
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | | |
Tổng quat
Phân loại máy tính xách tay Bộ phim này đánh giá là tích cực hay tiêu cực bằng cách sử dụng văn bản của tổng quan. Đây là một ví dụ về phân loại nhị phân, một loại quan trọng và được áp dụng rộng rãi các vấn đề máy học.
Chúng tôi sẽ chứng minh việc sử dụng chính quy đồ thị trong sổ tay này bằng cách xây dựng một đồ thị từ đầu vào đã cho. Công thức chung để xây dựng một mô hình được điều chỉnh bằng biểu đồ bằng cách sử dụng khung Học tập có cấu trúc thần kinh (NSL) khi đầu vào không chứa một biểu đồ rõ ràng như sau:
- Tạo nhúng cho từng mẫu văn bản trong đầu vào. Điều này có thể được thực hiện bằng mô hình pre-đào tạo như word2vec , xoay , Bert , vv
- Xây dựng biểu đồ dựa trên những lần nhúng này bằng cách sử dụng số liệu tương tự như khoảng cách 'L2', khoảng cách 'cosin', v.v. Các nút trong biểu đồ tương ứng với các mẫu và các cạnh trong biểu đồ tương ứng với độ giống nhau giữa các cặp mẫu.
- Tạo dữ liệu đào tạo từ biểu đồ tổng hợp ở trên và các tính năng mẫu. Dữ liệu đào tạo kết quả sẽ chứa các tính năng lân cận ngoài các tính năng nút ban đầu.
- Tạo mạng thần kinh làm mô hình cơ sở bằng cách sử dụng API tuần tự, chức năng hoặc lớp con của Keras.
- Bao bọc mô hình cơ sở bằng lớp bao bọc GraphRegulification, được cung cấp bởi khung NSL, để tạo mô hình Keras đồ thị mới. Mô hình mới này sẽ bao gồm sự mất chính quy đồ thị như là thuật ngữ chính quy hóa trong mục tiêu đào tạo của nó.
- Huấn luyện và đánh giá mô hình Keras đồ thị.
Yêu cầu
- Cài đặt gói Học có cấu trúc thần kinh.
- Cài đặt tensorflow-hub.
pip install --quiet neural-structured-learningpip install --quiet tensorflow-hub
Phụ thuộc và nhập khẩu
import matplotlib.pyplot as plt
import numpy as np
import neural_structured_learning as nsl
import tensorflow as tf
import tensorflow_hub as hub
# Resets notebook state
tf.keras.backend.clear_session()
print("Version: ", tf.__version__)
print("Eager mode: ", tf.executing_eagerly())
print("Hub version: ", hub.__version__)
print(
"GPU is",
"available" if tf.config.list_physical_devices("GPU") else "NOT AVAILABLE")
Version: 2.8.0-rc0 Eager mode: True Hub version: 0.12.0 GPU is NOT AVAILABLE 2022-01-05 12:28:32.113752: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
Tập dữ liệu IMDB
Các bộ dữ liệu IMDB chứa văn bản 50.000 đánh giá phim từ Internet Movie Database . Chúng được chia thành 25.000 đánh giá để đào tạo và 25.000 đánh giá để kiểm tra. Việc đào tạo và thử nghiệm bộ được cân bằng, nghĩa là chúng có chứa một số lượng tương đương đánh giá tích cực và tiêu cực.
Trong hướng dẫn này, chúng tôi sẽ sử dụng phiên bản được xử lý trước của tập dữ liệu IMDB.
Tải xuống tập dữ liệu IMDB được xử lý trước
Tập dữ liệu IMDB được đóng gói với TensorFlow. Nó đã được xử lý trước để các đánh giá (chuỗi từ) đã được chuyển đổi thành chuỗi các số nguyên, trong đó mỗi số nguyên đại diện cho một từ cụ thể trong từ điển.
Đoạn mã sau tải xuống tập dữ liệu IMDB (hoặc sử dụng bản sao được lưu trong bộ nhớ cache nếu nó đã được tải xuống):
imdb = tf.keras.datasets.imdb
(pp_train_data, pp_train_labels), (pp_test_data, pp_test_labels) = (
imdb.load_data(num_words=10000))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz 17465344/17464789 [==============================] - 0s 0us/step 17473536/17464789 [==============================] - 0s 0us/step
Đối số num_words=10000 giữ phía trên 10.000 từ thường xuyên nhất xảy ra trong dữ liệu huấn luyện. Các từ hiếm được loại bỏ để giữ cho kích thước của từ vựng có thể quản lý được.
Khám phá dữ liệu
Hãy dành một chút thời gian để hiểu định dạng của dữ liệu. Tập dữ liệu được xử lý trước: mỗi ví dụ là một mảng các số nguyên đại diện cho các từ của bài đánh giá phim. Mỗi nhãn là một giá trị nguyên của 0 hoặc 1, trong đó 0 là đánh giá tiêu cực và 1 là đánh giá tích cực.
print('Training entries: {}, labels: {}'.format(
len(pp_train_data), len(pp_train_labels)))
training_samples_count = len(pp_train_data)
Training entries: 25000, labels: 25000
Văn bản đánh giá đã được chuyển đổi thành số nguyên, trong đó mỗi số nguyên đại diện cho một từ cụ thể trong từ điển. Đây là những gì bài đánh giá đầu tiên trông như thế nào:
print(pp_train_data[0])
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]
Các bài đánh giá phim có thể dài ngắn khác nhau. Đoạn mã dưới đây hiển thị số lượng từ trong bài đánh giá đầu tiên và thứ hai. Vì các đầu vào cho mạng nơ-ron phải có cùng độ dài, chúng ta sẽ cần giải quyết vấn đề này sau.
