
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Модели со скрытыми переменными пытаются уловить скрытую структуру в данных большой размерности. Примеры включают анализ основных компонентов (PCA) и факторный анализ. Гауссовские процессы - это «непараметрические» модели, которые могут гибко фиксировать локальную корреляционную структуру и неопределенность. Гауссовский процесс скрытая модель переменной ( Lawrence, 2004 ) сочетает в себе эти понятия.
Справочная информация: гауссовские процессы
Гауссовский процесс - это любой набор случайных величин, такой что маргинальное распределение по любому конечному подмножеству является многомерным нормальным распределением. Для детального взгляда на врачей общей практики в контексте регрессии, проверить гауссовский процесс регрессии в TensorFlow вероятности .
Мы используем так называемый набор индексов для обозначения каждого из случайных величин в коллекции , что ГП содержит. В случае конечного набора индексов мы просто получаем многомерную нормаль. ВОП наиболее интересны, хотя, когда мы рассматриваем бесконечные коллекции. В случае индексных множеств как \(\mathbb{R}^D\), где мы имеем случайную переменную для каждой точки в \(D\) - мерном пространстве, ГП можно рассматривать как распределение по случайным функциям. Один дро из такого GP, если оно может быть реализовано, было бы присвоить значение (совместно нормально распределенной) для каждой точки в \(\mathbb{R}^D\). В этом colab, мы сосредоточимся на ВОП в течение некоторого\(\mathbb{R}^D\).
Нормальные распределения полностью определяются их статистикой первого и второго порядка - действительно, один из способов определить нормальное распределение - это такое, у которого все кумулянты более высокого порядка равны нулю. Это тот случай , для врачей общей практики, тоже: мы полностью указать GP, описывая средний и ковариационной *. Напомним, что для многомерных многомерных норм среднее значение является вектором, а ковариация - квадратной симметричной положительно определенной матрицей. В бесконечномерным GP, эти структуры обобщают к средней функции \(m : \mathbb{R}^D \to \mathbb{R}\), определенной в каждой точке множества индексов, и ковариационной функции «ядра»,\(k : \mathbb{R}^D \times \mathbb{R}^D \to \mathbb{R}\). Функция ядра требуется быть положительно определенным , который по существу говорит , что ограничивается конечным множеством точек, она дает postiive определенной матрицы.
Большая часть структуры GP происходит от его функции ядра ковариации - эта функция описывает, как значения функций sampeld меняются в соседних (или не очень близких) точках. Различные ковариационные функции способствуют разной степени гладкости. Одно из наиболее часто используемых функций ядра является «экспоненцируется квадратичная» (иначе, «Гауссово», «квадрат экспоненциальный» или «радиальной базисной функции»), \(k(x, x') = \sigma^2 e^{(x - x^2) / \lambda^2}\). Другие примеры изложены на Дэвиде Duvenaud в странице ядра поваренной , а также в канонических текстовых гауссовских процессах для машинного обучения .
* При бесконечном наборе индексов нам также требуется условие согласованности. Поскольку определение GP дано в терминах конечных маргиналов, мы должны требовать, чтобы эти маргиналы были непротиворечивыми независимо от порядка, в котором взяты маргиналы. Это несколько продвинутая тема теории случайных процессов, выходящая за рамки данного руководства; достаточно сказать, что в конце концов все идет хорошо!
Применение терапевтов: регрессия и модели со скрытыми переменными
Один из способов , мы можем использовать ВОП для регрессии: учитывая кучу наблюдаемых данных в виде входов \(\{x_i\}_{i=1}^N\) (элементы множества индексов) и наблюдений\(\{y_i\}_{i=1}^N\), мы можем использовать их , чтобы сформировать заднее прогностическое распределение на новом множество точек \(\{x_j^*\}_{j=1}^M\). Поскольку распределения являются всеми гауссовым, это сводится к некоторой простой линейной алгебре (но примечание: необходимые вычисления имеют выполнение кубического числа точек данных и требуют пространства квадратичных по числу точек данных - это является основным фактором, ограничивающим использование терапевтов и большая часть текущих исследований сосредоточена на вычислительно жизнеспособных альтернативах точному апостериорному выводу). Мы покрываем GP регрессии более подробно в GP регрессия в TFP colab .
