 R-hat for sigma_a : 1.0224565 R-hat for sigma_y : 1.0016255
partial_pooling_intercepts = reduce_samples(
partial_pooling_samples.a.numpy(), np.mean)
partial_pooling_intercepts_se = reduce_samples(
partial_pooling_samples.a.numpy(), np.std)
def plot_unpooled_vs_partial_pooling_estimates():
fig, axes = plt.subplots(1, 2, figsize=(14, 6), sharex=True, sharey=True)
# Order counties by number of observations (and add some jitter).
num_obs_per_county = (
radon.groupby('county')['idnum'].count().values.astype(np.float32))
num_obs_per_county += np.random.normal(scale=0.5, size=num_counties)
intercepts_list = [unpooled_intercepts, partial_pooling_intercepts]
intercepts_se_list = [unpooled_intercepts_se, partial_pooling_intercepts_se]
for ax, means, std_errors in zip(axes, intercepts_list, intercepts_se_list):
ax.plot(num_obs_per_county, means, 'C0.')
for n, m, se in zip(num_obs_per_county, means, std_errors):
ax.plot([n, n], [m - se, m + se], 'C1-', alpha=.5)
for ax in axes:
ax.set_xscale('log')
ax.set_xlabel('No. of Observations Per County')
ax.set_xlim(1, 100)
ax.set_ylabel('Log Radon Estimate (with Standard Error)')
ax.set_ylim(0, 3)
ax.hlines(partial_pooling_intercepts.mean(), .9, 125, 'k', '--', alpha=.5)
axes[0].set_title('Unpooled Estimates')
axes[1].set_title('Partially Pooled Estimates')
plot_unpooled_vs_partial_pooling_estimates()
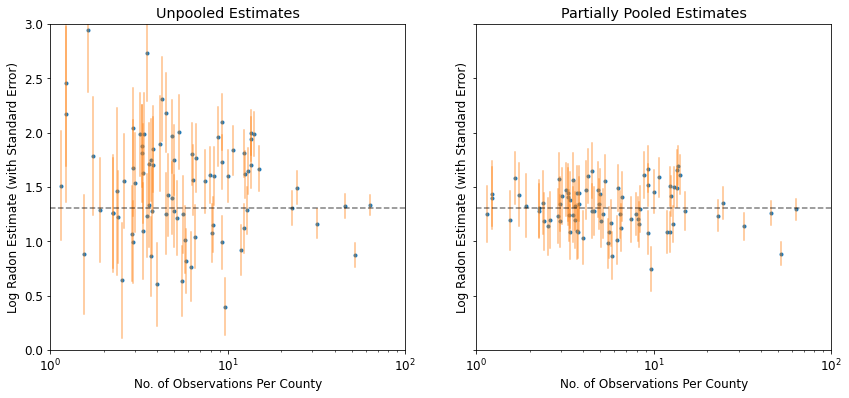
Lưu ý sự khác biệt giữa ước tính không được chia sẻ và ước tính được tổng hợp một phần, đặc biệt là ở các kích thước mẫu nhỏ hơn. Những điều trước đây đều cực đoan hơn và không chính xác hơn.
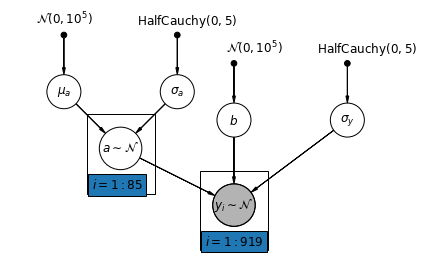
5.2 Chặn thay đổi
Bây giờ chúng tôi đang xem xét một mô hình phức tạp hơn cho phép các chốt chặn khác nhau giữa các quận, theo một hiệu ứng ngẫu nhiên.
\(y_i = \alpha_{j[i]} + \beta x_{i} + \epsilon_i\) nơi\(\epsilon_i \sim N(0, \sigma_y^2)\) và ảnh hưởng ngẫu nhiên đánh chặn:
\[\alpha_{j[i]} \sim N(\mu_{\alpha}, \sigma_{\alpha}^2)\]
Độ dốc \(\beta\), cho phép các quan sát khác nhau tùy theo vị trí của đo lường (tầng hầm hoặc tầng trệt), vẫn còn là một hiệu ứng cố định chia sẻ giữa các quận khác nhau.
Cũng như với các mô hình unpooling, chúng tôi thiết lập một đánh chặn riêng cho từng quận, nhưng thay vì phù hợp mô hình hồi quy hình vuông ít nhất riêng cho từng quận, đa cấp cổ phiếu mô hình sức mạnh giữa các hạt, cho phép suy luận hợp lý hơn trong các quận với dữ liệu ít.
mpl.rc("font", size=12)
pgm = daft.PGM([7, 4.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"mu_a_prior",
r"$\mathcal{N}(0, 10^5)$",
1,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"sigma_a_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
3,
4,
fixed=True,
offset=(10, 5)))
pgm.add_node(
daft.Node(
"b_prior",
r"$\mathcal{N}(0, 10^5)$",
4,
3.5,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("b", r"$b$", 4, 2.5))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
6,
3.5,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("mu_a", r"$\mu_a$", 1, 3))
pgm.add_node(daft.Node("sigma_a", r"$\sigma_a$", 3, 3))
pgm.add_node(daft.Node("a", r"$a \sim \mathcal{N}$", 2, 2, scale=1.25))
pgm.add_node(daft.Node("sigma_y", r"$\sigma_y$", 6, 2.5))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 4, 1, scale=1.25, observed=True))
pgm.add_edge("mu_a_prior", "mu_a")
pgm.add_edge("sigma_a_prior", "sigma_a")
pgm.add_edge("mu_a", "a")
pgm.add_edge("b_prior", "b")
pgm.add_edge("sigma_a", "a")
pgm.add_edge("sigma_prior", "sigma_y")
pgm.add_edge("sigma_y", "y_i")
pgm.add_edge("a", "y_i")
pgm.add_edge("b", "y_i")
pgm.add_plate(daft.Plate([1.4, 1.2, 1.2, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([3.4, 0.2, 1.2, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
def varying_intercept_model(floor, county):
"""Creates a joint distribution for the varying intercept model."""
return tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=1e5), # mu_a
tfd.HalfCauchy(loc=0., scale=5), # sigma_a
lambda sigma_a, mu_a: tfd.MultivariateNormalDiag( # a
loc=affine(tf.ones([num_counties]), mu_a[..., tf.newaxis]),
scale_identity_multiplier=sigma_a),
tfd.Normal(loc=0., scale=1e5), # b
tfd.HalfCauchy(loc=0., scale=5), # sigma_y
lambda sigma_y, b, a: tfd.MultivariateNormalDiag( # y
loc=affine(floor, b[..., tf.newaxis], tf.gather(a, county, axis=-1)),
scale_identity_multiplier=sigma_y)
])
def varying_intercept_log_prob(mu_a, sigma_a, a, b, sigma_y):
"""Computes joint log prob pinned at `log_radon`."""
return varying_intercept_model(floor, county).log_prob(
[mu_a, sigma_a, a, b, sigma_y, log_radon])
@tf.function
def sample_varying_intercepts(num_chains, num_results, num_burnin_steps):
"""Samples from the varying intercepts model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=varying_intercept_log_prob,
num_leapfrog_steps=10,
step_size=0.01)
initial_state = [
tf.zeros([num_chains], name='init_mu_a'),
tf.ones([num_chains], name='init_sigma_a'),
tf.zeros([num_chains, num_counties], name='init_a'),
tf.zeros([num_chains], name='init_b'),
tf.ones([num_chains], name='init_sigma_y')
]
unconstraining_bijectors = [
tfb.Identity(), # mu_a
tfb.Exp(), # sigma_a
tfb.Identity(), # a
tfb.Identity(), # b
tfb.Exp() # sigma_y
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
VaryingInterceptsModel = collections.namedtuple(
'VaryingInterceptsModel', ['mu_a', 'sigma_a', 'a', 'b', 'sigma_y'])
samples, acceptance_probs = sample_varying_intercepts(
num_chains=4, num_results=1000, num_burnin_steps=1000)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
varying_intercepts_samples = VaryingInterceptsModel._make(samples)
Acceptance Probabilities: [0.978 0.987 0.982 0.984]
for var in ['mu_a', 'sigma_a', 'b', 'sigma_y']:
print(
'R-hat for ', var, ': ',
tfp.mcmc.potential_scale_reduction(
getattr(varying_intercepts_samples, var)).numpy())
R-hat for mu_a : 1.1099764 R-hat for sigma_a : 1.1058794 R-hat for b : 1.0448593 R-hat for sigma_y : 1.0019052
varying_intercepts_estimates = LinearEstimates(
sample_mean(varying_intercepts_samples.a),
sample_mean(varying_intercepts_samples.b))
sample_counties = ('Lac Qui Parle', 'Aitkin', 'Koochiching', 'Douglas', 'Clay',
'Stearns', 'Ramsey', 'St Louis')
plot_estimates(
linear_estimates=[
unpooled_estimates, pooled_estimate, varying_intercepts_estimates
],
labels=['Unpooled', 'Pooled', 'Varying Intercepts'],
sample_counties=sample_counties)
def plot_posterior(var_name, var_samples):
if isinstance(var_samples, tf.Tensor):
var_samples = var_samples.numpy() # convert to numpy array
fig = plt.figure(figsize=(10, 3))
ax = fig.add_subplot(111)
ax.hist(var_samples.flatten(), bins=40, edgecolor='white')
sample_mean = var_samples.mean()
ax.text(
sample_mean,
100,
'mean={:.3f}'.format(sample_mean),
color='white',
fontsize=12)
ax.set_xlabel('posterior of ' + var_name)
plt.show()
plot_posterior('b', varying_intercepts_samples.b)
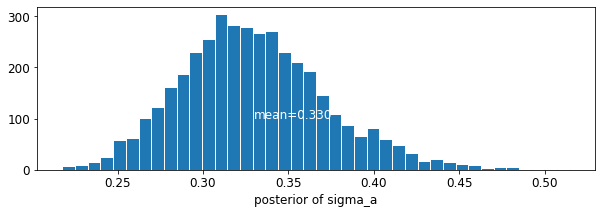
plot_posterior('sigma_a', varying_intercepts_samples.sigma_a)
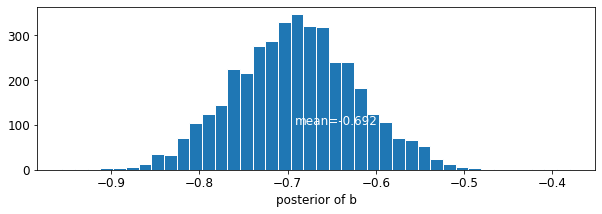
Ước tính cho hệ số sàn là khoảng -0,69, có thể được hiểu như là ngôi nhà mà không cần tầng hầm có khoảng một nửa (\(\exp(-0.69) = 0.50\)) mức radon của những người có tầng hầm, sau khi tính toán cho các quận.
for var in ['b']:
var_samples = getattr(varying_intercepts_samples, var)
mean = var_samples.numpy().mean()
std = var_samples.numpy().std()
r_hat = tfp.mcmc.potential_scale_reduction(var_samples).numpy()
n_eff = tfp.mcmc.effective_sample_size(var_samples).numpy().sum()
print('var: ', var, ' mean: ', mean, ' std: ', std, ' n_eff: ', n_eff,
' r_hat: ', r_hat)
var: b mean: -0.6972574 std: 0.06966117 n_eff: 397.94327 r_hat: 1.0448593
def plot_intercepts_and_slopes(linear_estimates, title):
xvals = np.arange(2)
intercepts = np.ones([num_counties]) * linear_estimates.intercept
slopes = np.ones([num_counties]) * linear_estimates.slope
fig, ax = plt.subplots()
for c in range(num_counties):
ax.plot(xvals, intercepts[c] + slopes[c] * xvals, 'bo-', alpha=0.4)
plt.xlim(-0.2, 1.2)
ax.set_xticks([0, 1])
ax.set_xticklabels(['Basement', 'First Floor'])
ax.set_ylabel('Log Radon level')
plt.title(title)
plt.show()
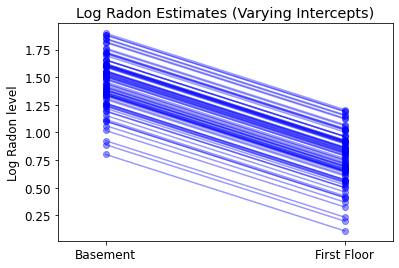
plot_intercepts_and_slopes(varying_intercepts_estimates,
'Log Radon Estimates (Varying Intercepts)')
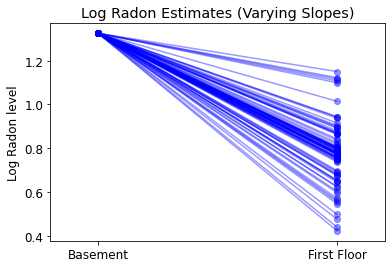
5.3 Độ dốc thay đổi
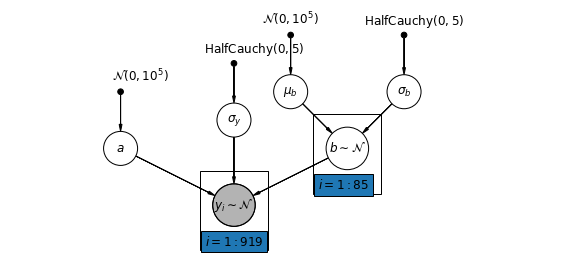
Ngoài ra, chúng ta có thể đặt ra một mô hình cho phép các quận thay đổi theo cách vị trí đo (tầng hầm hoặc tầng một) ảnh hưởng đến việc đọc radon. Trong trường hợp này đánh chặn \(\alpha\) được chia sẻ giữa các quận.
