
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Mô hình hiệu ứng hỗn hợp tuyến tính là một cách tiếp cận đơn giản để mô hình hóa các mối quan hệ tuyến tính có cấu trúc (Harville, 1997; Laird và Ware, 1982). Mỗi điểm dữ liệu bao gồm các đầu vào thuộc nhiều loại khác nhau — được phân loại thành các nhóm — và một đầu ra có giá trị thực. Một mô hình hiệu ứng hỗn hợp tuyến tính là một mô hình thứ bậc: nó chia sẻ sức mạnh thống kê giữa các nhóm nhằm nâng cao kết luận về bất kỳ điểm dữ liệu cá nhân.
Trong hướng dẫn này, chúng tôi trình bày các mô hình hiệu ứng hỗn hợp tuyến tính với một ví dụ trong thế giới thực trong TensorFlow Probability. Chúng tôi sẽ sử dụng JointDistributionCoroutine và Markov Chain Monte Carlo ( tfp.mcmc ) mô-đun.
Phụ thuộc & Điều kiện tiên quyết
Nhập và thiết lập
import csv
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import requests
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
dtype = tf.float64
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
plt.style.use('ggplot')
Làm cho mọi thứ trở nên nhanh chóng!
Trước khi đi sâu vào, hãy đảm bảo rằng chúng tôi đang sử dụng GPU cho bản trình diễn này.
Để thực hiện việc này, hãy chọn "Thời gian chạy" -> "Thay đổi loại thời gian chạy" -> "Trình tăng tốc phần cứng" -> "GPU".
Đoạn mã sau sẽ xác minh rằng chúng tôi có quyền truy cập vào GPU.
if tf.test.gpu_device_name() != '/device:GPU:0':
print('WARNING: GPU device not found.')
else:
print('SUCCESS: Found GPU: {}'.format(tf.test.gpu_device_name()))
SUCCESS: Found GPU: /device:GPU:0
Dữ liệu
Chúng tôi sử dụng InstEval tập dữ liệu từ phổ biến lme4 gói vào R (Bates et al., 2015). Nó là một tập hợp dữ liệu của các khóa học và xếp hạng đánh giá của họ. Mỗi khóa học bao gồm siêu dữ liệu như students , instructors , và departments , và biến phản ứng của lãi suất là giá đánh giá.
def load_insteval():
"""Loads the InstEval data set.
It contains 73,421 university lecture evaluations by students at ETH
Zurich with a total of 2,972 students, 2,160 professors and
lecturers, and several student, lecture, and lecturer attributes.
Implementation is built from the `observations` Python package.
Returns:
Tuple of np.ndarray `x_train` with 73,421 rows and 7 columns and
dictionary `metadata` of column headers (feature names).
"""
url = ('https://raw.github.com/vincentarelbundock/Rdatasets/master/csv/'
'lme4/InstEval.csv')
with requests.Session() as s:
download = s.get(url)
f = download.content.decode().splitlines()
iterator = csv.reader(f)
columns = next(iterator)[1:]
x_train = np.array([row[1:] for row in iterator], dtype=np.int)
metadata = {'columns': columns}
return x_train, metadata
Chúng tôi tải và xử lý trước tập dữ liệu. Chúng tôi giữ lại 20% dữ liệu để có thể đánh giá mô hình phù hợp của mình trên các điểm dữ liệu chưa nhìn thấy. Dưới đây chúng tôi hình dung một số hàng đầu tiên.
data, metadata = load_insteval()
data = pd.DataFrame(data, columns=metadata['columns'])
data = data.rename(columns={'s': 'students',
'd': 'instructors',
'dept': 'departments',
'y': 'ratings'})
data['students'] -= 1 # start index by 0
# Remap categories to start from 0 and end at max(category).
data['instructors'] = data['instructors'].astype('category').cat.codes
data['departments'] = data['departments'].astype('category').cat.codes
train = data.sample(frac=0.8)
test = data.drop(train.index)
train.head()
Chúng tôi thiết lập bộ dữ liệu về một features từ điển của đầu vào và một labels đầu ra tương ứng với xếp hạng. Mỗi đối tượng địa lý được mã hóa dưới dạng số nguyên và mỗi nhãn (xếp hạng đánh giá) được mã hóa dưới dạng số dấu phẩy động.
