
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
แปดโรงเรียนปัญหา ( รูบิน 1981 ) พิจารณาประสิทธิผลของโปรแกรมการฝึก SAT ดำเนินการในแบบคู่ขนานที่แปดโรงเรียน มันได้กลายเป็นปัญหาคลาสสิก ( เบส์วิเคราะห์ข้อมูล , สแตน ) ที่แสดงให้เห็นถึงประโยชน์ของการสร้างแบบจำลองลำดับชั้นสำหรับการแบ่งปันข้อมูลระหว่างกลุ่มแลกเปลี่ยน
implemention ด้านล่างคือการปรับตัวของเอ็ดเวิร์ด 1.0 กวดวิชา
นำเข้า
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import distributions as tfd
import warnings
tf.enable_v2_behavior()
plt.style.use("ggplot")
warnings.filterwarnings('ignore')
ข้อมูล
จากการวิเคราะห์ข้อมูลแบบเบย์ ส่วนที่ 5.5 (Gelman et al. 2013):
ได้ทำการศึกษาสำหรับบริการทดสอบทางการศึกษาเพื่อวิเคราะห์ผลกระทบของโปรแกรมการฝึกสอนพิเศษสำหรับ SAT-V (Scholastic Aptitude Test-Verbal) ในโรงเรียนมัธยมแต่ละแห่งแปดแห่ง ตัวแปรผลลัพธ์ในการศึกษาแต่ละครั้งคือคะแนนในการบริหารพิเศษของ SAT-V ซึ่งเป็นการทดสอบแบบเลือกตอบที่ได้มาตรฐานซึ่งบริหารจัดการโดยบริการทดสอบทางการศึกษา และใช้เพื่อช่วยวิทยาลัยในการตัดสินใจรับเข้าเรียน คะแนนสามารถเปลี่ยนแปลงได้ระหว่าง 200 ถึง 800 โดยมีค่าเฉลี่ยประมาณ 500 และส่วนเบี่ยงเบนมาตรฐานประมาณ 100 การสอบ SAT ได้รับการออกแบบมาให้ทนต่อความพยายามในระยะสั้นซึ่งมุ่งไปที่การปรับปรุงประสิทธิภาพการทดสอบโดยเฉพาะ แต่ได้รับการออกแบบเพื่อสะท้อนความรู้ที่ได้มาและความสามารถที่พัฒนาขึ้นตลอดหลายปีของการศึกษา อย่างไรก็ตาม โรงเรียนทั้งแปดแห่งในการศึกษานี้ถือว่าโปรแกรมการฝึกสอนระยะสั้นประสบความสำเร็จอย่างมากในการเพิ่มคะแนน SAT นอกจากนี้ ไม่มีเหตุผลก่อนหน้าที่จะเชื่อว่าโปรแกรมใด ๆ ในแปดโปรแกรมมีประสิทธิภาพมากกว่าโปรแกรมอื่น ๆ หรือบางโปรแกรมมีผลคล้ายกันมากกว่าโปรแกรมอื่น
สำหรับแต่ละโรงเรียนแปด (\(J = 8\)) เรามีการประเมินผลการรักษา \(y_j\) และข้อผิดพลาดมาตรฐานของการประมาณการผล \(\sigma_j\)ผลการรักษาในการศึกษาได้มาจากการถดถอยเชิงเส้นของกลุ่มบำบัดโดยใช้คะแนน PSAT-M และ PSAT-V เป็นตัวแปรควบคุม เมื่อไม่มีความเชื่อก่อนที่ใด ๆ ของโรงเรียนได้มากขึ้นหรือน้อยกว่าที่คล้ายกันหรือที่ใด ๆ ของโปรแกรมการฝึกจะมีประสิทธิภาพมากขึ้นเราสามารถพิจารณาผลกระทบการรักษาเป็น ที่แลกเปลี่ยน
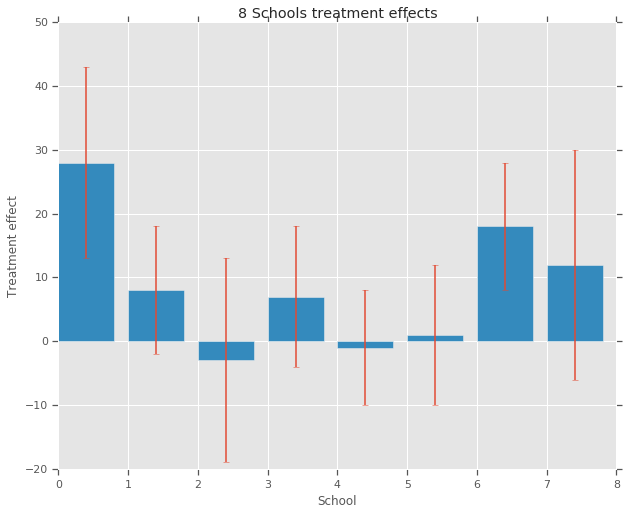
num_schools = 8 # number of schools
treatment_effects = np.array(
[28, 8, -3, 7, -1, 1, 18, 12], dtype=np.float32) # treatment effects
treatment_stddevs = np.array(
[15, 10, 16, 11, 9, 11, 10, 18], dtype=np.float32) # treatment SE
fig, ax = plt.subplots()
plt.bar(range(num_schools), treatment_effects, yerr=treatment_stddevs)
