| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Questo notebook reimplementa ed estende il bayesiana “Change analisi punto” esempio dalla documentazione pymc3 .
Prerequisiti
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (15,8)
%config InlineBackend.figure_format = 'retina'
import numpy as np
import pandas as pd
set di dati
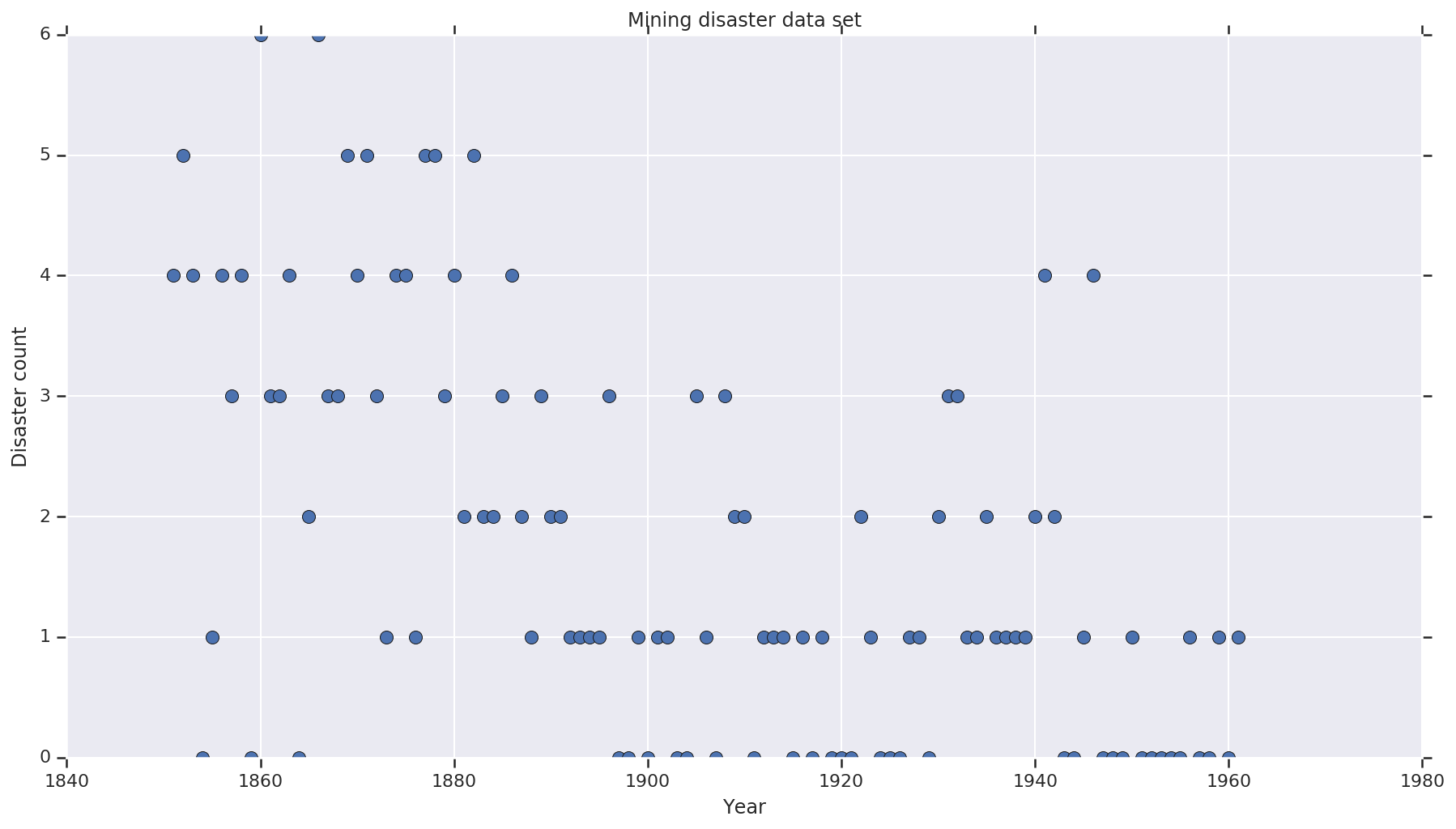
Il set di dati è da qui . Nota, c'è un'altra versione di questo esempio galleggia intorno , ma è “mancante” i dati - in questo caso avresti bisogno di imputare i valori mancanti. (Altrimenti il tuo modello non lascerà mai i suoi parametri iniziali perché la funzione di verosimiglianza non sarà definita.)
