
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מודלים משתנים סמויים מנסים ללכוד מבנה נסתר בנתונים בעלי ממדים גבוהים. דוגמאות כוללות ניתוח רכיבים עקרוניים (PCA) וניתוח גורמים. תהליכי גאוס הם מודלים "לא פרמטריים" שיכולים ללכוד בצורה גמישה מבנה מתאם מקומי ואי ודאות. המודל המשתנה הסמוי גאוס התהליך ( לורנס, 2004 ) משלבת מושגים אלה.
רקע: תהליכי גאוס
תהליך גאוס הוא כל אוסף של משתנים אקראיים כך שהתפלגות השולית על כל תת-קבוצה סופית היא התפלגות נורמלית רב-משתנית. לבחינה מדוקדקת על רופאים בהקשר של רגרסיה, לבדוק רגרסיה תהליך גאוס ב הסתברות TensorFlow .
אנו משתמשים במספר מדד שנקרא לתייג כול אחד מהמשתנים האקראיים באוסף כי כולל GP. במקרה של קבוצת אינדקס סופי, אנחנו פשוט מקבלים נורמה רב משתנים. של GP הם המעניינים ביותר, אם כי, כאשר אנו רואים אוספים אינסופיים. במקרה של קבוצות מדד כמו \(\mathbb{R}^D\), שבו יש לנו משתנה אקראי לכל טעם \(D\)מרחב מימדי, GP יכול להיחשב חלוקה מעל פונקציות אקראיות. תיקו בודד GP כזה, אם זה יכול להתממש, היה להקצות ערך (במשותף בדרך-מופץ) לכל נקודה \(\mathbb{R}^D\). בשנת colab זה, נתמקד GP של מעל כמה\(\mathbb{R}^D\).
התפלגויות נורמליות נקבעות לחלוטין על ידי הסטטיסטיקה של הסדר הראשון והשני שלהן -- ואכן, דרך אחת להגדיר את ההתפלגות הנורמלית היא כזו שכל המצטברים מהסדר הגבוה שלה הם אפס. זהו המקרה עבור GP של, מדי: אנחנו לגמרי לציין GP בתיאור * שונה משותף והמרושע. נזכיר שעבור נורמלי רב-משתנים סופי-ממדיים, הממוצע הוא וקטור והשונות היא מטריצה מרובעת וסימטרית חיובית-מוגדרת. בשנות ה GP-ממדים האינסופיים, מבנים אלה להכליל פונקציה ממוצעת \(m : \mathbb{R}^D \to \mathbb{R}\), מוגדרת בכול נקודה של סט המדד, וכן שונות המשותפת "הקרנל" פונקציה,\(k : \mathbb{R}^D \times \mathbb{R}^D \to \mathbb{R}\). פונקציית הליבה נדרשת להיות חיובי-מובהק , אשר בעצם אומר כי, מוגבלי קבוצה סופית של נקודות, היא הניבה מטריקס postiive-המובהק.
רוב המבנה של GP נובע מפונקציית ליבת השונות שלו - פונקציה זו מתארת כיצד הערכים של פונקציות שנדגמו משתנים בין נקודות קרובות (או לא כל כך קרובות). פונקציות שונות של שיתופיות מעודדות דרגות שונות של חלקות. נפוץ פונקציה הקרנל אחת מהן היא "exponentiated ריבועית" (aka, "גאוס", "בריבוע מעריכים" או "תפקוד בסיס רדיאלי"), \(k(x, x') = \sigma^2 e^{(x - x^2) / \lambda^2}\). דוגמאות נוספות מתוארים באתר של דוד Duvenaud דף ספר הבישול הקרנל , כמו גם הקנונית הטקסט תהליכים גאוס עבור מכונת למידה .
* עם סט אינדקס אינסופי, אנו דורשים גם תנאי עקביות. מכיוון שההגדרה של GP היא במונחים של שוליים סופיים, עלינו לדרוש ששוליים אלה יהיו עקביים ללא קשר לסדר שבו נלקחים השוליים. זהו נושא מתקדם במקצת בתורת התהליכים הסטוכסטיים, מחוץ לתחום של הדרכה זו; די לומר שהדברים מסתדרים בסופו של דבר!
החלת רופאי משפחה: מודלים משתנים רגרסיים וסמויים
אחת דרכים שאנחנו יכולים להשתמש ב- GPS היא לרגרסיה: נתון חבורה של נתונים נצפים בצורה של תשומות \(\{x_i\}_{i=1}^N\) (אלמנטים של סט המדד) ותצפיות\(\{y_i\}_{i=1}^N\), אנו יכולים להשתמש אלה כדי ליצור חלוק חזוי אחורית בבית חדש סט של נקודות \(\{x_j^*\}_{j=1}^M\). מאז הפצות הם כל גאוס, זה מסתכם בכמה אלגברה ליניארית פשוטה (אבל הערה: החישובים הנדרשים יש ריצה מעוקבים במספר נקודות נתונים ודורשים ריבועית החלל במספר נקודות נתונים - זהו הגורם המגביל העיקרי ב השימוש ברופאי משפחה ומחקרים עדכניים רבים מתמקדים בחלופות ברות-קיימא מבחינה חישובית להסקת מסקנות אחורית מדויקת). אנחנו מכסים רגרסיה GP ביתר פירוט את רגרסיה GP ב colab הפריון הכולל .