len(pp_train_data[0]), len(pp_train_data[1])
(218, 189)
Chuyển đổi số nguyên trở lại thành từ
Có thể hữu ích nếu biết cách chuyển đổi số nguyên trở lại văn bản tương ứng. Ở đây, chúng tôi sẽ tạo một hàm trợ giúp để truy vấn một đối tượng từ điển có chứa ánh xạ số nguyên thành chuỗi:
def build_reverse_word_index():
# A dictionary mapping words to an integer index
word_index = imdb.get_word_index()
# The first indices are reserved
word_index = {k: (v + 3) for k, v in word_index.items()}
word_index['<PAD>'] = 0
word_index['<START>'] = 1
word_index['<UNK>'] = 2 # unknown
word_index['<UNUSED>'] = 3
return dict((value, key) for (key, value) in word_index.items())
reverse_word_index = build_reverse_word_index()
def decode_review(text):
return ' '.join([reverse_word_index.get(i, '?') for i in text])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json 1646592/1641221 [==============================] - 0s 0us/step 1654784/1641221 [==============================] - 0s 0us/step
Bây giờ chúng ta có thể sử dụng decode_review chức năng để hiển thị văn bản cho việc xem xét đầu tiên:
decode_review(pp_train_data[0])
"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert <UNK> is an amazing actor and now the same being director <UNK> father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for <UNK> and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also <UNK> to the two little boy's that played the <UNK> of norman and paul they were just brilliant children are often left out of the <UNK> list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don't you think the whole story was so lovely because it was true and was someone's life after all that was shared with us all"
Xây dựng đồ thị
Xây dựng đồ thị liên quan đến việc tạo các nhúng cho các mẫu văn bản và sau đó sử dụng một hàm tương tự để so sánh các nhúng.
Trước khi tiếp tục, trước tiên chúng ta tạo một thư mục để lưu trữ các tạo tác được tạo bởi hướng dẫn này.
mkdir -p /tmp/imdb
Tạo nhúng mẫu
Chúng tôi sẽ sử dụng pretrained embeddings xoay để tạo embeddings trong tf.train.Example định dạng cho mỗi mẫu trong đầu vào. Chúng tôi sẽ lưu trữ các embeddings dẫn đến TFRecord định dạng cùng với một tính năng bổ sung mà đại diện cho ID của mỗi mẫu. Điều này quan trọng và sẽ cho phép chúng tôi so khớp các nhúng mẫu với các nút tương ứng trong biểu đồ sau này.
pretrained_embedding = 'https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1'
hub_layer = hub.KerasLayer(
pretrained_embedding, input_shape=[], dtype=tf.string, trainable=True)
def _int64_feature(value):
"""Returns int64 tf.train.Feature."""
return tf.train.Feature(int64_list=tf.train.Int64List(value=value.tolist()))
def _bytes_feature(value):
"""Returns bytes tf.train.Feature."""
return tf.train.Feature(
bytes_list=tf.train.BytesList(value=[value.encode('utf-8')]))
def _float_feature(value):
"""Returns float tf.train.Feature."""
return tf.train.Feature(float_list=tf.train.FloatList(value=value.tolist()))
def create_embedding_example(word_vector, record_id):
"""Create tf.Example containing the sample's embedding and its ID."""
text = decode_review(word_vector)
# Shape = [batch_size,].
sentence_embedding = hub_layer(tf.reshape(text, shape=[-1,]))
# Flatten the sentence embedding back to 1-D.
sentence_embedding = tf.reshape(sentence_embedding, shape=[-1])
features = {
'id': _bytes_feature(str(record_id)),
'embedding': _float_feature(sentence_embedding.numpy())
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_embeddings(word_vectors, output_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(output_path) as writer:
for word_vector in word_vectors:
example = create_embedding_example(word_vector, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features containing embeddings for training data in
# TFRecord format.
create_embeddings(pp_train_data, '/tmp/imdb/embeddings.tfr', 0)
25000
Xây dựng biểu đồ
Bây giờ chúng ta có các nhúng mẫu, chúng ta sẽ sử dụng chúng để xây dựng một đồ thị tương tự, tức là các nút trong đồ thị này sẽ tương ứng với các mẫu và các cạnh trong đồ thị này sẽ tương ứng với độ tương tự giữa các cặp nút.
Học có cấu trúc thần kinh cung cấp thư viện xây dựng biểu đồ để xây dựng biểu đồ dựa trên các lần nhúng mẫu. Nó sử dụng sự tương đồng cosin là biện pháp tương tự để so sánh embeddings và xây dựng các cạnh giữa chúng. Nó cũng cho phép chúng tôi chỉ định ngưỡng tương tự, có thể được sử dụng để loại bỏ các cạnh khác nhau khỏi biểu đồ cuối cùng. Trong ví dụ này, sử dụng 0,99 làm ngưỡng tương tự và 12345 làm hạt ngẫu nhiên, chúng tôi kết thúc với một biểu đồ có 429.415 cạnh hai hướng. Ở đây chúng ta đang sử dụng hỗ trợ những người xây dựng đồ thị cho địa phương nhạy cảm băm (LSH) để tăng tốc độ xây dựng đồ thị. Để biết chi tiết về việc sử dụng hỗ trợ LSH những người xây dựng đồ thị của, xem build_graph_from_config tài liệu API.
graph_builder_config = nsl.configs.GraphBuilderConfig(
similarity_threshold=0.99, lsh_splits=32, lsh_rounds=15, random_seed=12345)
nsl.tools.build_graph_from_config(['/tmp/imdb/embeddings.tfr'],
'/tmp/imdb/graph_99.tsv',
graph_builder_config)
Mỗi cạnh hai hướng được biểu thị bằng hai cạnh có hướng trong tệp TSV đầu ra, do đó tệp đó chứa tổng số 429.415 * 2 = 858.830 dòng:
wc -l /tmp/imdb/graph_99.tsv
858830 /tmp/imdb/graph_99.tsv
Các tính năng mẫu
Chúng tôi tạo ra các tính năng mẫu cho vấn đề của chúng tôi bằng cách sử dụng tf.train.Example định dạng và kiên trì chúng trong TFRecord định dạng. Mỗi mẫu sẽ bao gồm ba tính năng sau:
- id: Nút ID của mẫu.