disaster_data = np.array([ 4, 5, 4, 0, 1, 4, 3, 4, 0, 6, 3, 3, 4, 0, 2, 6,
3, 3, 5, 4, 5, 3, 1, 4, 4, 1, 5, 5, 3, 4, 2, 5,
2, 2, 3, 4, 2, 1, 3, 2, 2, 1, 1, 1, 1, 3, 0, 0,
1, 0, 1, 1, 0, 0, 3, 1, 0, 3, 2, 2, 0, 1, 1, 1,
0, 1, 0, 1, 0, 0, 0, 2, 1, 0, 0, 0, 1, 1, 0, 2,
3, 3, 1, 1, 2, 1, 1, 1, 1, 2, 4, 2, 0, 0, 1, 4,
0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1])
years = np.arange(1851, 1962)
plt.plot(years, disaster_data, 'o', markersize=8);
plt.ylabel('Disaster count')
plt.xlabel('Year')
plt.title('Mining disaster data set')
plt.show()
Modello probabilistico
Il modello presuppone un "punto di commutazione" (ad esempio un anno durante il quale le norme di sicurezza sono cambiate) e il tasso di disastro distribuito da Poisson con tassi costanti (ma potenzialmente diversi) prima e dopo tale punto di commutazione.
Il conteggio effettivo dei disastri è fisso (osservato); qualsiasi campione di questo modello dovrà specificare sia il punto di commutazione che il tasso di catastrofi "precoce" e "tardivo".
Modello originale da esempio documentazione pymc3 :
\[ \begin{align*} (D_t|s,e,l)&\sim \text{Poisson}(r_t), \\ & \,\quad\text{with}\; r_t = \begin{cases}e & \text{if}\; t < s\\l &\text{if}\; t \ge s\end{cases} \\ s&\sim\text{Discrete Uniform}(t_l,\,t_h) \\ e&\sim\text{Exponential}(r_e)\\ l&\sim\text{Exponential}(r_l) \end{align*} \]
Tuttavia, la media tasso di disastro \(r_t\) ha una discontinuità alla commutazione \(s\), che lo rende non differenziabile. Così fornisce alcun segnale di gradiente al (HMC) algoritmo di Hamilton Monte Carlo - ma perché la \(s\) prima è continuo, fallback di HMC per una passeggiata casuale è abbastanza buono per trovare le zone di alta massa di probabilità in questo esempio.
Come un secondo modello, modifichiamo il modello originale con un “switch” sigma tra E ed L per rendere la transizione differenziabile, e utilizzare una distribuzione uniforme continuo per la commutazione \(s\). (Si potrebbe obiettare che questo modello è più fedele alla realtà, poiché un "passaggio" del tasso medio probabilmente si estenderebbe su più anni.) Il nuovo modello è quindi:
\[ \begin{align*} (D_t|s,e,l)&\sim\text{Poisson}(r_t), \\ & \,\quad \text{with}\; r_t = e + \frac{1}{1+\exp(s-t)}(l-e) \\ s&\sim\text{Uniform}(t_l,\,t_h) \\ e&\sim\text{Exponential}(r_e)\\ l&\sim\text{Exponential}(r_l) \end{align*} \]
In assenza di ulteriori informazioni assumiamo \(r_e = r_l = 1\) come parametri per i priori. Eseguiremo entrambi i modelli e confronteremo i risultati dell'inferenza.