\[y_i = \alpha + \beta_{j[i]} x_{i} + \epsilon_i\]
mpl.rc("font", size=12)
pgm = daft.PGM([10, 4.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"mu_b_prior",
r"$\mathcal{N}(0, 10^5)$",
3.2,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"a_prior", r"$\mathcal{N}(0, 10^5)$", 2, 3, fixed=True, offset=(20, 5)))
pgm.add_node(daft.Node("a", r"$a$", 2, 2))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
4,
3.5,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("sigma_y", r"$\sigma_y$", 4, 2.5))
pgm.add_node(
daft.Node(
"mu_b_prior",
r"$\mathcal{N}(0, 10^5)$",
5,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"sigma_b_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
7,
4,
fixed=True,
offset=(10, 5)))
pgm.add_node(daft.Node("mu_b", r"$\mu_b$", 5, 3))
pgm.add_node(daft.Node("sigma_b", r"$\sigma_b$", 7, 3))
pgm.add_node(daft.Node("b", r"$b \sim \mathcal{N}$", 6, 2, scale=1.25))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 4, 1, scale=1.25, observed=True))
pgm.add_edge("a_prior", "a")
pgm.add_edge("mu_b_prior", "mu_b")
pgm.add_edge("sigma_b_prior", "sigma_b")
pgm.add_edge("mu_b", "b")
pgm.add_edge("sigma_b", "b")
pgm.add_edge("sigma_prior", "sigma_y")
pgm.add_edge("sigma_y", "y_i")
pgm.add_edge("a", "y_i")
pgm.add_edge("b", "y_i")
pgm.add_plate(daft.Plate([5.4, 1.2, 1.2, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([3.4, 0.2, 1.2, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
def varying_slopes_model(floor, county):
"""Creates a joint distribution for the varying slopes model."""
return tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=1e5), # mu_b
tfd.HalfCauchy(loc=0., scale=5), # sigma_b
tfd.Normal(loc=0., scale=1e5), # a
lambda _, sigma_b, mu_b: tfd.MultivariateNormalDiag( # b
loc=affine(tf.ones([num_counties]), mu_b[..., tf.newaxis]),
scale_identity_multiplier=sigma_b),
tfd.HalfCauchy(loc=0., scale=5), # sigma_y
lambda sigma_y, b, a: tfd.MultivariateNormalDiag( # y
loc=affine(floor, tf.gather(b, county, axis=-1), a[..., tf.newaxis]),
scale_identity_multiplier=sigma_y)
])
def varying_slopes_log_prob(mu_b, sigma_b, a, b, sigma_y):
return varying_slopes_model(floor, county).log_prob(
[mu_b, sigma_b, a, b, sigma_y, log_radon])
@tf.function
def sample_varying_slopes(num_chains, num_results, num_burnin_steps):
"""Samples from the varying slopes model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=varying_slopes_log_prob,
num_leapfrog_steps=25,
step_size=0.01)
initial_state = [
tf.zeros([num_chains], name='init_mu_b'),
tf.ones([num_chains], name='init_sigma_b'),
tf.zeros([num_chains], name='init_a'),
tf.zeros([num_chains, num_counties], name='init_b'),
tf.ones([num_chains], name='init_sigma_y')
]
unconstraining_bijectors = [
tfb.Identity(), # mu_b
tfb.Exp(), # sigma_b
tfb.Identity(), # a
tfb.Identity(), # b
tfb.Exp() # sigma_y
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
VaryingSlopesModel = collections.namedtuple(
'VaryingSlopesModel', ['mu_b', 'sigma_b', 'a', 'b', 'sigma_y'])
samples, acceptance_probs = sample_varying_slopes(
num_chains=4, num_results=1000, num_burnin_steps=1000)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
varying_slopes_samples = VaryingSlopesModel._make(samples)
Acceptance Probabilities: [0.979 0.984 0.977 0.984]
for var in ['mu_b', 'sigma_b', 'a', 'sigma_y']:
print(
'R-hat for ', var, '\t: ',
tfp.mcmc.potential_scale_reduction(getattr(varying_slopes_samples,
var)).numpy())
R-hat for mu_b : 1.0770341 R-hat for sigma_b : 1.0634488 R-hat for a : 1.0133665 R-hat for sigma_y : 1.0011941
varying_slopes_estimates = LinearEstimates(
sample_mean(varying_slopes_samples.a),
sample_mean(varying_slopes_samples.b))
plot_intercepts_and_slopes(varying_slopes_estimates,
'Log Radon Estimates (Varying Slopes)')
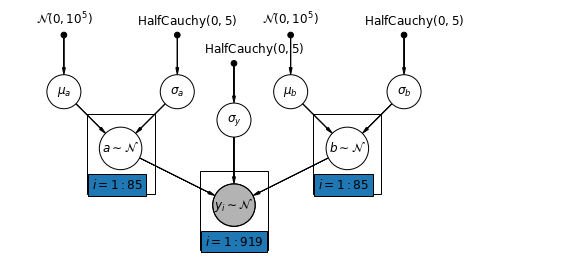
5.4 Các chốt chặn và độ dốc thay đổi
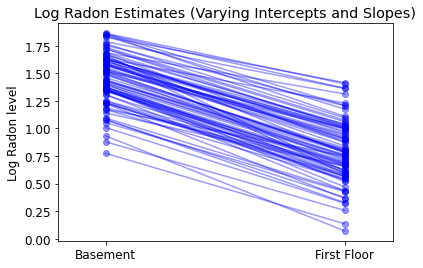
Mô hình chung nhất cho phép cả điểm chặn và độ dốc thay đổi theo quận:
\[y_i = \alpha_{j[i]} + \beta_{j[i]} x_{i} + \epsilon_i\]
mpl.rc("font", size=12)
pgm = daft.PGM([10, 4.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"mu_a_prior",
r"$\mathcal{N}(0, 10^5)$",
1,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"sigma_a_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
3,
4,
fixed=True,
offset=(10, 5)))
pgm.add_node(daft.Node("mu_a", r"$\mu_a$", 1, 3))
pgm.add_node(daft.Node("sigma_a", r"$\sigma_a$", 3, 3))
pgm.add_node(daft.Node("a", r"$a \sim \mathcal{N}$", 2, 2, scale=1.25))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
4,
3.5,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("sigma_y", r"$\sigma_y$", 4, 2.5))
pgm.add_node(
daft.Node(
"mu_b_prior",
r"$\mathcal{N}(0, 10^5)$",
5,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"sigma_b_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
7,
4,
fixed=True,
offset=(10, 5)))
pgm.add_node(daft.Node("mu_b", r"$\mu_b$", 5, 3))
