
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
المشكلة ثماني مدارس ( روبن 1981 ) وتعتبر فعالية برامج التدريب SAT أجريت بالتوازي في ثماني مدارس. لقد أصبحت مشكلة كلاسيكية ( تحليل البيانات النظرية الافتراضية ، ستان ) الذي يوضح فائدة النمذجة الهرمي لتبادل المعلومات بين الجماعات صرف.
يسهم تطبيق أدناه هو التكيف لإدوارد 1.0 البرنامج التعليمي .
الواردات
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow.compat.v2 as tf
import tensorflow_probability as tfp
from tensorflow_probability import distributions as tfd
import warnings
tf.enable_v2_behavior()
plt.style.use("ggplot")
warnings.filterwarnings('ignore')
البيانات
من تحليل بيانات بايزي ، القسم 5.5 (جيلمان وآخرون 2013):
تم إجراء دراسة لخدمة الاختبارات التعليمية لتحليل آثار برامج التدريب الخاصة لـ SAT-V (اختبار الكفاءة الدراسية - اللفظي) في كل من المدارس الثانوية الثماني. كان متغير النتيجة في كل دراسة هو النتيجة في إدارة خاصة لـ SAT-V ، وهو اختبار معياري متعدد الخيارات تديره خدمة الاختبارات التعليمية ويستخدم لمساعدة الكليات على اتخاذ قرارات القبول ؛ يمكن أن تتراوح الدرجات بين 200 و 800 ، بمتوسط حوالي 500 والانحراف المعياري حوالي 100. تم تصميم اختبارات SAT لتكون مقاومة للجهود قصيرة الأجل الموجهة بشكل خاص نحو تحسين الأداء في الاختبار ؛ بدلاً من ذلك ، تم تصميمها لتعكس المعرفة المكتسبة والقدرات التي تم تطويرها على مدار سنوات عديدة من التعليم. ومع ذلك ، اعتبرت كل مدرسة من المدارس الثماني في هذه الدراسة أن برنامج التدريب قصير المدى الخاص بها ناجح جدًا في زيادة درجات SAT. أيضًا ، لم يكن هناك سبب مسبق للاعتقاد بأن أيًا من البرامج الثمانية كان أكثر فعالية من أي برامج أخرى أو أن بعضها كان أكثر تشابهًا في التأثير مع بعضها البعض من أي برامج أخرى.
لكل من ثماني مدارس (\(J = 8\))، لدينا ما يقدر تأثير العلاج \(y_j\) والخطأ المعياري للتقدير تأثير \(\sigma_j\). تم الحصول على تأثيرات العلاج في الدراسة من خلال الانحدار الخطي على مجموعة العلاج باستخدام درجات PSAT-M و PSAT-V كمتغيرات تحكم. كما كان هناك اعتقاد مسبق بأن أي من المدارس كانت أكثر أو أقل مماثلة أو أن أيا من برامج التدريب سيكون أكثر فعالية، يمكننا النظر في آثار العلاج كما صرف .
num_schools = 8 # number of schools
treatment_effects = np.array(
[28, 8, -3, 7, -1, 1, 18, 12], dtype=np.float32) # treatment effects
treatment_stddevs = np.array(
[15, 10, 16, 11, 9, 11, 10, 18], dtype=np.float32) # treatment SE
fig, ax = plt.subplots()
plt.bar(range(num_schools), treatment_effects, yerr=treatment_stddevs)
plt.title("8 Schools treatment effects")
plt.xlabel("School")
plt.ylabel("Treatment effect")
