
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Gizli değişken modelleri, yüksek boyutlu verilerdeki gizli yapıyı yakalamaya çalışır. Örnekler, temel bileşen analizini (PCA) ve faktör analizini içerir. Gauss süreçleri, yerel korelasyon yapısını ve belirsizliği esnek bir şekilde yakalayabilen "parametrik olmayan" modellerdir. Gauss süreci gizli değişken modeli ( Lawrence 2004 ) bu kavramları birleştirir.
Arkaplan: Gauss Süreçleri
Bir Gauss süreci, herhangi bir sonlu altküme üzerindeki marjinal dağılımın çok değişkenli bir normal dağılım olduğu herhangi bir rastgele değişken topluluğudur. Regresyon bağlamında Pratisyen detaylı bir bakış için, check out TensorFlow Olasılığında Gauss Süreci Regresyon .
Biz GP aşağıda belirtilenleri koleksiyonunda rastgele değişkenlerin her etiketlemek için sözde bir indeks kümesi kullanın. Sonlu bir indeks kümesi durumunda, sadece çok değişkenli bir normal elde ederiz. Biz sonsuz koleksiyonlarını göz önüne aldığımızda GP en olsa da, en ilginçtir. Gibi indeks setlerinin durumunda \(\mathbb{R}^D\)biz her noktasında için rasgele değişkeni, \(D\)boyutlu uzayın, GP rasgele fonksiyonları üzerinde bir dağıtım olarak düşünülebilir. Böyle bir GP gelen tek beraberlik, bu fark edilip edilemeyeceğini, her noktaya bir (müştereken normalde dağıtılmış) değer atamak istiyorum \(\mathbb{R}^D\). Bu CoLab, biz bazı aşırı GP en odaklanacağız\(\mathbb{R}^D\).
Normal dağılımlar tamamen birinci ve ikinci dereceden istatistikler tarafından belirlenir - aslında, normal dağılımı tanımlamanın bir yolu, yüksek dereceli kümülantlarının tümü sıfır olan bir dağılımdır. Bu da GP için geçerlidir: biz tamamen ortalama ve kovaryans * açıklayan bir GP belirtin. Sonlu boyutlu çok değişkenli normaller için ortalamanın bir vektör olduğunu ve kovaryansın kare, simetrik pozitif tanımlı bir matris olduğunu hatırlayın. Sonsuz boyutlu GP, bu yapıların ortalama fonksiyonu için genelleme \(m : \mathbb{R}^D \to \mathbb{R}\)endeksi setinin her noktada tanımlanan ve bir kovaryans "çekirdek" fonksiyonu,\(k : \mathbb{R}^D \times \mathbb{R}^D \to \mathbb{R}\). Çekirdek işlevi için gerekli olan pozitif tanımlı , esas olarak bu, bir nokta sonlu ile kısıtlı, bir postiive-belirli matris verir söylüyor.
Bir GP'nin yapısının çoğu, kovaryans çekirdek işlevinden türetilir - bu işlev, örnekleme işlevlerinin değerlerinin yakın (veya çok yakın olmayan) noktalar arasında nasıl değiştiğini açıklar. Farklı kovaryans işlevleri, farklı derecelerde düzgünlüğü teşvik eder. Yaygın olarak kullanılan bir çekirdek fonksiyonu "exponentiated ikinci dereceden" (diğer adıyla "Gauss" ya da "radyal tabanlı fonksiyonu", "üstel-kare")" dir \(k(x, x') = \sigma^2 e^{(x - x^2) / \lambda^2}\). Diğer örnekler David Duvenaud en üstünde özetlenmiştir çekirdek yemek kitabı sayfa kanonik metin yanı sıra, Makine Öğrenmesi için Gauss Süreçleri .
* Sonsuz bir dizin kümesiyle, bir tutarlılık koşuluna da ihtiyacımız var. GP'nin tanımı sonlu marjinaller cinsinden olduğu için, marjinallerin alındığı sıraya bakılmaksızın bu marjinallerin tutarlı olmasını şart koşmalıyız. Bu, bu öğreticinin kapsamı dışında, stokastik süreçler teorisinde biraz ileri düzeyde bir konudur; sonunda işlerin yolunda gittiğini söylemek yeterli!
GP Uygulaması: Regresyon ve Gizli Değişken Modelleri
Biz pratisyen kullanabilirsiniz bir yolu gerileme içindir: girdilerin şeklinde gözlenen verilerin bir demet verilen \(\{x_i\}_{i=1}^N\) (indeks kümesinin elemanları) ve gözlemlere\(\{y_i\}_{i=1}^N\), bu yeni bir arka öngörü dağılımını oluşturmak için kullanabileceğiniz noktaları kümesi \(\{x_j^*\}_{j=1}^M\). Dağılımlar tüm Gauss olduğundan, bu bazı basit doğrusal cebir aşağı kaynar (ancak not: gerekli hesaplamalar veri noktaları sayısında zamanı kübik ve veri noktalarının sayısının uzay Kuadratik gerektirir - bu büyük bir sınırlayıcı faktör olduğu pratisyen hekimlerin kullanımı ve güncel araştırmaların çoğu, kesin sonsal çıkarsama için hesaplama açısından uygun alternatiflere odaklanır). Biz daha ayrıntılı olarak GP gerileme kapsayacak TFP CoLab GP Regresyon .
