
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этой колабе мы рассмотрим выборку из апостериорной модели байесовской гауссовской модели смеси (BGMM), используя только примитивы TensorFlow Probability.
Модель
Для \(k\in\{1,\ldots, K\}\) компонентов смеси , каждые из которых размерность \(D\), мы хотели бы, чтобы модель \(i\in\{1,\ldots,N\}\) IID образцов с использованием следующей байесовская модели гауссовой смеси:
\[\begin{align*} \theta &\sim \text{Dirichlet}(\text{concentration}=\alpha_0)\\ \mu_k &\sim \text{Normal}(\text{loc}=\mu_{0k}, \text{scale}=I_D)\\ T_k &\sim \text{Wishart}(\text{df}=5, \text{scale}=I_D)\\ Z_i &\sim \text{Categorical}(\text{probs}=\theta)\\ Y_i &\sim \text{Normal}(\text{loc}=\mu_{z_i}, \text{scale}=T_{z_i}^{-1/2})\\ \end{align*}\]
Обратите внимание, что scale аргументы все имеют cholesky семантики. Мы используем это соглашение, потому что оно относится к TF Distributions (которое само использует это соглашение отчасти потому, что оно выгодно с вычислительной точки зрения).
Наша цель - создать образцы из апостериорного:
\[p\left(\theta, \{\mu_k, T_k\}_{k=1}^K \Big| \{y_i\}_{i=1}^N, \alpha_0, \{\mu_{ok}\}_{k=1}^K\right)\]
Обратите внимание , что \(\{Z_i\}_{i=1}^N\) нет - we're заинтересованы только в тех случайных величин , которые не масштабируются с \(N\). (И , к счастью , есть распределение TF , который обрабатывает маргинализируя из \(Z_i\).)
Невозможно напрямую выполнить выборку из этого распределения из-за трудноразрешимого в вычислительном отношении члена нормировки.
Метрополис-Гастингс алгоритмы являются методом для отбора проб из трудноизлечимых к нормализуют распределений.
TensorFlow Probability предлагает несколько вариантов MCMC, в том числе несколько на основе Metropolis-Hastings. В этом ноутбуке, мы будем использовать гамильтонов Монте - tfp.mcmc.HamiltonianMonteCarlo Карло ( tfp.mcmc.HamiltonianMonteCarlo ). HMC часто является хорошим выбором, потому что он может быстро сходиться, совместно производить выборку пространства состояний (в отличие от покоординатного) и использовать одно из достоинств TF: автоматическое дифференцирование. Тем не менее, отбор проб из BGMM задней действительно может быть лучше сделано другими подходами, например, выборки Гиббса .
%matplotlib inline
import functools
import matplotlib.pyplot as plt; plt.style.use('ggplot')
import numpy as np
import seaborn as sns; sns.set_context('notebook')
import tensorflow.compat.v2 as tf
tf.enable_v2_behavior()
import tensorflow_probability as tfp
tfd = tfp.distributions
tfb = tfp.bijectors
physical_devices = tf.config.experimental.list_physical_devices('GPU')
if len(physical_devices) > 0:
tf.config.experimental.set_memory_growth(physical_devices[0], True)
Прежде чем фактически строить модель, нам нужно определить новый тип распределения. Из приведенной выше спецификации модели ясно, что мы параметризуем MVN с помощью обратной ковариационной матрицы, то есть [матрицы точности] (https://en.wikipedia.org/wiki/Precision_ (statistics% 29)). Для этого в TF, мы должны будем раскатывать нашу Bijector Это. Bijector будет использовать прямые преобразования:
-
Y = tf.linalg.triangular_solve((tf.linalg.matrix_transpose(chol_precision_tril), X, adjoint=True) + loc.
И log_prob расчет только обратное, а именно:
-
X = tf.linalg.matmul(chol_precision_tril, X - loc, adjoint_a=True).
Так как все , что нужно для НМС является log_prob , это означает , что мы когда - либо избежать вызова tf.linalg.triangular_solve (как было бы в случае tfd.MultivariateNormalTriL ). Это выгодно , так как tf.linalg.matmul обычно быстрее из - за лучшую локальность кэша.
class MVNCholPrecisionTriL(tfd.TransformedDistribution):
"""MVN from loc and (Cholesky) precision matrix."""
def __init__(self, loc, chol_precision_tril, name=None):
super(MVNCholPrecisionTriL, self).__init__(
distribution=tfd.Independent(tfd.Normal(tf.zeros_like(loc),
scale=tf.ones_like(loc)),
reinterpreted_batch_ndims=1),
bijector=tfb.Chain([
tfb.Shift(shift=loc),
tfb.Invert(tfb.ScaleMatvecTriL(scale_tril=chol_precision_tril,
adjoint=True)),
]),
name=name)
tfd.Independent распределение витки независимых розыгрыши одного распределения, в многомерное распределение со статистически независимыми координатами. С точки зрения вычисления log_prob , это «мета-распределение» проявляется в виде простой суммы по измерению событий (ов).
