
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
আট বিদ্যালয় সমস্যা ( রুবিন 1981 ) আট স্কুলে সমান্তরাল পরিচালিত স্যাট কোচিং প্রোগ্রামের কার্যকারিতা বিবেচনা করে। এটা একটা ক্লাসিক সমস্যা (পরিণত হয়েছে Bayesian ডেটা বিশ্লেষণ , স্ট্যান ) যে বিনিময়যোগ্য দলের মধ্যে তথ্য ভাগ করার জন্য হায়ারারকিকাল মডেলিং উপযোগিতা প্রকাশ করে।
নিচে implemention একটি এডওয়ার্ড 1.0 অভিযোজিত হয়েছে টিউটোরিয়াল ।
আমদানি
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import distributions as tfd
import warnings
tf.enable_v2_behavior()
plt.style.use("ggplot")
warnings.filterwarnings('ignore')
তথ্যটি
Bayesian ডেটা বিশ্লেষণ থেকে, বিভাগ 5.5 (Gelman et al. 2013):
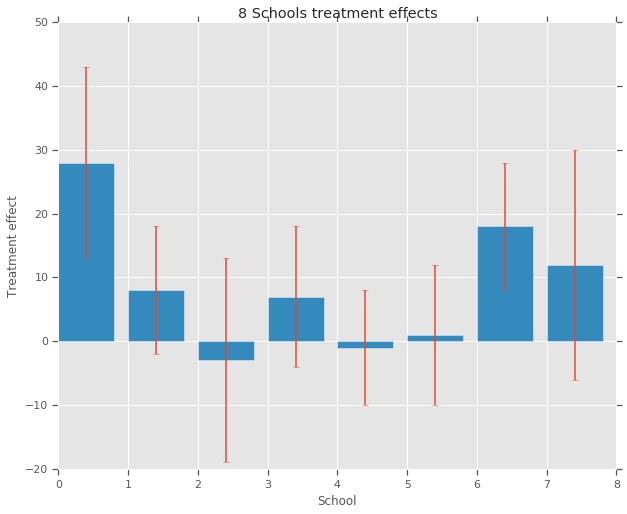
আটটি উচ্চ বিদ্যালয়ের প্রতিটিতে SAT-V (স্কলাস্টিক অ্যাপটিটিউড টেস্ট-ভারবাল) এর জন্য বিশেষ কোচিং প্রোগ্রামের প্রভাব বিশ্লেষণ করার জন্য শিক্ষাগত পরীক্ষা পরিষেবার জন্য একটি সমীক্ষা করা হয়েছিল। প্রতিটি গবেষণায় ফলাফল পরিবর্তনশীল ছিল SAT-V-এর একটি বিশেষ প্রশাসনের স্কোর, শিক্ষাগত পরীক্ষা পরিষেবা দ্বারা পরিচালিত একটি প্রমিত মাল্টিপল চয়েস টেস্ট এবং কলেজগুলিকে ভর্তির সিদ্ধান্ত নিতে সাহায্য করতে ব্যবহৃত হয়; স্কোরগুলি 200 থেকে 800 এর মধ্যে পরিবর্তিত হতে পারে, যার গড় প্রায় 500 এবং স্ট্যান্ডার্ড বিচ্যুতি প্রায় 100৷ SAT পরীক্ষাগুলি পরীক্ষায় পারফরম্যান্সের উন্নতির দিকে বিশেষভাবে নির্দেশিত স্বল্পমেয়াদী প্রচেষ্টার প্রতিরোধী হওয়ার জন্য ডিজাইন করা হয়েছে; পরিবর্তে তারা অর্জিত জ্ঞান এবং শিক্ষার অনেক বছর ধরে বিকশিত ক্ষমতা প্রতিফলিত করার জন্য ডিজাইন করা হয়েছে। তবুও, এই সমীক্ষায় আটটি স্কুলের প্রত্যেকটি তার স্বল্প-মেয়াদী কোচিং প্রোগ্রামকে SAT স্কোর বৃদ্ধিতে অত্যন্ত সফল বলে মনে করেছে। এছাড়াও, আটটি প্রোগ্রামের মধ্যে যে কোনওটি অন্য কোনওটির চেয়ে বেশি কার্যকর ছিল বা কোনওটি অন্য কোনওটির চেয়ে একে অপরের সাথে আরও বেশি কার্যকর ছিল বলে বিশ্বাস করার কোনও পূর্ব কারণ ছিল না।
আট বিদ্যালয় (প্রত্যেকের জন্য\(J = 8\)), আমরা আনুমানিক চিকিত্সা প্রভাব আছে \(y_j\) এবং প্রভাব অনুমান একটি মান ত্রুটি \(\sigma_j\)। গবেষণায় চিকিত্সার প্রভাবগুলি নিয়ন্ত্রণ ভেরিয়েবল হিসাবে PSAT-M এবং PSAT-V স্কোর ব্যবহার করে চিকিত্সা গোষ্ঠীতে একটি রৈখিক রিগ্রেশন দ্বারা প্রাপ্ত হয়েছিল। হিসাবে সেখানে কোন পূর্বে বিশ্বাস ছিল যে স্কুলের কোন বেশী বা কম অনুরূপ বা যে কোচিং প্রোগ্রামের কোন কার্যকর হবে হত, তাহলে আমরা যেমন চিকিত্সা প্রভাব বিবেচনা করতে পারেন বিনিময়যোগ্য ।
num_schools = 8 # number of schools
treatment_effects = np.array(
[28, 8, -3, 7, -1, 1, 18, 12], dtype=np.float32) # treatment effects