pgm.add_node(daft.Node("sigma_b", r"$\sigma_b$", 7, 3))
pgm.add_node(daft.Node("b", r"$b \sim \mathcal{N}$", 6, 2, scale=1.25))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 4, 1, scale=1.25, observed=True))
pgm.add_edge("mu_a_prior", "mu_a")
pgm.add_edge("sigma_a_prior", "sigma_a")
pgm.add_edge("mu_a", "a")
pgm.add_edge("sigma_a", "a")
pgm.add_edge("mu_b_prior", "mu_b")
pgm.add_edge("sigma_b_prior", "sigma_b")
pgm.add_edge("mu_b", "b")
pgm.add_edge("sigma_b", "b")
pgm.add_edge("sigma_prior", "sigma_y")
pgm.add_edge("sigma_y", "y_i")
pgm.add_edge("a", "y_i")
pgm.add_edge("b", "y_i")
pgm.add_plate(daft.Plate([1.4, 1.2, 1.2, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([5.4, 1.2, 1.2, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([3.4, 0.2, 1.2, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
def varying_intercepts_and_slopes_model(floor, county):
"""Creates a joint distribution for the varying slope model."""
return tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=1e5), # mu_a
tfd.HalfCauchy(loc=0., scale=5), # sigma_a
tfd.Normal(loc=0., scale=1e5), # mu_b
tfd.HalfCauchy(loc=0., scale=5), # sigma_b
lambda sigma_b, mu_b, sigma_a, mu_a: tfd.MultivariateNormalDiag( # a
loc=affine(tf.ones([num_counties]), mu_a[..., tf.newaxis]),
scale_identity_multiplier=sigma_a),
lambda _, sigma_b, mu_b: tfd.MultivariateNormalDiag( # b
loc=affine(tf.ones([num_counties]), mu_b[..., tf.newaxis]),
scale_identity_multiplier=sigma_b),
tfd.HalfCauchy(loc=0., scale=5), # sigma_y
lambda sigma_y, b, a: tfd.MultivariateNormalDiag( # y
loc=affine(floor, tf.gather(b, county, axis=-1),
tf.gather(a, county, axis=-1)),
scale_identity_multiplier=sigma_y)
])
@tf.function
def varying_intercepts_and_slopes_log_prob(mu_a, sigma_a, mu_b, sigma_b, a, b,
sigma_y):
"""Computes joint log prob pinned at `log_radon`."""
return varying_intercepts_and_slopes_model(floor, county).log_prob(
[mu_a, sigma_a, mu_b, sigma_b, a, b, sigma_y, log_radon])
@tf.function
def sample_varying_intercepts_and_slopes(num_chains, num_results,
num_burnin_steps):
"""Samples from the varying intercepts and slopes model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=varying_intercepts_and_slopes_log_prob,
num_leapfrog_steps=50,
step_size=0.01)
initial_state = [
tf.zeros([num_chains], name='init_mu_a'),
tf.ones([num_chains], name='init_sigma_a'),
tf.zeros([num_chains], name='init_mu_b'),
tf.ones([num_chains], name='init_sigma_b'),
tf.zeros([num_chains, num_counties], name='init_a'),
tf.zeros([num_chains, num_counties], name='init_b'),
tf.ones([num_chains], name='init_sigma_y')
]
unconstraining_bijectors = [
tfb.Identity(), # mu_a
tfb.Exp(), # sigma_a
tfb.Identity(), # mu_b
tfb.Exp(), # sigma_b
tfb.Identity(), # a
tfb.Identity(), # b
tfb.Exp() # sigma_y
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
VaryingInterceptsAndSlopesModel = collections.namedtuple(
'VaryingInterceptsAndSlopesModel',
['mu_a', 'sigma_a', 'mu_b', 'sigma_b', 'a', 'b', 'sigma_y'])
samples, acceptance_probs = sample_varying_intercepts_and_slopes(
num_chains=4, num_results=1000, num_burnin_steps=500)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
varying_intercepts_and_slopes_samples = VaryingInterceptsAndSlopesModel._make(
samples)
Acceptance Probabilities: [0.988 0.985 0.992 0.938]
for var in ['mu_a', 'sigma_a', 'mu_b', 'sigma_b']:
print(
'R-hat for ', var, '\t: ',
tfp.mcmc.potential_scale_reduction(
getattr(varying_intercepts_and_slopes_samples, var)).numpy())
R-hat for mu_a : 1.010764 R-hat for sigma_a : 1.0078123 R-hat for mu_b : 1.0279609 R-hat for sigma_b : 1.3165458
varying_intercepts_and_slopes_estimates = LinearEstimates(
sample_mean(varying_intercepts_and_slopes_samples.a),
sample_mean(varying_intercepts_and_slopes_samples.b))
plot_intercepts_and_slopes(
varying_intercepts_and_slopes_estimates,
'Log Radon Estimates (Varying Intercepts and Slopes)')
forest_plot(
num_chains=4,
num_vars=num_counties,
var_name='a',
var_labels=county_name,
samples=varying_intercepts_and_slopes_samples.a.numpy())
forest_plot(
num_chains=4,
num_vars=num_counties,
var_name='b',
var_labels=county_name,
samples=varying_intercepts_and_slopes_samples.b.numpy())


6 Thêm dự đoán cấp nhóm
Điểm mạnh chính của mô hình đa cấp là khả năng xử lý đồng thời các yếu tố dự báo trên nhiều cấp độ. Nếu chúng ta xem xét mô hình khác nhau-chặn ở trên:
\(y_i = \alpha_{j[i]} + \beta x_{i} + \epsilon_i\) chúng tôi có thể, thay vì một hiệu ứng ngẫu nhiên đơn giản để mô tả sự thay đổi trong giá trị radon mong đợi, chỉ định một mô hình hồi quy với một covariate cấp huyện. Ở đây, chúng tôi sử dụng uranium quận đọc \(u_j\), mà được cho là liên quan đến nồng độ radon:
\(\alpha_j = \gamma_0 + \gamma_1 u_j + \zeta_j\)\(\zeta_j \sim N(0, \sigma_{\alpha}^2)\) Vì vậy, chúng tôi đang kết hợp với một yếu tố dự báo nhà cấp (sàn hoặc tầng hầm) cũng như một yếu tố dự báo cấp huyện (uranium).
