
Uczenie się strukturalne neuronowe: szkolenie z sygnałami strukturalnymi
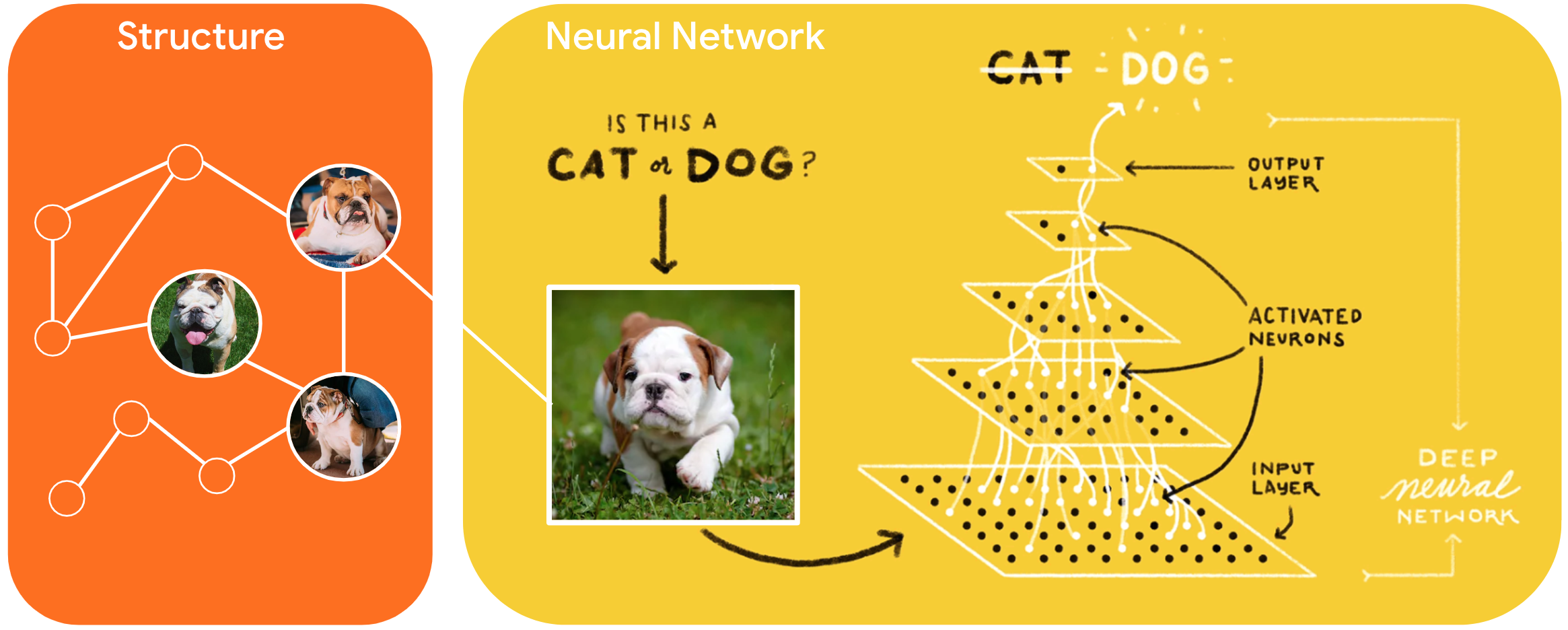
Neural Structured Learning (NSL) to nowy paradygmat uczenia się, który służy do uczenia sieci neuronowych poprzez wykorzystanie sygnałów strukturalnych oprócz danych wejściowych funkcji. Struktura może być jawna, reprezentowana przez wykres lub dorozumiana, wywołana perturbacją przeciwnika.
Sygnały strukturalne są powszechnie używane do reprezentowania relacji lub podobieństw między próbkami, które mogą być oznakowane lub nieoznakowane. Dlatego wykorzystanie tych sygnałów podczas uczenia sieci neuronowych obejmuje zarówno dane oznaczone, jak i nieoznaczone, co może poprawić dokładność modelu, szczególnie gdy ilość oznaczonych danych jest stosunkowo niewielka . Ponadto modele wytrenowane przy użyciu próbek generowanych przez dodanie perturbacji przeciwnika okazały się odporne na złośliwe ataki , których celem jest wprowadzenie w błąd prognoz lub klasyfikacji modelu.
NSL uogólnia uczenie się grafów neuronowych oraz uczenie przeciwstawne . Struktura NSL w TensorFlow zapewnia programistom następujące łatwe w użyciu interfejsy API i narzędzia do trenowania modeli za pomocą ustrukturyzowanych sygnałów:
- Interfejsy API Keras umożliwiające uczenie z wykresami (struktura jawna) i perturbacje przeciwstawne (struktura niejawna).
- Operacje i funkcje TF umożliwiające trening ze strukturą podczas korzystania z interfejsów API TensorFlow niższego poziomu
- Narzędzia do tworzenia wykresów i konstruowania danych wejściowych do wykresów na potrzeby szkolenia
Włączenie uporządkowanych sygnałów odbywa się tylko podczas treningu. Tak więc wydajność przepływu pracy udostępniania/wnioskowania pozostaje niezmieniona. Więcej informacji na temat uczenia struktury neuronowej można znaleźć w naszym opisie struktury . Aby rozpocząć, zapoznaj się z naszym przewodnikiem instalacji , a praktyczne wprowadzenie do NSL znajdziesz w naszych samouczkach.
import tensorflow as tf import neural_structured_learning as nsl # Prepare data. (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 # Create a base model -- sequential, functional, or subclass. model = tf.keras.Sequential([ tf.keras.Input((28, 28), name='feature'), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) # Wrap the model with adversarial regularization. adv_config = nsl.configs.make_adv_reg_config(multiplier=0.2, adv_step_size=0.05) adv_model = nsl.keras.AdversarialRegularization(model, adv_config=adv_config) # Compile, train, and evaluate. adv_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) adv_model.fit({'feature': x_train, 'label': y_train}, batch_size=32, epochs=5) adv_model.evaluate({'feature': x_test, 'label': y_test})
