
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Un modèle linéaire à effets mixtes est une approche simple pour modéliser des relations linéaires structurées (Harville, 1997; Laird et Ware, 1982). Chaque point de données se compose d'entrées de différents types, classées en groupes, et d'une sortie à valeur réelle. Un modèle linéaire à effets mixtes est un modèle hiérarchique: il partage la force statistique entre les groupes, afin d'améliorer des conclusions sur tout point de données individuel.
Dans ce didacticiel, nous montrons des modèles linéaires à effets mixtes avec un exemple réel dans TensorFlow Probability. Nous allons utiliser le JointDistributionCoroutine et chaînes de Markov Monte Carlo ( tfp.mcmc Modules).
Dépendances et prérequis
Importer et configurer
import csv
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import requests
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
dtype = tf.float64
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
plt.style.use('ggplot')
Faites les choses rapidement !
Avant de plonger, assurons-nous que nous utilisons un GPU pour cette démo.
Pour ce faire, sélectionnez "Runtime" -> "Modifier le type d'exécution" -> "Accélérateur matériel" -> "GPU".
L'extrait suivant vérifiera que nous avons accès à un GPU.
if tf.test.gpu_device_name() != '/device:GPU:0':
print('WARNING: GPU device not found.')
else:
print('SUCCESS: Found GPU: {}'.format(tf.test.gpu_device_name()))
SUCCESS: Found GPU: /device:GPU:0
Données
Nous utilisons les InstEval ensemble des données de la populaire lme4 package dans R (Bates et al., 2015). Il s'agit d'un ensemble de données sur les cours et leurs notes d'évaluation. Chaque cours comprend des métadonnées telles que les students , les instructors et les departments , et la variable de réponse d'intérêt est la cote d'évaluation.
def load_insteval():
"""Loads the InstEval data set.
It contains 73,421 university lecture evaluations by students at ETH
Zurich with a total of 2,972 students, 2,160 professors and
lecturers, and several student, lecture, and lecturer attributes.
Implementation is built from the `observations` Python package.
Returns:
Tuple of np.ndarray `x_train` with 73,421 rows and 7 columns and
dictionary `metadata` of column headers (feature names).
"""
url = ('https://raw.github.com/vincentarelbundock/Rdatasets/master/csv/'
'lme4/InstEval.csv')
with requests.Session() as s:
download = s.get(url)
f = download.content.decode().splitlines()
iterator = csv.reader(f)
columns = next(iterator)[1:]
x_train = np.array([row[1:] for row in iterator], dtype=np.int)
metadata = {'columns': columns}
return x_train, metadata
Nous chargeons et prétraitons l'ensemble de données. Nous conservons 20 % des données afin de pouvoir évaluer notre modèle ajusté sur des points de données invisibles. Ci-dessous, nous visualisons les premières lignes.
data, metadata = load_insteval()
data = pd.DataFrame(data, columns=metadata['columns'])
data = data.rename(columns={'s': 'students',
'd': 'instructors',
'dept': 'departments',
'y': 'ratings'})
data['students'] -= 1 # start index by 0
# Remap categories to start from 0 and end at max(category).
data['instructors'] = data['instructors'].astype('category').cat.codes
data['departments'] = data['departments'].astype('category').cat.codes
train = data.sample(frac=0.8)
test = data.drop(train.index)
train.head()
Nous avons mis en place l'ensemble de données en termes de features dictionnaire des entrées et des labels sortie correspondant aux évaluations. Chaque caractéristique est codée sous forme d'entier et chaque étiquette (cote d'évaluation) est codée sous forme de nombre à virgule flottante.