- chữ: danh sách Int64 Một chứa ID từ.
- nhãn: Một singleton Int64 xác định các lớp mục tiêu của tổng quan.
def create_example(word_vector, label, record_id):
"""Create tf.Example containing the sample's word vector, label, and ID."""
features = {
'id': _bytes_feature(str(record_id)),
'words': _int64_feature(np.asarray(word_vector)),
'label': _int64_feature(np.asarray([label])),
}
return tf.train.Example(features=tf.train.Features(feature=features))
def create_records(word_vectors, labels, record_path, starting_record_id):
record_id = int(starting_record_id)
with tf.io.TFRecordWriter(record_path) as writer:
for word_vector, label in zip(word_vectors, labels):
example = create_example(word_vector, label, record_id)
record_id = record_id + 1
writer.write(example.SerializeToString())
return record_id
# Persist TF.Example features (word vectors and labels) for training and test
# data in TFRecord format.
next_record_id = create_records(pp_train_data, pp_train_labels,
'/tmp/imdb/train_data.tfr', 0)
create_records(pp_test_data, pp_test_labels, '/tmp/imdb/test_data.tfr',
next_record_id)
50000
Tăng cường dữ liệu đào tạo với các hàng xóm của đồ thị
Vì chúng tôi có các tính năng mẫu và biểu đồ tổng hợp, chúng tôi có thể tạo dữ liệu đào tạo tăng cường cho Học có cấu trúc thần kinh. Khung NSL cung cấp một thư viện để kết hợp biểu đồ và các tính năng mẫu để tạo ra dữ liệu đào tạo cuối cùng cho quá trình chính quy hóa đồ thị. Dữ liệu đào tạo kết quả sẽ bao gồm các tính năng mẫu ban đầu cũng như các tính năng của các nước láng giềng tương ứng của chúng.
Trong hướng dẫn này, chúng tôi xem xét các cạnh vô hướng và sử dụng tối đa 3 hàng xóm cho mỗi mẫu để tăng cường dữ liệu đào tạo với các hàng xóm của đồ thị.
nsl.tools.pack_nbrs(
'/tmp/imdb/train_data.tfr',
'',
'/tmp/imdb/graph_99.tsv',
'/tmp/imdb/nsl_train_data.tfr',
add_undirected_edges=True,
max_nbrs=3)
Mô hình cơ sở
Bây giờ chúng tôi đã sẵn sàng để xây dựng một mô hình cơ sở mà không cần chính quy hóa đồ thị. Để xây dựng mô hình này, chúng ta có thể sử dụng các phép nhúng đã được sử dụng trong việc xây dựng biểu đồ hoặc chúng ta có thể học các phép nhúng mới cùng với nhiệm vụ phân loại. Đối với mục đích của sổ tay này, chúng tôi sẽ làm phần sau.
Các biến toàn cục
NBR_FEATURE_PREFIX = 'NL_nbr_'
NBR_WEIGHT_SUFFIX = '_weight'
Siêu tham số
Chúng tôi sẽ sử dụng một thể hiện của HParams để inclue siêu tham số khác nhau và các hằng số được sử dụng để đào tạo và đánh giá. Chúng tôi mô tả ngắn gọn từng người trong số họ dưới đây:
num_classes: Có 2 lớp - tích cực và tiêu cực.
max_seq_length: Đây là số lượng tối đa từ coi từ mỗi xét phim trong ví dụ này.
vocab_size: Đây là kích thước của từ vựng được coi là ví dụ này.
distance_type: Đây là khoảng cách số liệu sử dụng để hợp thức các mẫu với các nước láng giềng.
graph_regularization_multiplier: điều khiển này trọng lượng tương đối của các thuật ngữ đồ thị quy tắc trong hàm tổn thất chung.
num_neighbors: Số lượng các nước láng giềng sử dụng cho đồ thị quy tắc. Giá trị này phải nhỏ hơn hoặc bằng với
max_nbrsluận sử dụng trên khi gọinsl.tools.pack_nbrs.num_fc_units: Số lượng đơn vị trong lớp kết nối đầy đủ của mạng lưới thần kinh.
train_epochs: Số lượng các thời kỳ huấn luyện.
kích thước hàng loạt sử dụng cho đào tạo và đánh giá: batch_size.
eval_steps: Số lô để quá trình trước khi xét thấy đánh giá hoàn tất. Nếu thiết lập để
None, tất cả các trường trong tập kiểm tra được đánh giá.
class HParams(object):
"""Hyperparameters used for training."""
def __init__(self):
### dataset parameters
self.num_classes = 2
self.max_seq_length = 256
self.vocab_size = 10000
### neural graph learning parameters
self.distance_type = nsl.configs.DistanceType.L2
self.graph_regularization_multiplier = 0.1
self.num_neighbors = 2
### model architecture
self.num_embedding_dims = 16
self.num_lstm_dims = 64
self.num_fc_units = 64
### training parameters
self.train_epochs = 10
self.batch_size = 128
### eval parameters
self.eval_steps = None # All instances in the test set are evaluated.