Lưu ý rằng mô hình có cả hai biến chỉ số cho mỗi quận, cộng với một hiệp biến cấp quận. Trong hồi quy cổ điển, điều này sẽ dẫn đến tính thẳng hàng. Trong mô hình đa cấp, việc tổng hợp một phần các điểm chặn theo giá trị kỳ vọng của mô hình tuyến tính cấp nhóm sẽ tránh được điều này.
Dự đoán nhóm cấp cũng được dùng để làm giảm biến đổi nhóm cấp\(\sigma_{\alpha}\). Một hàm ý quan trọng của điều này là ước tính cấp nhóm tạo ra tổng hợp mạnh hơn.
6.1 Mô hình chặn phân cấp
mpl.rc("font", size=12)
pgm = daft.PGM([10, 4.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"gamma_0_prior",
r"$\mathcal{N}(0, 10^5)$",
0.5,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(
daft.Node(
"gamma_1_prior",
r"$\mathcal{N}(0, 10^5)$",
1.5,
4,
fixed=True,
offset=(10, 5)))
pgm.add_node(daft.Node("gamma_0", r"$\gamma_0$", 0.5, 3))
pgm.add_node(daft.Node("gamma_1", r"$\gamma_1$", 1.5, 3))
pgm.add_node(
daft.Node(
"sigma_a_prior",
r"$\mathcal{N}(0, 10^5)$",
3,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(daft.Node("sigma_a", r"$\sigma_a$", 3, 3.5))
pgm.add_node(daft.Node("eps_a", r"$eps_a$", 3, 2.5, scale=1.25))
pgm.add_node(daft.Node("a", r"$a \sim \mathcal{Det}$", 1.5, 1.2, scale=1.5))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{U}(0, 100)$",
4,
3.5,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("sigma_y", r"$\sigma_y$", 4, 2.5))
pgm.add_node(daft.Node("b_prior", r"$\mathcal{N}(0, 10^5)$", 5, 3, fixed=True))
pgm.add_node(daft.Node("b", r"$b$", 5, 2))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 4, 1, scale=1.25, observed=True))
pgm.add_edge("gamma_0_prior", "gamma_0")
pgm.add_edge("gamma_1_prior", "gamma_1")
pgm.add_edge("sigma_a_prior", "sigma_a")
pgm.add_edge("sigma_a", "eps_a")
pgm.add_edge("gamma_0", "a")
pgm.add_edge("gamma_1", "a")
pgm.add_edge("eps_a", "a")
pgm.add_edge("b_prior", "b")
pgm.add_edge("sigma_prior", "sigma_y")
pgm.add_edge("sigma_y", "y_i")
pgm.add_edge("a", "y_i")
pgm.add_edge("b", "y_i")
pgm.add_plate(daft.Plate([2.4, 1.7, 1.2, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([0.9, 0.4, 1.2, 1.4], "$i = 1:919$"))
pgm.add_plate(daft.Plate([3.4, 0.2, 1.2, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
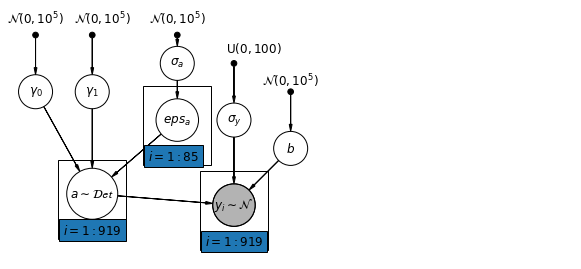
def hierarchical_intercepts_model(floor, county, log_uranium):
"""Creates a joint distribution for the varying slope model."""
return tfd.JointDistributionSequential([
tfd.HalfCauchy(loc=0., scale=5), # sigma_a
lambda sigma_a: tfd.MultivariateNormalDiag( # eps_a
loc=tf.zeros([num_counties]),
scale_identity_multiplier=sigma_a),
tfd.Normal(loc=0., scale=1e5), # gamma_0
tfd.Normal(loc=0., scale=1e5), # gamma_1
tfd.Normal(loc=0., scale=1e5), # b
tfd.Uniform(low=0., high=100), # sigma_y
lambda sigma_y, b, gamma_1, gamma_0, eps_a: tfd.
MultivariateNormalDiag( # y
loc=affine(
floor, b[..., tf.newaxis],
affine(log_uranium, gamma_1[..., tf.newaxis],
gamma_0[..., tf.newaxis]) + tf.gather(eps_a, county, axis=-1)),
scale_identity_multiplier=sigma_y)
])
def hierarchical_intercepts_log_prob(sigma_a, eps_a, gamma_0, gamma_1, b,
sigma_y):
"""Computes joint log prob pinned at `log_radon`."""
return hierarchical_intercepts_model(floor, county, log_uranium).log_prob(
[sigma_a, eps_a, gamma_0, gamma_1, b, sigma_y, log_radon])
@tf.function
def sample_hierarchical_intercepts(num_chains, num_results, num_burnin_steps):
"""Samples from the hierarchical intercepts model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=hierarchical_intercepts_log_prob,
num_leapfrog_steps=10,
step_size=0.01)
initial_state = [
tf.ones([num_chains], name='init_sigma_a'),
tf.zeros([num_chains, num_counties], name='eps_a'),
tf.zeros([num_chains], name='init_gamma_0'),
tf.zeros([num_chains], name='init_gamma_1'),
tf.zeros([num_chains], name='init_b'),
tf.ones([num_chains], name='init_sigma_y')
]
