
Il Neural Structured Learning (NSL) si concentra sull'addestramento delle reti neurali profonde sfruttando i segnali strutturati (se disponibili) insieme agli input delle funzionalità. Come introdotto da Bui et al. (WSDM'18) , questi segnali strutturati vengono utilizzati per regolarizzare l'addestramento di una rete neurale, costringendo il modello ad apprendere previsioni accurate (minimizzando la perdita supervisionata), mantenendo allo stesso tempo la somiglianza strutturale dell'input (minimizzando la perdita del vicino , vedere la figura seguente). Questa tecnica è generica e può essere applicata su architetture neurali arbitrarie (come NN feed-forward, NN convoluzionali e NN ricorrenti).
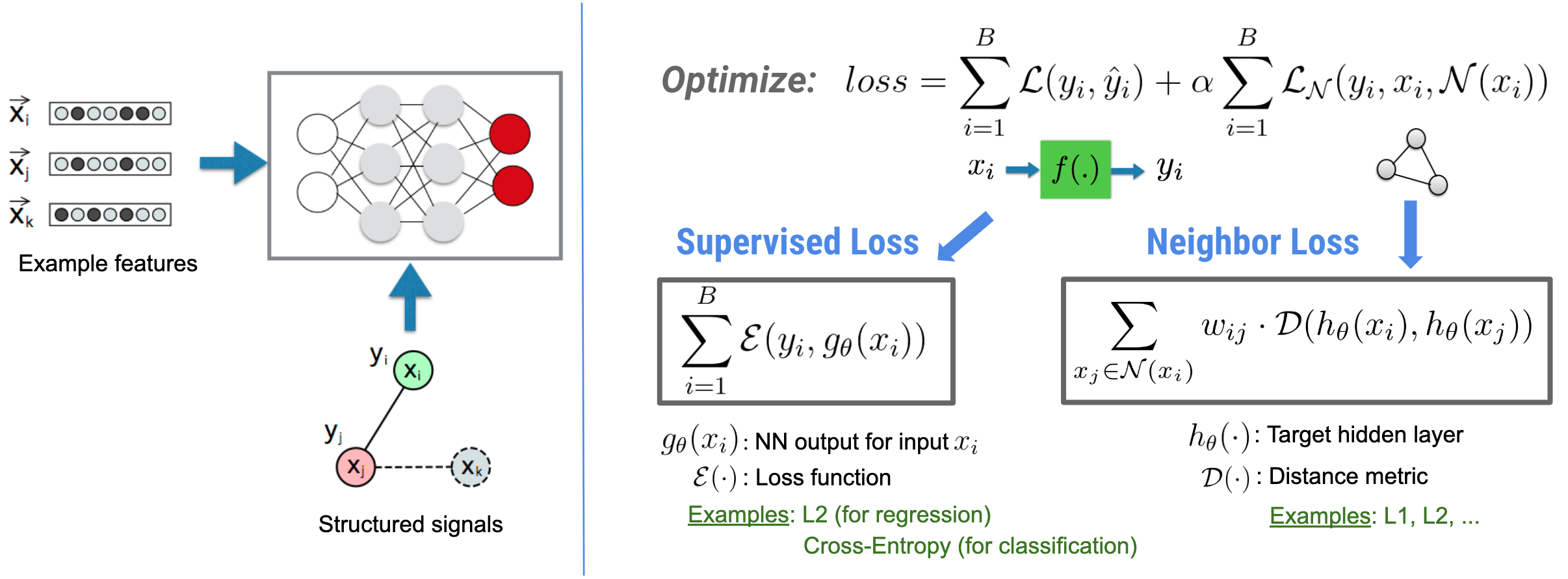
Si noti che l'equazione generalizzata della perdita del vicino è flessibile e può avere altre forme oltre a quella illustrata sopra. Ad esempio, possiamo anche selezionare\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) essere la perdita del vicino, che calcola la distanza tra la verità fondamentale \(y_i\)e la previsione del vicino \(g_\theta(x_j)\). Questo è comunemente usato nell'apprendimento contraddittorio (Goodfellow et al., ICLR'15) . Pertanto, NSL si generalizza al Neural Graph Learning se i vicini sono esplicitamente rappresentati da un grafico e all'Adversarial Learning se i vicini sono implicitamente indotti dalla perturbazione dell'avversario.