דרך נוספת שבה אנו יכולים להשתמש ברופאי משפחה היא כמודל משתנה סמוי: בהינתן אוסף של תצפיות בממדים גבוהים (למשל, תמונות), אנו יכולים להעמיד מבנה סמוי בממד נמוך כלשהו. אנו מניחים כי מותנה במבנה הסמוי, המספר הגדול של הפלטים (פיקסלים בתמונה) אינם תלויים זה בזה. הכשרה במודל זה מורכבת מ
- אופטימיזציה של פרמטרי מודל (פרמטרים של פונקציית ליבה וכן, למשל, שונות רעש תצפית), ו
- מציאת, עבור כל תצפית אימון (תמונה), מיקום נקודתי תואם בערכת האינדקס. כל האופטימיזציה יכולה להיעשות על ידי מיקסום הסבירות היומן השולי של הנתונים.
יבוא
import numpy as np
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfk = tfp.math.psd_kernels
%pylab inline
Populating the interactive namespace from numpy and matplotlib
טען נתוני MNIST
# Load the MNIST data set and isolate a subset of it.
(x_train, y_train), (_, _) = tf.keras.datasets.mnist.load_data()
N = 1000
small_x_train = x_train[:N, ...].astype(np.float64) / 256.
small_y_train = y_train[:N]
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
הכן משתנים הניתנים לאימון
אנו נאמן במשותף 3 פרמטרים של מודל, כמו גם את התשומות הסמויות.
# Create some trainable model parameters. We will constrain them to be strictly
# positive when constructing the kernel and the GP.
unconstrained_amplitude = tf.Variable(np.float64(1.), name='amplitude')
unconstrained_length_scale = tf.Variable(np.float64(1.), name='length_scale')
unconstrained_observation_noise = tf.Variable(np.float64(1.), name='observation_noise')
# We need to flatten the images and, somewhat unintuitively, transpose from
# shape [100, 784] to [784, 100]. This is because the 784 pixels will be
# treated as *independent* conditioned on the latent inputs, meaning we really
# have a batch of 784 GP's with 100 index_points.
observations_ = small_x_train.reshape(N, -1).transpose()
# Create a collection of N 2-dimensional index points that will represent our
# latent embeddings of the data. (Lawrence, 2004) prescribes initializing these
# with PCA, but a random initialization actually gives not-too-bad results, so
# we use this for simplicity. For a fun exercise, try doing the
# PCA-initialization yourself!
init_ = np.random.normal(size=(N, 2))
latent_index_points = tf.Variable(init_, name='latent_index_points')
בניית מודלים והדרכה
# Create our kernel and GP distribution
EPS = np.finfo(np.float64).eps
def create_kernel():
amplitude = tf.math.softplus(EPS + unconstrained_amplitude)
length_scale = tf.math.softplus(EPS + unconstrained_length_scale)
kernel = tfk.ExponentiatedQuadratic(amplitude, length_scale)
return kernel
def loss_fn():
observation_noise_variance = tf.math.softplus(
EPS + unconstrained_observation_noise)
gp = tfd.GaussianProcess(
kernel=create_kernel(),
index_points=latent_index_points,
observation_noise_variance=observation_noise_variance)
log_probs = gp.log_prob(observations_, name='log_prob')
return -tf.reduce_mean(log_probs)
trainable_variables = [unconstrained_amplitude,
unconstrained_length_scale,
unconstrained_observation_noise,
latent_index_points]
optimizer = tf.optimizers.Adam(learning_rate=1.0)
@tf.function(autograph=False, jit_compile=True)
def train_model():
with tf.GradientTape() as tape:
loss_value = loss_fn()
grads = tape.gradient(loss_value, trainable_variables)
optimizer.apply_gradients(zip(grads, trainable_variables))
