
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Проблема восемь школ ( Rubin 1981 ) считает , что эффективность программ наставничества SAT , проводимых параллельно в восьми школах. Она стала классической проблемой ( байесовский анализ данных , Стан ) , что иллюстрирует полезность иерархического моделирования для обмена информации между сменными группами.
РЕАЛИЗАЦИЯ ниже , является адаптацией Эдварда 1.0 учебника .
Импорт
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import distributions as tfd
import warnings
tf.enable_v2_behavior()
plt.style.use("ggplot")
warnings.filterwarnings('ignore')
Данные
Из анализа байесовских данных, раздел 5.5 (Гельман и др., 2013):
Для Службы образовательного тестирования было проведено исследование, чтобы проанализировать влияние специальных программ коучинга для SAT-V (Scholastic Aptitude Test-Verbal) в каждой из восьми средних школ. Переменной результата в каждом исследовании была оценка по специальному тесту SAT-V, стандартизированного теста с множественным выбором, который проводится Службой образовательного тестирования и используется, чтобы помочь колледжам принимать решения о приеме; оценки могут варьироваться от 200 до 800, со средним значением около 500 и стандартным отклонением около 100. Экзамены SAT рассчитаны на устойчивость к краткосрочным усилиям, направленным конкретно на улучшение результатов теста; вместо этого они предназначены для отражения приобретенных знаний и способностей, приобретенных в течение многих лет обучения. Тем не менее, каждая из восьми школ, участвовавших в этом исследовании, сочла свою краткосрочную программу коучинга очень успешной в повышении результатов SAT. Кроме того, не было никаких предварительных оснований полагать, что какая-либо из восьми программ более эффективна, чем любая другая, или что некоторые из них более похожи по действию друг на друга, чем на какие-либо другие.
Для каждого из восьми школ (\(J = 8\)), мы имеем оценочный эффект лечения \(y_j\) и стандартную ошибку оценка эффекта \(\sigma_j\). Эффекты лечения в исследовании были получены путем линейной регрессии в группе лечения с использованием показателей PSAT-M и PSAT-V в качестве контрольных переменных. Так как не было никакого предварительного убеждения , что какие - либо из школ было более или менее похожи , или что какое - либо из тренерских программ будет более эффективным, мы можем рассмотреть эффекты лечения , как заменяемые .
num_schools = 8 # number of schools
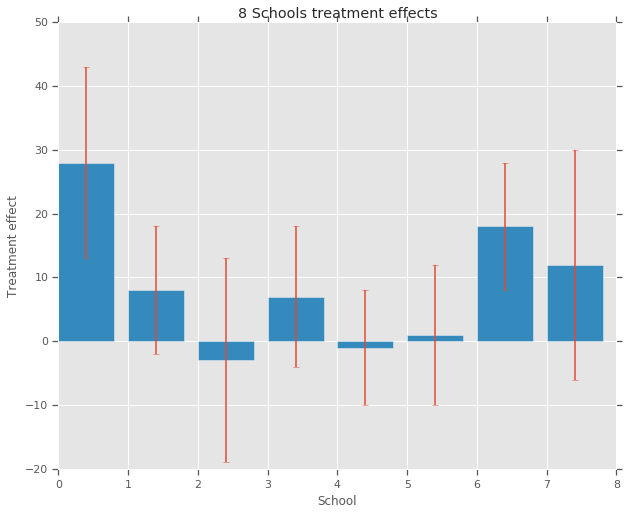
treatment_effects = np.array(
[28, 8, -3, 7, -1, 1, 18, 12], dtype=np.float32) # treatment effects
treatment_stddevs = np.array(
[15, 10, 16, 11, 9, 11, 10, 18], dtype=np.float32) # treatment SE
fig, ax = plt.subplots()
plt.bar(range(num_schools), treatment_effects, yerr=treatment_stddevs)
plt.title("8 Schools treatment effects")
plt.xlabel("School")
plt.ylabel("Treatment effect")
fig.set_size_inches(10, 8)
plt.show()
Модель
Для сбора данных мы используем иерархическую нормальную модель. Он следует за генеративным процессом,
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i \sim \text{Normal}\left(\text{loc}{=}\mu,\ \text{scale}{=}\tau \right) \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
где \(\mu\) представляет предшествующие среднего эффекта лечения и \(\tau\) управления , сколько существует разницы между школами. \(y_i\) и \(\sigma_i\) наблюдаются. Как \(\tau \rightarrow \infty\), модель приближается к не-пулы модели, то есть, каждая из оценок эффекта лечения школы могут быть более независимыми. Как \(\tau \rightarrow 0\), модель приближается к модели комплектно-пул, то есть, все эффекты лечения школы ближе к группе среднего \(\mu\). Чтобы ограничить стандартное отклонение будет положительными, мы проводим \(\tau\) из распределения логнормального (что эквивалентно рисунок \(log(\tau)\) от нормального распределения).