treatment_stddevs = np.array(
[15, 10, 16, 11, 9, 11, 10, 18], dtype=np.float32) # treatment SE
fig, ax = plt.subplots()
plt.bar(range(num_schools), treatment_effects, yerr=treatment_stddevs)
plt.title("8 Schools treatment effects")
plt.xlabel("School")
plt.ylabel("Treatment effect")
fig.set_size_inches(10, 8)
plt.show()
মডেল
ডেটা ক্যাপচার করতে, আমরা একটি শ্রেণীবিন্যাস স্বাভাবিক মডেল ব্যবহার করি। এটি উৎপাদন প্রক্রিয়া অনুসরণ করে,
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i \sim \text{Normal}\left(\text{loc}{=}\mu,\ \text{scale}{=}\tau \right) \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
যেখানে \(\mu\) পূর্বে গড় চিকিত্সা প্রভাব এবং প্রতিনিধিত্ব করে \(\tau\) নিয়ন্ত্রণগুলি কত ভ্যারিয়েন্স সেখানে স্কুলের মধ্যে হয়। \(y_i\) এবং \(\sigma_i\) লক্ষ্য করা যায়। হিসাবে \(\tau \rightarrow \infty\), মডেল নো পুলিং মডেল, অর্থাত পন্থা, স্কুল চিকিত্সা প্রভাব অনুমান প্রতিটি আরো স্বাধীন হতে অনুমতি দেওয়া হয়। হিসাবে \(\tau \rightarrow 0\), মডেল সম্পূর্ণ-পুলিং মডেল, অর্থাত পন্থা, স্কুল চিকিত্সা প্রভাব গোষ্ঠীর সকল গড়ে পৌঁছাতে কাছাকাছি \(\mu\)। ইতিবাচক হতে স্ট্যানডার্ড ডেভিয়েশন সীমিত করার জন্য, আমরা আঁকা \(\tau\) একটি lognormal বন্টন (যা অঙ্কন সমতূল্য থেকে \(log(\tau)\) একটি সাধারণ বিন্যাসের থেকে)।
অনুসরণ করছেন প্রভেদ সঙ্গে নির্ণয়ের একচক্ষু ইনফিরেনস , আমরা একটি সমতুল্য অ কেন্দ্রিক মডেল উপরের মডেল রুপান্তর:
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i' \sim \text{Normal}\left(\text{loc}{=}0,\ \text{scale}{=}1 \right) \\ & \theta_i = \mu + \tau \theta_i' \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
আমরা এই মডেল হিসেবে বাস্তবে পরিণত করা JointDistributionSequential উদাহরণস্বরূপ:
model = tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=10., name="avg_effect"), # `mu` above
tfd.Normal(loc=5., scale=1., name="avg_stddev"), # `log(tau)` above
tfd.Independent(tfd.Normal(loc=tf.zeros(num_schools),
scale=tf.ones(num_schools),
name="school_effects_standard"), # `theta_prime`
reinterpreted_batch_ndims=1),
lambda school_effects_standard, avg_stddev, avg_effect: (
tfd.Independent(tfd.Normal(loc=(avg_effect[..., tf.newaxis] +
tf.exp(avg_stddev[..., tf.newaxis]) *
school_effects_standard), # `theta` above
scale=treatment_stddevs),
name="treatment_effects", # `y` above
reinterpreted_batch_ndims=1))
])
def target_log_prob_fn(avg_effect, avg_stddev, school_effects_standard):
"""Unnormalized target density as a function of states."""