HPARAMS = HParams()
Chuẩn bị dữ liệu
Các đánh giá — mảng số nguyên — phải được chuyển đổi thành tensor trước khi được đưa vào mạng nơ-ron. Việc chuyển đổi này có thể được thực hiện theo một số cách:
Chuyển đổi các mảng vào vector
0s và1s chỉ xảy ra từ, tương tự như một mã hóa một nóng. Ví dụ, trình tự[3, 5]sẽ trở thành một10000vector chiều đó là tất cả số không trừ chỉ số3và5, đó là những người thân. Sau đó, làm cho lớp đầu tiên trong chúng tôi mạng mộtDenselớp-có thể xử lý nổi dữ liệu vector điểm. Cách tiếp cận này cần nhiều bộ nhớ, tuy nhiên, đòi hỏi mộtnum_words * num_reviewskích thước ma trận.Ngoài ra, chúng ta có thể pad các mảng để họ tất cả đều có cùng độ dài, sau đó tạo ra một tensor nguyên hình dạng
max_length * num_reviews. Chúng ta có thể sử dụng một lớp nhúng có khả năng xử lý hình dạng này làm lớp đầu tiên trong mạng của chúng ta.
Trong hướng dẫn này, chúng tôi sẽ sử dụng cách tiếp cận thứ hai.
Kể từ khi đánh giá bộ phim phải có cùng độ dài, chúng tôi sẽ sử dụng pad_sequence hàm được định nghĩa dưới đây để chuẩn độ dài.
def make_dataset(file_path, training=False):
"""Creates a `tf.data.TFRecordDataset`.
Args:
file_path: Name of the file in the `.tfrecord` format containing
`tf.train.Example` objects.
training: Boolean indicating if we are in training mode.
Returns:
An instance of `tf.data.TFRecordDataset` containing the `tf.train.Example`
objects.
"""
def pad_sequence(sequence, max_seq_length):
"""Pads the input sequence (a `tf.SparseTensor`) to `max_seq_length`."""
pad_size = tf.maximum([0], max_seq_length - tf.shape(sequence)[0])
padded = tf.concat(
[sequence.values,
tf.fill((pad_size), tf.cast(0, sequence.dtype))],
axis=0)
# The input sequence may be larger than max_seq_length. Truncate down if
# necessary.
return tf.slice(padded, [0], [max_seq_length])
def parse_example(example_proto):
"""Extracts relevant fields from the `example_proto`.
Args:
example_proto: An instance of `tf.train.Example`.
Returns:
A pair whose first value is a dictionary containing relevant features
and whose second value contains the ground truth labels.
"""
# The 'words' feature is a variable length word ID vector.
feature_spec = {
'words': tf.io.VarLenFeature(tf.int64),
'label': tf.io.FixedLenFeature((), tf.int64, default_value=-1),
}
# We also extract corresponding neighbor features in a similar manner to
# the features above during training.
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
nbr_weight_key = '{}{}{}'.format(NBR_FEATURE_PREFIX, i,
NBR_WEIGHT_SUFFIX)
feature_spec[nbr_feature_key] = tf.io.VarLenFeature(tf.int64)
# We assign a default value of 0.0 for the neighbor weight so that
# graph regularization is done on samples based on their exact number
# of neighbors. In other words, non-existent neighbors are discounted.
feature_spec[nbr_weight_key] = tf.io.FixedLenFeature(
[1], tf.float32, default_value=tf.constant([0.0]))
features = tf.io.parse_single_example(example_proto, feature_spec)
# Since the 'words' feature is a variable length word vector, we pad it to a
# constant maximum length based on HPARAMS.max_seq_length
features['words'] = pad_sequence(features['words'], HPARAMS.max_seq_length)
if training:
for i in range(HPARAMS.num_neighbors):
nbr_feature_key = '{}{}_{}'.format(NBR_FEATURE_PREFIX, i, 'words')
features[nbr_feature_key] = pad_sequence(features[nbr_feature_key],
HPARAMS.max_seq_length)
labels = features.pop('label')
return features, labels
dataset = tf.data.TFRecordDataset([file_path])
if training:
dataset = dataset.shuffle(10000)
dataset = dataset.map(parse_example)
dataset = dataset.batch(HPARAMS.batch_size)
return dataset
train_dataset = make_dataset('/tmp/imdb/nsl_train_data.tfr', True)
test_dataset = make_dataset('/tmp/imdb/test_data.tfr')
Xây dựng mô hình
Mạng nơ-ron được tạo bằng cách xếp chồng các lớp — điều này đòi hỏi hai quyết định kiến trúc chính:
- Có bao nhiêu lớp để sử dụng trong mô hình?
- Có bao nhiêu đơn vị ẩn để sử dụng cho mỗi lớp?
Trong ví dụ này, dữ liệu đầu vào bao gồm một mảng các chỉ số từ. Các nhãn để dự đoán là 0 hoặc 1.
Chúng tôi sẽ sử dụng LSTM hai hướng làm mô hình cơ sở của chúng tôi trong hướng dẫn này.
# This function exists as an alternative to the bi-LSTM model used in this
# notebook.
def make_feed_forward_model():
"""Builds a simple 2 layer feed forward neural network."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size, 16)(inputs)
pooling_layer = tf.keras.layers.GlobalAveragePooling1D()(embedding_layer)
dense_layer = tf.keras.layers.Dense(16, activation='relu')(pooling_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
def make_bilstm_model():
"""Builds a bi-directional LSTM model."""