get_value = lambda dataframe, key, dtype: dataframe[key].values.astype(dtype)
features_train = {
k: get_value(train, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_train = get_value(train, key='ratings', dtype=np.float32)
features_test = {k: get_value(test, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_test = get_value(test, key='ratings', dtype=np.float32)
num_students = max(features_train['students']) + 1
num_instructors = max(features_train['instructors']) + 1
num_departments = max(features_train['departments']) + 1
num_observations = train.shape[0]
print("Number of students:", num_students)
print("Number of instructors:", num_instructors)
print("Number of departments:", num_departments)
print("Number of observations:", num_observations)
Number of students: 2972 Number of instructors: 1128 Number of departments: 14 Number of observations: 58737
Mô hình
Một mô hình tuyến tính điển hình giả định sự độc lập, trong đó bất kỳ cặp điểm dữ liệu nào cũng có mối quan hệ tuyến tính không đổi. Trong InstEval bộ dữ liệu, quan sát phát sinh trong nhóm mỗi trong số đó có thể có độ dốc khác nhau và chặn. Mô hình hiệu ứng hỗn hợp tuyến tính, còn được gọi là mô hình tuyến tính phân cấp hoặc mô hình tuyến tính đa cấp, nắm bắt được hiện tượng này (Gelman & Hill, 2006).
Ví dụ về hiện tượng này bao gồm:
- Học sinh. Các quan sát từ một sinh viên không độc lập: một số sinh viên có thể đưa ra xếp hạng bài giảng thấp (hoặc cao) một cách có hệ thống.
- Giảng viên. Các quan sát từ một giảng viên không độc lập: chúng tôi mong đợi những giáo viên giỏi thường có xếp hạng tốt và giáo viên tồi thường có xếp hạng xấu.
- Sở. Các quan sát từ một bộ phận không độc lập: một số bộ phận thường có thể có nguyên liệu khô hoặc phân loại chặt chẽ hơn và do đó được đánh giá thấp hơn các bộ phận khác.
Để chụp này, nhớ lại rằng cho một tập dữ liệu \(N\times D\) tính năng \(\mathbf{X}\) và \(N\) nhãn \(\mathbf{y}\), thừa nhận hồi quy tuyến tính mô hình
\[ \begin{equation*} \mathbf{y} = \mathbf{X}\beta + \alpha + \epsilon, \end{equation*} \]
nơi có một vector dốc \(\beta\in\mathbb{R}^D\), chặn \(\alpha\in\mathbb{R}\), và tiếng ồn ngẫu nhiên \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). Chúng ta nói rằng \(\beta\) và \(\alpha\) là "hiệu ứng cố định": họ là tác tổ chức liên tục trên dân số của các điểm dữ liệu \((x, y)\). Một công thức tương đương của phương trình như một khả năng là \(\mathbf{y} \sim \text{Normal}(\mathbf{X}\beta + \alpha, \mathbf{I})\). Khả năng này là tối đa trong quá trình suy luận để tìm ra các ước lượng điểm của \(\beta\) và \(\alpha\) phù hợp với các dữ liệu.
Mô hình hiệu ứng hỗn hợp tuyến tính mở rộng hồi quy tuyến tính như
\[ \begin{align*} \eta &\sim \text{Normal}(\mathbf{0}, \sigma^2 \mathbf{I}), \\ \mathbf{y} &= \mathbf{X}\beta + \mathbf{Z}\eta + \alpha + \epsilon. \end{align*} \]
nơi vẫn còn là một vector dốc \(\beta\in\mathbb{R}^P\), chặn \(\alpha\in\mathbb{R}\), và tiếng ồn ngẫu nhiên \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). Ngoài ra, còn là một thuật ngữ \(\mathbf{Z}\eta\), nơi \(\mathbf{Z}\) là một ma trận các tính năng và \(\eta\in\mathbb{R}^Q\) là một vector của sườn ngẫu nhiên; \(\eta\) thường được phân phối với tham số thành phần sai \(\sigma^2\). \(\mathbf{Z}\) được hình thành bằng cách phân vùng gốc \(N\times D\) tính năng ma trận trong điều khoản của một mới \(N\times P\) ma trận \(\mathbf{X}\) và \(N\times Q\) ma trận \(\mathbf{Z}\), nơi \(P + Q=D\): phân vùng này cho phép chúng tôi để mô hình các tính năng riêng biệt sử dụng những tác động cố định \(\beta\) và biến tiềm ẩn \(\eta\) tương ứng.