После Диагностирования предвзято Выведение с дивергенцией , мы преобразуем модель выше в эквивалентную , не в центре модели:
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i' \sim \text{Normal}\left(\text{loc}{=}0,\ \text{scale}{=}1 \right) \\ & \theta_i = \mu + \tau \theta_i' \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
Мы материализовать эту модель как JointDistributionSequential например:
model = tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=10., name="avg_effect"), # `mu` above
tfd.Normal(loc=5., scale=1., name="avg_stddev"), # `log(tau)` above
tfd.Independent(tfd.Normal(loc=tf.zeros(num_schools),
scale=tf.ones(num_schools),
name="school_effects_standard"), # `theta_prime`
reinterpreted_batch_ndims=1),
lambda school_effects_standard, avg_stddev, avg_effect: (
tfd.Independent(tfd.Normal(loc=(avg_effect[..., tf.newaxis] +
tf.exp(avg_stddev[..., tf.newaxis]) *
school_effects_standard), # `theta` above
scale=treatment_stddevs),
name="treatment_effects", # `y` above
reinterpreted_batch_ndims=1))
])
def target_log_prob_fn(avg_effect, avg_stddev, school_effects_standard):
"""Unnormalized target density as a function of states."""
return model.log_prob((
avg_effect, avg_stddev, school_effects_standard, treatment_effects))
Байесовский вывод
Учитывая данные, мы выполняем гамильтониан Монте-Карло (HMC), чтобы вычислить апостериорное распределение по параметрам модели.
num_results = 5000
num_burnin_steps = 3000
# Improve performance by tracing the sampler using `tf.function`
# and compiling it using XLA.
@tf.function(autograph=False, jit_compile=True)
def do_sampling():
return tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
tf.zeros([], name='init_avg_effect'),
tf.zeros([], name='init_avg_stddev'),
tf.ones([num_schools], name='init_school_effects_standard'),
],
kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.4,
num_leapfrog_steps=3))
states, kernel_results = do_sampling()
avg_effect, avg_stddev, school_effects_standard = states
school_effects_samples = (
avg_effect[:, np.newaxis] +
np.exp(avg_stddev)[:, np.newaxis] * school_effects_standard)
num_accepted = np.sum(kernel_results.is_accepted)
print('Acceptance rate: {}'.format(num_accepted / num_results))