fig.set_size_inches(10, 8)
plt.show()
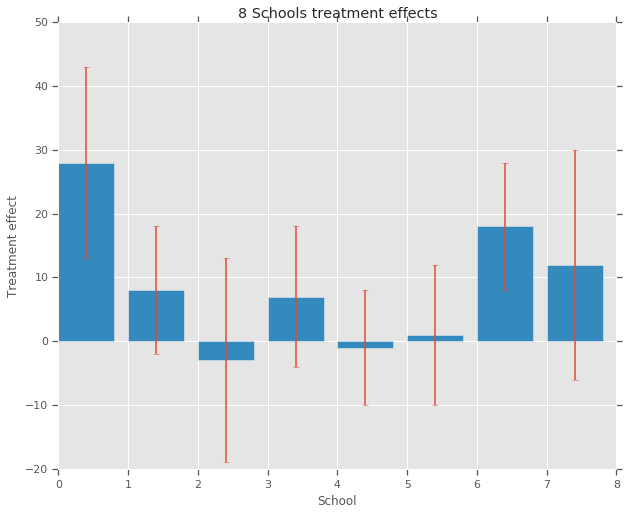
نموذج
لالتقاط البيانات ، نستخدم نموذجًا هرميًا عاديًا. يتبع العملية التوليدية ،
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i \sim \text{Normal}\left(\text{loc}{=}\mu,\ \text{scale}{=}\tau \right) \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
حيث \(\mu\) يمثل متوسط تأثير العلاج والسابقة \(\tau\) الضوابط مقدار التباين هناك بين المدارس. و \(y_i\) و \(\sigma_i\) لوحظ. كما \(\tau \rightarrow \infty\)، تقترب من نموذج أن لا يوجد نموذج تجميع، أي، يسمح كل من التقديرات تأثير العلاج المدرسة ليكون أكثر استقلالية. كما \(\tau \rightarrow 0\)، تقترب من نموذج نموذج كامل لتجميع، أي كل من آثار العلاج المدرسة هي أقرب إلى مجموعة المتوسط \(\mu\). للحد من الانحراف المعياري أن تكون إيجابية، نود أن نلفت \(\tau\) من توزيع اللوغاريتمي الطبيعي (وهو ما يعادل رسم \(log(\tau)\) من التوزيع الطبيعي).
وبعد تشخيص متحيزة الاستدلال مع الإنحرافات ، ونحن تحويل نموذج أعلاه في نموذج محورها غير يعادل:
\[ \begin{align*} \mu &\sim \text{Normal}(\text{loc}{=}0,\ \text{scale}{=}10) \\ \log\tau &\sim \text{Normal}(\text{loc}{=}5,\ \text{scale}{=}1) \\ \text{for } & i=1\ldots 8:\\ & \theta_i' \sim \text{Normal}\left(\text{loc}{=}0,\ \text{scale}{=}1 \right) \\ & \theta_i = \mu + \tau \theta_i' \\ & y_i \sim \text{Normal}\left(\text{loc}{=}\theta_i,\ \text{scale}{=}\sigma_i \right) \end{align*} \]
نحن جسد هذا النموذج باعتباره JointDistributionSequential سبيل المثال:
model = tfd.JointDistributionSequential([
tfd.Normal(loc=0., scale=10., name="avg_effect"), # `mu` above
tfd.Normal(loc=5., scale=1., name="avg_stddev"), # `log(tau)` above
tfd.Independent(tfd.Normal(loc=tf.zeros(num_schools),
scale=tf.ones(num_schools),
name="school_effects_standard"), # `theta_prime`
reinterpreted_batch_ndims=1),
lambda school_effects_standard, avg_stddev, avg_effect: (
tfd.Independent(tfd.Normal(loc=(avg_effect[..., tf.newaxis] +
tf.exp(avg_stddev[..., tf.newaxis]) *
school_effects_standard), # `theta` above
scale=treatment_stddevs),
name="treatment_effects", # `y` above
reinterpreted_batch_ndims=1))
])
def target_log_prob_fn(avg_effect, avg_stddev, school_effects_standard):
"""Unnormalized target density as a function of states."""
return model.log_prob((
avg_effect, avg_stddev, school_effects_standard, treatment_effects))
الاستدلال بايزي
بالنظر إلى البيانات ، نقوم بإجراء Hamiltonian Monte Carlo (HMC) لحساب التوزيع اللاحق على معلمات النموذج.