Другой способ использования GP - это модель со скрытыми переменными: учитывая набор многомерных наблюдений (например, изображений), мы можем постулировать некоторую низкоразмерную скрытую структуру. Мы предполагаем, что в зависимости от скрытой структуры большое количество выходов (пикселей в изображении) не зависят друг от друга. Обучение по этой модели состоит из
- оптимизация параметров модели (параметры функции ядра, а также, например, дисперсия шума наблюдения), и
- нахождение для каждого обучающего наблюдения (изображения) соответствующей точки в наборе индексов. Вся оптимизация может быть выполнена путем максимизации предельной логарифмической вероятности данных.
Импорт
import numpy as np
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfk = tfp.math.psd_kernels
%pylab inline
Populating the interactive namespace from numpy and matplotlib
Загрузить данные MNIST
# Load the MNIST data set and isolate a subset of it.
(x_train, y_train), (_, _) = tf.keras.datasets.mnist.load_data()
N = 1000
small_x_train = x_train[:N, ...].astype(np.float64) / 256.
small_y_train = y_train[:N]
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
Подготовьте обучаемые переменные
Мы будем совместно обучать 3 параметра модели, а также скрытые входные данные.
# Create some trainable model parameters. We will constrain them to be strictly
# positive when constructing the kernel and the GP.
unconstrained_amplitude = tf.Variable(np.float64(1.), name='amplitude')
unconstrained_length_scale = tf.Variable(np.float64(1.), name='length_scale')
unconstrained_observation_noise = tf.Variable(np.float64(1.), name='observation_noise')
# We need to flatten the images and, somewhat unintuitively, transpose from
# shape [100, 784] to [784, 100]. This is because the 784 pixels will be
# treated as *independent* conditioned on the latent inputs, meaning we really
# have a batch of 784 GP's with 100 index_points.
observations_ = small_x_train.reshape(N, -1).transpose()
# Create a collection of N 2-dimensional index points that will represent our
# latent embeddings of the data. (Lawrence, 2004) prescribes initializing these
# with PCA, but a random initialization actually gives not-too-bad results, so
# we use this for simplicity. For a fun exercise, try doing the
# PCA-initialization yourself!
init_ = np.random.normal(size=(N, 2))
latent_index_points = tf.Variable(init_, name='latent_index_points')
Построить модель и тренировочные операции
# Create our kernel and GP distribution
EPS = np.finfo(np.float64).eps
def create_kernel():
amplitude = tf.math.softplus(EPS + unconstrained_amplitude)
length_scale = tf.math.softplus(EPS + unconstrained_length_scale)
kernel = tfk.ExponentiatedQuadratic(amplitude, length_scale)
return kernel
def loss_fn():
observation_noise_variance = tf.math.softplus(
EPS + unconstrained_observation_noise)
gp = tfd.GaussianProcess(
kernel=create_kernel(),
index_points=latent_index_points,
observation_noise_variance=observation_noise_variance)
log_probs = gp.log_prob(observations_, name='log_prob')
return -tf.reduce_mean(log_probs)
trainable_variables = [unconstrained_amplitude,
unconstrained_length_scale,
unconstrained_observation_noise,
latent_index_points]
optimizer = tf.optimizers.Adam(learning_rate=1.0)
@tf.function(autograph=False, jit_compile=True)
def train_model():
with tf.GradientTape() as tape:
loss_value = loss_fn()
grads = tape.gradient(loss_value, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss_value