Acceptance rate: 0.5974
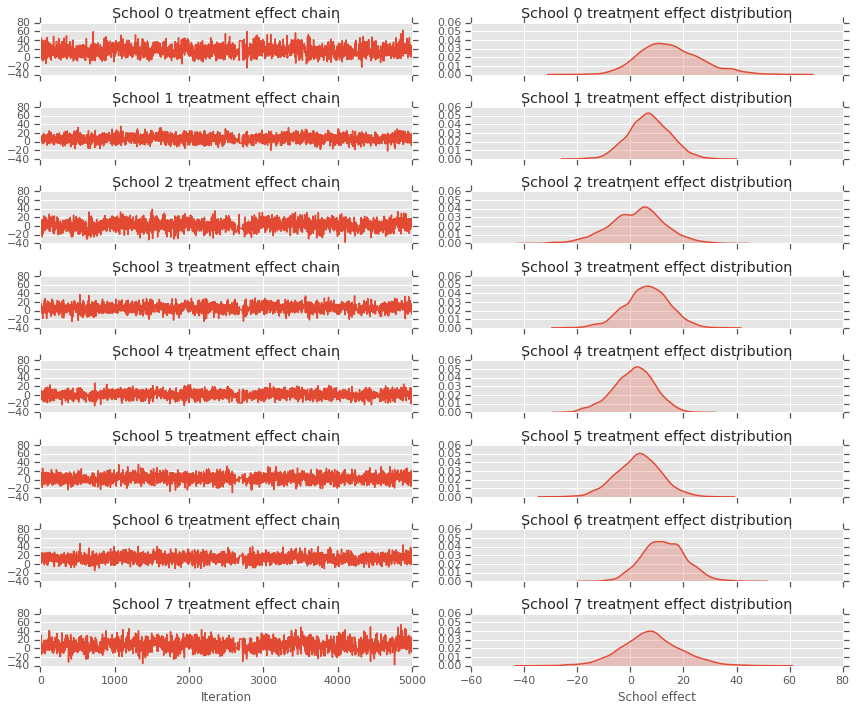
fig, axes = plt.subplots(8, 2, sharex='col', sharey='col')
fig.set_size_inches(12, 10)
for i in range(num_schools):
axes[i][0].plot(school_effects_samples[:,i].numpy())
axes[i][0].title.set_text("School {} treatment effect chain".format(i))
sns.kdeplot(school_effects_samples[:,i].numpy(), ax=axes[i][1], shade=True)
axes[i][1].title.set_text("School {} treatment effect distribution".format(i))
axes[num_schools - 1][0].set_xlabel("Iteration")
axes[num_schools - 1][1].set_xlabel("School effect")
fig.tight_layout()
plt.show()
print("E[avg_effect] = {}".format(np.mean(avg_effect)))
print("E[avg_stddev] = {}".format(np.mean(avg_stddev)))
print("E[school_effects_standard] =")
print(np.mean(school_effects_standard[:, ]))
print("E[school_effects] =")
print(np.mean(school_effects_samples[:, ], axis=0))
E[avg_effect] = 5.57183933258 E[avg_stddev] = 2.47738981247 E[school_effects_standard] = 0.08509017 E[school_effects] = [15.0051 7.103311 2.4552586 6.2744603 1.3364682 3.1125953 12.762501 7.743602 ]
# Compute the 95% interval for school_effects
school_effects_low = np.array([
np.percentile(school_effects_samples[:, i], 2.5) for i in range(num_schools)
])
school_effects_med = np.array([
np.percentile(school_effects_samples[:, i], 50) for i in range(num_schools)
])
school_effects_hi = np.array([
np.percentile(school_effects_samples[:, i], 97.5)
for i in range(num_schools)
])
fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True)
ax.scatter(np.array(range(num_schools)), school_effects_med, color='red', s=60)
ax.scatter(
np.array(range(num_schools)) + 0.1, treatment_effects, color='blue', s=60)
plt.plot([-0.2, 7.4], [np.mean(avg_effect),
np.mean(avg_effect)], 'k', linestyle='--')
ax.errorbar(
np.array(range(8)),
school_effects_med,
yerr=[
school_effects_med - school_effects_low,
school_effects_hi - school_effects_med
],
fmt='none')
ax.legend(('avg_effect', 'HMC', 'Observed effect'), fontsize=14)
plt.xlabel('School')
plt.ylabel('Treatment effect')
plt.title('HMC estimated school treatment effects vs. observed data')
fig.set_size_inches(10, 8)
plt.show()
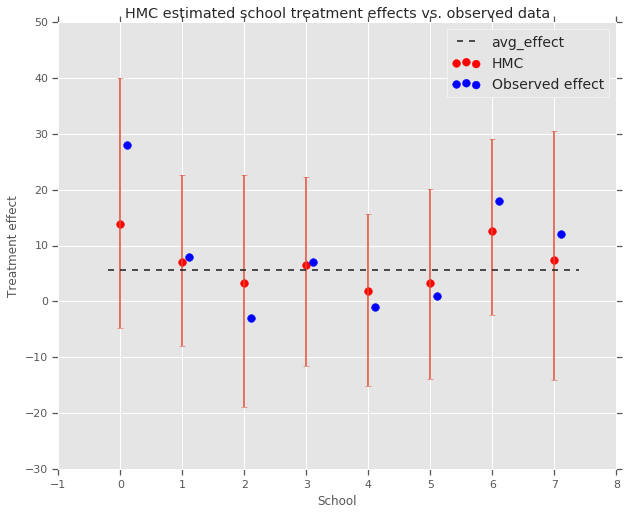
Мы можем наблюдать усадку к группе avg_effect выше.