def disaster_count_model(disaster_rate_fn):
disaster_count = tfd.JointDistributionNamed(dict(
e=tfd.Exponential(rate=1.),
l=tfd.Exponential(rate=1.),
s=tfd.Uniform(0., high=len(years)),
d_t=lambda s, l, e: tfd.Independent(
tfd.Poisson(rate=disaster_rate_fn(np.arange(len(years)), s, l, e)),
reinterpreted_batch_ndims=1)
))
return disaster_count
def disaster_rate_switch(ys, s, l, e):
return tf.where(ys < s, e, l)
def disaster_rate_sigmoid(ys, s, l, e):
return e + tf.sigmoid(ys - s) * (l - e)
model_switch = disaster_count_model(disaster_rate_switch)
model_sigmoid = disaster_count_model(disaster_rate_sigmoid)
Il codice sopra definisce il modello tramite le distribuzioni JointDistributionSequential. Le disaster_rate funzioni sono chiamate con un array di [0, ..., len(years)-1] per produrre un vettore di len(years) variabili aleatorie - anni prima della switchpoint sono early_disaster_rate , quelli dopo late_disaster_rate (modulo la transizione sigmoidea).
Ecco un controllo di integrità che la funzione di verifica del registro di destinazione è sana:
def target_log_prob_fn(model, s, e, l):
return model.log_prob(s=s, e=e, l=l, d_t=disaster_data)
models = [model_switch, model_sigmoid]