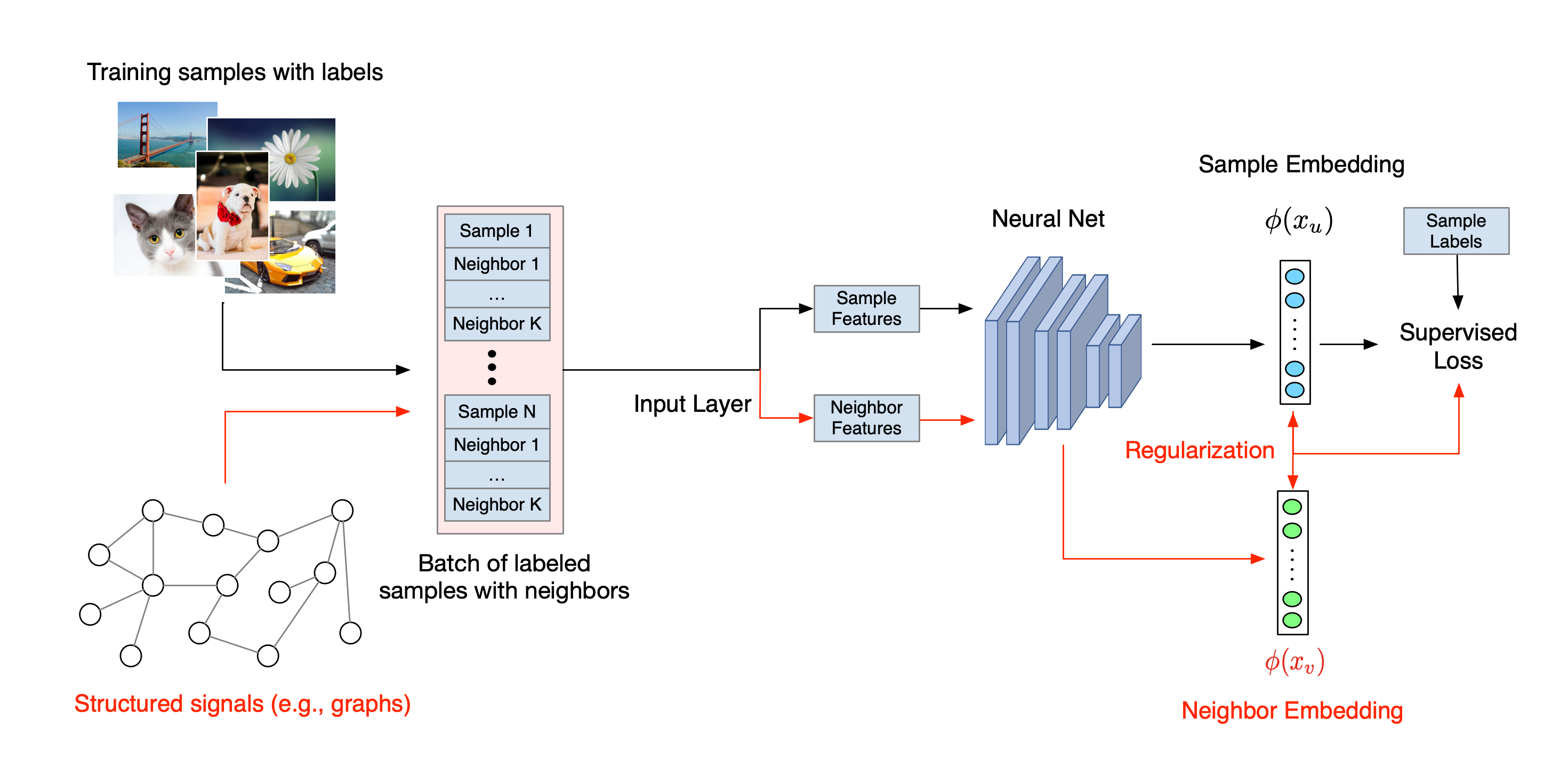
Il flusso di lavoro generale per l'apprendimento strutturato neurale è illustrato di seguito. Le frecce nere rappresentano il flusso di lavoro di formazione convenzionale e le frecce rosse rappresentano il nuovo flusso di lavoro introdotto da NSL per sfruttare i segnali strutturati. Innanzitutto, i campioni di addestramento vengono aumentati per includere segnali strutturati. Quando i segnali strutturati non vengono forniti esplicitamente, possono essere costruiti o indotti (quest'ultimo si applica all'apprendimento contraddittorio). Successivamente, i campioni di addestramento aumentati (compresi sia i campioni originali che i loro vicini corrispondenti) vengono inviati alla rete neurale per calcolare i loro incorporamenti. La distanza tra l'inclusione di un campione e l'inclusione del vicino viene calcolata e utilizzata come perdita del vicino, che viene trattata come un termine di regolarizzazione e aggiunta alla perdita finale. Per la regolarizzazione esplicita basata sui vicini, in genere calcoliamo la perdita dei vicini come la distanza tra l'inclusione del campione e l'inclusione del vicino. Tuttavia, qualsiasi livello della rete neurale può essere utilizzato per calcolare la perdita del vicino. D'altra parte, per la regolarizzazione indotta basata sul vicino (conflittuale), calcoliamo la perdita del vicino come la distanza tra la previsione di output del vicino contraddittorio indotto e l'etichetta di verità di base.
Perché utilizzare la NSL?
NSL porta i seguenti vantaggi:
- Maggiore precisione : i segnali strutturati tra i campioni possono fornire informazioni che non sono sempre disponibili negli input delle funzionalità; pertanto, è stato dimostrato che l'approccio di formazione congiunta (con segnali strutturati e funzionalità) supera molti metodi esistenti (che si basano solo sulla formazione con funzionalità) su un'ampia gamma di compiti, come la classificazione dei documenti e la classificazione degli intenti semantici ( Bui et al. ., WSDM'18 e Kipf et al., ICLR'17 ).