plt.title("8 Schools treatment effects")
plt.xlabel("School")
plt.ylabel("Treatment effect")
fig.set_size_inches(10, 8)
plt.show()
แบบอย่าง
ในการเก็บข้อมูล เราใช้โมเดลปกติแบบมีลำดับชั้น มันเป็นไปตามกระบวนการกำเนิด
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i \sim \text{Normal}\left(\text{loc}{=}\mu,\ \text{scale}{=}\tau \right) \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
ที่ \(\mu\) หมายถึงก่อนที่ผลการรักษาเฉลี่ยและ \(\tau\) ควบคุมวิธีการที่แปรปรวนมากมีระหว่างโรงเรียน \(y_i\) และ \(\sigma_i\) จะสังเกตเห็น ในฐานะที่เป็น \(\tau \rightarrow \infty\)รูปแบบวิธีการรูปแบบที่ไม่รวมกำไรคือแต่ละประมาณการผลการรักษาโรงเรียนได้รับอนุญาตให้เป็นอิสระมากขึ้น ในฐานะที่เป็น \(\tau \rightarrow 0\)รูปแบบวิธีการรูปแบบที่สมบูรณ์ร่วมกันคือทั้งหมดของผลการรักษาที่โรงเรียนมีความใกล้ชิดกับกลุ่มเฉลี่ย \(\mu\)หากต้องการ จำกัด ค่าเบี่ยงเบนมาตรฐานจะเป็นบวกเราวาด \(\tau\) จากการกระจาย lognormal (ซึ่งเทียบเท่ากับการวาดภาพ \(log(\tau)\) จากการแจกแจงแบบปกติ)
ต่อไปนี้การ วินิจฉัยลำเอียงอนุมานกับ Divergences เราเปลี่ยนรูปแบบข้างต้นลงในรูปแบบที่ไม่เป็นศูนย์กลางเทียบเท่า:
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i' \sim \text{Normal}\left(\text{loc}{=}0,\ \text{scale}{=}1 \right) \\ & \theta_i = \mu + \tau \theta_i' \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
เราทำให้เป็นจริงรุ่นนี้เป็น JointDistributionSequential เช่น:
model = tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=10., name="avg_effect"), # `mu` above
tfd.Normal(loc=5., scale=1., name="avg_stddev"), # `log(tau)` above
tfd.Independent(tfd.Normal(loc=tf.zeros(num_schools),
scale=tf.ones(num_schools),
name="school_effects_standard"), # `theta_prime`
reinterpreted_batch_ndims=1),
lambda school_effects_standard, avg_stddev, avg_effect: (
tfd.Independent(tfd.Normal(loc=(avg_effect[..., tf.newaxis] +
tf.exp(avg_stddev[..., tf.newaxis]) *
school_effects_standard), # `theta` above
scale=treatment_stddevs),
name="treatment_effects", # `y` above
reinterpreted_batch_ndims=1))
])
def target_log_prob_fn(avg_effect, avg_stddev, school_effects_standard):
"""Unnormalized target density as a function of states."""
return model.log_prob((
avg_effect, avg_stddev, school_effects_standard, treatment_effects))
การอนุมานแบบเบย์
จากข้อมูลที่ให้มา เราดำเนินการ Hamiltonian Monte Carlo (HMC) เพื่อคำนวณการแจกแจงภายหลังเหนือพารามิเตอร์ของแบบจำลอง