print("Inferred posterior mean: {0:.2f}".format(
np.mean(school_effects_samples[:,])))
print("Inferred posterior mean se: {0:.2f}".format(
np.std(school_effects_samples[:,])))
Inferred posterior mean: 6.97 Inferred posterior mean se: 10.41
Критика
Для того, чтобы получить заднее прогностическое распределение, т.е. модели новых данных \(y^*\) учитывая наблюдаемый данные \(y\):
\[ p(y^*|y) \propto \int_\theta p(y^* | \theta)p(\theta |y)d\theta\]
мы переопределяют значения случайных величин в модели , чтобы установить их среднее апостериорного распределения, и образца от этой модели , чтобы генерировать новые данные \(y^*\).
sample_shape = [5000]
_, _, _, predictive_treatment_effects = model.sample(
value=(tf.broadcast_to(np.mean(avg_effect, 0), sample_shape),
tf.broadcast_to(np.mean(avg_stddev, 0), sample_shape),
tf.broadcast_to(np.mean(school_effects_standard, 0),
sample_shape + [num_schools]),
None))
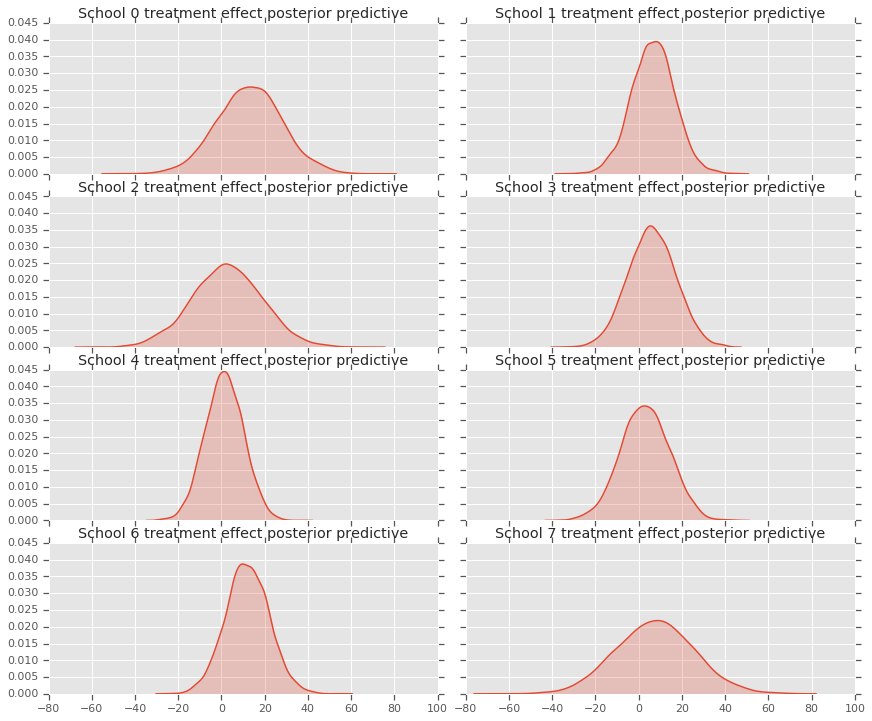
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(predictive_treatment_effects[:, 2*i].numpy(),
ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect posterior predictive".format(2*i))
sns.kdeplot(predictive_treatment_effects[:, 2*i + 1].numpy(),
ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect posterior predictive".format(2*i + 1))
plt.show()