- Robustezza : i modelli addestrati con esempi contraddittori hanno dimostrato di essere robusti contro le perturbazioni contraddittorie progettate per fuorviare la previsione o la classificazione di un modello ( Goodfellow et al., ICLR'15 e Miyato et al., ICLR'16 ). Quando il numero di campioni di addestramento è piccolo, l'addestramento con esempi contraddittori aiuta anche a migliorare l'accuratezza del modello ( Tsipras et al., ICLR'19 ).
- Sono necessari meno dati etichettati : NSL consente alle reti neurali di sfruttare sia dati etichettati che non etichettati, estendendo il paradigma di apprendimento all'apprendimento semi-supervisionato . Nello specifico, NSL consente alla rete di addestrarsi utilizzando dati etichettati come nell'ambiente supervisionato e allo stesso tempo guida la rete ad apprendere rappresentazioni nascoste simili per i "campioni vicini" che possono o meno avere etichette. Questa tecnica si è rivelata molto promettente per migliorare l'accuratezza del modello quando la quantità di dati etichettati è relativamente piccola ( Bui et al., WSDM'18 e Miyato et al., ICLR'16 ).
Tutorial passo dopo passo
Per acquisire esperienza pratica con l'apprendimento strutturato neurale, disponiamo di tutorial che coprono vari scenari in cui i segnali strutturati possono essere dati, costruiti o indotti esplicitamente. Eccone alcuni:
Regolarizzazione dei grafici per la classificazione dei documenti utilizzando grafici naturali . In questo tutorial esploreremo l'uso della regolarizzazione dei grafici per classificare i documenti che formano un grafico naturale (organico).
Regolarizzazione del grafico per la classificazione del sentiment utilizzando grafici sintetizzati . In questo tutorial, dimostriamo l'uso della regolarizzazione del grafico per classificare i sentimenti di recensione dei film costruendo (sintetizzando) segnali strutturati.
Apprendimento contraddittorio per la classificazione delle immagini . In questo tutorial esploriamo l'uso dell'apprendimento contraddittorio (dove vengono indotti segnali strutturati) per classificare immagini contenenti cifre numeriche.
Ulteriori esempi ed esercitazioni possono essere trovati nella directory degli esempi del nostro repository GitHub.