
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
בעית שמונה בתי הספר ( רובין 1981 ) רואה את האפקטיביות של תוכניות אימון SAT שנערכו במקביל בשמונה בתי ספר. זה הפך להיות בעיה קלסית ( ניתוח נתונים בייס , סטן ) הממחיש את השימושיות של מודלים היררכיים לשיתוף מידע בין קבוצות חליפיות.
Implemention מתחת הוא עיבוד של 1.0 אדוארד הדרכה .
יבוא
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import distributions as tfd
import warnings
tf.enable_v2_behavior()
plt.style.use("ggplot")
warnings.filterwarnings('ignore')
הנתונים
מתוך Bayesian Data Analysis, סעיף 5.5 (Gelman et al. 2013):
בוצע מחקר עבור שירות המבחנים החינוכיים כדי לנתח את ההשפעות של תכניות אימון מיוחדות עבור SAT-V (מבחן כושר לימודי-מילולי) בכל אחד משמונה בתי ספר תיכוניים. משתנה התוצאה בכל מחקר היה הציון בניהול מיוחד של ה-SAT-V, מבחן רב-ברירה סטנדרטי המנוהל על ידי שירות המבחנים החינוכיים ומשמש כדי לסייע למכללות לקבל החלטות קבלה; הציונים יכולים להשתנות בין 200 ל-800, עם ממוצע של כ-500 וסטיית תקן כ-100. בחינות ה-SAT נועדו להיות עמידות בפני מאמצים קצרי טווח המכוונים במיוחד לשיפור הביצועים במבחן; במקום זאת הם נועדו לשקף ידע שנרכש ויכולות שפותחו במהלך שנות חינוך רבות. עם זאת, כל אחד משמונת בתי הספר במחקר זה ראה בתוכנית האימון לטווח הקצר שלו מצליחה מאוד בהעלאת ציוני SAT. כמו כן, לא הייתה סיבה קודמת להאמין שאף אחת משמונה התוכניות הייתה יעילה יותר מכל אחת אחרת או שחלקן דומות יותר זו לזו מאשר לכל אחת אחרת.
עבור כל אחת משמונה בתי ספר (\(J = 8\)), יש לנו השפעה הטיפול מוערך \(y_j\) לבין סטיית התקן של אומדן ההשפעה \(\sigma_j\). השפעות הטיפול במחקר התקבלו על ידי רגרסיה ליניארית על קבוצת הטיפול תוך שימוש בציוני PSAT-M ו-PSAT-V כמשתני בקרה. כפי שאין אמונה לפני שכל בתי הספר היו פחות או יותר דומה או שכל התוכניות אימון יהיה יעיל יותר, נוכל לשקול את השפעות הטיפול כפי חליפי .
num_schools = 8 # number of schools
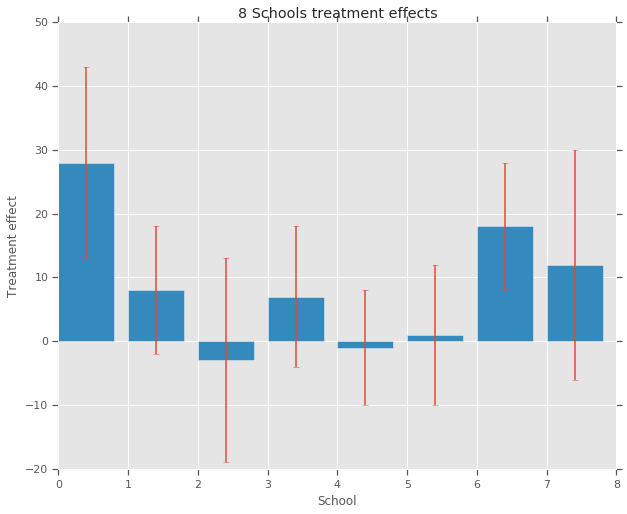
treatment_effects = np.array(
[28, 8, -3, 7, -1, 1, 18, 12], dtype=np.float32) # treatment effects
treatment_stddevs = np.array(
[15, 10, 16, 11, 9, 11, 10, 18], dtype=np.float32) # treatment SE
fig, ax = plt.subplots()
plt.bar(range(num_schools), treatment_effects, yerr=treatment_stddevs)
plt.title("8 Schools treatment effects")
plt.xlabel("School")
plt.ylabel("Treatment effect")
fig.set_size_inches(10, 8)
plt.show()
דֶגֶם
כדי ללכוד את הנתונים, אנו משתמשים במודל נורמלי היררכי. זה עוקב אחר התהליך הגנרטיבי,
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i \sim \text{Normal}\left(\text{loc}{=}\mu,\ \text{scale}{=}\tau \right) \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
איפה \(\mu\) מייצג את שפעת טיפול ממוצעת המוקדם \(\tau\) שולט כמה לשונות יש בין בתי ספר. \(y_i\) ו \(\sigma_i\) הם נצפו. כפי \(\tau \rightarrow \infty\), המודל מתקרב מודל לא-איגום, כלומר, כל אחד מהאומדנים השפעת הטיפול הספר רשאים להיות עצמאית יותר. כפי \(\tau \rightarrow 0\), המודל מתקרב למודל-pooling המוחלטת, כלומר, כול השפעות טיפול ספר קרובים לממוצע הקבוצה \(\mu\). כדי להגביל את סטיית התקן להיות חיובית, אנו מפנים \(\tau\) מן ההתפלגות הלוג-נורמלית (שהוא שווה ערך ל ציור \(log(\tau)\) מן התפלגות נורמלית).