Chúng ta nói các biến tiềm ẩn \(\eta\) là "hiệu ứng ngẫu nhiên": họ là hiệu ứng khác nhau giữa dân số (mặc dù họ có thể liên tục trên subpopulations). Đặc biệt, vì những tác động ngẫu nhiên \(\eta\) có nghĩa là 0, có nghĩa là các nhãn dữ liệu được bắt bởi \(\mathbf{X}\beta + \alpha\). Các hiệu ứng ngẫu nhiên thành phần \(\mathbf{Z}\eta\) chụp biến thể trong các dữ liệu: ví dụ, "Người hướng dẫn # 54 được đánh giá 1,4 điểm cao hơn so với giá trị trung bình."
Trong hướng dẫn này, chúng tôi đặt các hiệu ứng sau:
- Hiệu ứng cố định:
service.servicelà một covariate nhị phân tương ứng với liệu trình này thuộc về bộ phận chính của người hướng dẫn. Không có vấn đề chúng tôi thu thập bao nhiêu dữ liệu bổ sung, nó chỉ có thể đưa vào giá trị \(0\) và \(1\). - Hiệu ứng ngẫu nhiên:
students,instructors, vàdepartments. Với nhiều quan sát hơn từ dân số xếp hạng đánh giá khóa học, chúng tôi có thể đang xem xét các sinh viên, giáo viên hoặc bộ phận mới.
Theo cú pháp của gói lme4 của R (Bates và cộng sự, 2015), mô hình có thể được tóm tắt là
ratings ~ service + (1|students) + (1|instructors) + (1|departments) + 1
nơi x biểu thị một hiệu ứng cố định, (1|x) biểu thị một hiệu ứng ngẫu nhiên cho x , và 1 biểu thị một thuật ngữ đánh chặn.
Chúng tôi triển khai mô hình này bên dưới dưới dạng Phân phối chung. Để có hỗ trợ tốt hơn cho việc theo dõi thông số (ví dụ, chúng ta muốn theo dõi tất cả các tf.Variable trong model.trainable_variables ), chúng tôi thực hiện các mô hình mẫu như tf.Module .
class LinearMixedEffectModel(tf.Module):
def __init__(self):
# Set up fixed effects and other parameters.
# These are free parameters to be optimized in E-steps
self._intercept = tf.Variable(0., name="intercept") # alpha in eq
self._effect_service = tf.Variable(0., name="effect_service") # beta in eq
self._stddev_students = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_students") # sigma in eq
self._stddev_instructors = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_instructors") # sigma in eq
self._stddev_departments = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_departments") # sigma in eq
def __call__(self, features):
model = tfd.JointDistributionSequential([
# Set up random effects.
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_students),
scale_identity_multiplier=self._stddev_students),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_instructors),
scale_identity_multiplier=self._stddev_instructors),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_departments),
scale_identity_multiplier=self._stddev_departments),
# This is the likelihood for the observed.
lambda effect_departments, effect_instructors, effect_students: tfd.Independent(
tfd.Normal(
loc=(self._effect_service * features["service"] +
tf.gather(effect_students, features["students"], axis=-1) +
tf.gather(effect_instructors, features["instructors"], axis=-1) +
tf.gather(effect_departments, features["departments"], axis=-1) +
self._intercept),
scale=1.),
reinterpreted_batch_ndims=1)
])
# To enable tracking of the trainable variables via the created distribution,
# we attach a reference to `self`. Since all TFP objects sub-class
# `tf.Module`, this means that the following is possible:
# LinearMixedEffectModel()(features_train).trainable_variables
# ==> tuple of all tf.Variables created by LinearMixedEffectModel.
model._to_track = self
return model
lmm_jointdist = LinearMixedEffectModel()
# Conditioned on feature/predictors from the training data
lmm_train = lmm_jointdist(features_train)
lmm_train.trainable_variables
(<tf.Variable 'stddev_students:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_instructors:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_departments:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'effect_service:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'intercept:0' shape=() dtype=float32, numpy=0.0>)
Là một chương trình đồ họa Xác suất, chúng ta cũng có thể hình dung cấu trúc của mô hình dưới dạng đồ thị tính toán của nó. Biểu đồ này mã hóa luồng dữ liệu qua các biến ngẫu nhiên trong chương trình, làm rõ mối quan hệ của chúng dưới dạng mô hình đồ họa (Jordan, 2003).