get_value = lambda dataframe, key, dtype: dataframe[key].values.astype(dtype)
features_train = {
k: get_value(train, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_train = get_value(train, key='ratings', dtype=np.float32)
features_test = {k: get_value(test, key=k, dtype=np.int32)
for k in ['students', 'instructors', 'departments', 'service']}
labels_test = get_value(test, key='ratings', dtype=np.float32)
num_students = max(features_train['students']) + 1
num_instructors = max(features_train['instructors']) + 1
num_departments = max(features_train['departments']) + 1
num_observations = train.shape[0]
print("Number of students:", num_students)
print("Number of instructors:", num_instructors)
print("Number of departments:", num_departments)
print("Number of observations:", num_observations)
Number of students: 2972 Number of instructors: 1128 Number of departments: 14 Number of observations: 58737
Modèle
Un modèle linéaire typique suppose l'indépendance, où toute paire de points de données a une relation linéaire constante. Dans le InstEval ensemble de données, les observations se posent en groupes dont chacun peut avoir différentes pentes et Intercepts. Les modèles linéaires à effets mixtes, également appelés modèles linéaires hiérarchiques ou modèles linéaires multiniveaux, capturent ce phénomène (Gelman & Hill, 2006).
Voici des exemples de ce phénomène :
- Les étudiants. Les observations d'un étudiant ne sont pas indépendantes : certains étudiants peuvent systématiquement donner des notes de cours faibles (ou élevées).
- Les instructeurs. Les observations d'un instructeur ne sont pas indépendantes : nous nous attendons à ce que les bons enseignants aient généralement de bonnes notes et que les mauvais enseignants aient généralement de mauvaises notes.
- Départements. Les observations d'un département ne sont pas indépendantes : certains départements peuvent généralement avoir de la matière sèche ou un classement plus strict et donc être moins bien notés que d'autres.
Pour capturer cela, rappelons que pour un ensemble de données de \(N\times D\) dispose \(\mathbf{X}\) et \(N\) étiquettes \(\mathbf{y}\), régression linéaire pose le modèle
\[ \begin{equation*} \mathbf{y} = \mathbf{X}\beta + \alpha + \epsilon, \end{equation*} \]
où il y a un vecteur de pente \(\beta\in\mathbb{R}^D\), intercepter \(\alpha\in\mathbb{R}\), et le bruit aléatoire \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). Nous disons que \(\beta\) et \(\alpha\) sont « effets fixes »: ils sont des effets étant demeurées constantes dans la population de points de données \((x, y)\). Une formulation équivalente de l'équation en tant que probabilité est \(\mathbf{y} \sim \text{Normal}(\mathbf{X}\beta + \alpha, \mathbf{I})\). Cette probabilité est maximisée lors de l' inférence afin de trouver des estimations ponctuelles de \(\beta\) et \(\alpha\) qui correspondent aux données.
Un modèle linéaire à effets mixtes étend la régression linéaire comme
\[ \begin{align*} \eta &\sim \text{Normal}(\mathbf{0}, \sigma^2 \mathbf{I}), \\ \mathbf{y} &= \mathbf{X}\beta + \mathbf{Z}\eta + \alpha + \epsilon. \end{align*} \]
où il y a encore un vecteur de pente \(\beta\in\mathbb{R}^P\), intercepter \(\alpha\in\mathbb{R}\), et le bruit aléatoire \(\epsilon\sim\text{Normal}(\mathbf{0}, \mathbf{I})\). En outre, il y a un terme \(\mathbf{Z}\eta\), où \(\mathbf{Z}\) est une matrice de caractéristiques et \(\eta\in\mathbb{R}^Q\) est un vecteur de pentes aléatoires; \(\eta\) est normalement distribuée avec le paramètre de composante de variance \(\sigma^2\). \(\mathbf{Z}\) est formé en divisant l'original \(N\times D\) propose matrice en termes d'une nouvelle \(N\times P\) matrice \(\mathbf{X}\) et \(N\times Q\) matrice \(\mathbf{Z}\), où \(P + Q=D\): cette partition nous permet de modéliser les caractéristiques séparément à l' aide les effets fixes \(\beta\) et la variable latente \(\eta\) respectivement.