unconstraining_bijectors = [
tfb.Exp(), # sigma_a
tfb.Identity(), # eps_a
tfb.Identity(), # gamma_0
tfb.Identity(), # gamma_0
tfb.Identity(), # b
# Maps reals to [0, 100].
tfb.Chain([tfb.Shift(shift=50.),
tfb.Scale(scale=50.),
tfb.Tanh()]) # sigma_y
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
HierarchicalInterceptsModel = collections.namedtuple(
'HierarchicalInterceptsModel',
['sigma_a', 'eps_a', 'gamma_0', 'gamma_1', 'b', 'sigma_y'])
samples, acceptance_probs = sample_hierarchical_intercepts(
num_chains=4, num_results=2000, num_burnin_steps=500)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
hierarchical_intercepts_samples = HierarchicalInterceptsModel._make(samples)
Acceptance Probabilities: [0.9615 0.941 0.955 0.95 ]
for var in ['sigma_a', 'gamma_0', 'gamma_1', 'b', 'sigma_y']:
print(
'R-hat for', var, ':',
tfp.mcmc.potential_scale_reduction(
getattr(hierarchical_intercepts_samples, var)).numpy())
R-hat for sigma_a : 1.0469627 R-hat for gamma_0 : 1.0016835 R-hat for gamma_1 : 1.0097923 R-hat for b : 1.0014259 R-hat for sigma_y : 1.0025403
def plot_hierarchical_intercepts():
mean_and_var = lambda x : [reduce_samples(x, fn) for fn in [np.mean, np.var]]
gamma_0_mean, gamma_0_var = mean_and_var(
hierarchical_intercepts_samples.gamma_0)
gamma_1_mean, gamma_1_var = mean_and_var(
hierarchical_intercepts_samples.gamma_1)
eps_a_means, eps_a_vars = mean_and_var(hierarchical_intercepts_samples.eps_a)
mu_a_means = gamma_0_mean + gamma_1_mean * log_uranium
mu_a_vars = gamma_0_var + np.square(log_uranium) * gamma_1_var
a_means = mu_a_means + eps_a_means[county]
a_stds = np.sqrt(mu_a_vars + eps_a_vars[county])
plt.figure()
plt.scatter(log_uranium, a_means, marker='.', c='C0')
xvals = np.linspace(-1, 0.8)
plt.plot(xvals,gamma_0_mean + gamma_1_mean * xvals, 'k--')
plt.xlim(-1, 0.8)
for ui, m, se in zip(log_uranium, a_means, a_stds):
plt.plot([ui, ui], [m - se, m + se], 'C1-', alpha=0.1)
plt.xlabel('County-level uranium')
plt.ylabel('Intercept estimate')
plot_hierarchical_intercepts()
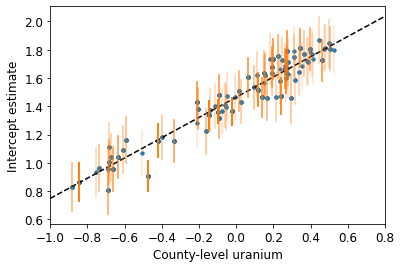
Sai số chuẩn trên các điểm chặn hẹp hơn so với mô hình gộp từng phần không có hiệp biến cấp hạt.
6.2 Mối tương quan giữa các cấp độ
Trong một số trường hợp, việc có các yếu tố dự báo ở nhiều cấp độ có thể cho thấy mối tương quan giữa các biến số cấp độ cá nhân và phần dư của nhóm. Chúng ta có thể giải thích điều này bằng cách bao gồm giá trị trung bình của các yếu tố dự đoán riêng lẻ làm hiệp biến trong mô hình cho nhóm chặn.
\(\alpha_j = \gamma_0 + \gamma_1 u_j + \gamma_2 \bar{x} + \zeta_j\) Đây là một cách rộng rãi được gọi là hiệu ứng theo ngữ cảnh.
mpl.rc("font", size=12)
pgm = daft.PGM([10, 4.5], node_unit=1.2)
pgm.add_node(
daft.Node(
"gamma_prior",
r"$\mathcal{N}(0, 10^5)$",
1.5,
4,
fixed=True,
offset=(10, 5)))
pgm.add_node(daft.Node("gamma", r"$\gamma$", 1.5, 3.5))
pgm.add_node(daft.Node("mu_a", r"$\mu_a$", 1.5, 2.2))
pgm.add_node(
daft.Node(
"sigma_a_prior",
r"$\mathrm{HalfCauchy}(0, 5)$",
3,
4,
fixed=True,
offset=(0, 5)))
pgm.add_node(daft.Node("sigma_a", r"$\sigma_a$", 3, 3.5))
pgm.add_node(daft.Node("eps_a", r"$eps_a$", 3, 2.5, scale=1.25))
pgm.add_node(daft.Node("a", r"$a \sim \mathcal{Det}$", 1.5, 1.2, scale=1.5))
pgm.add_node(
daft.Node(
"sigma_prior",
r"$\mathrm{U}(0, 100)$",
4,
3.5,
fixed=True,
offset=(20, 5)))
pgm.add_node(daft.Node("sigma_y", r"$\sigma_y$", 4, 2.5))
pgm.add_node(daft.Node("b_prior", r"$\mathcal{N}(0, 10^5)$", 5, 3, fixed=True))
pgm.add_node(daft.Node("b", r"$b$", 5, 2))
pgm.add_node(
daft.Node(
"y_i", r"$y_i \sim \mathcal{N}$", 4, 1, scale=1.25, observed=True))
pgm.add_edge("gamma_prior", "gamma")
pgm.add_edge("sigma_a_prior", "sigma_a")
pgm.add_edge("sigma_a", "eps_a")
pgm.add_edge("gamma", "mu_a")
pgm.add_edge("mu_a", "a")
pgm.add_edge("eps_a", "a")
pgm.add_edge("b_prior", "b")
pgm.add_edge("sigma_prior", "sigma_y")
pgm.add_edge("sigma_y", "y_i")
pgm.add_edge("a", "y_i")
pgm.add_edge("b", "y_i")
pgm.add_plate(daft.Plate([0.9, 2.9, 1.2, 1.0], "$i = 1:3$"))
pgm.add_plate(daft.Plate([2.4, 1.7, 1.2, 1.4], "$i = 1:85$"))
pgm.add_plate(daft.Plate([0.9, 0.4, 1.2, 2.2], "$i = 1:919$"))
pgm.add_plate(daft.Plate([3.4, 0.2, 1.2, 1.4], "$i = 1:919$"))
pgm.render()
plt.show()
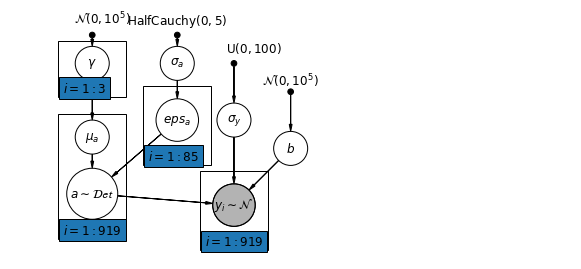
# Create a new variable for mean of floor across counties
xbar = tf.convert_to_tensor(radon.groupby('county')['floor'].mean(), tf.float32)
xbar = tf.gather(xbar, county, axis=-1)
def contextual_effects_model(floor, county, log_uranium, xbar):
"""Creates a joint distribution for the varying slope model."""