Là một công cụ thống kê, chúng ta có thể nhìn vào đồ thị để tốt hơn xem, ví dụ, rằng intercept và effect_service là điều kiện cho phụ thuộc ratings ; điều này có thể khó thấy hơn từ mã nguồn nếu chương trình được viết với các lớp, các tham chiếu chéo giữa các mô-đun và / hoặc các chương trình con. Là một công cụ tính toán, chúng tôi cũng có thể nhận thấy các biến tiềm ẩn chảy vào ratings biến qua tf.gather ops. Đây có thể là một nút cổ chai trên tăng tốc phần cứng nhất định nếu chỉ mục Tensor s là tốn kém; trực quan hóa biểu đồ làm cho điều này trở nên rõ ràng.
lmm_train.resolve_graph()
(('effect_students', ()),
('effect_instructors', ()),
('effect_departments', ()),
('x', ('effect_departments', 'effect_instructors', 'effect_students')))
Ước tính tham số
Với dữ liệu, mục tiêu của suy luận là để phù hợp của mô hình tác động cố định dốc \(\beta\), chặn \(\alpha\), và phương sai tham số thành phần \(\sigma^2\). Nguyên tắc khả năng xảy ra tối đa chính thức hóa nhiệm vụ này là
\[ \max_{\beta, \alpha, \sigma}~\log p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}; \beta, \alpha, \sigma) = \max_{\beta, \alpha, \sigma}~\log \int p(\eta; \sigma) ~p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}, \eta; \beta, \alpha)~d\eta. \]
Trong hướng dẫn này, chúng tôi sử dụng thuật toán Monte Carlo EM để tối đa hóa mật độ biên này (Dempster và cộng sự, 1977; Wei và Tanner, 1990) .¹ Chúng tôi thực hiện chuỗi Markov Monte Carlo để tính toán kỳ vọng của khả năng có điều kiện đối với hiệu ứng ngẫu nhiên ("E-step") và chúng tôi thực hiện giảm độ dốc để tối đa hóa kỳ vọng đối với các tham số ("M-step"):
Đối với bước E, chúng tôi thiết lập Hamilton Monte Carlo (HMC). Nó có một trạng thái hiện tại — ảnh hưởng của sinh viên, người hướng dẫn và bộ phận — và trả về một trạng thái mới. Chúng tôi gán trạng thái mới cho các biến TensorFlow, biến này sẽ biểu thị trạng thái của chuỗi HMC.
Đối với bước M, chúng tôi sử dụng mẫu sau từ HMC để tính toán ước tính không chệch về khả năng cận biên lên đến một hằng số. Sau đó, chúng tôi áp dụng gradient của nó đối với các tham số quan tâm. Điều này tạo ra một bước giảm ngẫu nhiên không thiên vị về khả năng cận biên. Chúng tôi triển khai nó với trình tối ưu hóa Adam TensorFlow và giảm thiểu tiêu cực của lề.
target_log_prob_fn = lambda *x: lmm_train.log_prob(x + (labels_train,))
trainable_variables = lmm_train.trainable_variables
current_state = lmm_train.sample()[:-1]
# For debugging
target_log_prob_fn(*current_state)
<tf.Tensor: shape=(), dtype=float32, numpy=-528062.5>
# Set up E-step (MCMC).
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.015,
num_leapfrog_steps=3)
kernel_results = hmc.bootstrap_results(current_state)
@tf.function(autograph=False, jit_compile=True)
def one_e_step(current_state, kernel_results):
next_state, next_kernel_results = hmc.one_step(
current_state=current_state,
previous_kernel_results=kernel_results)
return next_state, next_kernel_results
optimizer = tf.optimizers.Adam(learning_rate=.01)
# Set up M-step (gradient descent).
@tf.function(autograph=False, jit_compile=True)
def one_m_step(current_state):
with tf.GradientTape() as tape:
loss = -target_log_prob_fn(*current_state)
grads = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss
Chúng tôi thực hiện giai đoạn khởi động, chạy một chuỗi MCMC cho một số lần lặp lại để quá trình huấn luyện có thể được khởi tạo trong phạm vi xác suất của phần sau. Sau đó chúng tôi chạy một vòng đào tạo. Nó cùng chạy các bước E và M và ghi lại các giá trị trong quá trình đào tạo.