בעקבות האבחון מוטה הסקה עם הסתעפויות , אנו הופכים את המודל הנ"ל לתוך מודל מקביל שאינו מרוכז:
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i' \sim \text{Normal}\left(\text{loc}{=}0,\ \text{scale}{=}1 \right) \\ & \theta_i = \mu + \tau \theta_i' \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
אנחנו להמחיש את המודל הזה בתור JointDistributionSequential למשל:
model = tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=10., name="avg_effect"), # `mu` above
tfd.Normal(loc=5., scale=1., name="avg_stddev"), # `log(tau)` above
tfd.Independent(tfd.Normal(loc=tf.zeros(num_schools),
scale=tf.ones(num_schools),
name="school_effects_standard"), # `theta_prime`
reinterpreted_batch_ndims=1),
lambda school_effects_standard, avg_stddev, avg_effect: (
tfd.Independent(tfd.Normal(loc=(avg_effect[..., tf.newaxis] +
tf.exp(avg_stddev[..., tf.newaxis]) *
school_effects_standard), # `theta` above
scale=treatment_stddevs),
name="treatment_effects", # `y` above
reinterpreted_batch_ndims=1))
])
def target_log_prob_fn(avg_effect, avg_stddev, school_effects_standard):
"""Unnormalized target density as a function of states."""
return model.log_prob((
avg_effect, avg_stddev, school_effects_standard, treatment_effects))
מסקנות בייסיאניות
בהינתן נתונים, אנו מבצעים Hamiltonian Monte Carlo (HMC) כדי לחשב את ההתפלגות האחורית על פני הפרמטרים של המודל.
num_results = 5000
num_burnin_steps = 3000
# Improve performance by tracing the sampler using `tf.function`
# and compiling it using XLA.
@tf.function(autograph=False, jit_compile=True)
def do_sampling():
return tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
tf.zeros([], name='init_avg_effect'),
tf.zeros([], name='init_avg_stddev'),
tf.ones([num_schools], name='init_school_effects_standard'),
],
kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.4,
num_leapfrog_steps=3))
states, kernel_results = do_sampling()
avg_effect, avg_stddev, school_effects_standard = states
school_effects_samples = (
avg_effect[:, np.newaxis] +
np.exp(avg_stddev)[:, np.newaxis] * school_effects_standard)
num_accepted = np.sum(kernel_results.is_accepted)
print('Acceptance rate: {}'.format(num_accepted / num_results))
Acceptance rate: 0.5974
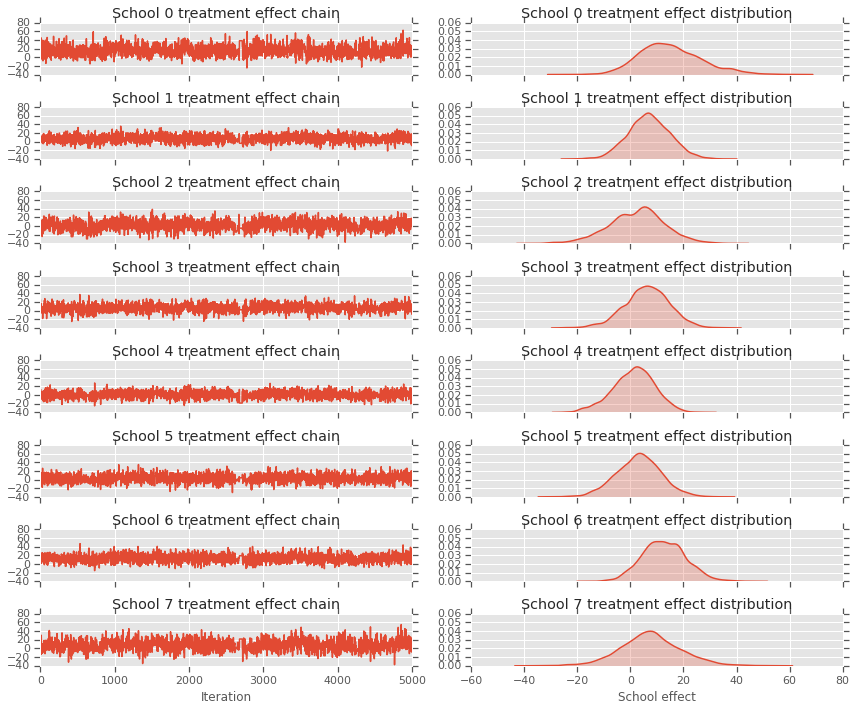
fig, axes = plt.subplots(8, 2, sharex='col', sharey='col')
fig.set_size_inches(12, 10)
for i in range(num_schools):
axes[i][0].plot(school_effects_samples[:,i].numpy())
axes[i][0].title.set_text("School {} treatment effect chain".format(i))
