
ニューラル構造化学習(NSL)は、構造化シグナル(利用可能な場合)を特徴入力と共に活用してディープニューラルネットワークをトレーニングすることに焦点を当てています。Bui et al.(WSDM'18)が紹介しているように、これらの構造化された信号をニューラルネットワークのトレーニングを正則化するために使用し、(教師あり損失を最小化することで)モデルに正確な予測値を学習させると同時に、(近傍損失を最小化することで)入力の構造的類似性を維持します(下の図をご覧ください)。これは一般的な手法であり、任意のニューラルアーキテクチャ(フィードフォワード NN、畳み込み NN、再帰型 NN など)に適用することができます。
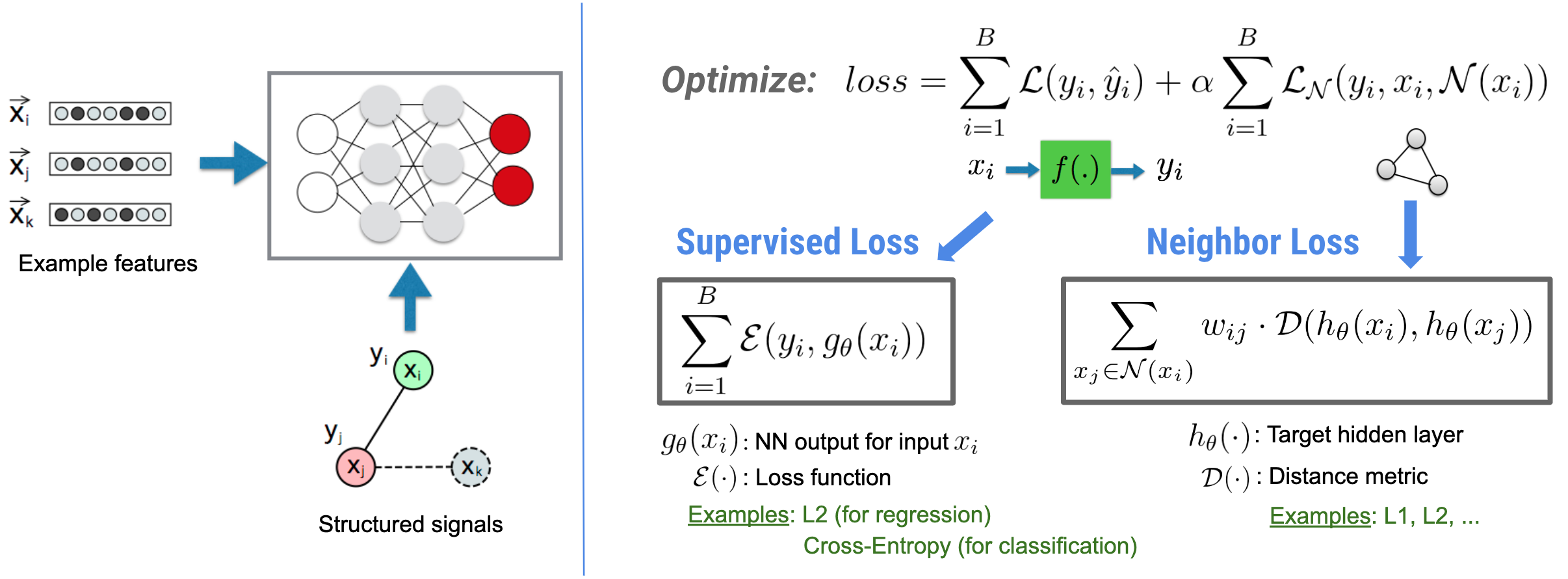
一般化された近傍損失の方程式には柔軟性があり、上で示した以外の形をとることができるので、注意が必要です。例えば、近傍損失に \(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) を選択して、真の正解 \($y_i\) と近傍 \(\)g_\theta(x_j)\(\) からの予測値との間の距離を計算することも可能です。これは敵対的学習でよく使用されています(Goodfellow et al., ICLR'15)。つまり NSL は、近傍が明示的にグラフで表現されている場合はニューラルグラフ学習に、近傍が暗黙的に敵対的摂動で誘導されている場合は敵対的学習に一般化します。
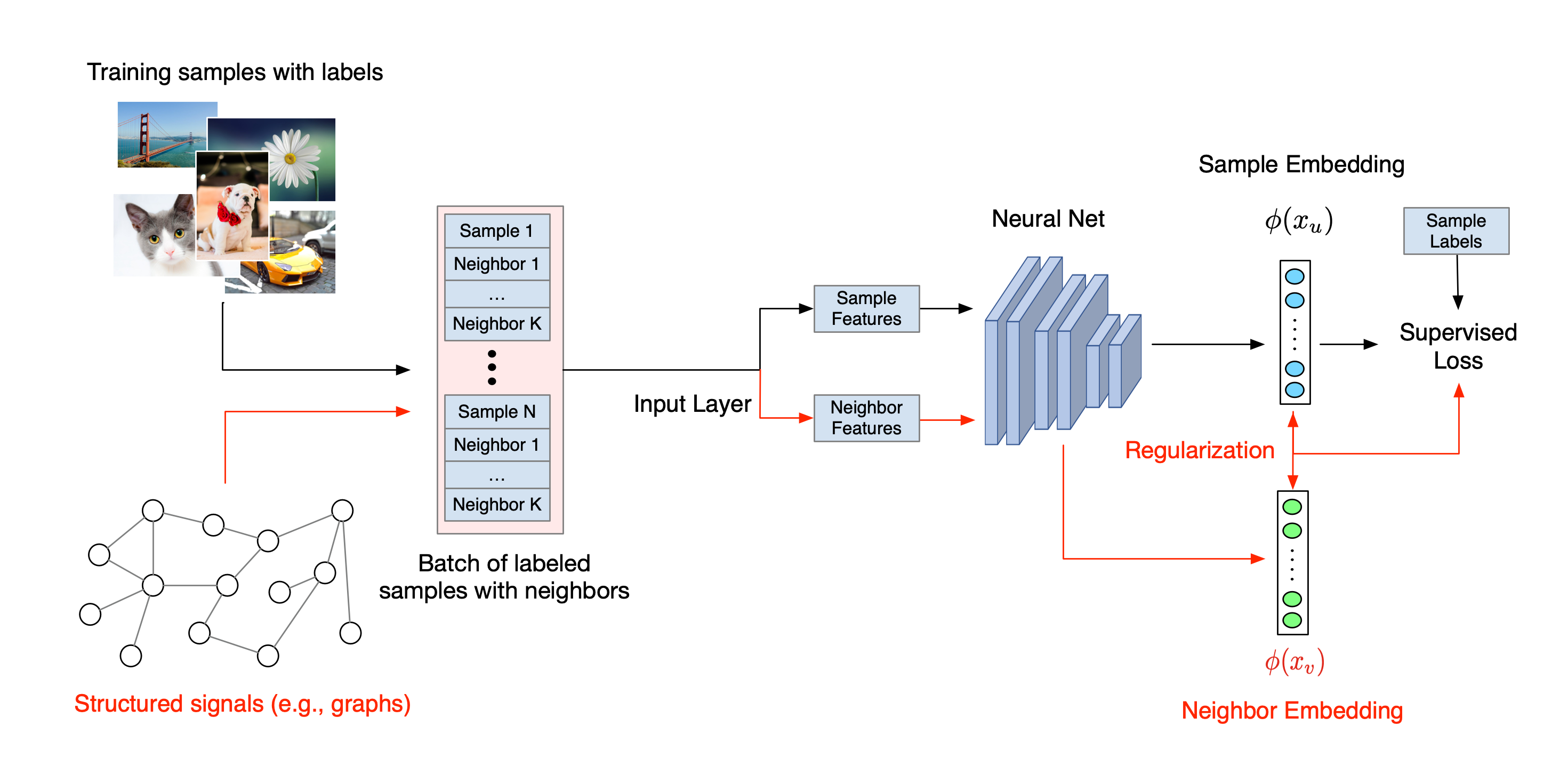