num_warmup_iters = 1000
num_iters = 1500
num_accepted = 0
effect_students_samples = np.zeros([num_iters, num_students])
effect_instructors_samples = np.zeros([num_iters, num_instructors])
effect_departments_samples = np.zeros([num_iters, num_departments])
loss_history = np.zeros([num_iters])
# Run warm-up stage.
for t in range(num_warmup_iters):
current_state, kernel_results = one_e_step(current_state, kernel_results)
num_accepted += kernel_results.is_accepted.numpy()
if t % 500 == 0 or t == num_warmup_iters - 1:
print("Warm-Up Iteration: {:>3} Acceptance Rate: {:.3f}".format(
t, num_accepted / (t + 1)))
num_accepted = 0 # reset acceptance rate counter
# Run training.
for t in range(num_iters):
# run 5 MCMC iterations before every joint EM update
for _ in range(5):
current_state, kernel_results = one_e_step(current_state, kernel_results)
loss = one_m_step(current_state)
effect_students_samples[t, :] = current_state[0].numpy()
effect_instructors_samples[t, :] = current_state[1].numpy()
effect_departments_samples[t, :] = current_state[2].numpy()
num_accepted += kernel_results.is_accepted.numpy()
loss_history[t] = loss.numpy()
if t % 500 == 0 or t == num_iters - 1:
print("Iteration: {:>4} Acceptance Rate: {:.3f} Loss: {:.3f}".format(
t, num_accepted / (t + 1), loss_history[t]))
Warm-Up Iteration: 0 Acceptance Rate: 1.000 Warm-Up Iteration: 500 Acceptance Rate: 0.754 Warm-Up Iteration: 999 Acceptance Rate: 0.707 Iteration: 0 Acceptance Rate: 1.000 Loss: 98220.266 Iteration: 500 Acceptance Rate: 0.703 Loss: 96003.969 Iteration: 1000 Acceptance Rate: 0.678 Loss: 95958.609 Iteration: 1499 Acceptance Rate: 0.685 Loss: 95921.891
Bạn cũng có thể viết hâm lại cho vòng lặp thành một tf.while_loop , và bước đào tạo thành một tf.scan hoặc tf.while_loop cho thậm chí nhanh hơn suy luận. Ví dụ:
@tf.function(autograph=False, jit_compile=True)
def run_k_e_steps(k, current_state, kernel_results):
_, next_state, next_kernel_results = tf.while_loop(
cond=lambda i, state, pkr: i < k,
body=lambda i, state, pkr: (i+1, *one_e_step(state, pkr)),
loop_vars=(tf.constant(0), current_state, kernel_results)
)
return next_state, next_kernel_results
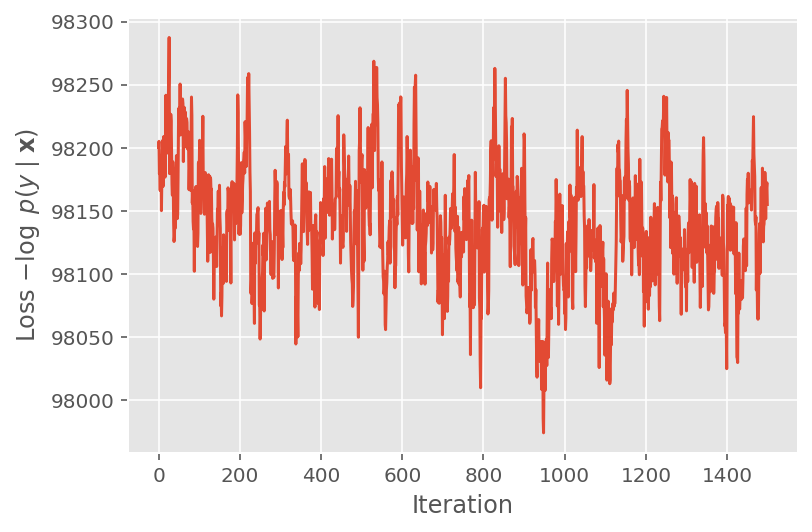
Ở trên, chúng tôi đã không chạy thuật toán cho đến khi phát hiện thấy ngưỡng hội tụ. Để kiểm tra xem việc đào tạo có hợp lý hay không, chúng tôi xác minh rằng hàm mất mát thực sự có xu hướng hội tụ qua các lần lặp lại đào tạo.
