| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
Reimplements מחברת זו ומרחיב את "ניתוח נקודת שינוי" בייס דוגמה מן התיעוד pymc3 .
דרישות מוקדמות
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (15,8)
%config InlineBackend.figure_format = 'retina'
import numpy as np
import pandas as pd
מערך נתונים
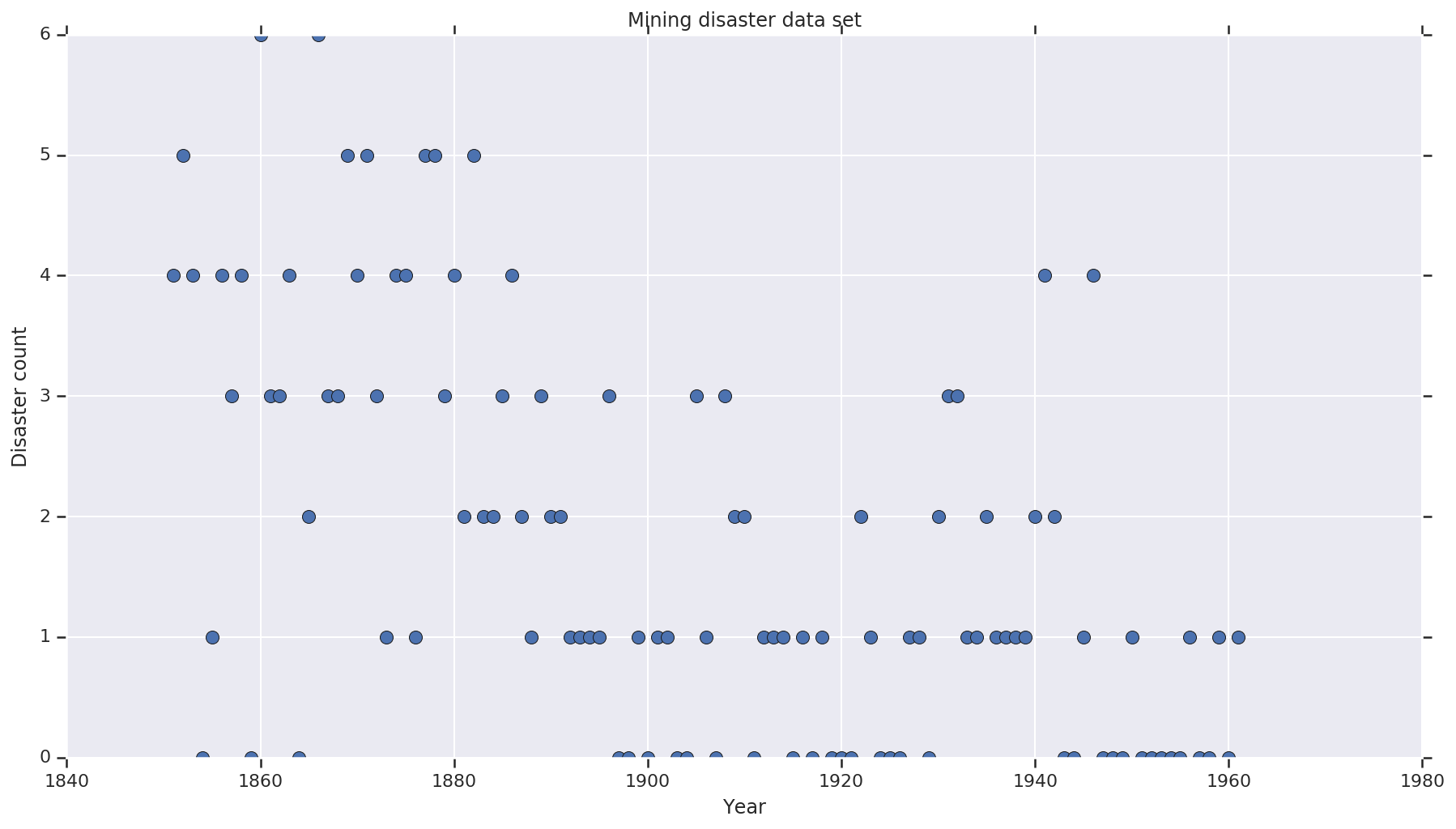
בסיס הנתונים הוא מ- כאן . הערה, יש גרסה אחרת של בדוגמה זו מרחפת , אך הוא "חסר" הנתונים - ובמקרה היית צריך לזקוף ערכים חסרים. (אחרת המודל שלך לעולם לא יעזוב את הפרמטרים הראשוניים שלו מכיוון שפונקציית הסבירות לא תהיה מוגדרת).