GP'leri kullanmanın başka bir yolu da gizli değişken modeldir: yüksek boyutlu gözlemler (örneğin, görüntüler) koleksiyonu verildiğinde, bazı düşük boyutlu gizli yapılar varsayabiliriz. Gizli yapıya bağlı olarak, çok sayıda çıktının (görüntüdeki pikseller) birbirinden bağımsız olduğunu varsayıyoruz. Bu modeldeki eğitim şunlardan oluşur:
- model parametrelerinin optimize edilmesi (çekirdek fonksiyon parametrelerinin yanı sıra örneğin gözlem gürültüsü varyansı) ve
- her eğitim gözlemi (görüntü) için indeks setinde karşılık gelen bir nokta konumu bulma. Tüm optimizasyon, verilerin marjinal log olasılığını maksimize ederek yapılabilir.
ithalat
import numpy as np
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfk = tfp.math.psd_kernels
%pylab inline
Populating the interactive namespace from numpy and matplotlib
MNIST Verilerini Yükle
# Load the MNIST data set and isolate a subset of it.
(x_train, y_train), (_, _) = tf.keras.datasets.mnist.load_data()
N = 1000
small_x_train = x_train[:N, ...].astype(np.float64) / 256.
small_y_train = y_train[:N]
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
Eğitilebilir değişkenler hazırlayın
Gizli girdilerin yanı sıra 3 model parametresini birlikte eğiteceğiz.
# Create some trainable model parameters. We will constrain them to be strictly
# positive when constructing the kernel and the GP.
unconstrained_amplitude = tf.Variable(np.float64(1.), name='amplitude')
unconstrained_length_scale = tf.Variable(np.float64(1.), name='length_scale')
unconstrained_observation_noise = tf.Variable(np.float64(1.), name='observation_noise')
# We need to flatten the images and, somewhat unintuitively, transpose from
# shape [100, 784] to [784, 100]. This is because the 784 pixels will be
# treated as *independent* conditioned on the latent inputs, meaning we really
# have a batch of 784 GP's with 100 index_points.
observations_ = small_x_train.reshape(N, -1).transpose()
# Create a collection of N 2-dimensional index points that will represent our
# latent embeddings of the data. (Lawrence, 2004) prescribes initializing these
# with PCA, but a random initialization actually gives not-too-bad results, so
# we use this for simplicity. For a fun exercise, try doing the
# PCA-initialization yourself!
init_ = np.random.normal(size=(N, 2))
latent_index_points = tf.Variable(init_, name='latent_index_points')
Model oluşturma ve eğitim operasyonları
# Create our kernel and GP distribution
EPS = np.finfo(np.float64).eps
def create_kernel():
amplitude = tf.math.softplus(EPS + unconstrained_amplitude)
length_scale = tf.math.softplus(EPS + unconstrained_length_scale)
kernel = tfk.ExponentiatedQuadratic(amplitude, length_scale)
return kernel
def loss_fn():
observation_noise_variance = tf.math.softplus(
EPS + unconstrained_observation_noise)
gp = tfd.GaussianProcess(
kernel=create_kernel(),
index_points=latent_index_points,
observation_noise_variance=observation_noise_variance)
log_probs = gp.log_prob(observations_, name='log_prob')
return -tf.reduce_mean(log_probs)
trainable_variables = [unconstrained_amplitude,
unconstrained_length_scale,
unconstrained_observation_noise,
latent_index_points]
optimizer = tf.optimizers.Adam(learning_rate=1.0)
@tf.function(autograph=False, jit_compile=True)
def train_model():
with tf.GradientTape() as tape:
loss_value = loss_fn()
grads = tape.gradient(loss_value, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss_value