plt.plot(loss_history)
plt.ylabel(r'Loss $-\log$ $p(y\mid\mathbf{x})$')
plt.xlabel('Iteration')
plt.show()
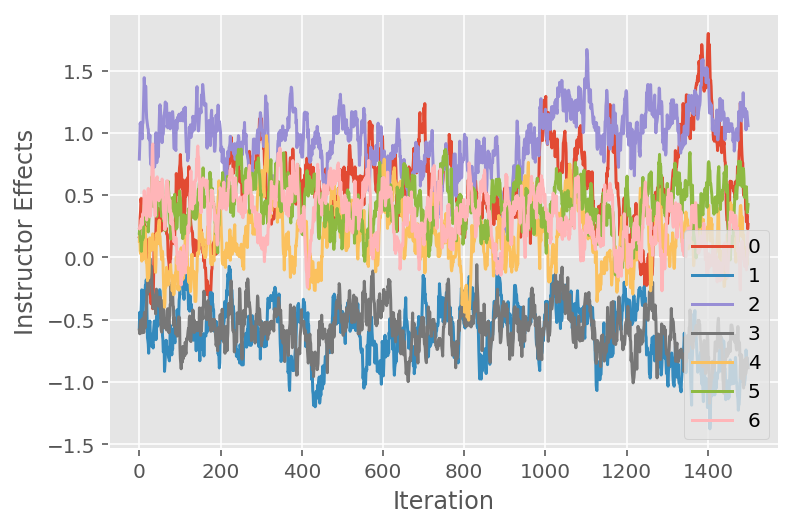
Chúng tôi cũng sử dụng một biểu đồ theo dõi, cho thấy quỹ đạo của thuật toán Markov chuỗi Monte Carlo trên các kích thước tiềm ẩn cụ thể. Dưới đây, chúng tôi thấy rằng các hiệu ứng hướng dẫn cụ thể thực sự chuyển đổi có ý nghĩa khỏi trạng thái ban đầu của chúng và khám phá không gian trạng thái. Biểu đồ theo dõi cũng chỉ ra rằng các hiệu ứng khác nhau giữa các giảng viên nhưng với hành vi trộn tương tự.
for i in range(7):
plt.plot(effect_instructors_samples[:, i])
plt.legend([i for i in range(7)], loc='lower right')
plt.ylabel('Instructor Effects')
plt.xlabel('Iteration')
plt.show()
Sự chỉ trích
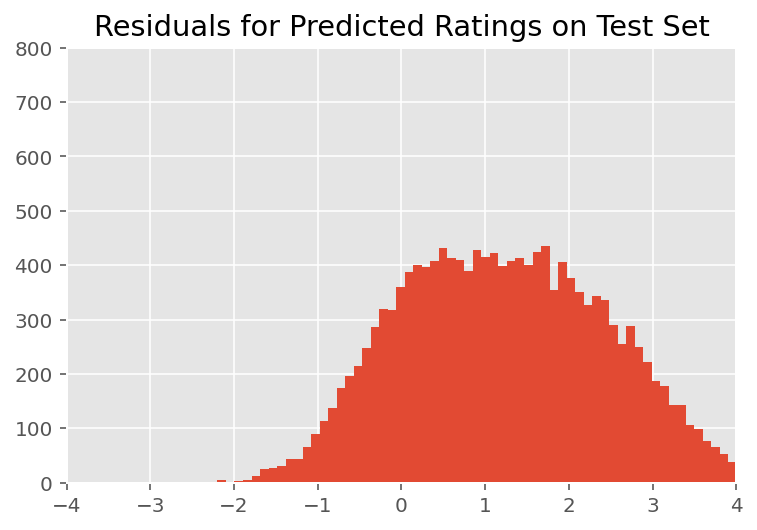
Ở trên, chúng tôi đã lắp mô hình. Bây giờ chúng tôi xem xét việc chỉ trích sự phù hợp của nó bằng cách sử dụng dữ liệu, điều này cho phép chúng tôi khám phá và hiểu rõ hơn về mô hình. Một trong những kỹ thuật như vậy là một đồ thị còn lại, biểu đồ sự khác biệt giữa các dự đoán của mô hình và sự thật cơ bản cho mỗi điểm dữ liệu. Nếu mô hình là chính xác, thì sự khác biệt của chúng phải được phân phối chuẩn; bất kỳ sai lệch nào so với mô hình này trong biểu đồ cho thấy mô hình không phù hợp.
Chúng tôi xây dựng biểu đồ còn lại bằng cách đầu tiên hình thành phân phối dự đoán sau so với xếp hạng, phân phối này thay thế phân phối trước về các tác động ngẫu nhiên bằng dữ liệu đào tạo đã cho sau của nó. Đặc biệt, chúng tôi chạy mô hình về phía trước và ngăn chặn sự phụ thuộc của nó vào các tác động ngẫu nhiên trước đó bằng các phương tiện sau được suy luận của chúng.²
lmm_test = lmm_jointdist(features_test)
[
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
] = [
np.mean(x, axis=0).astype(np.float32) for x in [
effect_students_samples,
effect_instructors_samples,
effect_departments_samples
]
]
# Get the posterior predictive distribution
(*posterior_conditionals, ratings_posterior), _ = lmm_test.sample_distributions(
value=(
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
))
ratings_prediction = ratings_posterior.mean()
Khi kiểm tra bằng mắt thường, phần còn lại trông hơi chuẩn và được phân phối bình thường. Tuy nhiên, sự phù hợp không phải là hoàn hảo: có khối lượng xác suất lớn hơn ở các phần đuôi so với phân phối chuẩn, điều này cho thấy mô hình có thể cải thiện sự phù hợp của nó bằng cách giảm bớt các giả định về tính chuẩn của nó.