Nous disons que les variables latentes \(\eta\) sont des « effets aléatoires »: ils sont des effets qui varient selon la population (même si elles peuvent être constantes à travers les sous - populations). En particulier, parce que les effets aléatoires \(\eta\) ont une moyenne de 0, la moyenne de l'étiquette de données est capturée par \(\mathbf{X}\beta + \alpha\). Les composants effets aléatoires \(\mathbf{Z}\eta\) captures variations dans les données: par exemple, « instructeur # 54 est évalué de 1,4 point supérieur à la moyenne. »
Dans ce tutoriel, nous posons les effets suivants :
- Effets fixes:
service. leserviceest un covariable binaire correspondant si le cours appartient au département principal de l'instructeur. Peu importe la quantité de données supplémentaires que nous recueillons, il ne peut prendre des valeurs \(0\) et \(1\). - Effets aléatoires: les
students, lesinstructorset lesdepartments. Compte tenu de plus d'observations de la population des cotes d'évaluation des cours, nous pouvons envisager de nouveaux étudiants, enseignants ou départements.
Dans la syntaxe du package lme4 de R (Bates et al., 2015), le modèle peut être résumé comme suit
ratings ~ service + (1|students) + (1|instructors) + (1|departments) + 1
où x désigne un effet fixe, (1|x) désigne un effet aléatoire pour x , et 1 désigne un terme d'interception.
Nous implémentons ce modèle ci-dessous en tant que JointDistribution. Pour avoir un meilleur support pour le suivi des paramètres (par exemple, nous voulons suivre tous les tf.Variable en model.trainable_variables ), nous mettre en œuvre le modèle de modèle comme tf.Module .
class LinearMixedEffectModel(tf.Module):
def __init__(self):
# Set up fixed effects and other parameters.
# These are free parameters to be optimized in E-steps
self._intercept = tf.Variable(0., name="intercept") # alpha in eq
self._effect_service = tf.Variable(0., name="effect_service") # beta in eq
self._stddev_students = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_students") # sigma in eq
self._stddev_instructors = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_instructors") # sigma in eq
self._stddev_departments = tfp.util.TransformedVariable(
1., bijector=tfb.Exp(), name="stddev_departments") # sigma in eq
def __call__(self, features):
model = tfd.JointDistributionSequential([
# Set up random effects.
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_students),
scale_identity_multiplier=self._stddev_students),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_instructors),
scale_identity_multiplier=self._stddev_instructors),
tfd.MultivariateNormalDiag(
loc=tf.zeros(num_departments),
scale_identity_multiplier=self._stddev_departments),
# This is the likelihood for the observed.
lambda effect_departments, effect_instructors, effect_students: tfd.Independent(
tfd.Normal(
loc=(self._effect_service * features["service"] +
tf.gather(effect_students, features["students"], axis=-1) +
tf.gather(effect_instructors, features["instructors"], axis=-1) +
tf.gather(effect_departments, features["departments"], axis=-1) +
self._intercept),
scale=1.),
reinterpreted_batch_ndims=1)
])
# To enable tracking of the trainable variables via the created distribution,
# we attach a reference to `self`. Since all TFP objects sub-class
# `tf.Module`, this means that the following is possible:
# LinearMixedEffectModel()(features_train).trainable_variables
# ==> tuple of all tf.Variables created by LinearMixedEffectModel.
model._to_track = self
return model
lmm_jointdist = LinearMixedEffectModel()
# Conditioned on feature/predictors from the training data
lmm_train = lmm_jointdist(features_train)
lmm_train.trainable_variables
(<tf.Variable 'stddev_students:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_instructors:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'stddev_departments:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'effect_service:0' shape=() dtype=float32, numpy=0.0>, <tf.Variable 'intercept:0' shape=() dtype=float32, numpy=0.0>)
En tant que programme graphique probabiliste, nous pouvons également visualiser la structure du modèle en termes de son graphe de calcul. Ce graphique code le flux de données à travers les variables aléatoires du programme, rendant explicites leurs relations en termes de modèle graphique (Jordan, 2003).