# The mean predicted treatment effects for each of the eight schools.
prediction = np.mean(predictive_treatment_effects, axis=0)
Мы можем посмотреть на остатки между данными эффектов лечения и прогнозами апостериорной модели. Они соответствуют графику выше, который показывает уменьшение оцененных эффектов по отношению к среднему по населению.
treatment_effects - prediction
array([14.905351 , 1.2838383, -5.6966295, 0.8327627, -2.3356671,
-2.0363257, 5.997898 , 4.3731265], dtype=float32)
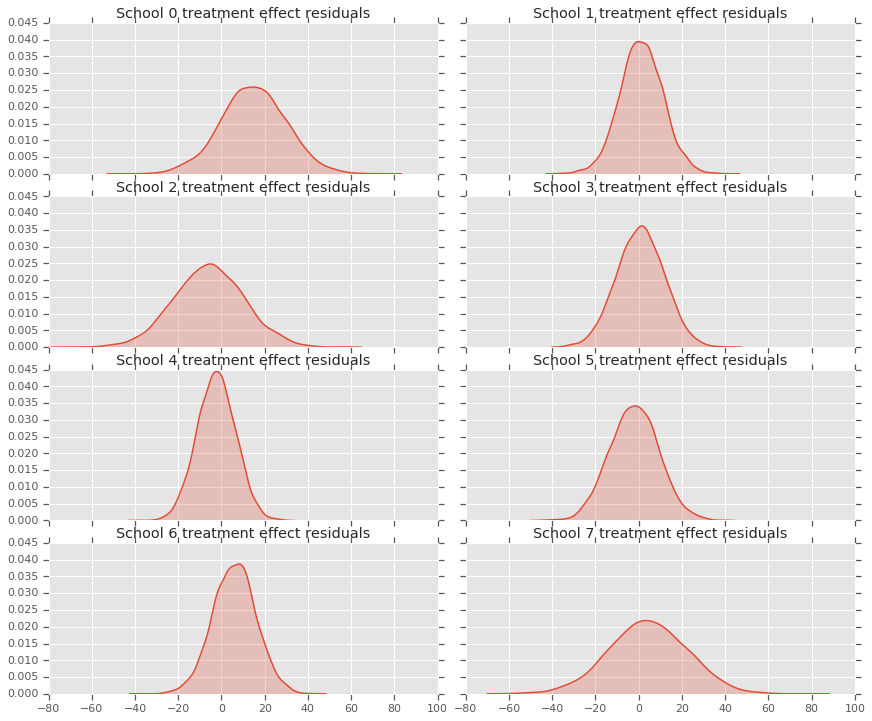
Поскольку у нас есть распределение прогнозов для каждой школы, мы также можем учитывать распределение остатков.
residuals = treatment_effects - predictive_treatment_effects
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(residuals[:, 2*i].numpy(), ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect residuals".format(2*i))
sns.kdeplot(residuals[:, 2*i + 1].numpy(), ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect residuals".format(2*i + 1))
plt.show()
Благодарности
Этот учебник был изначально написан на Эдварде 1.0 ( источник ). Мы благодарим всех участников за написание и исправление этой версии.
использованная литература
- Дональд Б. Рубин. Оценка в параллельных рандомизированных экспериментах. Журнал статистики образования, 6 (4): 377-401, 1981.
- Эндрю Гельман, Джон Карлин, Хэл Стерн, Дэвид Дансон, Аки Вехтари и Дональд Рубин. Байесовский анализ данных, третье издание. Чепмен и Холл / CRC, 2013.