inputs = tf.keras.Input(
shape=(HPARAMS.max_seq_length,), dtype='int64', name='words')
embedding_layer = tf.keras.layers.Embedding(HPARAMS.vocab_size,
HPARAMS.num_embedding_dims)(
inputs)
lstm_layer = tf.keras.layers.Bidirectional(
tf.keras.layers.LSTM(HPARAMS.num_lstm_dims))(
embedding_layer)
dense_layer = tf.keras.layers.Dense(
HPARAMS.num_fc_units, activation='relu')(
lstm_layer)
outputs = tf.keras.layers.Dense(1)(dense_layer)
return tf.keras.Model(inputs=inputs, outputs=outputs)
# Feel free to use an architecture of your choice.
model = make_bilstm_model()
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
words (InputLayer) [(None, 256)] 0
embedding (Embedding) (None, 256, 16) 160000
bidirectional (Bidirectiona (None, 128) 41472
l)
dense (Dense) (None, 64) 8256
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 209,793
Trainable params: 209,793
Non-trainable params: 0
_________________________________________________________________
Các lớp được xếp chồng tuần tự một cách hiệu quả để xây dựng bộ phân loại:
- Lớp đầu tiên là một
Inputlớp mà phải mất từ vựng nguyên-mã hóa. - Lớp tiếp theo là một
Embeddinglớp, trong đó có các từ vựng nguyên-mã hóa và vẻ lên vector nhúng cho mỗi từ-index. Các vectơ này được học khi mô hình đào tạo. Các vectơ thêm một thứ nguyên vào mảng đầu ra. Các kích thước kết quả là:(batch, sequence, embedding). - Tiếp theo, lớp LSTM hai chiều trả về một vectơ đầu ra có độ dài cố định cho mỗi ví dụ.
- Vector đầu ra cố định thời lượng này được dẫn qua một đầy đủ kết nối (
Dense) lớp với 64 đơn vị ẩn. - Lớp cuối cùng được kết nối dày đặc với một nút đầu ra duy nhất. Sử dụng
sigmoidchức năng kích hoạt, giá trị này là một phao giữa 0 và 1, đại diện cho một xác suất, hoặc mức độ tin cậy.
Đơn vị ẩn
Các mô hình trên có hai trung gian hay "ẩn" lớp, giữa đầu vào và đầu ra, và loại trừ những Embedding lớp. Số lượng đầu ra (đơn vị, nút hoặc nơ-ron) là thứ nguyên của không gian biểu diễn cho lớp. Nói cách khác, số lượng tự do mạng được phép khi học một đại diện bên trong.
Nếu một mô hình có nhiều đơn vị ẩn hơn (không gian biểu diễn chiều cao hơn) và / hoặc nhiều lớp hơn, thì mạng có thể học các biểu diễn phức tạp hơn. Tuy nhiên, nó làm cho mạng tốn kém hơn về mặt tính toán và có thể dẫn đến việc học các mẫu không mong muốn — các mẫu cải thiện hiệu suất trên dữ liệu đào tạo nhưng không cải thiện trên dữ liệu thử nghiệm. Điều này được gọi overfitting.
Chức năng mất mát và trình tối ưu hóa
Một mô hình cần một chức năng mất mát và một trình tối ưu hóa để đào tạo. Do đây là một vấn đề phân loại nhị phân và mô hình đầu ra một xác suất (một lớp duy nhất đơn vị với một kích hoạt sigmoid), chúng tôi sẽ sử dụng binary_crossentropy chức năng thua lỗ.
model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Tạo một tập hợp xác thực
Khi đào tạo, chúng tôi muốn kiểm tra độ chính xác của mô hình trên dữ liệu mà nó chưa từng thấy trước đây. Tạo một tập hợp kiểm chứng bằng cách thiết lập ngoài một phần nhỏ của dữ liệu huấn luyện gốc. (Tại sao không sử dụng bộ thử nghiệm ngay bây giờ? Mục tiêu của chúng tôi là phát triển và điều chỉnh mô hình của mình chỉ sử dụng dữ liệu đào tạo, sau đó sử dụng dữ liệu thử nghiệm chỉ một lần để đánh giá độ chính xác của chúng tôi).
Trong hướng dẫn này, chúng tôi lấy khoảng 10% mẫu đào tạo ban đầu (10% trong số 25000) làm dữ liệu được gắn nhãn để đào tạo và phần còn lại làm dữ liệu xác thực. Vì phần tách chuyến tàu / thử nghiệm ban đầu là 50/50 (mỗi lần 25000 mẫu), nên phần phân chia chuyến tàu / xác thực / thử nghiệm hiệu quả mà chúng tôi hiện có là 5/45/50.
Lưu ý rằng 'train_dataset' đã được trộn và xáo trộn.
validation_fraction = 0.9
validation_size = int(validation_fraction *
int(training_samples_count / HPARAMS.batch_size))
print(validation_size)
validation_dataset = train_dataset.take(validation_size)
train_dataset = train_dataset.skip(validation_size)
175
Đào tạo mô hình
