
न्यूरल स्ट्रक्चर्ड लर्निंग (एनएसएल) फीचर इनपुट के साथ संरचित संकेतों (जब उपलब्ध हो) का लाभ उठाकर गहरे तंत्रिका नेटवर्क को प्रशिक्षित करने पर केंद्रित है। जैसा कि बुई एट अल द्वारा प्रस्तुत किया गया है। (डब्लूएसडीएम'18) , इन संरचित संकेतों का उपयोग तंत्रिका नेटवर्क के प्रशिक्षण को नियमित करने के लिए किया जाता है, जिससे मॉडल को सटीक भविष्यवाणियां सीखने के लिए मजबूर किया जाता है (पर्यवेक्षित नुकसान को कम करके), जबकि साथ ही इनपुट संरचनात्मक समानता को बनाए रखा जाता है (पड़ोसी नुकसान को कम करके) , नीचे चित्र देखें)। यह तकनीक सामान्य है और इसे मनमाने तंत्रिका आर्किटेक्चर (जैसे फ़ीड-फ़ॉरवर्ड एनएन, कन्वेन्शनल एनएन और आवर्ती एनएन) पर लागू किया जा सकता है।
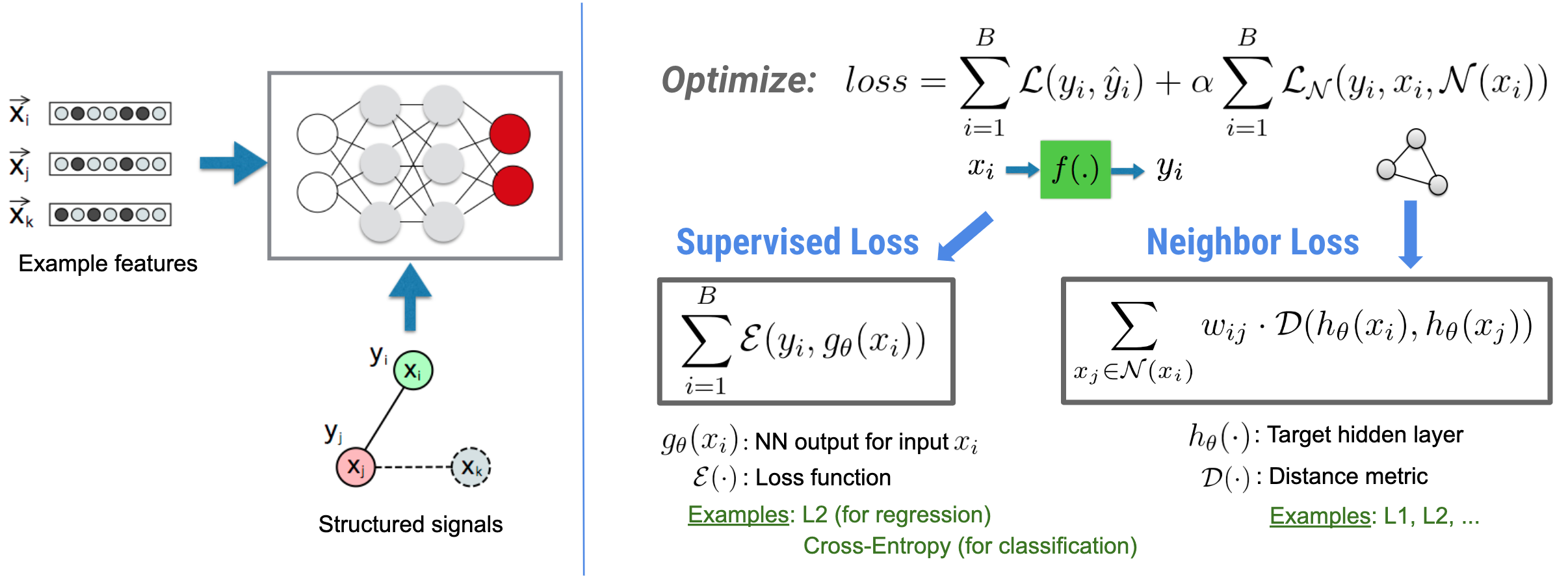
ध्यान दें कि सामान्यीकृत पड़ोसी हानि समीकरण लचीला है और ऊपर दिखाए गए के अलावा इसके अन्य रूप भी हो सकते हैं। उदाहरण के तौर पर हम चयन भी कर सकते हैं\(\sum_{x_j \in \mathcal{N}(x_i)}\mathcal{E}(y_i,g_\theta(x_j))\) पड़ोसी का नुकसान होना, जो जमीनी सच्चाई के बीच की दूरी की गणना करता है \(y_i\)और पड़ोसी से भविष्यवाणी \(g_\theta(x_j)\). इसका उपयोग आमतौर पर प्रतिकूल शिक्षा (गुडफेलो एट अल., आईसीएलआर'15) में किया जाता है। इसलिए, यदि पड़ोसियों को स्पष्ट रूप से एक ग्राफ द्वारा दर्शाया जाता है, तो एनएसएल न्यूरल ग्राफ लर्निंग को सामान्यीकृत करता है, और यदि पड़ोसियों को प्रतिकूल रूप से प्रतिकूल गड़बड़ी से प्रेरित किया जाता है, तो एडवरसैरियल लर्निंग को सामान्यीकृत किया जाता है।
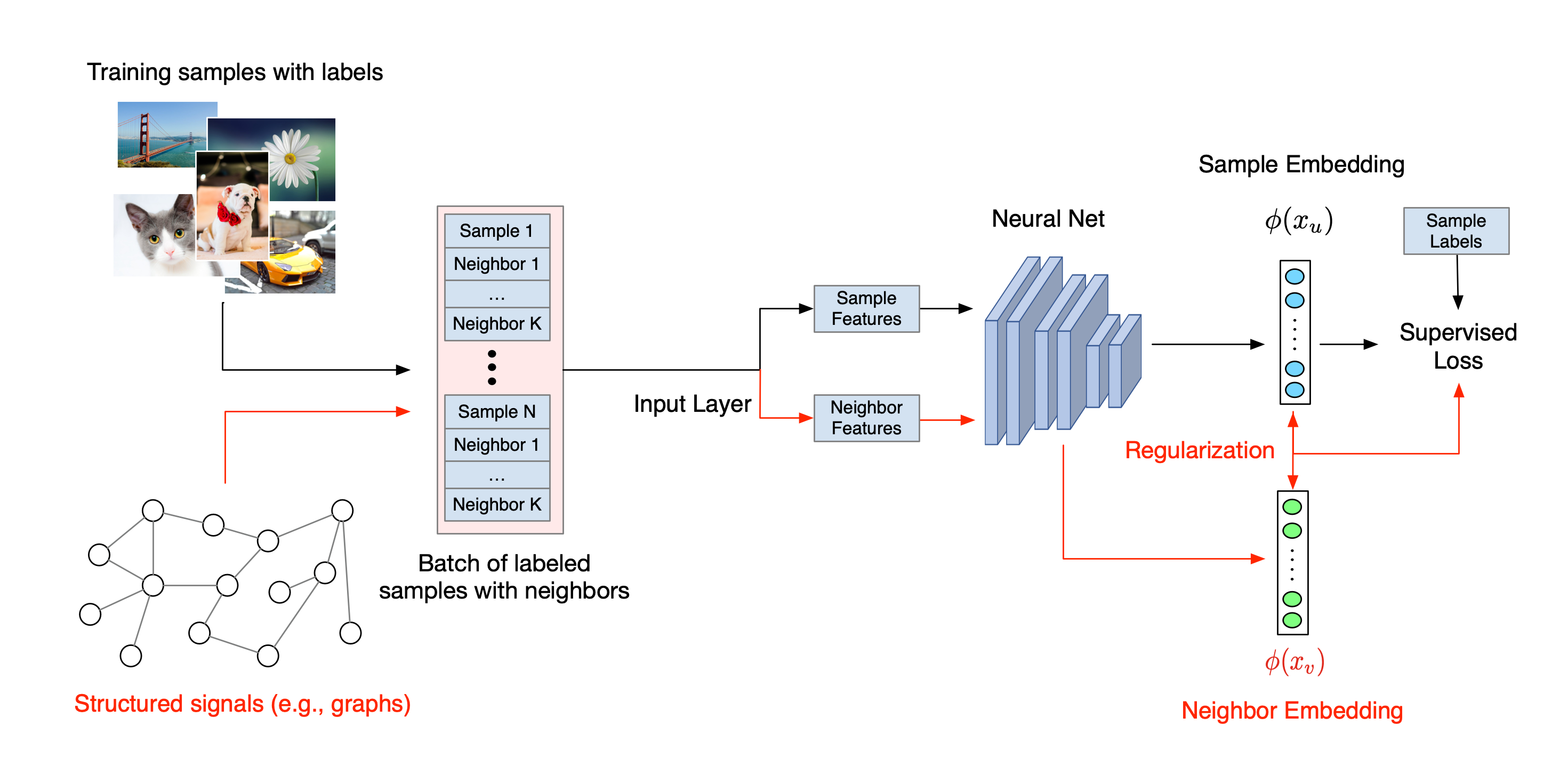
तंत्रिका संरचित शिक्षण के लिए समग्र कार्यप्रवाह नीचे दर्शाया गया है। काले तीर पारंपरिक प्रशिक्षण वर्कफ़्लो का प्रतिनिधित्व करते हैं और लाल तीर संरचित संकेतों का लाभ उठाने के लिए एनएसएल द्वारा शुरू किए गए नए वर्कफ़्लो का प्रतिनिधित्व करते हैं। सबसे पहले, संरचित संकेतों को शामिल करने के लिए प्रशिक्षण नमूनों को संवर्धित किया जाता है। जब संरचित संकेत स्पष्ट रूप से प्रदान नहीं किए जाते हैं, तो उन्हें या तो निर्मित या प्रेरित किया जा सकता है (बाद वाला प्रतिकूल शिक्षा पर लागू होता है)। इसके बाद, संवर्धित प्रशिक्षण नमूने (मूल नमूने और उनके संबंधित पड़ोसियों दोनों सहित) उनके एम्बेडिंग की गणना के लिए तंत्रिका नेटवर्क को खिलाए जाते हैं। एक नमूने की एम्बेडिंग और उसके पड़ोसी की एम्बेडिंग के बीच की दूरी की गणना की जाती है और पड़ोसी