

動画分類は、動画が表す内容を特定する機械学習タスクです。動画分類モデルは、さまざまなアクションや動きといった固有のクラスのセットを含む動画データセットに対してトレーニングされます。モデルは動画フレームを入力として受け取り、各クラスが動画で表示される確率を出力します。
動画分類モデルと画像分類モデルはいずれも、画像を入力として使用し、その画像が定義済みのクラスに属する確率を予測します。ただし、動画分類モデルは、隣接するフレームの間の空間と時間の関係も処理し、動画のアクションを認識します。
たとえば、動画行動認識モデルをトレーニングして、走る、拍手、手を振るといった人間の行動を特定できます。次の図は、Android での動画分類モデルの出力を示します。
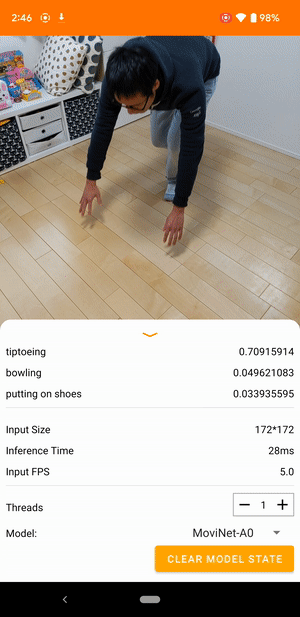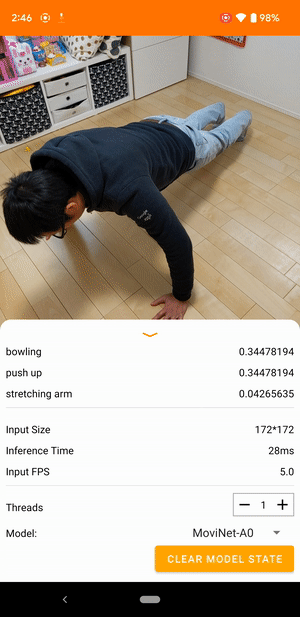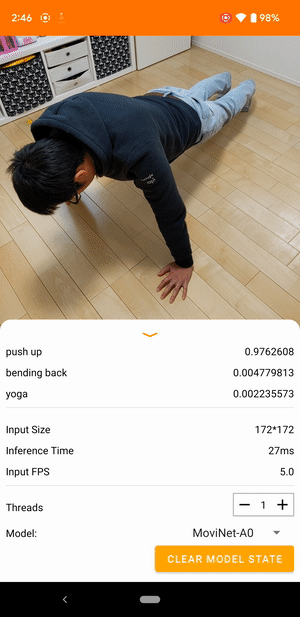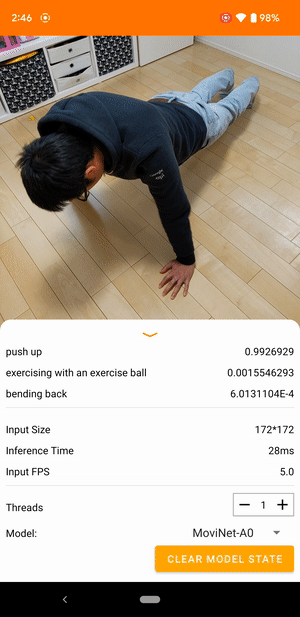
はじめに
Android または Raspberry Pi 以外のプラットフォームを使用している場合、あるいはすでに TensorFlow Lite API に慣れている場合は、スターター動画分類モデルと追加ファイルをダウンロードしてください。TensorFlow Lite Support Library を使用して、独自のカスタム推論パイプラインを構築することもできます。
TensorFlow Lite を初めて使用する場合、Android または Raspberry Pi を使用する場合は、以下のサンプルアプリをご覧ください。
Android
Android アプリケーションは、デバイスの背面カメラを使用して、連続的な動画分類を実行します。推論は、TensorFlow Lite Java API を使用して実行されます。デモアプリはフレームを分類し、予測された分類をリアルタイムで表示します。
Raspberry Pi
Raspberry Pi の例では、TensorFlow Lite と Python を使用して、連続動画分類を実行します。Raspberry Pi を Pi カメラなどのカメラに接続し、リアルタイムの動画分類を実行します。カメラから結果を表示するには、モニターを Raspberry Pi に接続し、SSH を使用して Pi シェルにアクセス (キーボードを Pi に接続しないようにするため) します。
最初に、Raspberry Pi OS (Buster への更新を推奨) の Raspberry Pi をセットアップします。
モデルの説明
Mobile Video Networks (MoViNets) は、モバイルデバイス向けに最適化された、効率的な動画分類モデルのファミリーです。MoViNets は、複数の大規模行動認識データセットに対して、最先端の精度と効率を実証し、動画行動認識タスクに適しています。
TensorFlow Lite 向けの MoviNet モデルには 3 つのバリアントがあります。MoviNet-A0、MoviNet-A1、MoviNet-A2 です。これらのバリアントは、Kinetics-600 データセットでトレーニングされ、600 の異なる人間の行動を認識します。MoviNet-A0 は最も小さく、最速ですが、最も精度が低いモデルです。MoviNet-A2 は最も大きく、最も低速ですが、最も精度が高いモデルです。MoviNet-A1 は A0 と A2 の中間です。
使い方
トレーニング中、動画分類モデルは、動画と関連付けられたラベルを提供します。各ラベルは、モデルが認識するように学習する固有の概念の名前またはクラスです。動画動認識では、動画は人間の行動の動画であり、ラベルは関連付けられた行動になります。
動画分類モデルは、新しい動画がトレーニング中に提供されたクラスに属するかどうかを予測します。このプロセスは推論と呼ばれます。転移学習で、既存のモデルを使用して、動画の新しいクラスを特定することもできます。