print([target_log_prob_fn(m, 40., 3., .9).numpy() for m in models]) # Somewhat likely result
print([target_log_prob_fn(m, 60., 1., 5.).numpy() for m in models]) # Rather unlikely result
print([target_log_prob_fn(m, -10., 1., 1.).numpy() for m in models]) # Impossible result
[-176.94559, -176.28717] [-371.3125, -366.8816] [-inf, -inf]
HMC per fare l'inferenza bayesiana
Definiamo il numero di risultati e i passaggi di burn-in richiesti; il codice è in gran parte modellato la documentazione di tfp.mcmc.HamiltonianMonteCarlo . Utilizza una dimensione del passo adattiva (altrimenti il risultato è molto sensibile al valore della dimensione del passo scelto). Usiamo i valori di uno come stato iniziale della catena.
Questa non è la storia completa però. Se torni alla definizione del modello sopra, noterai che alcune delle distribuzioni di probabilità non sono ben definite sull'intera linea dei numeri reali. Perciò abbiamo vincolare la spazio che HMC esamina avvolgendo il kernel HMC con un TransformedTransitionKernel che specifica il bijectors avanti per trasformare i numeri reali sul dominio che la distribuzione di probabilità è definita (vedere commenti nel codice qui sotto).
num_results = 10000
num_burnin_steps = 3000
@tf.function(autograph=False, jit_compile=True)