num_results = 5000
num_burnin_steps = 3000
# Improve performance by tracing the sampler using `tf.function`
# and compiling it using XLA.
@tf.function(autograph=False, jit_compile=True)
def do_sampling():
return tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
tf.zeros([], name='init_avg_effect'),
tf.zeros([], name='init_avg_stddev'),
tf.ones([num_schools], name='init_school_effects_standard'),
],
kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.4,
num_leapfrog_steps=3))
states, kernel_results = do_sampling()
avg_effect, avg_stddev, school_effects_standard = states
school_effects_samples = (
avg_effect[:, np.newaxis] +
np.exp(avg_stddev)[:, np.newaxis] * school_effects_standard)
num_accepted = np.sum(kernel_results.is_accepted)
print('Acceptance rate: {}'.format(num_accepted / num_results))
Acceptance rate: 0.5974
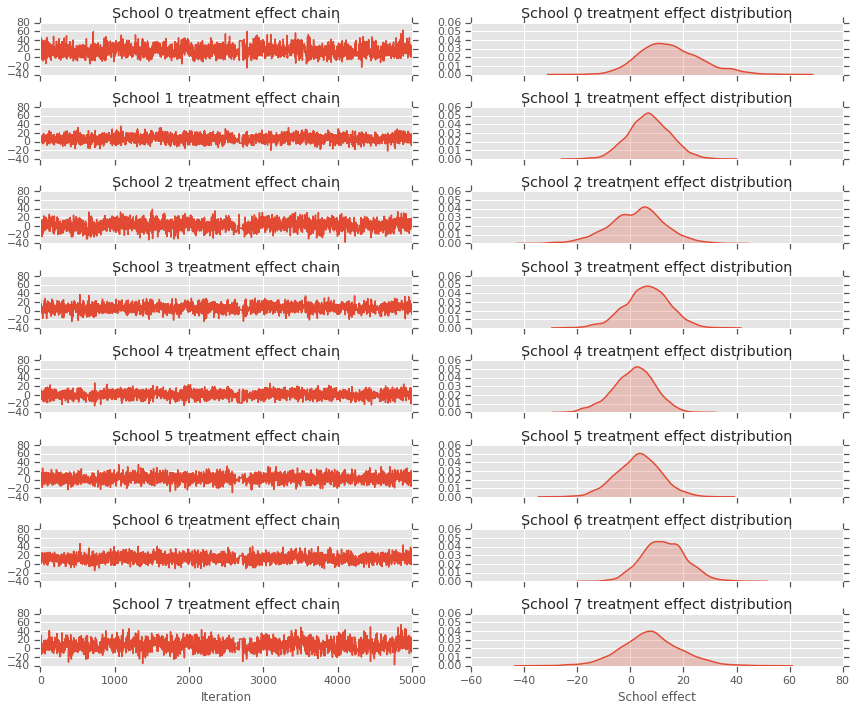
fig, axes = plt.subplots(8, 2, sharex='col', sharey='col')
fig.set_size_inches(12, 10)
for i in range(num_schools):
axes[i][0].plot(school_effects_samples[:,i].numpy())
axes[i][0].title.set_text("School {} treatment effect chain".format(i))
sns.kdeplot(school_effects_samples[:,i].numpy(), ax=axes[i][1], shade=True)
axes[i][1].title.set_text("School {} treatment effect distribution".format(i))
axes[num_schools - 1][0].set_xlabel("Iteration")
axes[num_schools - 1][1].set_xlabel("School effect")
fig.tight_layout()
plt.show()
print("E[avg_effect] = {}".format(np.mean(avg_effect)))
print("E[avg_stddev] = {}".format(np.mean(avg_stddev)))
print("E[school_effects_standard] =")
print(np.mean(school_effects_standard[:, ]))
print("E[school_effects] =")
print(np.mean(school_effects_samples[:, ], axis=0))
E[avg_effect] = 5.57183933258 E[avg_stddev] = 2.47738981247 E[school_effects_standard] = 0.08509017 E[school_effects] = [15.0051 7.103311 2.4552586 6.2744603 1.3364682 3.1125953 12.762501 7.743602 ]
# Compute the 95% interval for school_effects
school_effects_low = np.array([
np.percentile(school_effects_samples[:, i], 2.5) for i in range(num_schools)
])
school_effects_med = np.array([
np.percentile(school_effects_samples[:, i], 50) for i in range(num_schools)