Đặc biệt, mặc dù nó là hầu hết thường sử dụng một phân phối chuẩn để xếp hạng mô hình trong InstEval bộ dữ liệu, xem xét kỹ hơn các dữ liệu cho thấy xếp hạng đánh giá tất nhiên là ở giá trị thứ tự thực tế từ 1 đến 5. Điều này cho thấy chúng ta nên sử dụng phân phối theo thứ tự, hoặc thậm chí là Phân loại nếu chúng ta có đủ dữ liệu để loại bỏ thứ tự tương đối. Đây là thay đổi một dòng đối với mô hình trên; cùng một mã suy luận được áp dụng.
plt.title("Residuals for Predicted Ratings on Test Set")
plt.xlim(-4, 4)
plt.ylim(0, 800)
plt.hist(ratings_prediction - labels_test, 75)
plt.show()
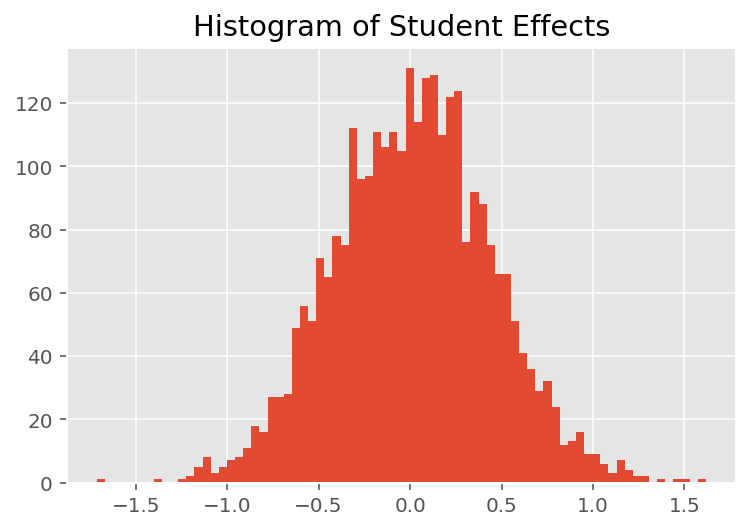
Để khám phá cách mô hình đưa ra các dự đoán riêng lẻ, chúng tôi xem xét biểu đồ hiệu ứng đối với sinh viên, giáo viên hướng dẫn và các phòng ban. Điều này cho phép chúng tôi hiểu các yếu tố riêng lẻ trong vectơ đặc trưng của điểm dữ liệu có xu hướng ảnh hưởng như thế nào đến kết quả.
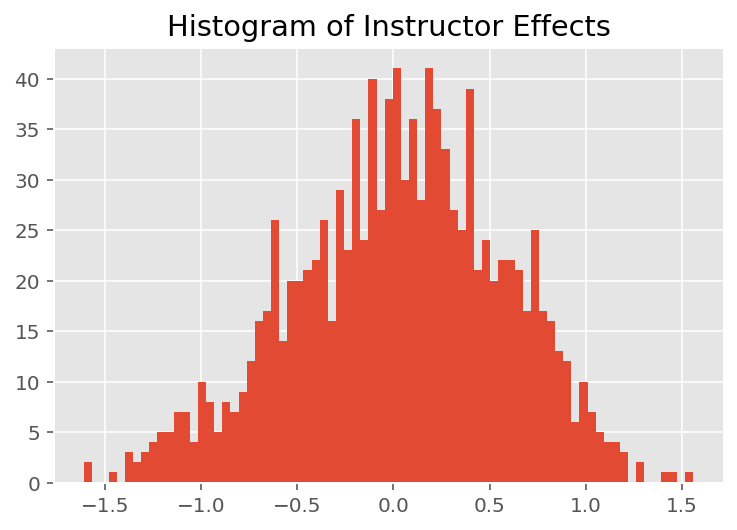
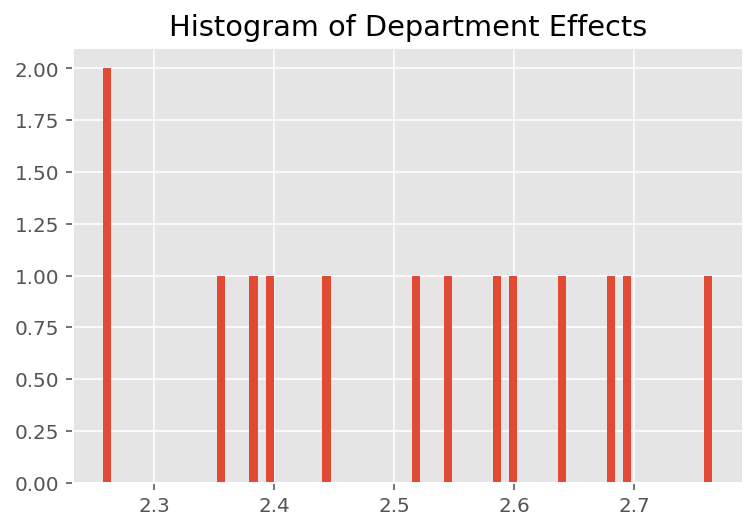
Không có gì ngạc nhiên khi chúng tôi thấy bên dưới rằng mỗi sinh viên thường ít ảnh hưởng đến xếp hạng đánh giá của giảng viên. Điều thú vị là chúng tôi thấy rằng bộ phận mà một người hướng dẫn thuộc về có ảnh hưởng lớn.
plt.title("Histogram of Student Effects")
plt.hist(effect_students_mean, 75)
plt.show()
plt.title("Histogram of Instructor Effects")
plt.hist(effect_instructors_mean, 75)
plt.show()
plt.title("Histogram of Department Effects")
plt.hist(effect_departments_mean, 75)
plt.show()
Chú thích
¹ Mô hình hiệu ứng hỗn hợp tuyến tính là một trường hợp đặc biệt mà chúng ta có thể tính toán phân tích mật độ biên của nó. Với mục đích của hướng dẫn này, chúng tôi chứng minh Monte Carlo EM, áp dụng dễ dàng hơn cho các mật độ biên không phân tích, chẳng hạn như nếu khả năng được mở rộng thành Phân loại thay vì Bình thường.