モデルはストリーミングモデルであり、リアルタイムで連続する動画を受け取り、応答します。モデルは動画ストリームを受け取るため、トレーニングデータセットのクラスが動画で表されているかどうかを特定します。モデルは、各フレームに対して、これらのクラスとクラスが動画に表示される確率を返します。特定の時間の出力例は、次のとおりです。
| 行動 | 確率 |
|---|---|
| スクウェアダンス | 0.02 |
| 針に糸を通す | 0.08 |
| 指で遊ぶ | 0.23 |
| 手を振る | 0.67 |
出力の各アクションは、トレーニングデータのラベルに対応します。確率は、行動が動画に表示される確率を示します。
モデル入力
モデルは、RGB 動画フレームのストリームを入力として受け取ります。入力動画のサイズは柔軟ですが、モデルトレーニング解像度とフレームレートに合わせることをお勧めします。
- MoviNet-A0: 172 x 172 (5 fps)
- MoviNet-A1: 172 x 172 (5 fps)
- MoviNet-A1: 224 x 224 (5 fps)
入力動画には、範囲 0 ~ 1 の色値があり、共通の画像入力 に従うことが想定されています。
内部的には、モデルは、前のフレームで収集された情報を使用して、各フレームのコンテキストを分析します。これは、モデル出力の内部状態を受け取り、それを予定されているフレームのモデルに入力することで、各フレームのコンテキストを分析します。
モデル出力
モデルは、一連のラベルと対応するスコアを返します。スコアは、各クラスの予測を表す logit 値です。ソフト関数 (tf.nn.softmax) を使用することで、これらのスコアを確率に変換できます。
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
内部的には、モデル出力には、モデルの内部状態が含まれ、予定されているフレームでモデルを入力することもできます。
パフォーマンスベンチマーク
パフォーマンスベンチマークの数値は、ベンチマークツールで生成されます。MoviNets は CPU のみをサポートしています。
モデルパフォーマンスは、モデルが特定のハードウェアの部分に対して推論を実行するためにかかった時間を計測します。値が低いほど、モデルが高速になります。精度は、モデルが正常にクラスを分類する頻度によって計測されます。
| モデル名 | サイズ | 精度 * | デバイス | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (整数量子化) | 3.1 MB | 65% | Pixel 4 | 5 ms |
| Pixel 3 | 11 ms | |||
| MoviNet-A1 (整数量子化) | 4.5 MB | 70% | Pixel 4 | 8 ms |
| Pixel 3 | 19 ms | |||
| MoviNet-A2 (整数量子化) | 5.1 MB | 72% | Pixel 4 | 15 ms |
| Pixel 3 | 36 ms |
- Kinetics-600 データセットで測定された Top-1 精度
** 1 スレッドの CPU で動作しているときに測定されたレイテンシ
モデルのカスタマイズ
事前トレーニング済みのモデルを学習し、Kinetics-600 データセットから 600 の人間の行動を認識します。転移学習を使用して、モデルを再トレーニングすると、元のデータセットにはない人間の行動を認識できます。このためには、モデルに取り込む新しい行動ごとに、トレーニング動画のセットが必要です。
カスタムデータに対するモデルの微調整の詳細については、MoViNets repo および MoViNets チュートリアル を参照してください。
その他の資料とリソース
このページでケネトウされた概念の詳細については、次のリソースを使用してください。