En tant qu'outil statistique, nous pourrions examiner le graphique afin de mieux voir, par exemple, d' intercept et effect_service conditionnellement dépendants données ratings ; cela peut être plus difficile à voir à partir du code source si le programme est écrit avec des classes, des références croisées entre les modules et/ou des sous-routines. En tant qu'outil de calcul, on peut également remarquer des variables latentes se déversent dans les ratings variables par tf.gather ops. Cela peut être un goulot d' étranglement sur certains accélérateurs matériels si l' indexation Tensor s est cher; la visualisation du graphique rend cela facilement apparent.
lmm_train.resolve_graph()
(('effect_students', ()),
('effect_instructors', ()),
('effect_departments', ()),
('x', ('effect_departments', 'effect_instructors', 'effect_students')))
Estimation des paramètres
Compte tenu des données, l'objectif de l' inférence est d'adapter les effets de modèle fixe pente \(\beta\), interception \(\alpha\)et paramètre composante de la variance \(\sigma^2\). Le principe du maximum de vraisemblance formalise cette tâche comme
\[ \max_{\beta, \alpha, \sigma}~\log p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}; \beta, \alpha, \sigma) = \max_{\beta, \alpha, \sigma}~\log \int p(\eta; \sigma) ~p(\mathbf{y}\mid \mathbf{X}, \mathbf{Z}, \eta; \beta, \alpha)~d\eta. \]
Dans ce tutoriel, nous utilisons l'algorithme de Monte Carlo EM pour maximiser cette densité marginale (Dempster et al., 1977 ; Wei et Tanner, 1990).¹ Nous effectuons une chaîne de Markov Monte Carlo pour calculer l'espérance de la vraisemblance conditionnelle par rapport à la effets aléatoires ("E-step"), et nous effectuons une descente de gradient pour maximiser l'attente par rapport aux paramètres ("M-step") :
Pour l'E-step, nous avons mis en place l'hamiltonien Monte Carlo (HMC). Il prend un état actuel (les effets étudiant, instructeur et département) et renvoie un nouvel état. Nous attribuons le nouvel état aux variables TensorFlow, qui indiqueront l'état de la chaîne HMC.
Pour l'étape M, nous utilisons l'échantillon a posteriori de HMC pour calculer une estimation non biaisée de la vraisemblance marginale jusqu'à une constante. Nous appliquons ensuite son gradient par rapport aux paramètres d'intérêt. Cela produit un pas de descente stochastique non biaisé sur la vraisemblance marginale. Nous l'implémentons avec l'optimiseur Adam TensorFlow et minimisons le négatif du marginal.
target_log_prob_fn = lambda *x: lmm_train.log_prob(x + (labels_train,))
trainable_variables = lmm_train.trainable_variables
current_state = lmm_train.sample()[:-1]
# For debugging
target_log_prob_fn(*current_state)
<tf.Tensor: shape=(), dtype=float32, numpy=-528062.5>
# Set up E-step (MCMC).
hmc = tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.015,
num_leapfrog_steps=3)
kernel_results = hmc.bootstrap_results(current_state)
@tf.function(autograph=False, jit_compile=True)
def one_e_step(current_state, kernel_results):
next_state, next_kernel_results = hmc.one_step(
current_state=current_state,
previous_kernel_results=kernel_results)
return next_state, next_kernel_results
optimizer = tf.optimizers.Adam(learning_rate=.01)
# Set up M-step (gradient descent).
@tf.function(autograph=False, jit_compile=True)
def one_m_step(current_state):
with tf.GradientTape() as tape:
loss = -target_log_prob_fn(*current_state)
grads = tape.gradient(loss, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss
Nous effectuons une étape d'échauffement, qui exécute une chaîne MCMC pour un certain nombre d'itérations afin que l'entraînement puisse être initialisé dans la masse de probabilité du postérieur. Nous effectuons ensuite une boucle d'entraînement. Il exécute conjointement les étapes E et M et enregistre les valeurs pendant la formation.
num_warmup_iters = 1000
num_iters = 1500
num_accepted = 0
effect_students_samples = np.zeros([num_iters, num_students])
effect_instructors_samples = np.zeros([num_iters, num_instructors])
effect_departments_samples = np.zeros([num_iters, num_departments])
loss_history = np.zeros([num_iters])
# Run warm-up stage.
for t in range(num_warmup_iters):
current_state, kernel_results = one_e_step(current_state, kernel_results)
num_accepted += kernel_results.is_accepted.numpy()
if t % 500 == 0 or t == num_warmup_iters - 1:
print("Warm-Up Iteration: {:>3} Acceptance Rate: {:.3f}".format(
t, num_accepted / (t + 1)))