Đào tạo mô hình theo lô nhỏ. Trong khi đào tạo, hãy theo dõi sự mất mát và độ chính xác của mô hình trên bộ xác nhận:
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
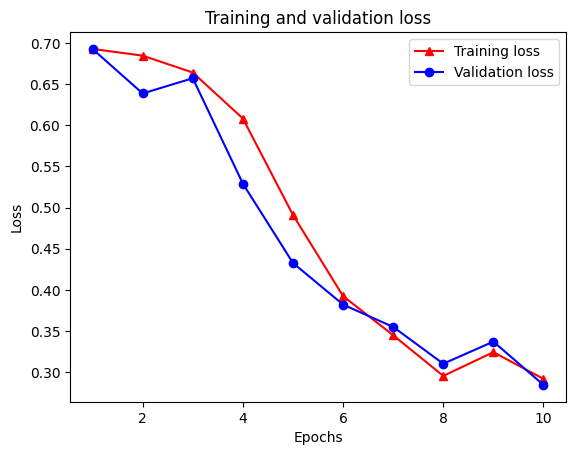
Epoch 1/10 /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/keras/engine/functional.py:559: UserWarning: Input dict contained keys ['NL_nbr_0_words', 'NL_nbr_1_words', 'NL_nbr_0_weight', 'NL_nbr_1_weight'] which did not match any model input. They will be ignored by the model. inputs = self._flatten_to_reference_inputs(inputs) 21/21 [==============================] - 22s 889ms/step - loss: 0.6932 - accuracy: 0.5065 - val_loss: 0.6928 - val_accuracy: 0.5004 Epoch 2/10 21/21 [==============================] - 17s 841ms/step - loss: 0.6918 - accuracy: 0.5000 - val_loss: 0.6843 - val_accuracy: 0.4988 Epoch 3/10 21/21 [==============================] - 17s 839ms/step - loss: 0.6677 - accuracy: 0.5069 - val_loss: 0.5976 - val_accuracy: 0.6507 Epoch 4/10 21/21 [==============================] - 17s 836ms/step - loss: 0.5579 - accuracy: 0.6912 - val_loss: 0.4801 - val_accuracy: 0.7974 Epoch 5/10 21/21 [==============================] - 17s 837ms/step - loss: 0.4377 - accuracy: 0.7965 - val_loss: 0.3678 - val_accuracy: 0.8372 Epoch 6/10 21/21 [==============================] - 17s 836ms/step - loss: 0.3526 - accuracy: 0.8408 - val_loss: 0.4261 - val_accuracy: 0.8283 Epoch 7/10 21/21 [==============================] - 17s 835ms/step - loss: 0.4090 - accuracy: 0.8273 - val_loss: 0.3961 - val_accuracy: 0.8346 Epoch 8/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3105 - accuracy: 0.8842 - val_loss: 0.2976 - val_accuracy: 0.8813 Epoch 9/10 21/21 [==============================] - 17s 834ms/step - loss: 0.3335 - accuracy: 0.8673 - val_loss: 0.3373 - val_accuracy: 0.8537 Epoch 10/10 21/21 [==============================] - 17s 837ms/step - loss: 0.3104 - accuracy: 0.8765 - val_loss: 0.2804 - val_accuracy: 0.8902
Đánh giá mô hình
Bây giờ, hãy xem mô hình hoạt động như thế nào. Hai giá trị sẽ được trả về. Mất mát (một con số đại diện cho lỗi của chúng tôi, giá trị càng thấp càng tốt) và độ chính xác.
results = model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(results)
196/196 [==============================] - 16s 76ms/step - loss: 0.3695 - accuracy: 0.8389 [0.3694916367530823, 0.838919997215271]
Tạo biểu đồ về độ chính xác / mất mát theo thời gian
model.fit() trả về một History đối tượng có chứa một từ điển với tất cả mọi thứ đã xảy ra trong đào tạo:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Có bốn mục nhập: một mục cho mỗi chỉ số được giám sát trong quá trình đào tạo và xác nhận. Chúng tôi có thể sử dụng những điều này để lập biểu đồ về sự mất mát trong quá trình đào tạo và xác thực để so sánh, cũng như độ chính xác của quá trình đào tạo và xác nhận:
acc = history_dict['accuracy']
val_acc = history_dict['val_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
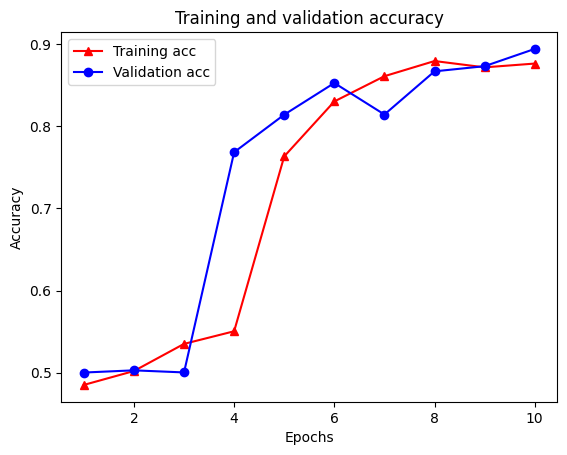
Chú ý sự mất mát đào tạo giảm theo từng thời đại và tính chính xác đào tạo tăng lên theo từng thời đại. Điều này được mong đợi khi sử dụng tối ưu hóa giảm dần độ dốc — nó sẽ giảm thiểu số lượng mong muốn trên mỗi lần lặp.
Chính quy đồ thị
Bây giờ chúng tôi đã sẵn sàng để thử chính quy đồ thị bằng cách sử dụng mô hình cơ sở mà chúng tôi đã xây dựng ở trên. Chúng tôi sẽ sử dụng GraphRegularization lớp wrapper framework cung cấp cho học thần kinh có cấu trúc để bọc các mô hình (bi-LSTM) cơ sở bao gồm đồ thị quy tắc. Các bước còn lại để huấn luyện và đánh giá mô hình đồ thị chính quy tương tự như các bước của mô hình cơ sở.
Tạo mô hình đồ thị chính quy
Để đánh giá lợi ích gia tăng của việc chính quy hóa đồ thị, chúng tôi sẽ tạo một phiên bản mô hình cơ sở mới. Điều này là do model đã được đào tạo trong một vài lần lặp lại, và tái sử dụng mô hình đào tạo này để tạo ra một mô hình đồ thị regularized sẽ không so sánh công bằng cho model .
# Build a new base LSTM model.
base_reg_model = make_bilstm_model()