ニューラル構造化学習の全体的なワークフローを以下に示します。黒い矢印は従来のトレーニングワークフロー、赤い矢印は構造化された信号を活用するために NSL が導入した新しいワークフローを示しています。まず、トレーニングサンプルを増強して構造化された信号が含まれるようにします。構造化された信号が明示的に提供されない場合は、信号が構築されているか誘導されている可能性があります(誘導された信号は敵対的学習に適用されます)。次に、増強されたトレーニングサンプル(元のサンプルとそれに対応する近傍サンプルの両方を含む)をニューラルネットワークに供給して、それらの埋め込みを計算します。サンプル埋め込みと近傍埋め込みの間の距離を計算して近傍損失として使用し、これが正則化項とみなされて最終的な損失に加算されます。通常、近傍ベースの明示的な正則化には、サンプル埋め込みと近傍埋め込み間の距離で近傍損失を計算します。ただし、近傍損失の計算にはニューラルネットワークのどのレイヤーでも使用できます。一方、誘導された近傍ベースの正則化(敵対的)には、誘導された敵対的近傍の出力予測と真の正解ラベルとの間の距離で近傍損失を計算します。
NSL を選ぶ理由
NSL には以下のようなメリットがあります。
- 高精度: サンプル間で構造化された信号は、特徴入力で必ずしも利用できるとは限らない情報を提供することができます。したがって、結合トレーニングのアプローチ(構造化された信号と特徴の両方を使用するアプローチ)は、ドキュメント分類や意味的意図分類など広範囲のタスクにおいて、多くの(特徴のみを使用するトレーニングに依存した)既存の手法よりも優れていることが証明されています(Bui et al.、WSDM'18 および Kipf et al.、ICLR'17)。
- ロバスト性: 敵対的サンプルでトレーニングされたモデルは、モデルの予測や分類を誤認識させるように設計された敵対的摂動に対してロバストであることが証明されています(Goodfellow et al.、ICLR'15 & Miyato et al.、ICLR'16)。トレーニングサンプル数が少ない場合は、敵対的サンプルを用いたトレーニングもモデルの精度向上に有効です(Tsipras et al.、ICLR'19)。