num_accepted = 0 # reset acceptance rate counter
# Run training.
for t in range(num_iters):
# run 5 MCMC iterations before every joint EM update
for _ in range(5):
current_state, kernel_results = one_e_step(current_state, kernel_results)
loss = one_m_step(current_state)
effect_students_samples[t, :] = current_state[0].numpy()
effect_instructors_samples[t, :] = current_state[1].numpy()
effect_departments_samples[t, :] = current_state[2].numpy()
num_accepted += kernel_results.is_accepted.numpy()
loss_history[t] = loss.numpy()
if t % 500 == 0 or t == num_iters - 1:
print("Iteration: {:>4} Acceptance Rate: {:.3f} Loss: {:.3f}".format(
t, num_accepted / (t + 1), loss_history[t]))
Warm-Up Iteration: 0 Acceptance Rate: 1.000 Warm-Up Iteration: 500 Acceptance Rate: 0.754 Warm-Up Iteration: 999 Acceptance Rate: 0.707 Iteration: 0 Acceptance Rate: 1.000 Loss: 98220.266 Iteration: 500 Acceptance Rate: 0.703 Loss: 96003.969 Iteration: 1000 Acceptance Rate: 0.678 Loss: 95958.609 Iteration: 1499 Acceptance Rate: 0.685 Loss: 95921.891
Vous pouvez également écrire le warm - up pour la boucle dans un tf.while_loop , et l'étape de formation dans un tf.scan ou tf.while_loop même pour l' inférence plus rapide. Par example:
@tf.function(autograph=False, jit_compile=True)
def run_k_e_steps(k, current_state, kernel_results):
_, next_state, next_kernel_results = tf.while_loop(
cond=lambda i, state, pkr: i < k,
body=lambda i, state, pkr: (i+1, *one_e_step(state, pkr)),
loop_vars=(tf.constant(0), current_state, kernel_results)
)
return next_state, next_kernel_results
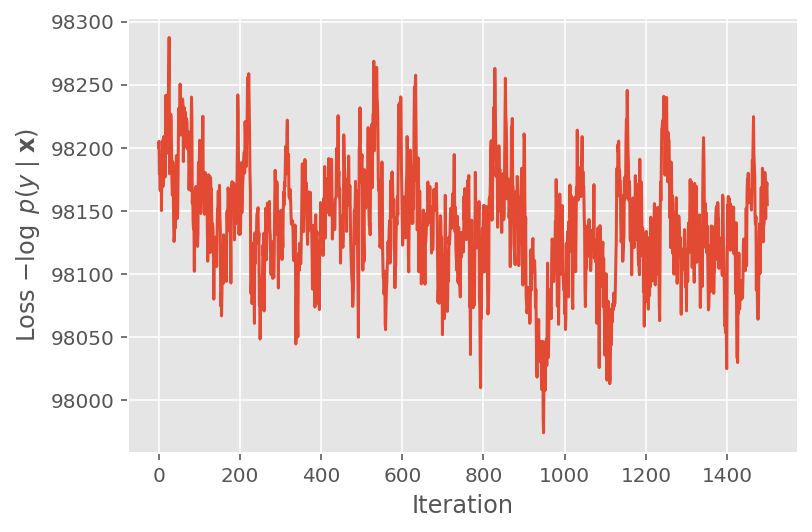
Ci-dessus, nous n'avons pas exécuté l'algorithme tant qu'un seuil de convergence n'a pas été détecté. Pour vérifier si l'apprentissage était judicieux, nous vérifions que la fonction de perte a bien tendance à converger au cours des itérations d'apprentissage.
