
 GitHub에서 소스보기 GitHub에서 소스보기 |
개요
TensorFlow Lite는 이제 TensorFlow에서 TensorFlow Lite의 flat buffer 형식으로 모델을 변환하는 동안 가중치를 16bit 부동 소수점 값으로 변환하는 것을 지원합니다. 그 결과 모델 크기가 2배 감소합니다. GPU와 같은 일부 하드웨어는 감소한 정밀도 산술로 기본적으로 계산할 수 있으므로 기존 부동 소수점 실행보다 속도가 향상됩니다. Tensorflow Lite GPU 대리자는 이러한 방식으로 실행되도록 구성될 수 있습니다. 그러나 float16 가중치로 변환된 모델은 추가 수정없이도 CPU에서 계속 실행될 수 있습니다. float16 가중치는 첫 번째 추론 이전에 float32로 업 샘플링됩니다. 이를 통해 지연 시간과 정확성에 미치는 영향을 최소화하는 대신 모델 크기를 크게 줄일 수 있습니다.
이 가이드에서는 MNIST 모델을 처음부터 훈련하고 TensorFlow에서 정확성을 확인한 다음 모델을 float16 양자화를 사용하여 Tensorflow Lite flatbuffer로 변환합니다. 마지막으로 변환된 모델의 정확성을 확인하고 원래 float32 모델과 비교합니다.
MNIST 모델 빌드하기
설정
import logging
logging.getLogger("tensorflow").setLevel(logging.DEBUG)
import tensorflow as tf
from tensorflow import keras
import numpy as np
import pathlib
2022-12-15 00:55:59.580016: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory 2022-12-15 00:55:59.580120: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory 2022-12-15 00:55:59.580130: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
모델 훈련 및 내보내기
# Load MNIST dataset
mnist = keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Normalize the input image so that each pixel value is between 0 to 1.
train_images = train_images / 255.0
test_images = test_images / 255.0
# Define the model architecture
model = keras.Sequential([
keras.layers.InputLayer(input_shape=(28, 28)),
keras.layers.Reshape(target_shape=(28, 28, 1)),
keras.layers.Conv2D(filters=12, kernel_size=(3, 3), activation=tf.nn.relu),
keras.layers.MaxPooling2D(pool_size=(2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
# Train the digit classification model
model.compile(optimizer='adam',
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_images,
train_labels,
epochs=1,
validation_data=(test_images, test_labels)
)
1875/1875 [==============================] - 9s 3ms/step - loss: 0.2901 - accuracy: 0.9197 - val_loss: 0.1384 - val_accuracy: 0.9614 <keras.callbacks.History at 0x7f9c1ccb6a90>
예를 들어, 단일 epoch에 대해서만 모델을 훈련시켰으므로 ~96% 정확성으로만 훈련합니다.
TensorFlow Lite 모델로 변환하기
TensorFlow Lite Converter를 사용하여 이제 훈련된 모델을 TensorFlow Lite 모델로 변환할 수 있습니다.
TFLiteConverter를 사용하여 모델을 로드합니다.
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op while saving (showing 1 of 1). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmpfs/tmp/tmp6lyb31lw/assets INFO:tensorflow:Assets written to: /tmpfs/tmp/tmp6lyb31lw/assets 2022-12-15 00:56:14.848472: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:362] Ignored output_format. 2022-12-15 00:56:14.848515: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:365] Ignored drop_control_dependency.
.tflite 파일에 작성합니다.
tflite_models_dir = pathlib.Path("/tmp/mnist_tflite_models/")
tflite_models_dir.mkdir(exist_ok=True, parents=True)
tflite_model_file = tflite_models_dir/"mnist_model.tflite"
tflite_model_file.write_bytes(tflite_model)
84820
대신 모델을 내보낼 때 float16으로 양자화하려면 먼저 기본 최적화를 사용하도록 optimizations 플래그를 지정합니다. 그런 다음 float16이 대상 플랫폼에서 지원되는 유형임을 지정합니다.
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_types = [tf.float16]
마지막으로 평소와 같이 모델을 변환합니다. 기본적으로 변환된 모델은 호출 편의를 위해 여전히 float 입력 및 출력을 사용합니다.
tflite_fp16_model = converter.convert()
tflite_model_fp16_file = tflite_models_dir/"mnist_model_quant_f16.tflite"
tflite_model_fp16_file.write_bytes(tflite_fp16_model)
WARNING:absl:Found untraced functions such as _jit_compiled_convolution_op while saving (showing 1 of 1). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpb6hmdxdl/assets INFO:tensorflow:Assets written to: /tmpfs/tmp/tmpb6hmdxdl/assets 2022-12-15 00:56:15.826625: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:362] Ignored output_format. 2022-12-15 00:56:15.826673: W tensorflow/compiler/mlir/lite/python/tf_tfl_flatbuffer_helpers.cc:365] Ignored drop_control_dependency. 44624
결과 파일이 약 1/2 크기인지 확인하세요.
ls -lh {tflite_models_dir}total 128K -rw-rw-r-- 1 kbuilder kbuilder 83K Dec 15 00:56 mnist_model.tflite -rw-rw-r-- 1 kbuilder kbuilder 44K Dec 15 00:56 mnist_model_quant_f16.tflite
TensorFlow Lite 모델 실행하기
Python TensorFlow Lite 인터프리터를 사용하여 TensorFlow Lite 모델을 실행합니다.