])
school_effects_hi = np.array([
np.percentile(school_effects_samples[:, i], 97.5)
for i in range(num_schools)
])
fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True)
ax.scatter(np.array(range(num_schools)), school_effects_med, color='red', s=60)
ax.scatter(
np.array(range(num_schools)) + 0.1, treatment_effects, color='blue', s=60)
plt.plot([-0.2, 7.4], [np.mean(avg_effect),
np.mean(avg_effect)], 'k', linestyle='--')
ax.errorbar(
np.array(range(8)),
school_effects_med,
yerr=[
school_effects_med - school_effects_low,
school_effects_hi - school_effects_med
],
fmt='none')
ax.legend(('avg_effect', 'HMC', 'Observed effect'), fontsize=14)
plt.xlabel('School')
plt.ylabel('Treatment effect')
plt.title('HMC estimated school treatment effects vs. observed data')
fig.set_size_inches(10, 8)
plt.show()
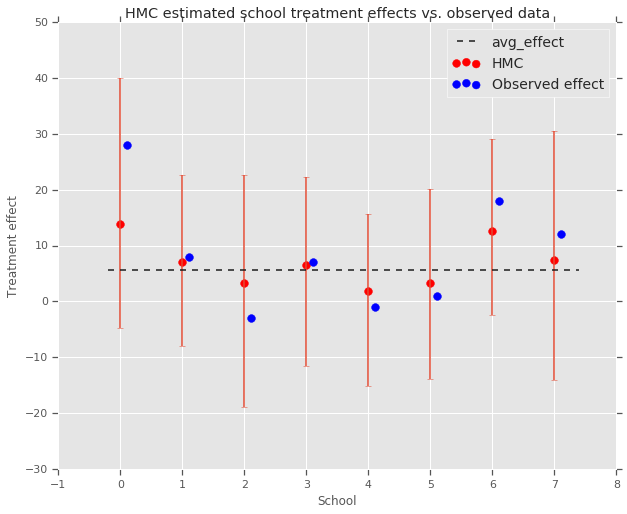
เราสามารถสังเกตเห็นการหดตัวที่มีต่อกลุ่ม avg_effect ดังกล่าวข้างต้น
print("Inferred posterior mean: {0:.2f}".format(
np.mean(school_effects_samples[:,])))
print("Inferred posterior mean se: {0:.2f}".format(
np.std(school_effects_samples[:,])))
Inferred posterior mean: 6.97 Inferred posterior mean se: 10.41
คำติชม
ที่จะได้รับการกระจายการทำนายหลังคือรูปแบบของข้อมูลใหม่ \(y^*\) ได้รับข้อมูลที่สังเกต \(y\):
\[ p(y^*|y) \propto \int_\theta p(y^* | \theta)p(\theta |y)d\theta\]
เราแทนที่ค่าของตัวแปรสุ่มที่อยู่ในรูปแบบที่จะกำหนดให้ค่าเฉลี่ยของการกระจายหลังและตัวอย่างจากรูปแบบที่จะสร้างข้อมูลใหม่ \(y^*\)
sample_shape = [5000]
_, _, _, predictive_treatment_effects = model.sample(
value=(tf.broadcast_to(np.mean(avg_effect, 0), sample_shape),
tf.broadcast_to(np.mean(avg_stddev, 0), sample_shape),
tf.broadcast_to(np.mean(school_effects_standard, 0),
sample_shape + [num_schools]),
None))
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(predictive_treatment_effects[:, 2*i].numpy(),
ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect posterior predictive".format(2*i))
sns.kdeplot(predictive_treatment_effects[:, 2*i + 1].numpy(),
ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect posterior predictive".format(2*i + 1))
plt.show()