Также обратите внимание , что мы взяли adjoint ( «транспонирование») в масштабе матрицы. Это происходит потому , что если точность обратной ковариации, т.е. \(P=C^{-1}\) и если \(C=AA^\top\), то \(P=BB^{\top}\) где \(B=A^{-\top}\).
Поскольку это распределение является своего рода сложно, давайте быстро проверить , что наша MVNCholPrecisionTriL работает , как мы думаем , что должны.
def compute_sample_stats(d, seed=42, n=int(1e6)):
x = d.sample(n, seed=seed)
sample_mean = tf.reduce_mean(x, axis=0, keepdims=True)
s = x - sample_mean
sample_cov = tf.linalg.matmul(s, s, adjoint_a=True) / tf.cast(n, s.dtype)
sample_scale = tf.linalg.cholesky(sample_cov)
sample_mean = sample_mean[0]
return [
sample_mean,
sample_cov,
sample_scale,
]
dtype = np.float32
true_loc = np.array([1., -1.], dtype=dtype)
true_chol_precision = np.array([[1., 0.],
[2., 8.]],
dtype=dtype)
true_precision = np.matmul(true_chol_precision, true_chol_precision.T)
true_cov = np.linalg.inv(true_precision)
d = MVNCholPrecisionTriL(
loc=true_loc,
chol_precision_tril=true_chol_precision)
[sample_mean, sample_cov, sample_scale] = [
t.numpy() for t in compute_sample_stats(d)]
print('true mean:', true_loc)
print('sample mean:', sample_mean)
print('true cov:\n', true_cov)
print('sample cov:\n', sample_cov)
true mean: [ 1. -1.] sample mean: [ 1.0002806 -1.000105 ] true cov: [[ 1.0625 -0.03125 ] [-0.03125 0.015625]] sample cov: [[ 1.0641273 -0.03126175] [-0.03126175 0.01559312]]
Поскольку выборочное среднее и ковариация близки к истинному среднему и ковариации, кажется, что распределение реализовано правильно. Теперь мы будем использовать MVNCholPrecisionTriL tfp.distributions.JointDistributionNamed указать модель BGMM. Для наблюдательной модели, мы будем использовать tfd.MixtureSameFamily автоматически интегрировать вне \(\{Z_i\}_{i=1}^N\) рисует.
dtype = np.float64
dims = 2
components = 3
num_samples = 1000
bgmm = tfd.JointDistributionNamed(dict(
mix_probs=tfd.Dirichlet(
concentration=np.ones(components, dtype) / 10.),
loc=tfd.Independent(
tfd.Normal(
loc=np.stack([
-np.ones(dims, dtype),
np.zeros(dims, dtype),
np.ones(dims, dtype),
]),
scale=tf.ones([components, dims], dtype)),
reinterpreted_batch_ndims=2),
precision=tfd.Independent(
tfd.WishartTriL(
df=5,
scale_tril=np.stack([np.eye(dims, dtype=dtype)]*components),
input_output_cholesky=True),
reinterpreted_batch_ndims=1),
s=lambda mix_probs, loc, precision: tfd.Sample(tfd.MixtureSameFamily(
mixture_distribution=tfd.Categorical(probs=mix_probs),
components_distribution=MVNCholPrecisionTriL(
loc=loc,
chol_precision_tril=precision)),
sample_shape=num_samples)
))
def joint_log_prob(observations, mix_probs, loc, chol_precision):
"""BGMM with priors: loc=Normal, precision=Inverse-Wishart, mix=Dirichlet.
Args:
observations: `[n, d]`-shaped `Tensor` representing Bayesian Gaussian
Mixture model draws. Each sample is a length-`d` vector.
mix_probs: `[K]`-shaped `Tensor` representing random draw from
`Dirichlet` prior.
loc: `[K, d]`-shaped `Tensor` representing the location parameter of the
`K` components.
chol_precision: `[K, d, d]`-shaped `Tensor` representing `K` lower
triangular `cholesky(Precision)` matrices, each being sampled from
a Wishart distribution.
Returns:
log_prob: `Tensor` representing joint log-density over all inputs.
"""
return bgmm.log_prob(
mix_probs=mix_probs, loc=loc, precision=chol_precision, s=observations)
Создание "обучающих" данных
Для этой демонстрации мы выберем случайные данные.
true_loc = np.array([[-2., -2],
[0, 0],
[2, 2]], dtype)
random = np.random.RandomState(seed=43)
true_hidden_component = random.randint(0, components, num_samples)
observations = (true_loc[true_hidden_component] +
random.randn(num_samples, dims).astype(dtype))
Байесовский вывод с использованием HMC
Теперь, когда мы использовали TFD для определения нашей модели и получили некоторые наблюдаемые данные, у нас есть все необходимое для запуска HMC.