disaster_data = np.array([ 4, 5, 4, 0, 1, 4, 3, 4, 0, 6, 3, 3, 4, 0, 2, 6,
3, 3, 5, 4, 5, 3, 1, 4, 4, 1, 5, 5, 3, 4, 2, 5,
2, 2, 3, 4, 2, 1, 3, 2, 2, 1, 1, 1, 1, 3, 0, 0,
1, 0, 1, 1, 0, 0, 3, 1, 0, 3, 2, 2, 0, 1, 1, 1,
0, 1, 0, 1, 0, 0, 0, 2, 1, 0, 0, 0, 1, 1, 0, 2,
3, 3, 1, 1, 2, 1, 1, 1, 1, 2, 4, 2, 0, 0, 1, 4,
0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1])
years = np.arange(1851, 1962)
plt.plot(years, disaster_data, 'o', markersize=8);
plt.ylabel('Disaster count')
plt.xlabel('Year')
plt.title('Mining disaster data set')
plt.show()
מודל הסתברותי
המודל מניח "נקודת מיתוג" (למשל שנה שבה השתנו תקנות הבטיחות), וקצב אסונות בהפצת Poisson עם שיעורים קבועים (אך פוטנציאליים שונים) לפני ואחרי אותה נקודת מיתוג.
ספירת האסונות בפועל קבועה (נצפה); כל מדגם של מודל זה יצטרך לציין גם את נקודת המעבר וגם את שיעור האסונות ה"מוקדם" וה"מאוחר".
מודל מקורי מן הדוגמה תיעוד pymc3 :
\[ \begin{align*} (D_t|s,e,l)&\sim \text{Poisson}(r_t), \\ & \,\quad\text{with}\; r_t = \begin{cases}e & \text{if}\; t < s\\l &\text{if}\; t \ge s\end{cases} \\ s&\sim\text{Discrete Uniform}(t_l,\,t_h) \\ e&\sim\text{Exponential}(r_e)\\ l&\sim\text{Exponential}(r_l) \end{align*} \]
עם זאת, שיעור אסון ממוצע \(r_t\) יש רציפות על switchpoint \(s\), מה שהופך אותו לא גזירה. בכך הוא מוסיף שום אות שיפוע לאלגוריתם והמילטון מונטה קרלו (HMC) - אלא משום \(s\) קודמים הוא רציף, השחזור של HMC כדי הליכה אקראית הוא מספיק טוב כדי למצוא את תחום המוניים סבירות גבוהה בדוגמא זו.
כתוצאה המודל השני, אנו משנים את המודל המקורי באמצעות "מתג" סיגמואיד בין E ו- l לבצע את המעבר גזיר, ולהשתמש התפלגות אחידה רציפה עבור switchpoint \(s\). (אפשר לטעון שהמודל הזה נכון יותר למציאות, מכיוון ש"מתג" בשיעור הממוצע יימתח על פני שנים רבות.) המודל החדש הוא כך:
\[ \begin{align*} (D_t|s,e,l)&\sim\text{Poisson}(r_t), \\ & \,\quad \text{with}\; r_t = e + \frac{1}{1+\exp(s-t)}(l-e) \\ s&\sim\text{Uniform}(t_l,\,t_h) \\ e&\sim\text{Exponential}(r_e)\\ l&\sim\text{Exponential}(r_l) \end{align*} \]
בהעדר מידע נוסף נניח \(r_e = r_l = 1\) כפרמטרים עבור ההרשעות הקודמות. נריץ את שני המודלים ונשווה את תוצאות ההסקה שלהם.