हानि के रूप में उपयोग किया जाता है, जिसे नियमितीकरण शब्द के रूप में माना जाता है और अंतिम हानि में जोड़ा जाता है। स्पष्ट पड़ोसी-आधारित नियमितीकरण के लिए, हम आम तौर पर नमूना के एम्बेडिंग और पड़ोसी के एम्बेडिंग के बीच की दूरी के रूप में पड़ोसी हानि की गणना करते हैं। हालाँकि, पड़ोसी नुकसान की गणना करने के लिए तंत्रिका नेटवर्क की किसी भी परत का उपयोग किया जा सकता है। दूसरी ओर, प्रेरित पड़ोसी-आधारित नियमितीकरण (प्रतिकूल) के लिए, हम पड़ोसी नुकसान की गणना प्रेरित प्रतिकूल पड़ोसी के आउटपुट पूर्वानुमान और जमीनी सच्चाई लेबल के बीच की दूरी के रूप में करते हैं।
एनएसएल का उपयोग क्यों करें?
एनएसएल निम्नलिखित लाभ लाता है:
- उच्च सटीकता : नमूनों के बीच संरचित सिग्नल ऐसी जानकारी प्रदान कर सकते हैं जो हमेशा फीचर इनपुट में उपलब्ध नहीं होती है; इसलिए, संयुक्त प्रशिक्षण दृष्टिकोण (संरचित संकेतों और सुविधाओं दोनों के साथ) को कई मौजूदा तरीकों (जो केवल सुविधाओं के साथ प्रशिक्षण पर निर्भर हैं) को कार्यों की एक विस्तृत श्रृंखला, जैसे दस्तावेज़ वर्गीकरण और सिमेंटिक इरादे वर्गीकरण ( बुई एट अल) पर बेहतर प्रदर्शन करने के लिए दिखाया गया है। ., WSDM'18 और Kipf एट अल., ICLR'17 ).