return tfd.JointDistributionSequential([
tfd.HalfCauchy(loc=0., scale=5), # sigma_a
lambda sigma_a: tfd.MultivariateNormalDiag( # eps_a
loc=tf.zeros([num_counties]),
scale_identity_multiplier=sigma_a),
tfd.Normal(loc=0., scale=1e5), # gamma_0
tfd.Normal(loc=0., scale=1e5), # gamma_1
tfd.Normal(loc=0., scale=1e5), # gamma_2
tfd.Normal(loc=0., scale=1e5), # b
tfd.Uniform(low=0., high=100), # sigma_y
lambda sigma_y, b, gamma_2, gamma_1, gamma_0, eps_a: tfd.
MultivariateNormalDiag( # y
loc=affine(
floor, b[..., tf.newaxis],
affine(log_uranium, gamma_1[..., tf.newaxis], gamma_0[
..., tf.newaxis]) + affine(xbar, gamma_2[..., tf.newaxis]) +
tf.gather(eps_a, county, axis=-1)),
scale_identity_multiplier=sigma_y)
])
def contextual_effects_log_prob(sigma_a, eps_a, gamma_0, gamma_1, gamma_2, b,
sigma_y):
"""Computes joint log prob pinned at `log_radon`."""
return contextual_effects_model(floor, county, log_uranium, xbar).log_prob(
[sigma_a, eps_a, gamma_0, gamma_1, gamma_2, b, sigma_y, log_radon])
@tf.function
def sample_contextual_effects(num_chains, num_results, num_burnin_steps):
"""Samples from the hierarchical intercepts model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=contextual_effects_log_prob,
num_leapfrog_steps=10,
step_size=0.01)
initial_state = [
tf.ones([num_chains], name='init_sigma_a'),
tf.zeros([num_chains, num_counties], name='eps_a'),
tf.zeros([num_chains], name='init_gamma_0'),
tf.zeros([num_chains], name='init_gamma_1'),
tf.zeros([num_chains], name='init_gamma_2'),
tf.zeros([num_chains], name='init_b'),
tf.ones([num_chains], name='init_sigma_y')
]
unconstraining_bijectors = [
tfb.Exp(), # sigma_a
tfb.Identity(), # eps_a
tfb.Identity(), # gamma_0
tfb.Identity(), # gamma_1
tfb.Identity(), # gamma_2
tfb.Identity(), # b
tfb.Chain([tfb.Shift(shift=50.),
tfb.Scale(scale=50.),
tfb.Tanh()]) # sigma_y
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
ContextualEffectsModel = collections.namedtuple(
'ContextualEffectsModel',
['sigma_a', 'eps_a', 'gamma_0', 'gamma_1', 'gamma_2', 'b', 'sigma_y'])
samples, acceptance_probs = sample_contextual_effects(
num_chains=4, num_results=2000, num_burnin_steps=500)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
contextual_effects_samples = ContextualEffectsModel._make(samples)
Acceptance Probabilities: [0.9505 0.9595 0.951 0.9535]
for var in ['sigma_a', 'gamma_0', 'gamma_1', 'gamma_2', 'b', 'sigma_y']:
print(
'R-hat for ', var, ': ',
tfp.mcmc.potential_scale_reduction(
getattr(contextual_effects_samples, var)).numpy())
R-hat for sigma_a : 1.0709597 R-hat for gamma_0 : 1.0067923 R-hat for gamma_1 : 1.0089629 R-hat for gamma_2 : 1.0054177 R-hat for b : 1.0018929 R-hat for sigma_y : 1.0032713
for var in ['gamma_0', 'gamma_1', 'gamma_2']:
var_samples = getattr(contextual_effects_samples, var)
mean = var_samples.numpy().mean()
std = var_samples.numpy().std()
r_hat = tfp.mcmc.potential_scale_reduction(var_samples).numpy()
n_eff = tfp.mcmc.effective_sample_size(var_samples).numpy().sum()
print(var, ' mean: ', mean, ' std: ', std, ' n_eff: ', n_eff, ' r_hat: ',
r_hat)
gamma_0 mean: 1.3934746 std: 0.04966602 n_eff: 816.21265 r_hat: 1.0067923 gamma_1 mean: 0.7229424 std: 0.088611916 n_eff: 1462.486 r_hat: 1.0089629 gamma_2 mean: 0.40893936 std: 0.20304097 n_eff: 457.8165 r_hat: 1.0054177
Vì vậy, từ đó chúng ta có thể suy ra rằng các quận có tỷ lệ nhà không có tầng hầm cao hơn có xu hướng có mức radon cơ bản cao hơn. Có lẽ điều này liên quan đến loại đất, do đó có thể ảnh hưởng đến loại cấu trúc được xây dựng.
6.3 Dự đoán
Gelman (2006) đã sử dụng các bài kiểm tra xác nhận chéo để kiểm tra lỗi dự đoán của các mô hình không được chia sẻ, gộp chung và một phần.
Lỗi dự đoán xác thực chéo bình phương trung bình gốc:
- không chia sẻ = 0,86
- gộp lại = 0,84
- đa cấp = 0,79
Có hai loại dự đoán có thể được thực hiện trong một mô hình đa cấp:
- Một cá nhân mới trong một nhóm hiện có
- Một cá nhân mới trong một nhóm mới
Ví dụ: nếu chúng ta muốn đưa ra dự đoán cho một ngôi nhà mới không có tầng hầm ở hạt St. Louis, chúng ta chỉ cần lấy mẫu từ mô hình radon với hệ số chặn thích hợp.