def disaster_count_model(disaster_rate_fn):
disaster_count = tfd.JointDistributionNamed(dict(
e=tfd.Exponential(rate=1.),
l=tfd.Exponential(rate=1.),
s=tfd.Uniform(0., high=len(years)),
d_t=lambda s, l, e: tfd.Independent(
tfd.Poisson(rate=disaster_rate_fn(np.arange(len(years)), s, l, e)),
reinterpreted_batch_ndims=1)
))
return disaster_count
def disaster_rate_switch(ys, s, l, e):
return tf.where(ys < s, e, l)
def disaster_rate_sigmoid(ys, s, l, e):
return e + tf.sigmoid(ys - s) * (l - e)
model_switch = disaster_count_model(disaster_rate_switch)
model_sigmoid = disaster_count_model(disaster_rate_sigmoid)
הקוד לעיל מגדיר את המודל באמצעות JointDistributionSequential הפצות. disaster_rate הפונקציות נקראות עם מערך של [0, ..., len(years)-1] לייצר וקטור של len(years) משתנה אקראי - השנים שלפני switchpoint הן early_disaster_rate , אלה לאחר late_disaster_rate (מודולו מעבר סיגמואיד).
הנה בדיקת שפיות שפונקציית הבדיקה של יומן המטרה שפויה:
def target_log_prob_fn(model, s, e, l):
return model.log_prob(s=s, e=e, l=l, d_t=disaster_data)
models = [model_switch, model_sigmoid]
print([target_log_prob_fn(m, 40., 3., .9).numpy() for m in models]) # Somewhat likely result