sns.kdeplot(school_effects_samples[:,i].numpy(), ax=axes[i][1], shade=True)
axes[i][1].title.set_text("School {} treatment effect distribution".format(i))
axes[num_schools - 1][0].set_xlabel("Iteration")
axes[num_schools - 1][1].set_xlabel("School effect")
fig.tight_layout()
plt.show()
print("E[avg_effect] = {}".format(np.mean(avg_effect)))
print("E[avg_stddev] = {}".format(np.mean(avg_stddev)))
print("E[school_effects_standard] =")
print(np.mean(school_effects_standard[:, ]))
print("E[school_effects] =")
print(np.mean(school_effects_samples[:, ], axis=0))
E[avg_effect] = 5.57183933258 E[avg_stddev] = 2.47738981247 E[school_effects_standard] = 0.08509017 E[school_effects] = [15.0051 7.103311 2.4552586 6.2744603 1.3364682 3.1125953 12.762501 7.743602 ]
# Compute the 95% interval for school_effects
school_effects_low = np.array([
np.percentile(school_effects_samples[:, i], 2.5) for i in range(num_schools)
])
school_effects_med = np.array([
np.percentile(school_effects_samples[:, i], 50) for i in range(num_schools)
])
school_effects_hi = np.array([
np.percentile(school_effects_samples[:, i], 97.5)
for i in range(num_schools)
])
fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True)
ax.scatter(np.array(range(num_schools)), school_effects_med, color='red', s=60)
ax.scatter(
np.array(range(num_schools)) + 0.1, treatment_effects, color='blue', s=60)
plt.plot([-0.2, 7.4], [np.mean(avg_effect),
np.mean(avg_effect)], 'k', linestyle='--')
ax.errorbar(
np.array(range(8)),
school_effects_med,
yerr=[
school_effects_med - school_effects_low,
school_effects_hi - school_effects_med
],
fmt='none')
ax.legend(('avg_effect', 'HMC', 'Observed effect'), fontsize=14)
plt.xlabel('School')
plt.ylabel('Treatment effect')
plt.title('HMC estimated school treatment effects vs. observed data')
fig.set_size_inches(10, 8)
plt.show()
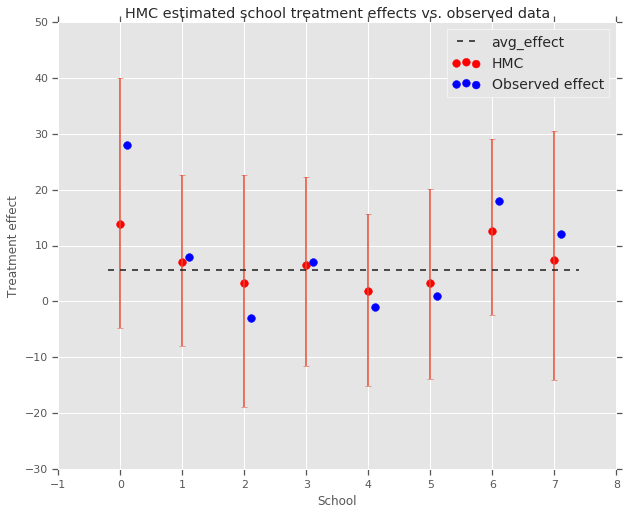
אנחנו יכולים לבחון את ההצטמקות כלפי קבוצת avg_effect לעיל.
print("Inferred posterior mean: {0:.2f}".format(
np.mean(school_effects_samples[:,])))
print("Inferred posterior mean se: {0:.2f}".format(
np.std(school_effects_samples[:,])))
Inferred posterior mean: 6.97 Inferred posterior mean se: 10.41
ביקורת
כדי לקבל את חלוקת חזוי האחורי, כלומר, מודל נתונים חדשים \(y^*\) בהתחשב בנתונים נצפים \(y\):
\[ p(y^*|y) \propto \int_\theta p(y^* | \theta)p(\theta |y)d\theta\]
אנו מבטלים את הערכים של המשתנים האקראיים במודל להגדיר אותם הממוצע של ההתפלגות האחורית, ואת המדגם לבין מודל זה כדי להפיק נתונים חדש \(y^*\).