- मजबूती : प्रतिकूल उदाहरणों के साथ प्रशिक्षित मॉडल को किसी मॉडल की भविष्यवाणी या वर्गीकरण को गुमराह करने के लिए डिज़ाइन की गई प्रतिकूल गड़बड़ी के खिलाफ मजबूत दिखाया गया है ( गुडफेलो एट अल., आईसीएलआर'15 और मियाटो एट अल., आईसीएलआर'16 )। जब प्रशिक्षण नमूनों की संख्या छोटी होती है, तो प्रतिकूल उदाहरणों के साथ प्रशिक्षण भी मॉडल सटीकता में सुधार करने में मदद करता है ( सिप्रास एट अल।, आईसीएलआर'19 )।
- कम लेबल वाले डेटा की आवश्यकता : एनएसएल तंत्रिका नेटवर्क को लेबल किए गए और बिना लेबल वाले दोनों डेटा का उपयोग करने में सक्षम बनाता है, जो सीखने के प्रतिमान को अर्ध-पर्यवेक्षित शिक्षण तक विस्तारित करता है। विशेष रूप से, एनएसएल नेटवर्क को पर्यवेक्षित सेटिंग के अनुसार लेबल किए गए डेटा का उपयोग करके प्रशिक्षित करने की अनुमति देता है, और साथ ही नेटवर्क को "पड़ोसी नमूनों" के लिए समान छिपे हुए अभ्यावेदन को सीखने के लिए प्रेरित करता है जिनमें लेबल हो भी सकते हैं और नहीं भी। जब लेबल किए गए डेटा की मात्रा अपेक्षाकृत कम होती है ( बुई एट अल., डब्लूएसडीएम'18 और मियाटो एट अल., आईसीएलआर'16 ) तो इस तकनीक ने मॉडल सटीकता में सुधार करने का बड़ा वादा दिखाया है।
चरण-दर-चरण ट्यूटोरियल
तंत्रिका संरचित शिक्षण के साथ व्यावहारिक अनुभव प्राप्त करने के लिए, हमारे पास ऐसे ट्यूटोरियल हैं जो विभिन्न परिदृश्यों को कवर करते हैं जहां संरचित संकेत स्पष्ट रूप से दिए जा सकते हैं, निर्मित किए जा सकते हैं या प्रेरित किए जा सकते हैं। यहाँ कुछ हैं:
प्राकृतिक ग्राफ़ का उपयोग करके दस्तावेज़ वर्गीकरण के लिए ग्राफ़ नियमितीकरण । इस ट्यूटोरियल में, हम प्राकृतिक (जैविक) ग्राफ़ बनाने वाले दस्तावेज़ों को वर्गीकृत करने के लिए ग्राफ़ नियमितीकरण के उपयोग का पता लगाते हैं।
संश्लेषित ग्राफ़ का उपयोग करके भावना वर्गीकरण के लिए ग्राफ़ नियमितीकरण । इस ट्यूटोरियल में, हम संरचित संकेतों का निर्माण (संश्लेषण) करके फिल्म समीक्षा भावनाओं को वर्गीकृत करने के लिए ग्राफ़ नियमितीकरण के उपयोग को प्रदर्शित करते हैं।
छवि वर्गीकरण के लिए प्रतिकूल शिक्षा । इस ट्यूटोरियल में, हम संख्यात्मक अंकों वाली छवियों को वर्गीकृत करने के लिए प्रतिकूल शिक्षा (जहां संरचित संकेत प्रेरित होते हैं) के उपयोग का पता लगाते हैं।
अधिक उदाहरण और ट्यूटोरियल हमारे GitHub रिपॉजिटरी की उदाहरण निर्देशिका में पाए जा सकते हैं।