print([target_log_prob_fn(m, 60., 1., 5.).numpy() for m in models]) # Rather unlikely result
print([target_log_prob_fn(m, -10., 1., 1.).numpy() for m in models]) # Impossible result
[-176.94559, -176.28717] [-371.3125, -366.8816] [-inf, -inf]
HMC לעשות מסקנות בייסיאניות
אנו מגדירים את מספר התוצאות ושלבי הצריבה הנדרשים; הקוד הוא מודל בעיקר לאחר בתיעוד של tfp.mcmc.HamiltonianMonteCarlo . הוא משתמש בגודל צעד אדפטיבי (אחרת התוצאה רגישה מאוד לערך גודל הצעד שנבחר). אנו משתמשים בערכים של אחד כמצב ההתחלתי של השרשרת.
אבל זה לא הסיפור המלא. אם תחזור להגדרת המודל שלמעלה, תשים לב שחלק מההתפלגות ההסתברות אינן מוגדרות היטב על כל קו המספרים הממשיים. לכן אנו להגביל את המרחב HMC יבחן על ידי עטיפת הקרנל HMC עם TransformedTransitionKernel המציין את bijectors קדימה כדי להפוך את המספרים האמיתיים על התחום כי התפלגות ההסתברות מוגדרת על (ראה הערות בקוד להלן).
num_results = 10000
num_burnin_steps = 3000
@tf.function(autograph=False, jit_compile=True)
def make_chain(target_log_prob_fn):
kernel = tfp.mcmc.TransformedTransitionKernel(
inner_kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=target_log_prob_fn,