plt.plot(loss_history)
plt.ylabel(r'Loss $-\log$ $p(y\mid\mathbf{x})$')
plt.xlabel('Iteration')
plt.show()
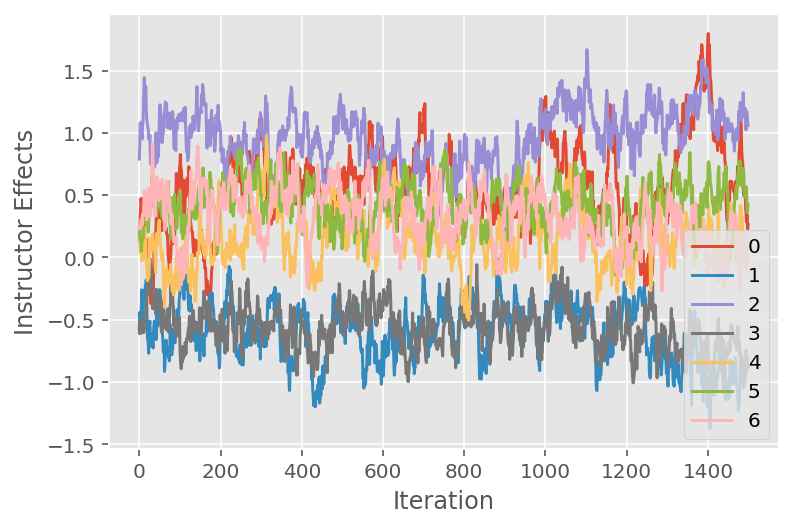
Nous utilisons également un tracé de trace, qui montre la trajectoire de l'algorithme de Monte Carlo de la chaîne de Markov à travers des dimensions latentes spécifiques. Ci-dessous, nous voyons que les effets d'instructeur spécifiques s'éloignent de manière significative de leur état initial et explorent l'espace d'état. Le tracé de trace indique également que les effets diffèrent d'un instructeur à l'autre, mais avec un comportement de mixage similaire.
for i in range(7):
plt.plot(effect_instructors_samples[:, i])
plt.legend([i for i in range(7)], loc='lower right')
plt.ylabel('Instructor Effects')
plt.xlabel('Iteration')
plt.show()
Critique
Ci-dessus, nous avons ajusté le modèle. Nous nous intéressons maintenant à la critique de son ajustement à l'aide de données, ce qui nous permet d'explorer et de mieux comprendre le modèle. Une de ces techniques est un graphique résiduel, qui trace la différence entre les prédictions du modèle et la vérité terrain pour chaque point de données. Si le modèle était correct, alors leur différence devrait être standard normalement distribuée ; tout écart par rapport à ce modèle dans le graphique indique une inadéquation du modèle.
Nous construisons le graphique résiduel en formant d'abord la distribution prédictive postérieure sur les notes, qui remplace la distribution antérieure sur les effets aléatoires par ses données d'apprentissage postérieures. En particulier, nous faisons avancer le modèle et interceptons sa dépendance vis-à-vis des effets aléatoires antérieurs avec leurs moyennes a posteriori inférées.²
lmm_test = lmm_jointdist(features_test)
[
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
] = [
np.mean(x, axis=0).astype(np.float32) for x in [
effect_students_samples,
effect_instructors_samples,
effect_departments_samples
]
]
# Get the posterior predictive distribution
(*posterior_conditionals, ratings_posterior), _ = lmm_test.sample_distributions(
value=(
effect_students_mean,
effect_instructors_mean,
effect_departments_mean,
))
ratings_prediction = ratings_posterior.mean()
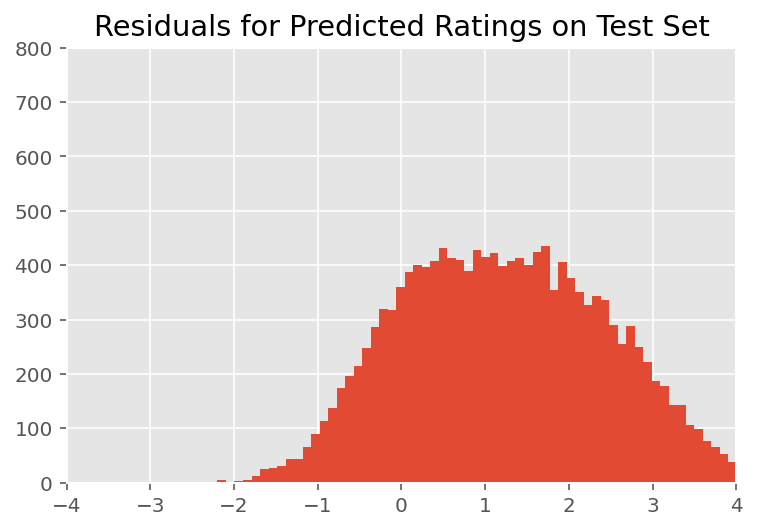
Lors d'une inspection visuelle, les résidus ont l'air quelque peu standard-normalement distribués. Cependant, l'ajustement n'est pas parfait : il y a une masse de probabilité plus grande dans les queues qu'une distribution normale, ce qui indique que le modèle pourrait améliorer son ajustement en assouplissant ses hypothèses de normalité.