Ortaya çıkan gizli yerleştirmeleri eğitin ve çizin
# Initialize variables and train!
num_iters = 100
log_interval = 20
lips = np.zeros((num_iters, N, 2), np.float64)
for i in range(num_iters):
loss = train_model()
lips[i] = latent_index_points.numpy()
if i % log_interval == 0 or i + 1 == num_iters:
print("Loss at step %d: %f" % (i, loss))
Loss at step 0: 1108.121688 Loss at step 20: -159.633761 Loss at step 40: -263.014394 Loss at step 60: -283.713056 Loss at step 80: -288.709413 Loss at step 99: -289.662253
Arsa sonuçları
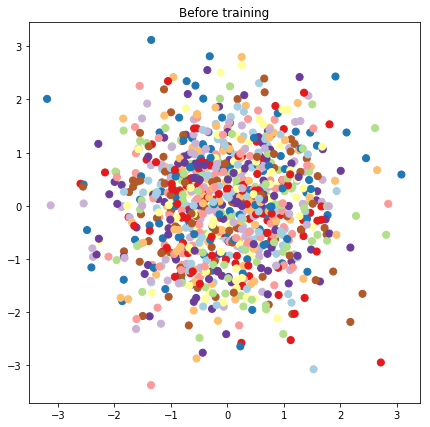
# Plot the latent locations before and after training
plt.figure(figsize=(7, 7))
plt.title("Before training")
plt.grid(False)
plt.scatter(x=init_[:, 0], y=init_[:, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
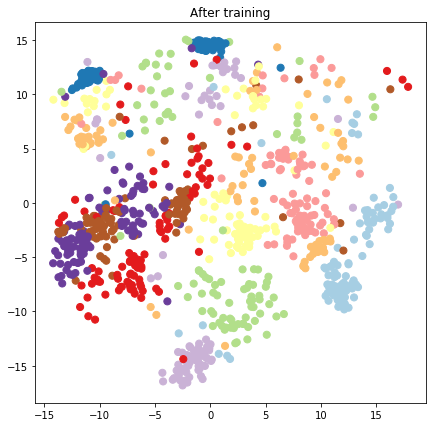
plt.figure(figsize=(7, 7))
plt.title("After training")
plt.grid(False)
plt.scatter(x=lips[-1, :, 0], y=lips[-1, :, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
Tahmine dayalı model ve örnekleme operasyonları oluşturun
# We'll draw samples at evenly spaced points on a 10x10 grid in the latent
# input space.
sample_grid_points = 10
grid_ = np.linspace(-4, 4, sample_grid_points).astype(np.float64)
# Create a 10x10 grid of 2-vectors, for a total shape [10, 10, 2]
grid_ = np.stack(np.meshgrid(grid_, grid_), axis=-1)
# This part's a bit subtle! What we defined above was a batch of 784 (=28x28)
# independent GP distributions over the input space. Each one corresponds to a
# single pixel of an MNIST image. Now what we'd like to do is draw 100 (=10x10)
# *independent* samples, each one separately conditioned on all the observations
# as well as the learned latent input locations above.
#
# The GP regression model below will define a batch of 784 independent
# posteriors. We'd like to get 100 independent samples each at a different
# latent index point. We could loop over the points in the grid, but that might
# be a bit slow. Instead, we can vectorize the computation by tacking on *even
# more* batch dimensions to our GaussianProcessRegressionModel distribution.
# In the below grid_ shape, we have concatentaed
# 1. batch shape: [sample_grid_points, sample_grid_points, 1]
# 2. number of examples: [1]
# 3. number of latent input dimensions: [2]
# The `1` in the batch shape will broadcast with 784. The final result will be
# samples of shape [10, 10, 784, 1]. The `1` comes from the "number of examples"
# and we can just `np.squeeze` it off.
grid_ = grid_.reshape(sample_grid_points, sample_grid_points, 1, 1, 2)
# Create the GPRegressionModel instance which represents the posterior
# predictive at the grid of new points.
gprm = tfd.GaussianProcessRegressionModel(
kernel=create_kernel(),
# Shape [10, 10, 1, 1, 2]
index_points=grid_,
# Shape [1000, 2]. 1000 2 dimensional vectors.
observation_index_points=latent_index_points,
# Shape [784, 1000]. A batch of 784 1000-dimensional observations.
observations=observations_)
Verilere ve gizli yerleştirmelere göre koşullandırılmış örnekler çizin
Gizli uzayda 2 boyutlu bir ızgarada 100 noktada numune alıyoruz.
samples = gprm.sample()
# Plot the grid of samples at new points. We do a bit of tweaking of the samples
# first, squeezing off extra 1-shapes and normalizing the values.
samples_ = np.squeeze(samples.numpy())
samples_ = ((samples_ -
samples_.min(-1, keepdims=True)) /
(samples_.max(-1, keepdims=True) -
samples_.min(-1, keepdims=True)))
samples_ = samples_.reshape(sample_grid_points, sample_grid_points, 28, 28)
samples_ = samples_.transpose([0, 2, 1, 3])
samples_ = samples_.reshape(28 * sample_grid_points, 28 * sample_grid_points)
plt.figure(figsize=(7, 7))
ax = plt.subplot()
ax.grid(False)
ax.imshow(-samples_, interpolation='none', cmap='Greys')
plt.show()

Çözüm
Gauss süreci gizli değişken modelinde kısa bir tur attık ve onu sadece birkaç satır TF ve TF Olasılık kodunda nasıl uygulayabileceğimizi gösterdik.