sample_shape = [5000]
_, _, _, predictive_treatment_effects = model.sample(
value=(tf.broadcast_to(np.mean(avg_effect, 0), sample_shape),
tf.broadcast_to(np.mean(avg_stddev, 0), sample_shape),
tf.broadcast_to(np.mean(school_effects_standard, 0),
sample_shape + [num_schools]),
None))
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(predictive_treatment_effects[:, 2*i].numpy(),
ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect posterior predictive".format(2*i))
sns.kdeplot(predictive_treatment_effects[:, 2*i + 1].numpy(),
ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect posterior predictive".format(2*i + 1))
plt.show()
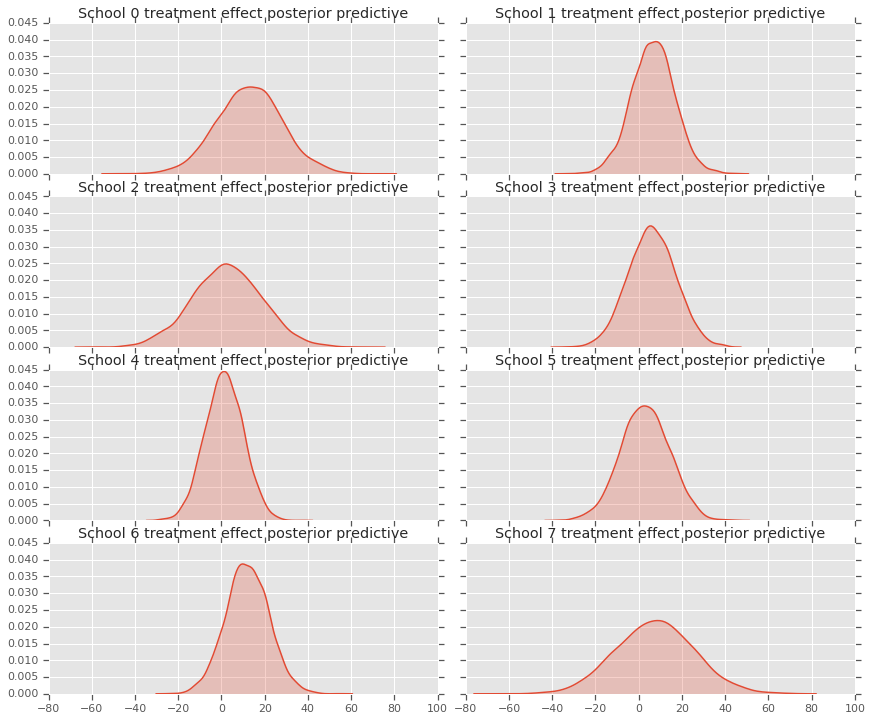
# The mean predicted treatment effects for each of the eight schools.
prediction = np.mean(predictive_treatment_effects, axis=0)
אנו יכולים להסתכל על השאריות בין נתוני השפעות הטיפול לבין התחזיות של המודל האחורי. אלו מתכתבים עם העלילה לעיל המציגה את הצטמקות ההשפעות המשוערות כלפי ממוצע האוכלוסייה.
treatment_effects - prediction
array([14.905351 , 1.2838383, -5.6966295, 0.8327627, -2.3356671,
-2.0363257, 5.997898 , 4.3731265], dtype=float32)
מכיוון שיש לנו התפלגות של תחזיות לכל בית ספר, אנחנו יכולים לשקול גם את התפלגות השאריות.
residuals = treatment_effects - predictive_treatment_effects
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(residuals[:, 2*i].numpy(), ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect residuals".format(2*i))
sns.kdeplot(residuals[:, 2*i + 1].numpy(), ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect residuals".format(2*i + 1))
plt.show()
תודות
הדרכה זו נכתבה במקור אדוארד 1.0 ( מקור ). אנו מודים לכל התורמים לכתיבת הגרסה הזו ולתיקון שלה.
הפניות
- דונלד ב. רובין. אומדן בניסויים אקראיים מקבילים. כתב עת לסטטיסטיקה חינוכית, 6(4):377-401, 1981.
- אנדרו גלמן, ג'ון קרלין, האל סטרן, דיוויד דאנסון, אקי והטרי ודונלד רובין. ניתוח נתונים בייסיאני, מהדורה שלישית. צ'פמן והול/CRC, 2013.