return model.log_prob((
avg_effect, avg_stddev, school_effects_standard, treatment_effects))
বায়েসিয়ান ইনফারেন্স
প্রদত্ত ডেটা, আমরা মডেলের পরামিতিগুলির উপর পোস্টেরিয়র ডিস্ট্রিবিউশন গণনা করতে হ্যামিলটোনিয়ান মন্টে কার্লো (HMC) সম্পাদন করি।
num_results = 5000
num_burnin_steps = 3000
# Improve performance by tracing the sampler using `tf.function`
# and compiling it using XLA.
@tf.function(autograph=False, jit_compile=True)
def do_sampling():
return tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
tf.zeros([], name='init_avg_effect'),
tf.zeros([], name='init_avg_stddev'),
tf.ones([num_schools], name='init_school_effects_standard'),
],
kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.4,
num_leapfrog_steps=3))
states, kernel_results = do_sampling()
avg_effect, avg_stddev, school_effects_standard = states
school_effects_samples = (
avg_effect[:, np.newaxis] +
np.exp(avg_stddev)[:, np.newaxis] * school_effects_standard)
num_accepted = np.sum(kernel_results.is_accepted)
print('Acceptance rate: {}'.format(num_accepted / num_results))
Acceptance rate: 0.5974
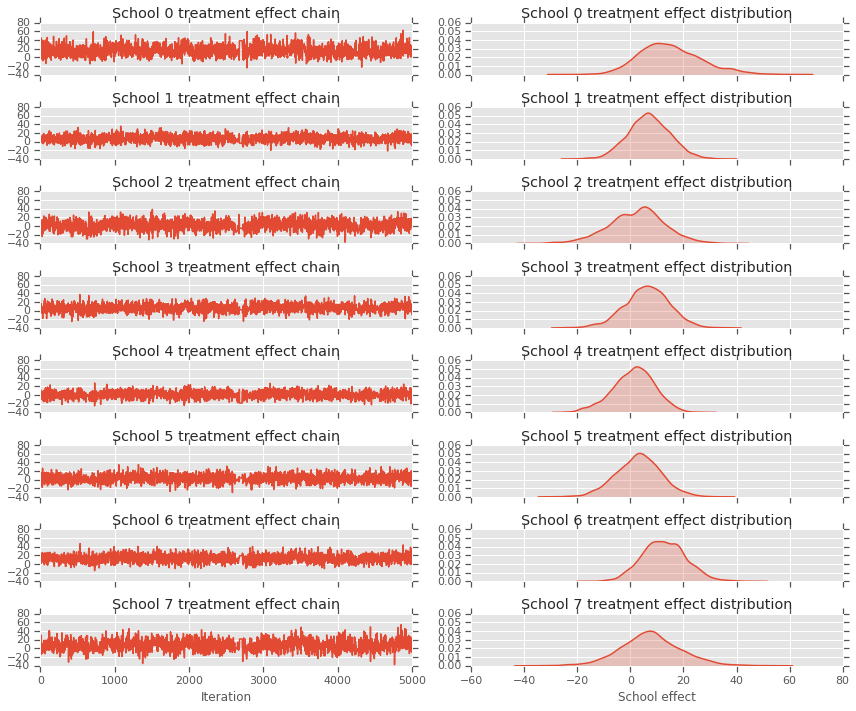
fig, axes = plt.subplots(8, 2, sharex='col', sharey='col')
fig.set_size_inches(12, 10)
for i in range(num_schools):
axes[i][0].plot(school_effects_samples[:,i].numpy())
axes[i][0].title.set_text("School {} treatment effect chain".format(i))
sns.kdeplot(school_effects_samples[:,i].numpy(), ax=axes[i][1], shade=True)
axes[i][1].title.set_text("School {} treatment effect distribution".format(i))
axes[num_schools - 1][0].set_xlabel("Iteration")
axes[num_schools - 1][1].set_xlabel("School effect")
fig.tight_layout()
plt.show()
print("E[avg_effect] = {}".format(np.mean(avg_effect)))
print("E[avg_stddev] = {}".format(np.mean(avg_stddev)))
print("E[school_effects_standard] =")
print(np.mean(school_effects_standard[:, ]))
print("E[school_effects] =")
print(np.mean(school_effects_samples[:, ], axis=0))
E[avg_effect] = 5.57183933258 E[avg_stddev] = 2.47738981247 E[school_effects_standard] = 0.08509017 E[school_effects] = [15.0051 7.103311 2.4552586 6.2744603 1.3364682 3.1125953 12.762501 7.743602 ]
# Compute the 95% interval for school_effects
school_effects_low = np.array([