인터프리터에 모델 로드하기
interpreter = tf.lite.Interpreter(model_path=str(tflite_model_file))
interpreter.allocate_tensors()
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
interpreter_fp16 = tf.lite.Interpreter(model_path=str(tflite_model_fp16_file))
interpreter_fp16.allocate_tensors()
하나의 이미지에서 모델 테스트하기
test_image = np.expand_dims(test_images[0], axis=0).astype(np.float32)
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
interpreter.set_tensor(input_index, test_image)
interpreter.invoke()
predictions = interpreter.get_tensor(output_index)
import matplotlib.pylab as plt
plt.imshow(test_images[0])
template = "True:{true}, predicted:{predict}"
_ = plt.title(template.format(true= str(test_labels[0]),
predict=str(np.argmax(predictions[0]))))
plt.grid(False)
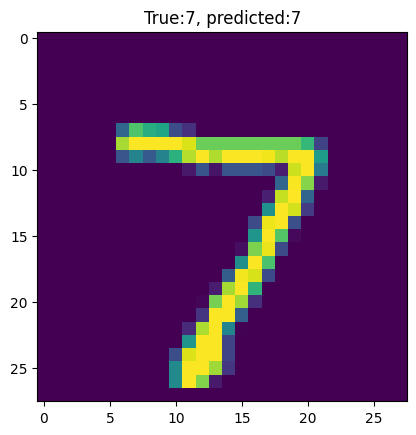
test_image = np.expand_dims(test_images[0], axis=0).astype(np.float32)
input_index = interpreter_fp16.get_input_details()[0]["index"]
output_index = interpreter_fp16.get_output_details()[0]["index"]
interpreter_fp16.set_tensor(input_index, test_image)
interpreter_fp16.invoke()
predictions = interpreter_fp16.get_tensor(output_index)
plt.imshow(test_images[0])
template = "True:{true}, predicted:{predict}"
_ = plt.title(template.format(true= str(test_labels[0]),
predict=str(np.argmax(predictions[0]))))
plt.grid(False)
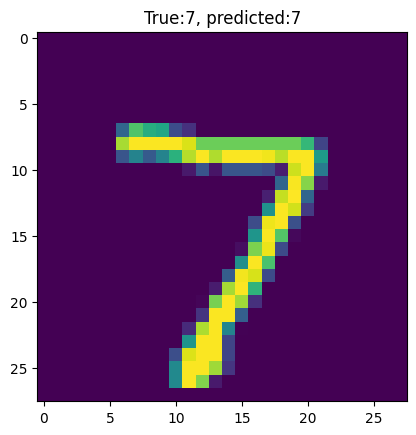
모델 평가하기
# A helper function to evaluate the TF Lite model using "test" dataset.
def evaluate_model(interpreter):
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
# Run predictions on every image in the "test" dataset.
prediction_digits = []
for test_image in test_images:
# Pre-processing: add batch dimension and convert to float32 to match with
# the model's input data format.
test_image = np.expand_dims(test_image, axis=0).astype(np.float32)
interpreter.set_tensor(input_index, test_image)
# Run inference.
interpreter.invoke()
# Post-processing: remove batch dimension and find the digit with highest
# probability.
output = interpreter.tensor(output_index)
digit = np.argmax(output()[0])
prediction_digits.append(digit)
# Compare prediction results with ground truth labels to calculate accuracy.
accurate_count = 0
for index in range(len(prediction_digits)):
if prediction_digits[index] == test_labels[index]:
accurate_count += 1
accuracy = accurate_count * 1.0 / len(prediction_digits)
return accuracy
print(evaluate_model(interpreter))
0.9614
float16 양자화된 모델에 대한 평가를 반복하여 다음을 얻습니다.
# NOTE: Colab runs on server CPUs. At the time of writing this, TensorFlow Lite
# doesn't have super optimized server CPU kernels. For this reason this may be
# slower than the above float interpreter. But for mobile CPUs, considerable
# speedup can be observed.
print(evaluate_model(interpreter_fp16))
0.9614
이 예에서는 정확성 차이가 없이 모델을 float16으로 양자화했습니다.
GPU에서 fp16 양자화 모델을 평가하는 것도 가능합니다. 감소된 정밀도 값으로 모든 산술을 수행하려면 다음과 같이 앱에서 TfLiteGPUDelegateOptions 구조체를 만들고 precision_loss_allowed를 1로 설정해야 합니다.
//Prepare GPU delegate.
const TfLiteGpuDelegateOptions options = {
.metadata = NULL,
.compile_options = {
.precision_loss_allowed = 1, // FP16
.preferred_gl_object_type = TFLITE_GL_OBJECT_TYPE_FASTEST,
.dynamic_batch_enabled = 0, // Not fully functional yet
},
};
TFLite GPU 대리자 및 애플리케이션에서 사용하는 방법에 대한 자세한 설명서는 여기에서 찾을 수 있습니다