county_name.index('St Louis')
69
Đó là,
\[\tilde{y}_i \sim N(\alpha_{69} + \beta (x_i=1), \sigma_y^2)\]
st_louis_log_uranium = tf.convert_to_tensor(
radon.where(radon['county'] == 69)['log_uranium_ppm'].mean(), tf.float32)
st_louis_xbar = tf.convert_to_tensor(
radon.where(radon['county'] == 69)['floor'].mean(), tf.float32)
@tf.function
def intercept_a(gamma_0, gamma_1, gamma_2, eps_a, log_uranium, xbar, county):
return (affine(log_uranium, gamma_1, gamma_0) + affine(xbar, gamma_2) +
tf.gather(eps_a, county, axis=-1))
def contextual_effects_predictive_model(floor, county, log_uranium, xbar,
st_louis_log_uranium, st_louis_xbar):
"""Creates a joint distribution for the contextual effects model."""
return tfd.JointDistributionSequential([
tfd.HalfCauchy(loc=0., scale=5), # sigma_a
lambda sigma_a: tfd.MultivariateNormalDiag( # eps_a
loc=tf.zeros([num_counties]),
scale_identity_multiplier=sigma_a),
tfd.Normal(loc=0., scale=1e5), # gamma_0
tfd.Normal(loc=0., scale=1e5), # gamma_1
tfd.Normal(loc=0., scale=1e5), # gamma_2
tfd.Normal(loc=0., scale=1e5), # b
tfd.Uniform(low=0., high=100), # sigma_y
# y
lambda sigma_y, b, gamma_2, gamma_1, gamma_0, eps_a: (
tfd.MultivariateNormalDiag(
loc=affine(
floor, b[..., tf.newaxis],
intercept_a(gamma_0[..., tf.newaxis],
gamma_1[..., tf.newaxis], gamma_2[..., tf.newaxis],
eps_a, log_uranium, xbar, county)),
scale_identity_multiplier=sigma_y)),
# stl_pred
lambda _, sigma_y, b, gamma_2, gamma_1, gamma_0, eps_a: tfd.Normal(
loc=intercept_a(gamma_0, gamma_1, gamma_2, eps_a,
st_louis_log_uranium, st_louis_xbar, 69) + b,
scale=sigma_y)
])
@tf.function
def contextual_effects_predictive_log_prob(sigma_a, eps_a, gamma_0, gamma_1,
gamma_2, b, sigma_y, stl_pred):
"""Computes joint log prob pinned at `log_radon`."""
return contextual_effects_predictive_model(floor, county, log_uranium, xbar,
st_louis_log_uranium,
st_louis_xbar).log_prob([
sigma_a, eps_a, gamma_0,
gamma_1, gamma_2, b, sigma_y,
log_radon, stl_pred
])
@tf.function
def sample_contextual_effects_predictive(num_chains, num_results,
num_burnin_steps):
"""Samples from the contextual effects predictive model."""
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=contextual_effects_predictive_log_prob,
num_leapfrog_steps=50,
step_size=0.01)
initial_state = [
tf.ones([num_chains], name='init_sigma_a'),
tf.zeros([num_chains, num_counties], name='eps_a'),
tf.zeros([num_chains], name='init_gamma_0'),
tf.zeros([num_chains], name='init_gamma_1'),
tf.zeros([num_chains], name='init_gamma_2'),
tf.zeros([num_chains], name='init_b'),
tf.ones([num_chains], name='init_sigma_y'),
tf.zeros([num_chains], name='init_stl_pred')
]
unconstraining_bijectors = [
tfb.Exp(), # sigma_a
tfb.Identity(), # eps_a
tfb.Identity(), # gamma_0
tfb.Identity(), # gamma_1
tfb.Identity(), # gamma_2
tfb.Identity(), # b
tfb.Chain([tfb.Shift(shift=50.),
tfb.Scale(scale=50.),
tfb.Tanh()]), # sigma_y
tfb.Identity(), # stl_pred
]
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=hmc, bijector=unconstraining_bijectors)
samples, kernel_results = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=initial_state,
kernel=kernel)
acceptance_probs = tf.reduce_mean(
tf.cast(kernel_results.inner_results.is_accepted, tf.float32), axis=0)
return samples, acceptance_probs
ContextualEffectsPredictiveModel = collections.namedtuple(
'ContextualEffectsPredictiveModel', [
'sigma_a', 'eps_a', 'gamma_0', 'gamma_1', 'gamma_2', 'b', 'sigma_y',
'stl_pred'
])
samples, acceptance_probs = sample_contextual_effects_predictive(
num_chains=4, num_results=2000, num_burnin_steps=500)
print('Acceptance Probabilities: ', acceptance_probs.numpy())
contextual_effects_pred_samples = ContextualEffectsPredictiveModel._make(
samples)
Acceptance Probabilities: [0.9165 0.978 0.9755 0.9785]
for var in [
'sigma_a', 'gamma_0', 'gamma_1', 'gamma_2', 'b', 'sigma_y', 'stl_pred'
]:
print(
'R-hat for ', var, ': ',
tfp.mcmc.potential_scale_reduction(
getattr(contextual_effects_pred_samples, var)).numpy())
R-hat for sigma_a : 1.0325582 R-hat for gamma_0 : 1.0033548 R-hat for gamma_1 : 1.0011047 R-hat for gamma_2 : 1.001153 R-hat for b : 1.0020066 R-hat for sigma_y : 1.0128921 R-hat for stl_pred : 1.0058256
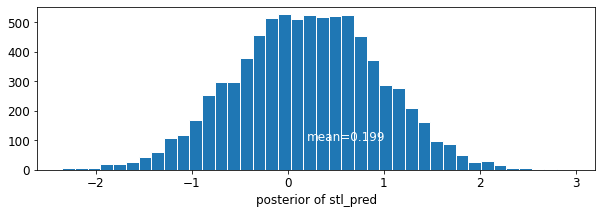
plot_traces('stl_pred', contextual_effects_pred_samples.stl_pred, num_chains=4)

plot_posterior('stl_pred', contextual_effects_pred_samples.stl_pred)
7 Kết luận
Lợi ích của Mô hình Đa cấp:
- Tính toán cấu trúc phân cấp tự nhiên của dữ liệu quan sát.
- Ước tính hệ số cho các nhóm (đại diện ít).
- Kết hợp thông tin cấp độ cá nhân và cấp độ nhóm khi ước tính hệ số cấp độ nhóm.
- Cho phép sự thay đổi giữa các hệ số cấp độ cá nhân giữa các nhóm.
Người giới thiệu
Gelman, A., & Hill, J. (2006). Phân tích dữ liệu sử dụng mô hình hồi quy và đa cấp / phân cấp (ấn bản đầu tiên). Nhà xuất bản Đại học Cambridge.
Gelman, A. (2006). Mô hình hóa đa cấp (Phân cấp): những gì nó có thể và không thể làm. Kỹ thuật số, 48 (3), 432–435.