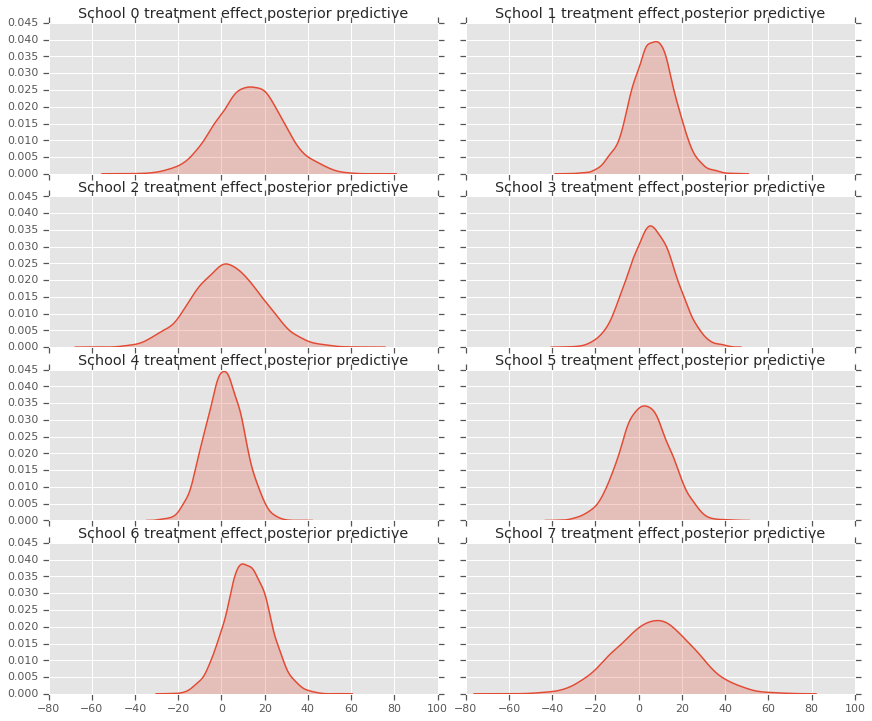
# The mean predicted treatment effects for each of the eight schools.
prediction = np.mean(predictive_treatment_effects, axis=0)
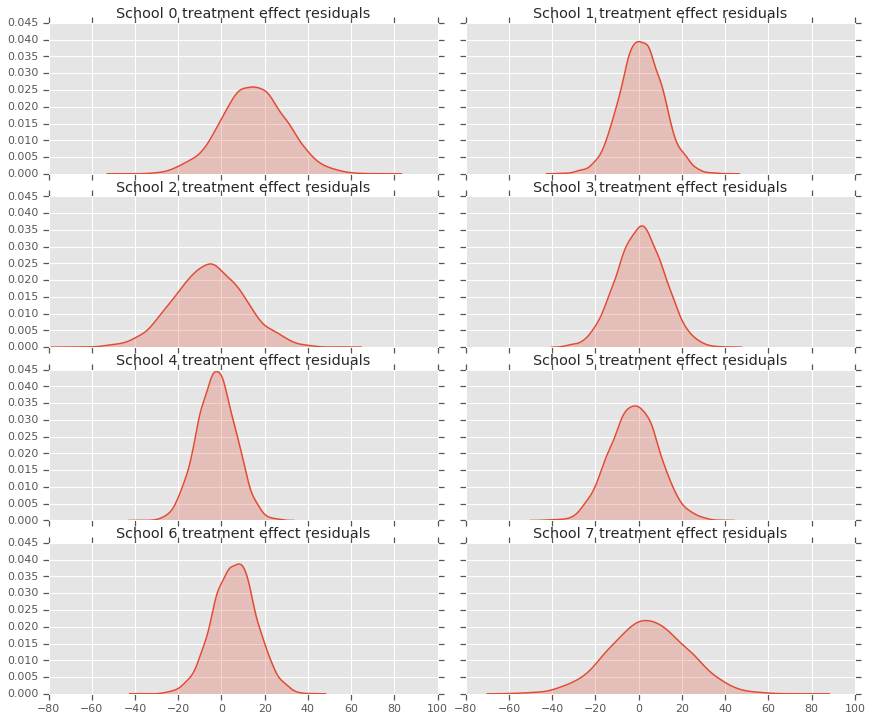
เราสามารถดูส่วนที่เหลือระหว่างข้อมูลผลการรักษาและการคาดการณ์ของแบบจำลองหลัง สิ่งเหล่านี้สอดคล้องกับโครงเรื่องด้านบนซึ่งแสดงให้เห็นการหดตัวของผลกระทบโดยประมาณที่มีต่อค่าเฉลี่ยของประชากร
treatment_effects - prediction
array([14.905351 , 1.2838383, -5.6966295, 0.8327627, -2.3356671,
-2.0363257, 5.997898 , 4.3731265], dtype=float32)
เนื่องจากเรามีการกระจายคำทำนายสำหรับแต่ละโรงเรียน เราจึงสามารถพิจารณาการกระจายของที่เหลือได้เช่นกัน
residuals = treatment_effects - predictive_treatment_effects
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(residuals[:, 2*i].numpy(), ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect residuals".format(2*i))
sns.kdeplot(residuals[:, 2*i + 1].numpy(), ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect residuals".format(2*i + 1))
plt.show()
รับทราบ
กวดวิชานี้ถูกเขียนเดิมในเอ็ดเวิร์ด 1.0 ( แหล่งที่มา ) เราขอขอบคุณผู้ร่วมเขียนข้อความและแก้ไขเวอร์ชันนั้น
อ้างอิง
- โดนัลด์ บี. รูบิน. การประมาณค่าในการทดลองสุ่มคู่ขนาน วารสารสถิติการศึกษา 6(4):377-401, 1981.
- แอนดรูว์ เกลแมน, จอห์น คาร์ลิน, ฮัล สเติร์น, เดวิด ดันสัน, อากิ เวห์ทารี และโดนัลด์ รูบิน การวิเคราะห์ข้อมูลแบบเบย์ ฉบับที่ 3 แชปแมนและฮอลล์/CRC, 2013