² Để đơn giản, chúng tôi hình thành giá trị trung bình của phân phối dự đoán chỉ sử dụng một lần chuyển tiếp của mô hình. Điều này được thực hiện bằng cách điều hòa trên giá trị trung bình sau và có giá trị đối với các mô hình hiệu ứng hỗn hợp tuyến tính. Tuy nhiên, điều này nói chung là không hợp lệ: giá trị trung bình của phân phối tiên đoán phía sau thường khó xác định và yêu cầu lấy giá trị trung bình thực nghiệm qua nhiều lần chuyển tiếp của mô hình đã cho các mẫu phía sau.
Sự nhìn nhận
Hướng dẫn này ban đầu được viết bằng Edward 1.0 ( nguồn ). Chúng tôi cảm ơn tất cả những người đóng góp để viết và sửa đổi phiên bản đó.
Người giới thiệu
Douglas Bates và Martin Machler và Ben Bolker và Steve Walker. Phù hợp với các mô hình hiệu ứng hỗn hợp tuyến tính bằng lme4. Tạp chí phần mềm thống kê, 67 (1): 1-48 năm 2015.
Arthur P. Dempster, Nan M. Laird và Donald B. Rubin. Khả năng tối đa từ dữ liệu không đầy đủ thông qua thuật toán EM. Tạp chí của Hiệp hội thống kê Hoàng gia, Series B (phương pháp), 1-38, 1977.
Andrew Gelman và Jennifer Hill. Phân tích dữ liệu bằng cách sử dụng mô hình hồi quy và đa cấp / phân cấp. Nhà xuất bản Đại học Cambridge, 2006.
David A. Harville. Các phương pháp tiếp cận khả năng tối đa để ước lượng thành phần phương sai và các vấn đề liên quan. Tạp chí của Hiệp hội thống kê Mỹ, 72 tuổi (358): 320-338, 1977.
Michael I. Jordan. Giới thiệu về Mô hình đồ họa. Báo cáo kỹ thuật, 2003.
Nan M. Laird và James Ware. Mô hình hiệu ứng ngẫu nhiên cho dữ liệu dọc. Sinh trắc học, 963-974, 1982.
Greg Wei và Martin A. Tanner. Monte Carlo triển khai thuật toán EM và các thuật toán tăng dữ liệu của người nghèo. Tạp chí của Hiệp hội thống kê Mỹ, 699-704, 1990.