Обучите и нанесите на график полученные скрытые вложения
# Initialize variables and train!
num_iters = 100
log_interval = 20
lips = np.zeros((num_iters, N, 2), np.float64)
for i in range(num_iters):
loss = train_model()
lips[i] = latent_index_points.numpy()
if i % log_interval == 0 or i + 1 == num_iters:
print("Loss at step %d: %f" % (i, loss))
Loss at step 0: 1108.121688 Loss at step 20: -159.633761 Loss at step 40: -263.014394 Loss at step 60: -283.713056 Loss at step 80: -288.709413 Loss at step 99: -289.662253
Результаты сюжета
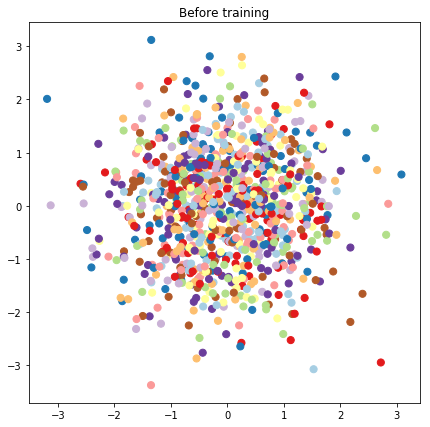
# Plot the latent locations before and after training
plt.figure(figsize=(7, 7))
plt.title("Before training")
plt.grid(False)
plt.scatter(x=init_[:, 0], y=init_[:, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
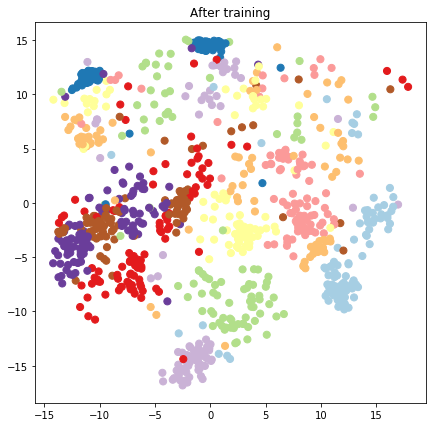
plt.figure(figsize=(7, 7))
plt.title("After training")
plt.grid(False)
plt.scatter(x=lips[-1, :, 0], y=lips[-1, :, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
Построение прогнозной модели и выборочных операций
# We'll draw samples at evenly spaced points on a 10x10 grid in the latent
# input space.
sample_grid_points = 10
grid_ = np.linspace(-4, 4, sample_grid_points).astype(np.float64)
# Create a 10x10 grid of 2-vectors, for a total shape [10, 10, 2]
grid_ = np.stack(np.meshgrid(grid_, grid_), axis=-1)
# This part's a bit subtle! What we defined above was a batch of 784 (=28x28)
# independent GP distributions over the input space. Each one corresponds to a
# single pixel of an MNIST image. Now what we'd like to do is draw 100 (=10x10)
# *independent* samples, each one separately conditioned on all the observations
# as well as the learned latent input locations above.
#
# The GP regression model below will define a batch of 784 independent
# posteriors. We'd like to get 100 independent samples each at a different
# latent index point. We could loop over the points in the grid, but that might
# be a bit slow. Instead, we can vectorize the computation by tacking on *even
# more* batch dimensions to our GaussianProcessRegressionModel distribution.
# In the below grid_ shape, we have concatentaed
# 1. batch shape: [sample_grid_points, sample_grid_points, 1]
# 2. number of examples: [1]
# 3. number of latent input dimensions: [2]
# The `1` in the batch shape will broadcast with 784. The final result will be
# samples of shape [10, 10, 784, 1]. The `1` comes from the "number of examples"
# and we can just `np.squeeze` it off.
grid_ = grid_.reshape(sample_grid_points, sample_grid_points, 1, 1, 2)
# Create the GPRegressionModel instance which represents the posterior
# predictive at the grid of new points.
gprm = tfd.GaussianProcessRegressionModel(
kernel=create_kernel(),
# Shape [10, 10, 1, 1, 2]
index_points=grid_,
# Shape [1000, 2]. 1000 2 dimensional vectors.
observation_index_points=latent_index_points,
# Shape [784, 1000]. A batch of 784 1000-dimensional observations.
observations=observations_)
Нарисуйте образцы, основанные на данных и скрытых вложениях
Мы делаем выборку в 100 точках на двумерной сетке в скрытом пространстве.
samples = gprm.sample()
# Plot the grid of samples at new points. We do a bit of tweaking of the samples
# first, squeezing off extra 1-shapes and normalizing the values.
samples_ = np.squeeze(samples.numpy())
samples_ = ((samples_ -
samples_.min(-1, keepdims=True)) /
(samples_.max(-1, keepdims=True) -
samples_.min(-1, keepdims=True)))
samples_ = samples_.reshape(sample_grid_points, sample_grid_points, 28, 28)
samples_ = samples_.transpose([0, 2, 1, 3])
samples_ = samples_.reshape(28 * sample_grid_points, 28 * sample_grid_points)
plt.figure(figsize=(7, 7))
ax = plt.subplot()
ax.grid(False)
ax.imshow(-samples_, interpolation='none', cmap='Greys')
plt.show()

Вывод
Мы кратко ознакомились с моделью скрытых переменных гауссовского процесса и показали, как мы можем реализовать ее всего в нескольких строках кода TF и TF Probability.