step_size=0.05,
num_leapfrog_steps=3),
bijector=[
# The switchpoint is constrained between zero and len(years).
# Hence we supply a bijector that maps the real numbers (in a
# differentiable way) to the interval (0;len(yers))
tfb.Sigmoid(low=0., high=tf.cast(len(years), dtype=tf.float32)),
# Early and late disaster rate: The exponential distribution is
# defined on the positive real numbers
tfb.Softplus(),
tfb.Softplus(),
])
kernel = tfp.mcmc.SimpleStepSizeAdaptation(
inner_kernel=kernel,
num_adaptation_steps=int(0.8*num_burnin_steps))
states = tfp.mcmc.sample_chain(
num_results=num_results,
num_burnin_steps=num_burnin_steps,
current_state=[
# The three latent variables
tf.ones([], name='init_switchpoint'),
tf.ones([], name='init_early_disaster_rate'),
tf.ones([], name='init_late_disaster_rate'),
],
trace_fn=None,
kernel=kernel)
return states
switch_samples = [s.numpy() for s in make_chain(
lambda *args: target_log_prob_fn(model_switch, *args))]
sigmoid_samples = [s.numpy() for s in make_chain(
lambda *args: target_log_prob_fn(model_sigmoid, *args))]
switchpoint, early_disaster_rate, late_disaster_rate = zip(
switch_samples, sigmoid_samples)