num_results = 5000
num_burnin_steps = 3000
# Improve performance by tracing the sampler using `tf.function`
# and compiling it using XLA.
@tf.function(autograph=False, jit_compile=True)
def do_sampling():
return tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
tf.zeros([], name='init_avg_effect'),
tf.zeros([], name='init_avg_stddev'),
tf.ones([num_schools], name='init_school_effects_standard'),
],
kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.4,
num_leapfrog_steps=3))
states, kernel_results = do_sampling()
avg_effect, avg_stddev, school_effects_standard = states
school_effects_samples = (
avg_effect[:, np.newaxis] +
np.exp(avg_stddev)[:, np.newaxis] * school_effects_standard)
num_accepted = np.sum(kernel_results.is_accepted)
print('Acceptance rate: {}'.format(num_accepted / num_results))
Acceptance rate: 0.5974
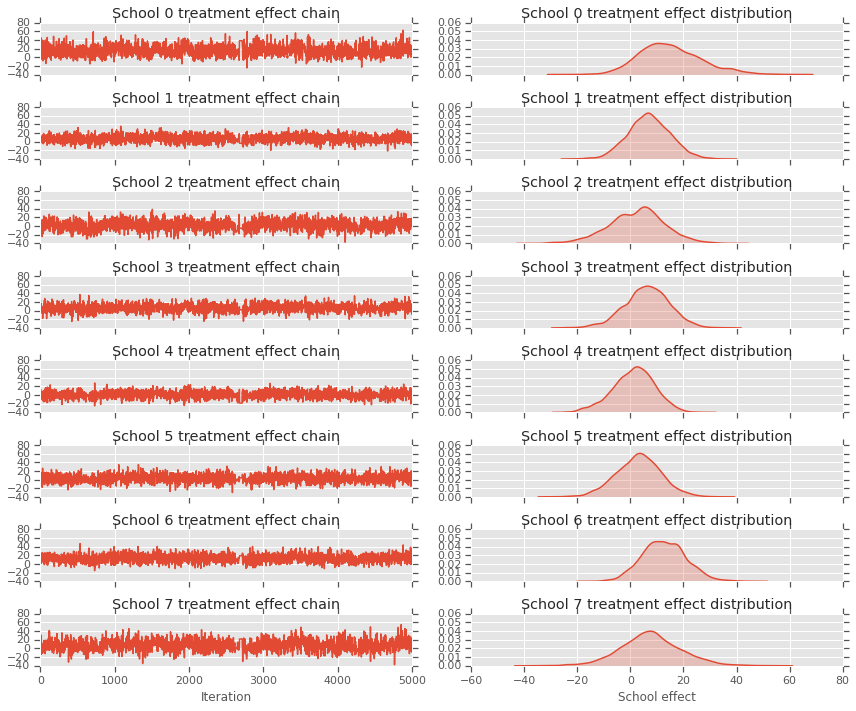
fig, axes = plt.subplots(8, 2, sharex='col', sharey='col')
fig.set_size_inches(12, 10)
for i in range(num_schools):
axes[i][0].plot(school_effects_samples[:,i].numpy())
axes[i][0].title.set_text("School {} treatment effect chain".format(i))
sns.kdeplot(school_effects_samples[:,i].numpy(), ax=axes[i][1], shade=True)
axes[i][1].title.set_text("School {} treatment effect distribution".format(i))
axes[num_schools - 1][0].set_xlabel("Iteration")
axes[num_schools - 1][1].set_xlabel("School effect")
fig.tight_layout()
plt.show()
print("E[avg_effect] = {}".format(np.mean(avg_effect)))
print("E[avg_stddev] = {}".format(np.mean(avg_stddev)))
print("E[school_effects_standard] =")
print(np.mean(school_effects_standard[:, ]))
print("E[school_effects] =")
print(np.mean(school_effects_samples[:, ], axis=0))
E[avg_effect] = 5.57183933258 E[avg_stddev] = 2.47738981247 E[school_effects_standard] = 0.08509017 E[school_effects] = [15.0051 7.103311 2.4552586 6.2744603 1.3364682 3.1125953 12.762501 7.743602 ]
# Compute the 95% interval for school_effects
school_effects_low = np.array([
np.percentile(school_effects_samples[:, i], 2.5) for i in range(num_schools)
])
school_effects_med = np.array([
np.percentile(school_effects_samples[:, i], 50) for i in range(num_schools)
])
school_effects_hi = np.array([
np.percentile(school_effects_samples[:, i], 97.5)
for i in range(num_schools)
])
fig, ax = plt.subplots(nrows=1, ncols=1, sharex=True)
ax.scatter(np.array(range(num_schools)), school_effects_med, color='red', s=60)
ax.scatter(
np.array(range(num_schools)) + 0.1, treatment_effects, color='blue', s=60)
plt.plot([-0.2, 7.4], [np.mean(avg_effect),
np.mean(avg_effect)], 'k', linestyle='--')
ax.errorbar(
np.array(range(8)),
school_effects_med,
yerr=[
school_effects_med - school_effects_low,
school_effects_hi - school_effects_med
],
fmt='none')
ax.legend(('avg_effect', 'HMC', 'Observed effect'), fontsize=14)
plt.xlabel('School')
plt.ylabel('Treatment effect')
plt.title('HMC estimated school treatment effects vs. observed data')
fig.set_size_inches(10, 8)
plt.show()
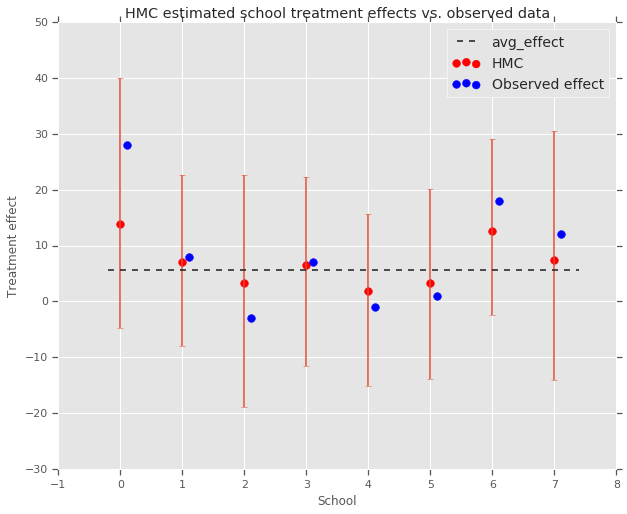
يمكننا أن نلاحظ انكماش تجاه مجموعة avg_effect أعلاه.