# Wrap the base model with graph regularization.
graph_reg_config = nsl.configs.make_graph_reg_config(
max_neighbors=HPARAMS.num_neighbors,
multiplier=HPARAMS.graph_regularization_multiplier,
distance_type=HPARAMS.distance_type,
sum_over_axis=-1)
graph_reg_model = nsl.keras.GraphRegularization(base_reg_model,
graph_reg_config)
graph_reg_model.compile(
optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Đào tạo mô hình
graph_reg_history = graph_reg_model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=HPARAMS.train_epochs,
verbose=1)
Epoch 1/10
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/tensorflow/python/framework/indexed_slices.py:446: UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape_1:0", shape=(None,), dtype=int32), values=Tensor("gradient_tape/GraphRegularization/graph_loss/Reshape:0", shape=(None, 1), dtype=float32), dense_shape=Tensor("gradient_tape/GraphRegularization/graph_loss/Cast:0", shape=(2,), dtype=int32))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
"shape. This may consume a large amount of memory." % value)
21/21 [==============================] - 28s 1s/step - loss: 0.6928 - accuracy: 0.5131 - scaled_graph_loss: 4.3840e-05 - val_loss: 0.6923 - val_accuracy: 0.4997
Epoch 2/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6852 - accuracy: 0.5158 - scaled_graph_loss: 0.0021 - val_loss: 0.6818 - val_accuracy: 0.4996
Epoch 3/10
21/21 [==============================] - 19s 939ms/step - loss: 0.6698 - accuracy: 0.5123 - scaled_graph_loss: 0.0021 - val_loss: 0.6534 - val_accuracy: 0.5001
Epoch 4/10
21/21 [==============================] - 20s 959ms/step - loss: 0.6194 - accuracy: 0.6285 - scaled_graph_loss: 0.0284 - val_loss: 0.5297 - val_accuracy: 0.7955
Epoch 5/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5805 - accuracy: 0.7346 - scaled_graph_loss: 0.0545 - val_loss: 0.5601 - val_accuracy: 0.6349
Epoch 6/10
21/21 [==============================] - 19s 934ms/step - loss: 0.5509 - accuracy: 0.7662 - scaled_graph_loss: 0.0654 - val_loss: 0.4899 - val_accuracy: 0.7538
Epoch 7/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5326 - accuracy: 0.7877 - scaled_graph_loss: 0.0701 - val_loss: 0.4395 - val_accuracy: 0.7923
Epoch 8/10
21/21 [==============================] - 20s 940ms/step - loss: 0.5157 - accuracy: 0.8258 - scaled_graph_loss: 0.0811 - val_loss: 0.4585 - val_accuracy: 0.7909
Epoch 9/10
21/21 [==============================] - 19s 937ms/step - loss: 0.5063 - accuracy: 0.8388 - scaled_graph_loss: 0.0868 - val_loss: 0.4272 - val_accuracy: 0.8433
Epoch 10/10
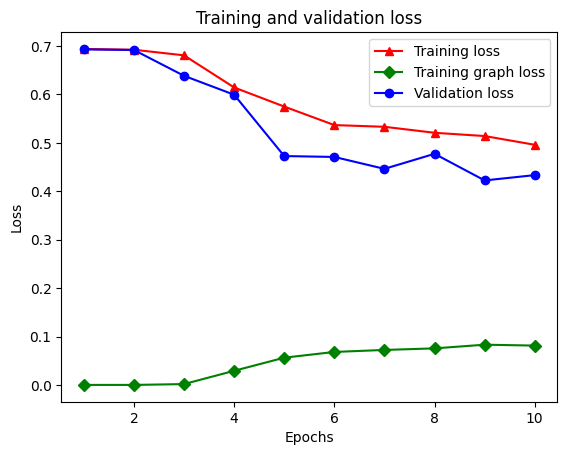
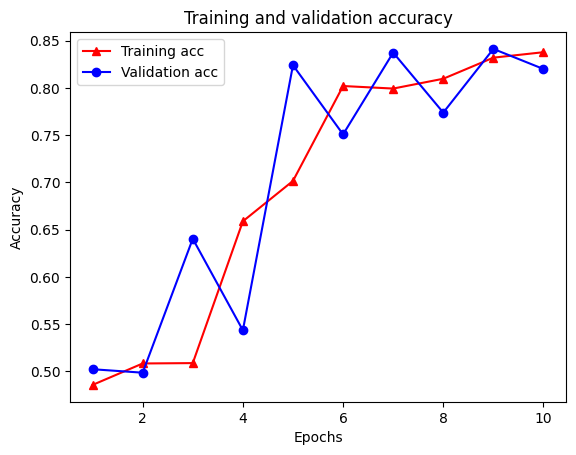
21/21 [==============================] - 19s 934ms/step - loss: 0.5053 - accuracy: 0.8438 - scaled_graph_loss: 0.0858 - val_loss: 0.4485 - val_accuracy: 0.7680
Đánh giá mô hình
graph_reg_results = graph_reg_model.evaluate(test_dataset, steps=HPARAMS.eval_steps)
print(graph_reg_results)
196/196 [==============================] - 16s 76ms/step - loss: 0.4890 - accuracy: 0.7246 [0.4889770448207855, 0.7246000170707703]
Tạo biểu đồ về độ chính xác / mất mát theo thời gian
graph_reg_history_dict = graph_reg_history.history
graph_reg_history_dict.keys()
dict_keys(['loss', 'accuracy', 'scaled_graph_loss', 'val_loss', 'val_accuracy'])
Tổng cộng có năm mục nhập trong từ điển: mất quá trình huấn luyện, độ chính xác trong quá trình huấn luyện, mất đồ thị huấn luyện, mất xác thực và độ chính xác xác thực. Chúng ta có thể vẽ tất cả chúng lại với nhau để so sánh. Lưu ý rằng sự mất mát của đồ thị chỉ được tính toán trong quá trình đào tạo.
acc = graph_reg_history_dict['accuracy']
val_acc = graph_reg_history_dict['val_accuracy']
loss = graph_reg_history_dict['loss']
graph_loss = graph_reg_history_dict['scaled_graph_loss']
val_loss = graph_reg_history_dict['val_loss']
epochs = range(1, len(acc) + 1)
plt.clf() # clear figure
# "-r^" is for solid red line with triangle markers.
plt.plot(epochs, loss, '-r^', label='Training loss')
# "-gD" is for solid green line with diamond markers.
plt.plot(epochs, graph_loss, '-gD', label='Training graph loss')
# "-b0" is for solid blue line with circle markers.
plt.plot(epochs, val_loss, '-bo', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc='best')
plt.show()
plt.clf() # clear figure
plt.plot(epochs, acc, '-r^', label='Training acc')
plt.plot(epochs, val_acc, '-bo', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='best')
plt.show()
Sức mạnh của học tập bán giám sát
Học tập bán giám sát và cụ thể hơn, chính quy hóa đồ thị trong ngữ cảnh của hướng dẫn này, có thể thực sự mạnh mẽ khi lượng dữ liệu đào tạo nhỏ. Việc thiếu dữ liệu đào tạo được bù đắp bằng cách tận dụng sự tương đồng giữa các mẫu đào tạo, điều không thể thực hiện được trong học tập có giám sát truyền thống.