- 最小限のラベル付きデータで機能: NSL は、ニューラルネットワークがラベル付きデータとラベルなしデータの両方を活用することを可能にし、学習パラダイムを半教師あり学習に拡張します。厳密には、NSL はラベル付きデータを用いて教師あり学習と同様のトレーニングを行い、それと同時にラベルの有無に関わらず「近傍サンプル」でも同様の隠れた表現を学習するようにネットワークを駆動します。この手法は、ラベル付けされたデータの量が比較的少ない場合のモデル精度向上に大いに貢献できることが証明されています(Bui et al.、WSDM'18 および Miyato et al.、ICLR'16)。
段階的なチュートリアル
ニューラル構造化学習の実戦経験を得られるよう、構造化シグナルが明示的に指定される場合、構築される場合、または誘導される場合など、さまざまなシナリオをカバーするチュートリアルを用意しています。以下にその一部を紹介します。
自然グラフを使用したドキュメント分類のためのグラフ正則化。このチュートリアルでは、自然な(有機的な)グラフを形成するドキュメントを分類するためのグラフ正則化の使用法について説明します。
合成グラフを使用した感情分類のためのグラフ正則化。このチュートリアルでは、構造化された信号を構築(合成)することによって、映画レビューの感情を分類するためのグラフ正則化の使用法について実証します。
画像分類のための敵対的学習。このチュートリアルでは、数字を含んだ画像を分類するための(構造化された信号が誘導される)敵対的学習の使用法について説明します。
その他の例やチュートリアルは、GitHub リポジトリの examples ディレクトリをご覧ください。