En particulier, bien qu'il est plus courant d'utiliser une distribution normale des cotes de modèle dans le InstEval ensemble de données, un examen plus approfondi des données révèle que les cotes d'évaluation des cours sont en fait des valeurs ordinales de 1 à 5. Cela donne à penser que nous devrions utiliser une distribution ordinale, ou même catégorique si nous avons suffisamment de données pour rejeter l'ordre relatif. Il s'agit d'un changement d'une ligne par rapport au modèle ci-dessus ; le même code d'inférence est applicable.
plt.title("Residuals for Predicted Ratings on Test Set")
plt.xlim(-4, 4)
plt.ylim(0, 800)
plt.hist(ratings_prediction - labels_test, 75)
plt.show()
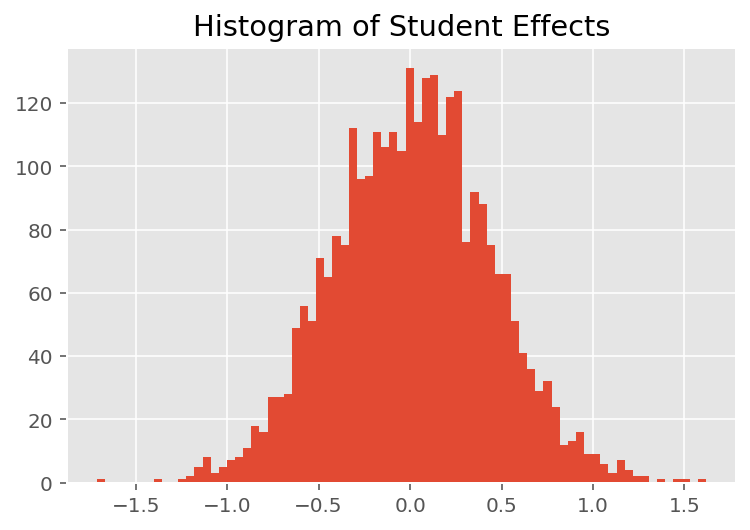
Pour explorer comment le modèle fait des prédictions individuelles, nous examinons l'histogramme des effets pour les étudiants, les instructeurs et les départements. Cela nous permet de comprendre comment les éléments individuels du vecteur de caractéristiques d'un point de données ont tendance à influencer le résultat.
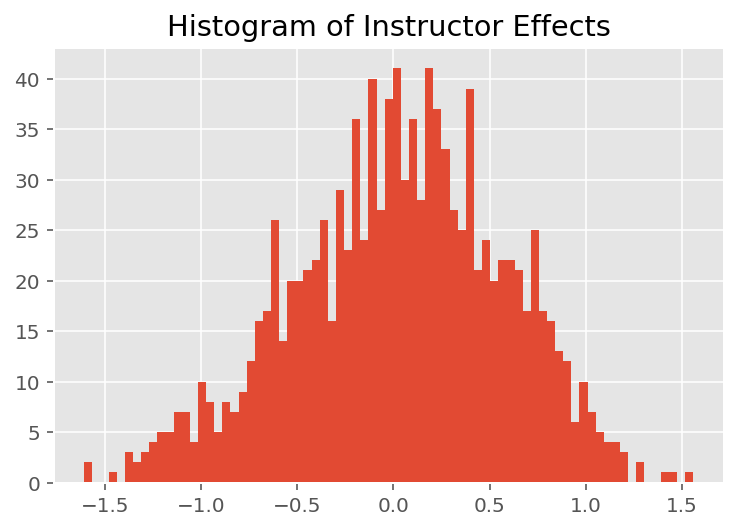
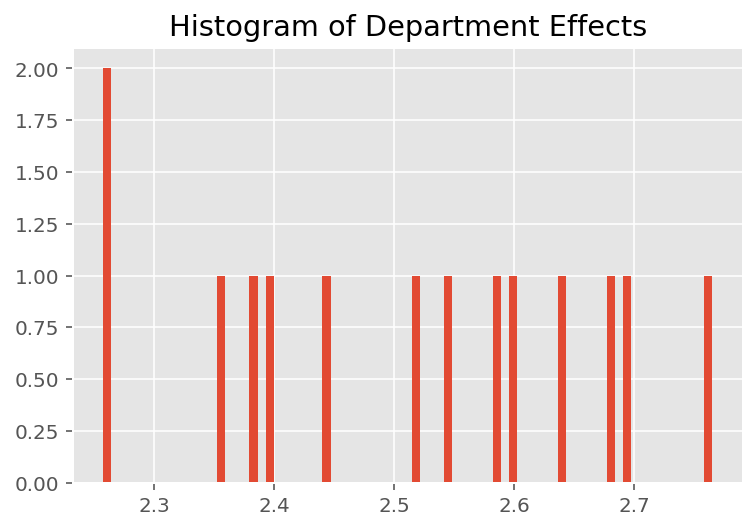
Sans surprise, nous voyons ci-dessous que chaque étudiant a généralement peu d'effet sur la note d'évaluation d'un instructeur. Fait intéressant, nous voyons que le département auquel appartient un instructeur a un effet important.
plt.title("Histogram of Student Effects")
plt.hist(effect_students_mean, 75)
plt.show()
plt.title("Histogram of Instructor Effects")
plt.hist(effect_instructors_mean, 75)
plt.show()
plt.title("Histogram of Department Effects")
plt.hist(effect_departments_mean, 75)
plt.show()
Notes de bas de page
¹ Les modèles linéaires à effets mixtes sont un cas particulier où nous pouvons calculer analytiquement sa densité marginale. Pour les besoins de ce didacticiel, nous démontrons l'EM de Monte Carlo, qui s'applique plus facilement aux densités marginales non analytiques, comme si la probabilité était étendue pour être catégorielle au lieu de normale.