הפעל את שני הדגמים במקביל:
דמיינו את התוצאה
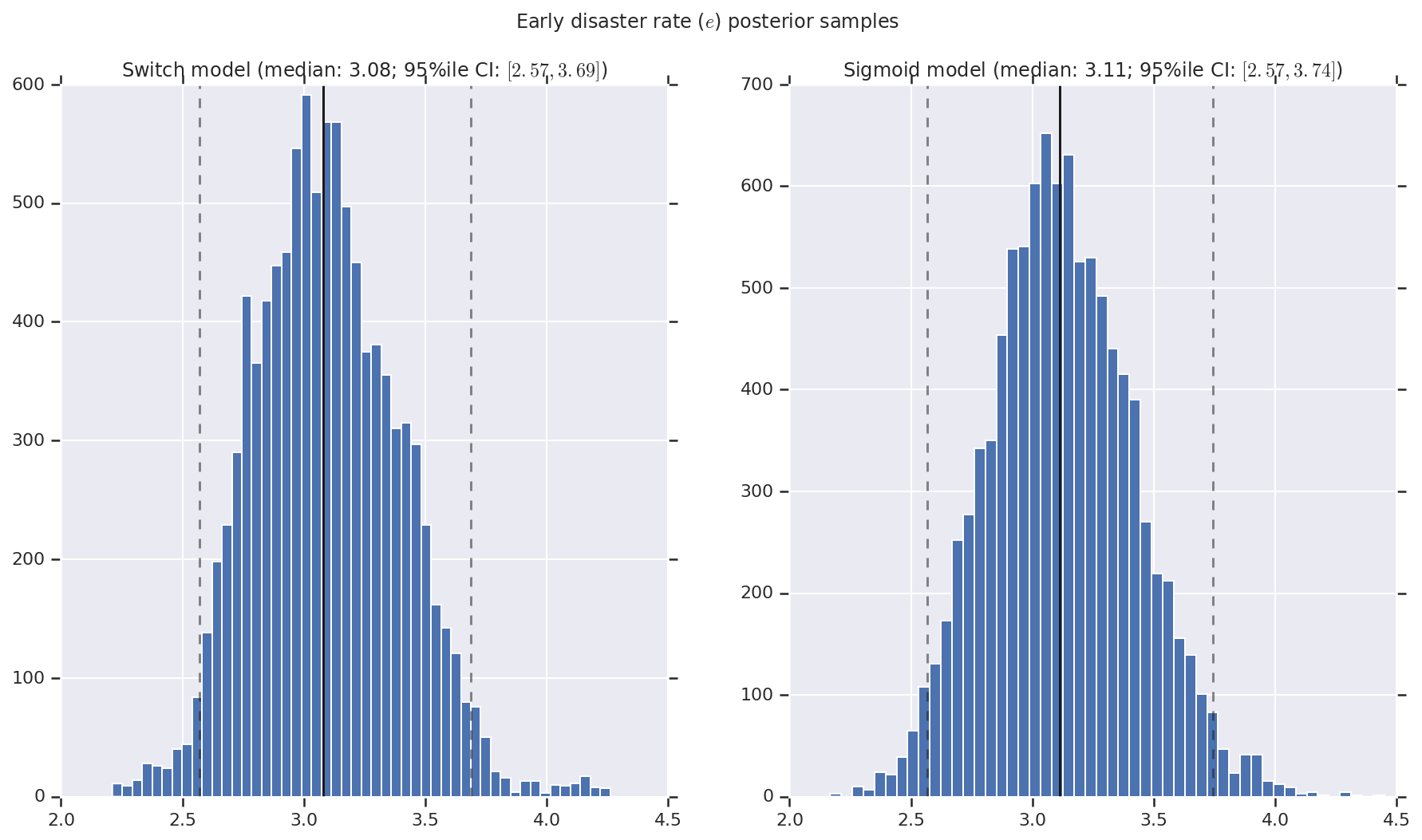
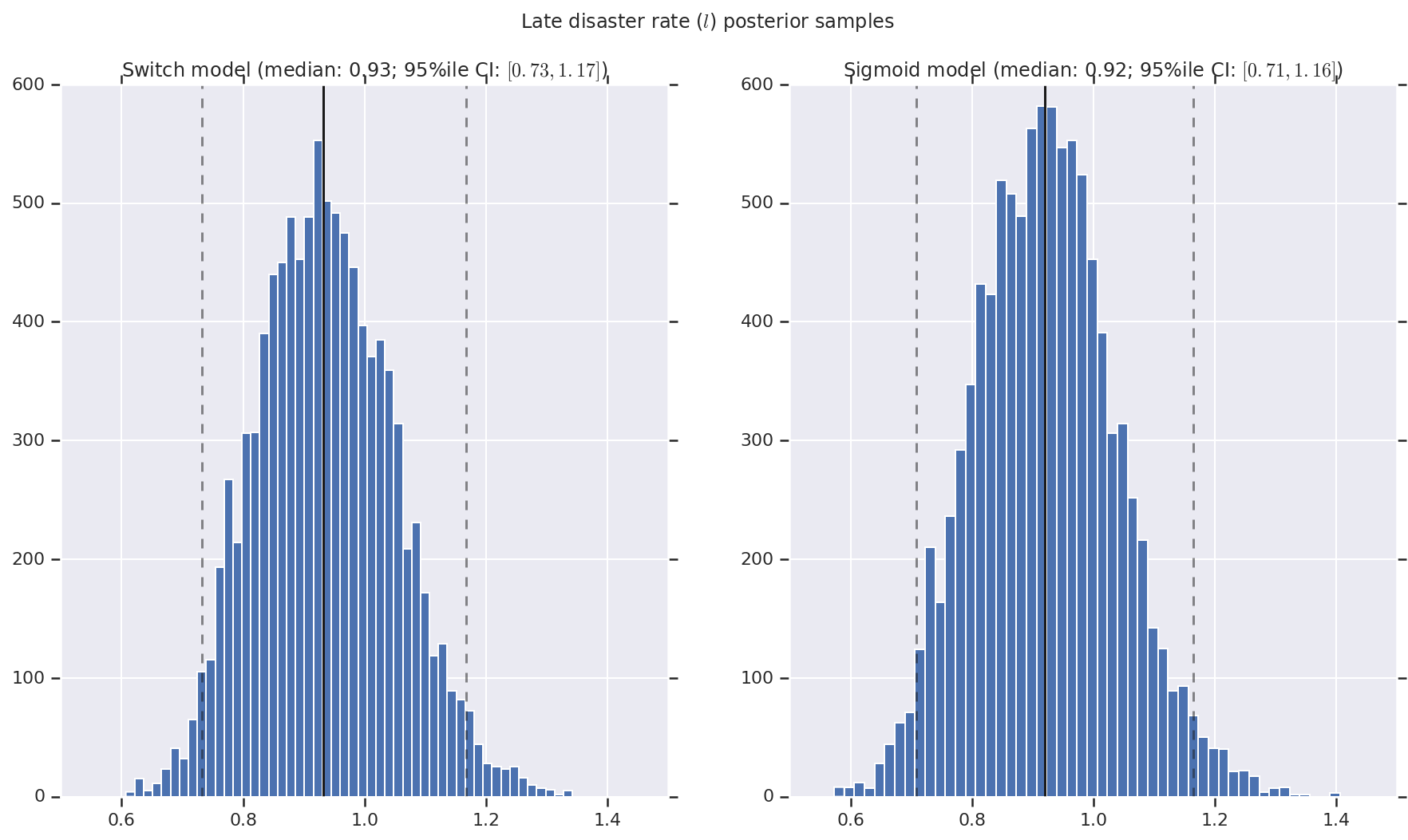
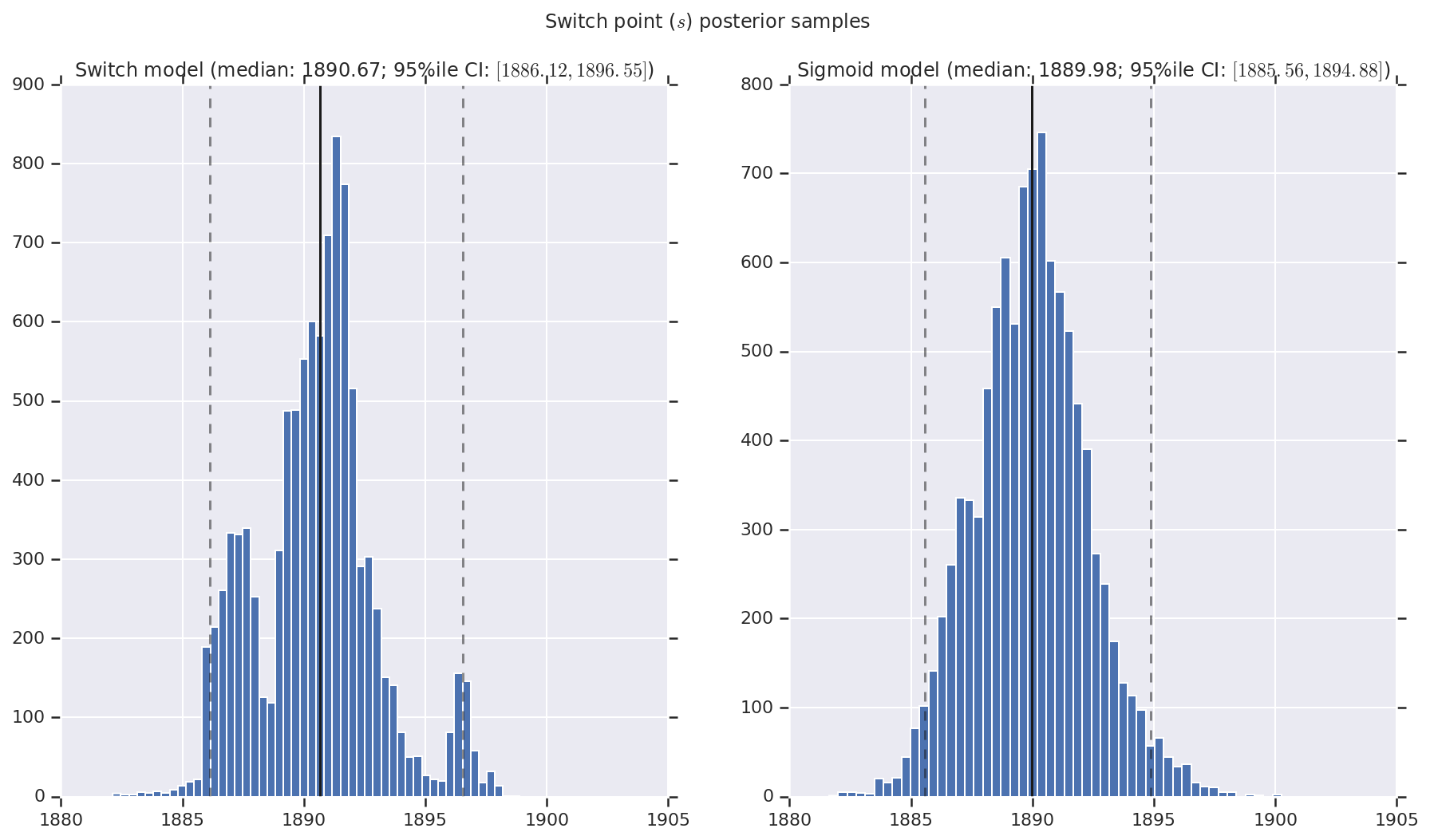
אנו מדמיינים את התוצאה כהיסטוגרמות של דגימות של ההתפלגות האחורית עבור שיעור האסון המוקדם והמאוחר, כמו גם נקודת המעבר. ההיסטוגרמות מכוסות בקו מוצק המייצג את חציון המדגם, כמו גם את גבולות המרווח האמינים של 95%ile כקווים מקווקוים.
def _desc(v):
return '(median: {}; 95%ile CI: $[{}, {}]$)'.format(
*np.round(np.percentile(v, [50, 2.5, 97.5]), 2))
for t, v in [
('Early disaster rate ($e$) posterior samples', early_disaster_rate),
('Late disaster rate ($l$) posterior samples', late_disaster_rate),
('Switch point ($s$) posterior samples', years[0] + switchpoint),
]:
fig, ax = plt.subplots(nrows=1, ncols=2, sharex=True)
for (m, i) in (('Switch', 0), ('Sigmoid', 1)):
a = ax[i]
a.hist(v[i], bins=50)
a.axvline(x=np.percentile(v[i], 50), color='k')
a.axvline(x=np.percentile(v[i], 2.5), color='k', ls='dashed', alpha=.5)
a.axvline(x=np.percentile(v[i], 97.5), color='k', ls='dashed', alpha=.5)
a.set_title(m + ' model ' + _desc(v[i]))
fig.suptitle(t)
plt.show()