print("Inferred posterior mean: {0:.2f}".format(
np.mean(school_effects_samples[:,])))
print("Inferred posterior mean se: {0:.2f}".format(
np.std(school_effects_samples[:,])))
Inferred posterior mean: 6.97 Inferred posterior mean se: 10.41
نقد
للحصول على توزيع التنبؤي الخلفي، أي نموذج بيانات جديد \(y^*\) نظرا لاحظ البيانات \(y\):
\[ p(y^*|y) \propto \int_\theta p(y^* | \theta)p(\theta |y)d\theta\]
نحن تجاوز قيم المتغيرات العشوائية في نموذج لمجموعة منهم إلى الوسط للتوزيع الخلفي، وعينة من هذا النموذج لتوليد جديدة بيانات \(y^*\).
sample_shape = [5000]
_, _, _, predictive_treatment_effects = model.sample(
value=(tf.broadcast_to(np.mean(avg_effect, 0), sample_shape),
tf.broadcast_to(np.mean(avg_stddev, 0), sample_shape),
tf.broadcast_to(np.mean(school_effects_standard, 0),
sample_shape + [num_schools]),
None))
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(predictive_treatment_effects[:, 2*i].numpy(),
ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect posterior predictive".format(2*i))
sns.kdeplot(predictive_treatment_effects[:, 2*i + 1].numpy(),
ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect posterior predictive".format(2*i + 1))
plt.show()