² Pour simplifier, nous formons la moyenne de la distribution prédictive en utilisant un seul passage avant du modèle. Ceci est fait en conditionnant sur la moyenne a posteriori et est valable pour les modèles linéaires à effets mixtes. Cependant, cela n'est pas valable en général : la moyenne de la distribution prédictive postérieure est généralement insoluble et nécessite de prendre la moyenne empirique sur plusieurs passages avant du modèle à partir d'échantillons postérieurs.
Remerciements
Ce tutoriel a été écrit dans Edward 1.0 ( source de ). Nous remercions tous ceux qui ont contribué à la rédaction et à la révision de cette version.
Les références
Douglas Bates et Martin Machler et Ben Bolker et Steve Walker. Ajustement de modèles linéaires à effets mixtes à l'aide de lme4. Journal of Statistical Software, 67 (1): 1-48, 2015.
Arthur P. Dempster, Nan M. Laird et Donald B. Rubin. Vraisemblance maximale à partir de données incomplètes via l'algorithme EM. Journal de la Société royale de statistique, série B (méthodologique), 1-38, 1977.
Andrew Gelman et Jennifer Hill. Analyse des données à l'aide de modèles de régression et multiniveaux/hiérarchiques. Cambridge University Press, 2006.
David A. Harville. Approches du maximum de vraisemblance pour l'estimation des composantes de la variance et les problèmes connexes. Journal de l'American Statistical Association, 72 (358): 320-338, 1977.
Michael I. Jordanie. Une introduction aux modèles graphiques. Rapport technique, 2003.
Nan M. Laird et James Ware. Modèles à effets aléatoires pour les données longitudinales. Biométrie, 963-974, 1982.
Greg Wei et Martin A. Tanner. Une implémentation Monte Carlo de l'algorithme EM et des algorithmes d'augmentation de données du pauvre. Journal de l'American Statistical Association, 699-704, 1990.