np.percentile(school_effects_samples[:, i], 2.5) for i in range(num_schools)
])
school_effects_med = np.array([
np.percentile(school_effects_samples[:, i], 50) for i in range(num_schools)
])
school_effects_hi = np.array([
np.percentile(school_effects_samples[:, i], 97.5)
for i in range(num_schools)
])
fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True)
ax.scatter(np.array(range(num_schools)), school_effects_med, color='red', s=60)
ax.scatter(
np.array(range(num_schools)) + 0.1, treatment_effects, color='blue', s=60)
plt.plot([-0.2, 7.4], [np.mean(avg_effect),
np.mean(avg_effect)], 'k', linestyle='--')
ax.errorbar(
np.array(range(8)),
school_effects_med,
yerr=[
school_effects_med - school_effects_low,
school_effects_hi - school_effects_med
],
fmt='none')
ax.legend(('avg_effect', 'HMC', 'Observed effect'), fontsize=14)
plt.xlabel('School')
plt.ylabel('Treatment effect')
plt.title('HMC estimated school treatment effects vs. observed data')
fig.set_size_inches(10, 8)
plt.show()
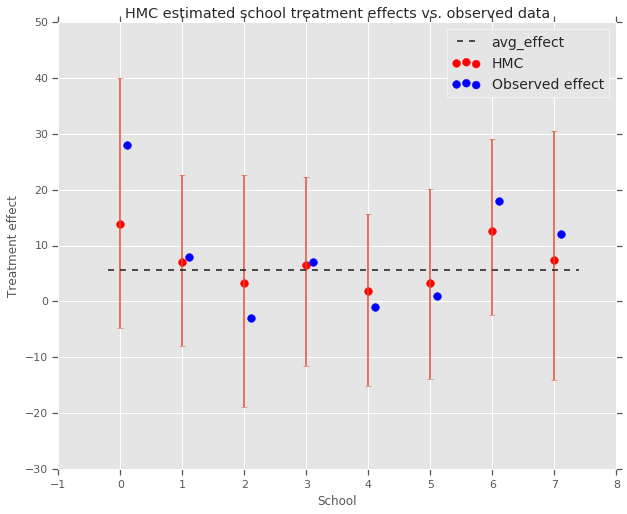
গোষ্ঠী দিকে সংকোচন মান্য করতে পারেন avg_effect উপরে।
print("Inferred posterior mean: {0:.2f}".format(
np.mean(school_effects_samples[:,])))
print("Inferred posterior mean se: {0:.2f}".format(
np.std(school_effects_samples[:,])))
Inferred posterior mean: 6.97 Inferred posterior mean se: 10.41
সমালোচনা
অবর ভবিষ্যদ্বাণীপূর্ণ বন্টন, অর্থাত, নতুন তথ্য মডেল পেতে \(y^*\) পর্যবেক্ষিত তথ্য দেওয়া \(y\):
\[ p(y^*|y) \propto \int_\theta p(y^* | \theta)p(\theta |y)d\theta\]
আমরা তাদের যে মডেল থেকে অবর বন্টন, এবং নমুনা গড় সেট করতে নতুন তথ্য জেনারেট করতে মডেল র্যান্ডম ভেরিয়েবলের মান ওভাররাইড \(y^*\)।
sample_shape = [5000]
_, _, _, predictive_treatment_effects = model.sample(
value=(tf.broadcast_to(np.mean(avg_effect, 0), sample_shape),
tf.broadcast_to(np.mean(avg_stddev, 0), sample_shape),
tf.broadcast_to(np.mean(school_effects_standard, 0),
sample_shape + [num_schools]),
None))
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(predictive_treatment_effects[:, 2*i].numpy(),
ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect posterior predictive".format(2*i))
sns.kdeplot(predictive_treatment_effects[:, 2*i + 1].numpy(),
ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect posterior predictive".format(2*i + 1))
plt.show()