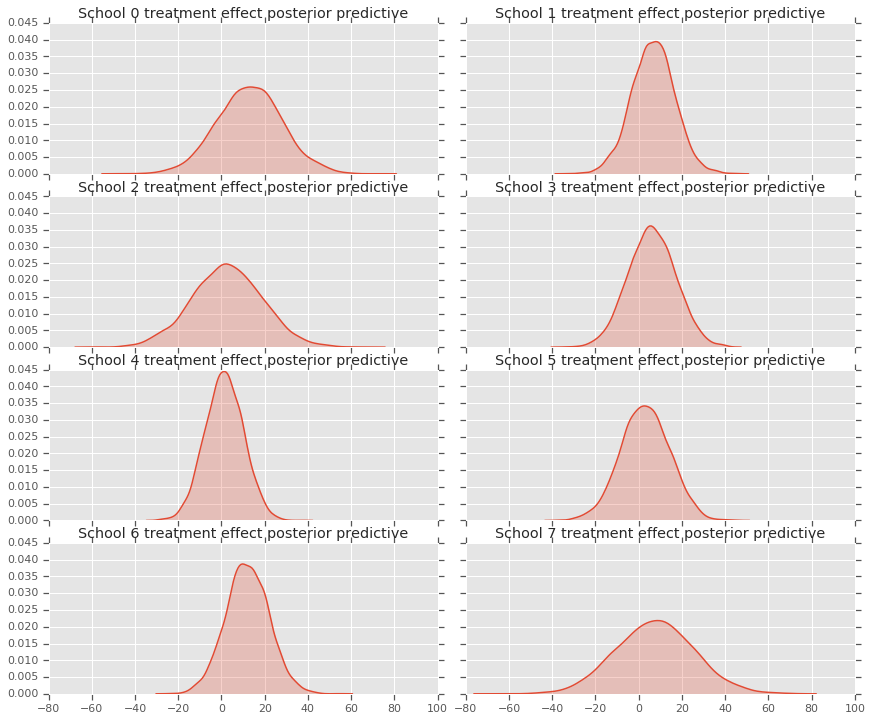
# The mean predicted treatment effects for each of the eight schools.
prediction = np.mean(predictive_treatment_effects, axis=0)
يمكننا أن ننظر إلى المتبقي بين بيانات آثار العلاج وتنبؤات النموذج الخلفي. تتوافق هذه مع المخطط أعلاه الذي يوضح تقلص التأثيرات المقدرة تجاه متوسط السكان.
treatment_effects - prediction
array([14.905351 , 1.2838383, -5.6966295, 0.8327627, -2.3356671,
-2.0363257, 5.997898 , 4.3731265], dtype=float32)
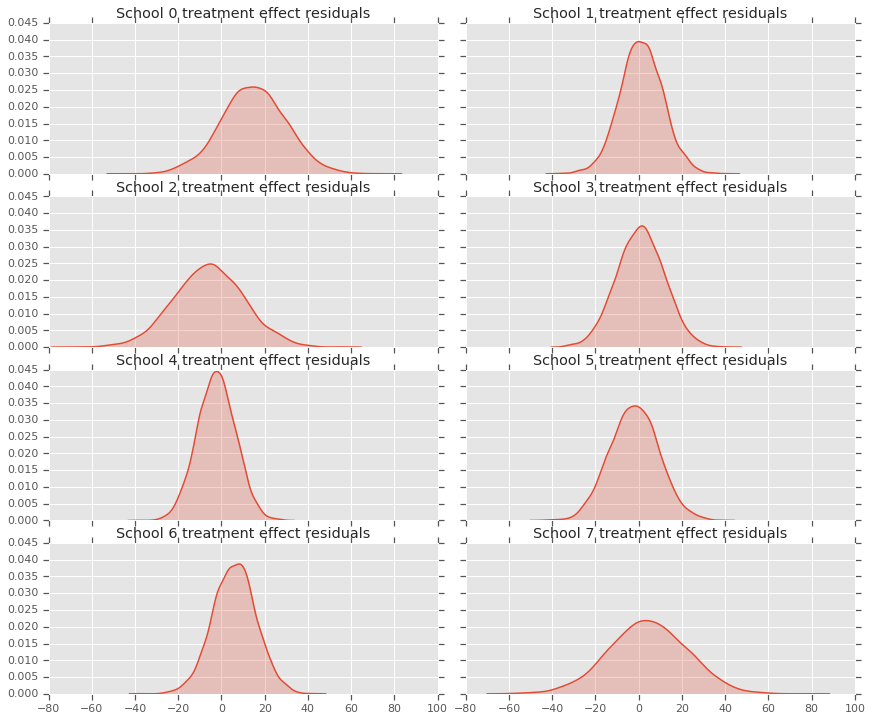
نظرًا لأن لدينا توزيعًا للتنبؤات لكل مدرسة ، يمكننا أيضًا النظر في توزيع المخلفات.
residuals = treatment_effects - predictive_treatment_effects
fig, axes = plt.subplots(4, 2, sharex=True, sharey=True)
fig.set_size_inches(12, 10)
fig.tight_layout()
for i, ax in enumerate(axes):
sns.kdeplot(residuals[:, 2*i].numpy(), ax=ax[0], shade=True)
ax[0].title.set_text(
"School {} treatment effect residuals".format(2*i))
sns.kdeplot(residuals[:, 2*i + 1].numpy(), ax=ax[1], shade=True)
ax[1].title.set_text(
"School {} treatment effect residuals".format(2*i + 1))
plt.show()
شكر وتقدير
وقد كتب هذا البرنامج التعليمي أصلا في إدوارد 1.0 ( مصدر ). نشكر جميع المساهمين في كتابة ومراجعة هذا الإصدار.
مراجع
- دونالد ب.روبين. التقدير في التجارب العشوائية المتوازية. مجلة الإحصاء التربوي ، 6 (4): 377-401 ، 1981.
- أندرو جيلمان وجون كارلين وهال ستيرن وديفيد دونسون وآكي فيهاري ودونالد روبين. تحليل البيانات بايزي ، الطبعة الثالثة. تشابمان وهال / CRC ، 2013.