def make_chain(target_log_prob_fn):
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.05,
num_leapfrog_steps=3),
bijector=[
# The switchpoint is constrained between zero and len(years).
# Hence we supply a bijector that maps the real numbers (in a
# differentiable way) to the interval (0;len(yers))
tfb.Sigmoid(low=0., high=tf.cast(len(years), dtype=tf.float32)),
# Early and late disaster rate: The exponential distribution is
# defined on the positive real numbers
tfb.Softplus(),
tfb.Softplus(),
])
kernel = tfp.mcmc.SimpleStepSizeAdaptation(
inner_kernel=kernel,
num_adaptation_steps=int(0.8*num_burnin_steps))
states = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
# The three latent variables
tf.ones([], name='init_switchpoint'),
tf.ones([], name='init_early_disaster_rate'),
tf.ones([], name='init_late_disaster_rate'),
],
trace_fn=None,
kernel=kernel)
return states
switch_samples = [s.numpy() for s in make_chain(
lambda *args: target_log_prob_fn(model_switch, *args))]
sigmoid_samples = [s.numpy() for s in make_chain(
lambda *args: target_log_prob_fn(model_sigmoid, *args))]
switchpoint, early_disaster_rate, late_disaster_rate = zip(
switch_samples, sigmoid_samples)
Esegui entrambi i modelli in parallelo:
Visualizza il risultato
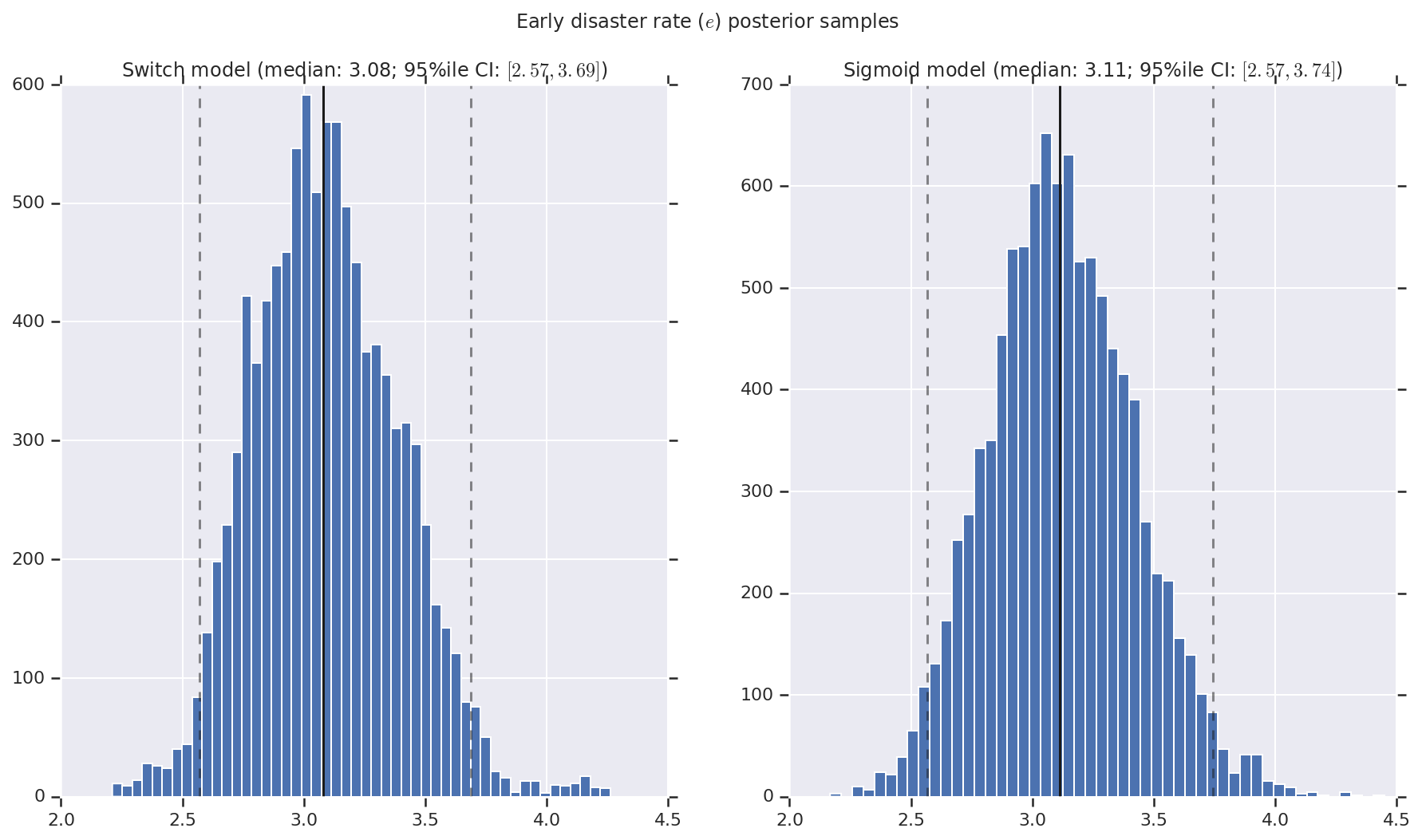
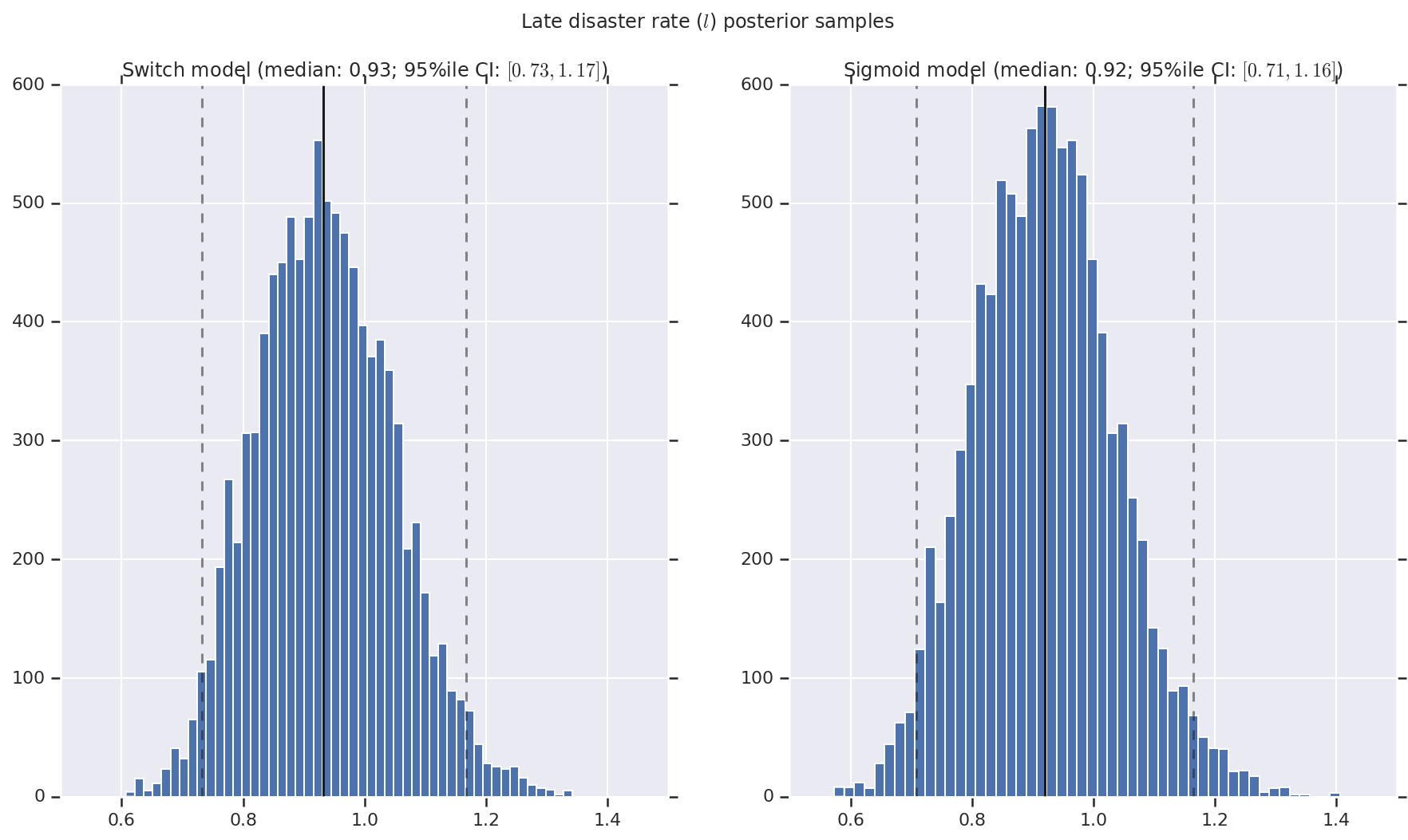
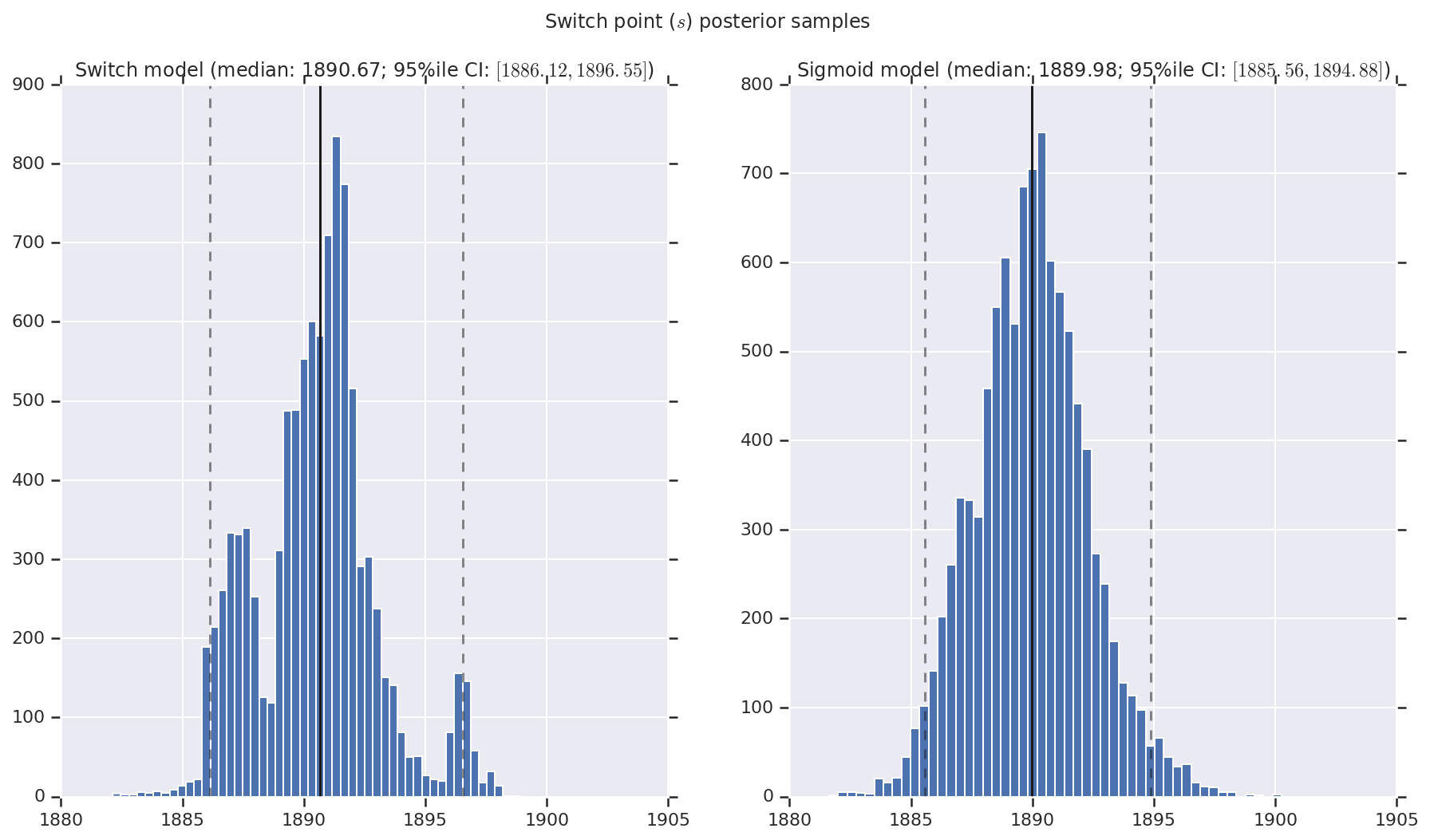
Visualizziamo il risultato come istogrammi di campioni della distribuzione a posteriori per il tasso di disastro precoce e tardivo, nonché il punto di commutazione. Gli istogrammi sono sovrapposti con una linea continua che rappresenta la mediana del campione, nonché i limiti dell'intervallo credibile al 95% come linee tratteggiate.
def _desc(v):
return '(median: {}; 95%ile CI: $[{}, {}]$)'.format(
*np.round(np.percentile(v, [50, 2.5, 97.5]), 2))
for t, v in [
('Early disaster rate ($e$) posterior samples', early_disaster_rate),
('Late disaster rate ($l$) posterior samples', late_disaster_rate),
('Switch point ($s$) posterior samples', years[0] + switchpoint),
]:
fig, ax = plt.subplots(nrows=1, ncols=2, sharex=True)
for (m, i) in (('Switch', 0), ('Sigmoid', 1)):
a = ax[i]
a.hist(v[i], bins=50)
a.axvline(x=np.percentile(v[i], 50), color='k')
a.axvline(x=np.percentile(v[i], 2.5), color='k', ls='dashed', alpha=.5)
a.axvline(x=np.percentile(v[i], 97.5), color='k', ls='dashed', alpha=.5)
a.set_title(m + ' model ' + _desc(v[i]))
fig.suptitle(t)
plt.show()