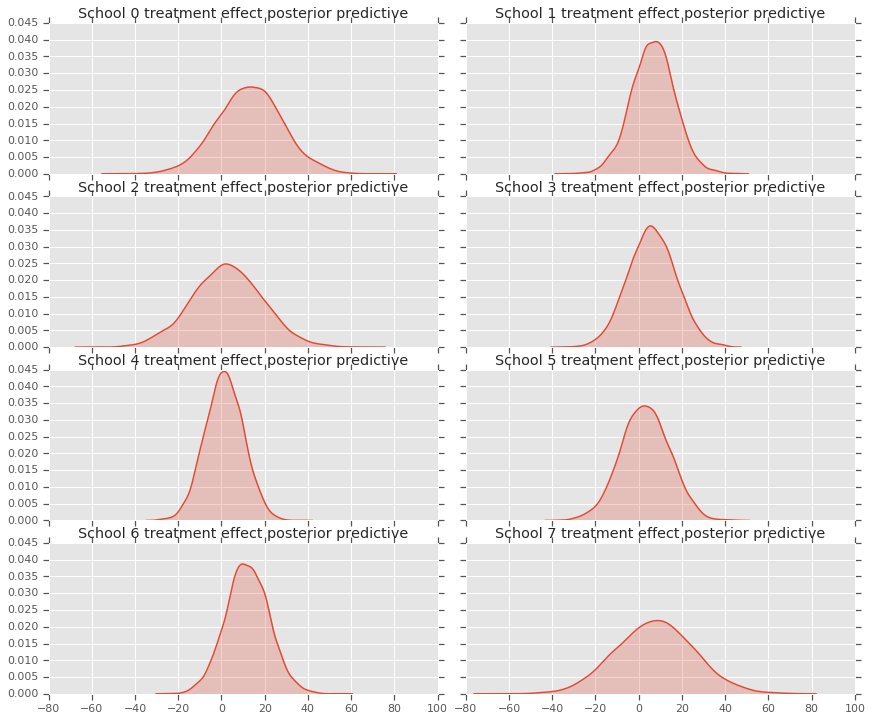
# The mean predicted treatment effects for each of the eight schools.
prediction = np.mean(predictive_treatment_effects, axis=0)
আমরা চিকিত্সা প্রভাব ডেটা এবং মডেল পোস্টেরিয়ার ভবিষ্যদ্বাণীগুলির মধ্যে অবশিষ্টাংশগুলি দেখতে পারি। এগুলি উপরের প্লটের সাথে মিলে যায় যা জনসংখ্যার গড় প্রতি আনুমানিক প্রভাবের সংকোচন দেখায়।
treatment_effects - prediction
array([14.905351 , 1.2838383, -5.6966295, 0.8327627, -2.3356671,
-2.0363257, 5.997898 , 4.3731265], dtype=float32)
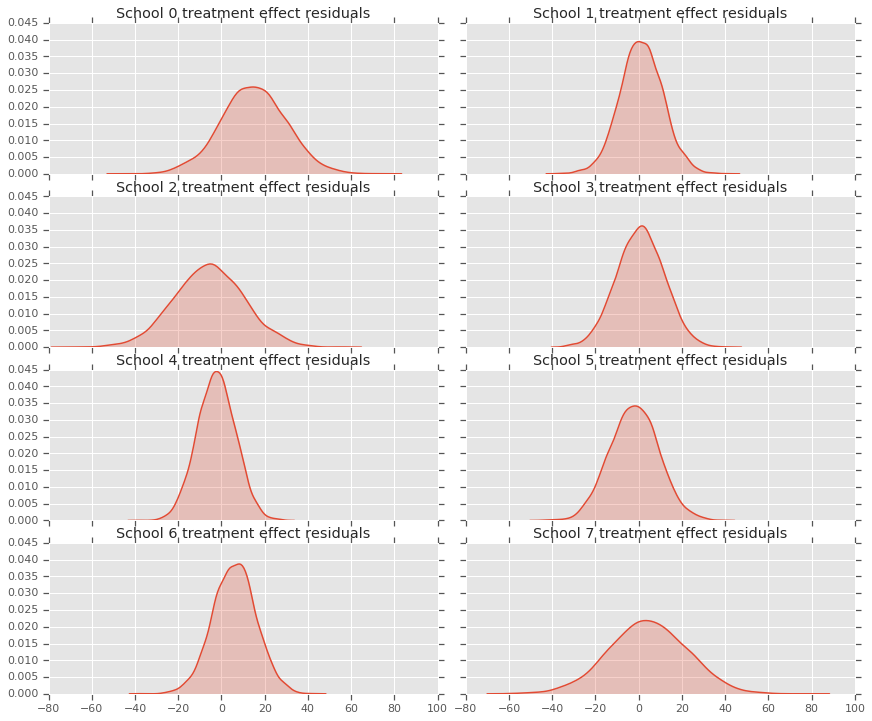
যেহেতু আমাদের প্রতিটি স্কুলের জন্য ভবিষ্যদ্বাণীর একটি বন্টন রয়েছে, তাই আমরা অবশিষ্টাংশের বিতরণও বিবেচনা করতে পারি।
residuals = treatment_effects - predictive_treatment_effects
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(residuals[:, 2*i].numpy(), ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect residuals".format(2*i))
sns.kdeplot(residuals[:, 2*i + 1].numpy(), ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect residuals".format(2*i + 1))
plt.show()
স্বীকৃতি
এই টিউটোরিয়ালটি মূলত এডওয়ার্ড 1.0 (লেখা ছিল উৎস )। আমরা সেই সংস্করণটি লেখা এবং সংশোধন করার জন্য সমস্ত অবদানকারীদের ধন্যবাদ জানাই।
তথ্যসূত্র
- ডোনাল্ড বি রুবিন। সমান্তরাল এলোমেলো পরীক্ষায় অনুমান। শিক্ষাগত পরিসংখ্যান জার্নাল, 6(4):377-401, 1981।
- অ্যান্ড্রু গেলম্যান, জন কার্লিন, হ্যাল স্টার্ন, ডেভিড ডানসন, আকি ভেহতারি এবং ডোনাল্ড রুবিন। Bayesian ডেটা বিশ্লেষণ, তৃতীয় সংস্করণ। চ্যাপম্যান এবং হল/সিআরসি, 2013।