Chúng tôi xác định tỷ lệ giám sát như tỷ lệ đào tạo mẫu với tổng số lượng mẫu trong đó bao gồm đào tạo, xác nhận, và các mẫu thử nghiệm. Trong sổ tay này, chúng tôi đã sử dụng tỷ lệ giám sát 0,05 (tức là 5% dữ liệu được gắn nhãn) để đào tạo cả mô hình cơ sở cũng như mô hình điều chỉnh bằng đồ thị. Chúng tôi minh họa tác động của tỷ lệ giám sát đến độ chính xác của mô hình trong ô bên dưới.
# Accuracy values for both the Bi-LSTM model and the feed forward NN model have
# been precomputed for the following supervision ratios.
supervision_ratios = [0.3, 0.15, 0.05, 0.03, 0.02, 0.01, 0.005]
model_tags = ['Bi-LSTM model', 'Feed Forward NN model']
base_model_accs = [[84, 84, 83, 80, 65, 52, 50], [87, 86, 76, 74, 67, 52, 51]]
graph_reg_model_accs = [[84, 84, 83, 83, 65, 63, 50],
[87, 86, 80, 75, 67, 52, 50]]
plt.clf() # clear figure
fig, axes = plt.subplots(1, 2)
fig.set_size_inches((12, 5))
for ax, model_tag, base_model_acc, graph_reg_model_acc in zip(
axes, model_tags, base_model_accs, graph_reg_model_accs):
# "-r^" is for solid red line with triangle markers.
ax.plot(base_model_acc, '-r^', label='Base model')
# "-gD" is for solid green line with diamond markers.
ax.plot(graph_reg_model_acc, '-gD', label='Graph-regularized model')
ax.set_title(model_tag)
ax.set_xlabel('Supervision ratio')
ax.set_ylabel('Accuracy(%)')
ax.set_ylim((25, 100))
ax.set_xticks(range(len(supervision_ratios)))
ax.set_xticklabels(supervision_ratios)
ax.legend(loc='best')
plt.show()
<Figure size 432x288 with 0 Axes>
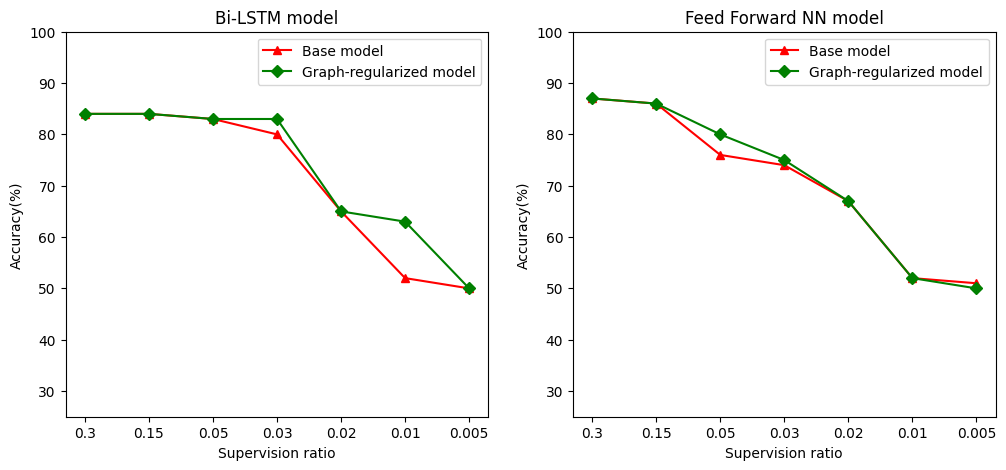
Có thể quan sát thấy rằng khi tỷ lệ giám sát giảm, độ chính xác của mô hình cũng giảm theo. Điều này đúng cho cả mô hình cơ sở và mô hình điều chỉnh bằng đồ thị, bất kể kiến trúc mô hình được sử dụng. Tuy nhiên, lưu ý rằng mô hình điều chỉnh bằng đồ thị hoạt động tốt hơn mô hình cơ sở cho cả hai kiến trúc. Đặc biệt, đối với mô hình Bi-LSTM, khi tỷ lệ giám sát là 0,01, tính chính xác của mô hình đồ thị regularized là ~ cao hơn so với các mô hình cơ sở 20%. Điều này chủ yếu là do học bán giám sát đối với mô hình đồ thị chính quy, trong đó sự tương đồng về cấu trúc giữa các mẫu đào tạo được sử dụng ngoài chính các mẫu đào tạo.
Sự kết luận
Chúng tôi đã chứng minh việc sử dụng chính quy đồ thị bằng cách sử dụng khung Học tập có cấu trúc thần kinh (NSL) ngay cả khi đầu vào không chứa đồ thị rõ ràng. Chúng tôi đã xem xét nhiệm vụ phân loại tình cảm của các bài đánh giá phim IMDB mà chúng tôi đã tổng hợp một biểu đồ tương tự dựa trên các lần nhúng bài đánh giá. Chúng tôi khuyến khích người dùng thử nghiệm thêm bằng các siêu tham số khác nhau, số lượng giám sát và bằng cách sử dụng các kiến trúc mô hình khác nhau.