return loss_value
אימון ותכנן את ההטבעות הסמויות שנוצרו
# Initialize variables and train!
num_iters = 100
log_interval = 20
lips = np.zeros((num_iters, N, 2), np.float64)
for i in range(num_iters):
loss = train_model()
lips[i] = latent_index_points.numpy()
if i % log_interval == 0 or i + 1 == num_iters:
print("Loss at step %d: %f" % (i, loss))
Loss at step 0: 1108.121688 Loss at step 20: -159.633761 Loss at step 40: -263.014394 Loss at step 60: -283.713056 Loss at step 80: -288.709413 Loss at step 99: -289.662253
תוצאות עלילה
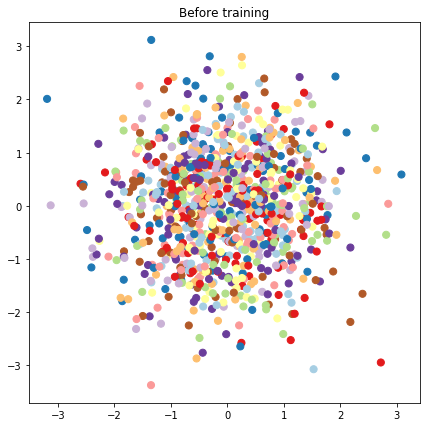
# Plot the latent locations before and after training
plt.figure(figsize=(7, 7))
plt.title("Before training")
plt.grid(False)
plt.scatter(x=init_[:, 0], y=init_[:, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
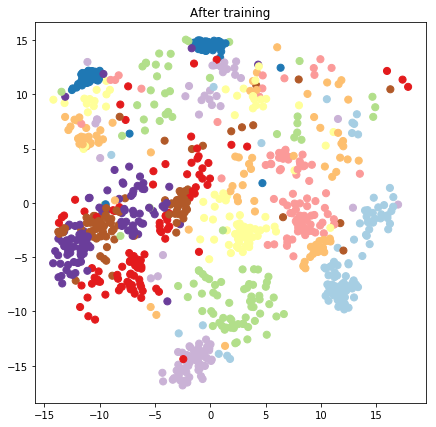
plt.figure(figsize=(7, 7))
plt.title("After training")
plt.grid(False)
plt.scatter(x=lips[-1, :, 0], y=lips[-1, :, 1],
c=y_train[:N], cmap=plt.get_cmap('Paired'), s=50)
plt.show()
בניית מודל חזוי ופעולות דגימה
# We'll draw samples at evenly spaced points on a 10x10 grid in the latent
# input space.
sample_grid_points = 10
grid_ = np.linspace(-4, 4, sample_grid_points).astype(np.float64)
# Create a 10x10 grid of 2-vectors, for a total shape [10, 10, 2]
grid_ = np.stack(np.meshgrid(grid_, grid_), axis=-1)
# This part's a bit subtle! What we defined above was a batch of 784 (=28x28)
# independent GP distributions over the input space. Each one corresponds to a
# single pixel of an MNIST image. Now what we'd like to do is draw 100 (=10x10)
# *independent* samples, each one separately conditioned on all the observations
# as well as the learned latent input locations above.
#
# The GP regression model below will define a batch of 784 independent
# posteriors. We'd like to get 100 independent samples each at a different
# latent index point. We could loop over the points in the grid, but that might
# be a bit slow. Instead, we can vectorize the computation by tacking on *even
# more* batch dimensions to our GaussianProcessRegressionModel distribution.
# In the below grid_ shape, we have concatentaed
# 1. batch shape: [sample_grid_points, sample_grid_points, 1]
# 2. number of examples: [1]
# 3. number of latent input dimensions: [2]
# The `1` in the batch shape will broadcast with 784. The final result will be
# samples of shape [10, 10, 784, 1]. The `1` comes from the "number of examples"
# and we can just `np.squeeze` it off.
grid_ = grid_.reshape(sample_grid_points, sample_grid_points, 1, 1, 2)
# Create the GPRegressionModel instance which represents the posterior
# predictive at the grid of new points.
gprm = tfd.GaussianProcessRegressionModel(
kernel=create_kernel(),
# Shape [10, 10, 1, 1, 2]
index_points=grid_,
# Shape [1000, 2]. 1000 2 dimensional vectors.
observation_index_points=latent_index_points,
# Shape [784, 1000]. A batch of 784 1000-dimensional observations.
observations=observations_)
צייר דוגמאות המותנות בנתונים ובהטבעות סמויות
אנו דוגמים ב-100 נקודות ברשת דו-ממדית במרחב הסמוי.
samples = gprm.sample()
# Plot the grid of samples at new points. We do a bit of tweaking of the samples
# first, squeezing off extra 1-shapes and normalizing the values.
samples_ = np.squeeze(samples.numpy())
samples_ = ((samples_ -
samples_.min(-1, keepdims=True)) /
(samples_.max(-1, keepdims=True) -
samples_.min(-1, keepdims=True)))
samples_ = samples_.reshape(sample_grid_points, sample_grid_points, 28, 28)
samples_ = samples_.transpose([0, 2, 1, 3])
samples_ = samples_.reshape(28 * sample_grid_points, 28 * sample_grid_points)
plt.figure(figsize=(7, 7))
ax = plt.subplot()
ax.grid(False)
ax.imshow(-samples_, interpolation='none', cmap='Greys')
plt.show()

סיכום
ערכנו סיור קצר במודל המשתנה הסמוי של תהליך גאוס, והראינו כיצד אנו יכולים ליישם אותו בכמה שורות בלבד של קוד הסתברות TF ו-TF.