Для этого мы будем использовать частичное приложение к «придавить» вещи , которые мы не хотим образец. В этом случае , что означает , что мы достаточно лишь придавить observations . (Гипер-параметры уже запеченные в к предыдущим распределениям и не частям joint_log_prob функции подписи.)
unnormalized_posterior_log_prob = functools.partial(joint_log_prob, observations)
initial_state = [
tf.fill([components],
value=np.array(1. / components, dtype),
name='mix_probs'),
tf.constant(np.array([[-2., -2],
[0, 0],
[2, 2]], dtype),
name='loc'),
tf.linalg.eye(dims, batch_shape=[components], dtype=dtype, name='chol_precision'),
]
Неограниченное представление
Гамильтониан Монте-Карло (HMC) требует, чтобы целевая функция логарифмической вероятности была дифференцируемой по своим аргументам. Более того, HMC может демонстрировать значительно более высокую статистическую эффективность, если пространство состояний не ограничено.
Это означает, что нам придется решить две основные проблемы при выборке из апостериорной BGMM:
- \(\theta\) представляет собой дискретный вектор вероятности, то есть, должен быть таким , чтобы \(\sum_{k=1}^K \theta_k = 1\) и \(\theta_k>0\).
- \(T_k\) представляет собой обратную ковариационной матрицы, то есть, должны быть такими , чтобы \(T_k \succ 0\), т.е. является положительно определенной .
Чтобы выполнить это требование, нам необходимо:
- преобразовать ограниченные переменные в неограниченное пространство
- запустить MCMC в неограниченном пространстве
- преобразовать неограниченные переменные обратно в ограниченное пространство.
Как MVNCholPrecisionTriL , мы будем использовать Bijector s для преобразования случайных переменных без ограничений пространства.
Dirichletпреобразуется в пространстве без ограничений через SoftMax функции .Наша прецизионная случайная величина - это распределение по положительным полуопределенным матрицам. Для этого мы Отменить закрепление будем использовать
FillTriangularиTransformDiagonalbijectors. Они преобразуют векторы в матрицы нижнего треугольника и гарантируют, что диагональ положительна. Первая из них является полезной , поскольку она позволяет выборки только \(d(d+1)/2\) плавает , а не \(d^2\).
unconstraining_bijectors = [
tfb.SoftmaxCentered(),
tfb.Identity(),
tfb.Chain([
tfb.TransformDiagonal(tfb.Softplus()),
tfb.FillTriangular(),
])]
@tf.function(autograph=False)
def sample():
return tfp.mcmc.sample_chain(
num_results=2000,
num_burnin_steps=500,
current_state=initial_state,
kernel=tfp.mcmc.SimpleStepSizeAdaptation(
tfp.mcmc.TransformedTransitionKernel(
inner_kernel=tfp.mcmc.HamiltonianMonteCarlo(
target_log_prob_fn=unnormalized_posterior_log_prob,
step_size=0.065,
num_leapfrog_steps=5),
bijector=unconstraining_bijectors),
num_adaptation_steps=400),
trace_fn=lambda _, pkr: pkr.inner_results.inner_results.is_accepted)
[mix_probs, loc, chol_precision], is_accepted = sample()
Теперь выполним цепочку и распечатаем апостериорные средние.
acceptance_rate = tf.reduce_mean(tf.cast(is_accepted, dtype=tf.float32)).numpy()
mean_mix_probs = tf.reduce_mean(mix_probs, axis=0).numpy()
mean_loc = tf.reduce_mean(loc, axis=0).numpy()
mean_chol_precision = tf.reduce_mean(chol_precision, axis=0).numpy()
precision = tf.linalg.matmul(chol_precision, chol_precision, transpose_b=True)
print('acceptance_rate:', acceptance_rate)
print('avg mix probs:', mean_mix_probs)
print('avg loc:\n', mean_loc)
print('avg chol(precision):\n', mean_chol_precision)
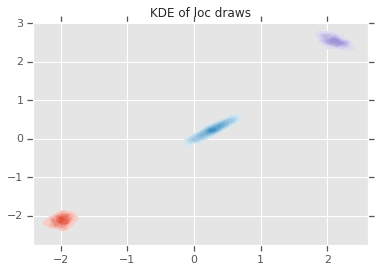
acceptance_rate: 0.5305 avg mix probs: [0.25248723 0.60729516 0.1402176 ] avg loc: [[-1.96466753 -2.12047249] [ 0.27628865 0.22944732] [ 2.06461244 2.54216122]] avg chol(precision): [[[ 1.05105032 0. ] [ 0.12699955 1.06553113]] [[ 0.76058015 0. ] [-0.50332767 0.77947431]] [[ 1.22770457 0. ] [ 0.70670027 1.50914164]]]
loc_ = loc.numpy()
ax = sns.kdeplot(loc_[:,0,0], loc_[:,0,1], shade=True, shade_lowest=False)
ax = sns.kdeplot(loc_[:,1,0], loc_[:,1,1], shade=True, shade_lowest=False)
ax = sns.kdeplot(loc_[:,2,0], loc_[:,2,1], shade=True, shade_lowest=False)
plt.title('KDE of loc draws');
Вывод
Этот простой колаб продемонстрировал, как примитивы TensorFlow Probability можно использовать для построения иерархических моделей байесовской смеси.