

오디오가 나타내는 것을 식별하는 작업을 오디오 분류라고 합니다. 오디오 분류 모델은 다양한 오디오 이벤트를 인식하도록 학습됩니다. 예를 들어 박수, 손가락 튕기기, 타이핑의 세 가지 이벤트를 나타내는 이벤트를 인식하도록 모델을 훈련할 수 있습니다. TensorFlow Lite는 모바일 애플리케이션에 배포할 수 있는 최적화된 사전 학습된 모델을 제공합니다. 여기에서 TensorFlow를 사용한 오디오 분류에 대해 자세히 알아보세요.
다음 이미지는 Android에서 오디오 분류 모델의 출력을 보여줍니다.
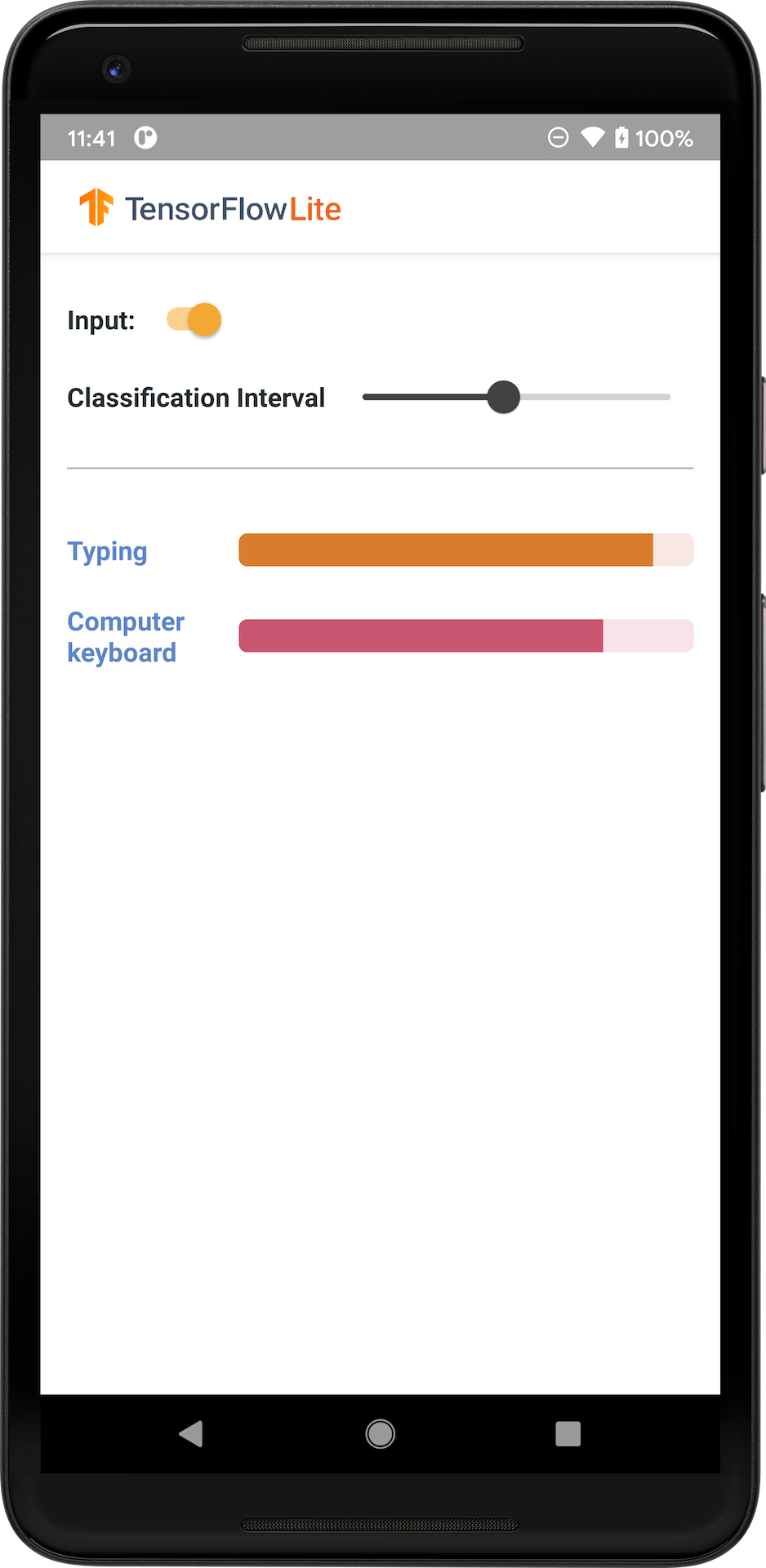
참고: (1) 기존 모델을 통합하려면 TensorFlow Lite 작업 라이브러리를 사용해 보세요. (2) 모델을 사용자 지정하려면 TensorFlow Lite 모델 제작기를 사용해 보세요.
시작하기
TensorFlow Lite를 처음 사용하고 Android로 작업하는 경우, 다음 예제 애플리케이션을 탐색하면 시작하는 데 도움이 됩니다.
TensorFlow Lite 작업 라이브러리의 기본 API를 활용하여 몇 줄의 코드로 오디오 분류 모델을 통합할 수 있습니다. TensorFlow Lite 지원 라이브러리를 사용하여 사용자 지정 추론 파이프라인을 구축할 수도 있습니다.
아래 Android 예제는 TFLite 작업 라이브러리를 사용한 구현을 보여줍니다.
Android/iOS 이외의 플랫폼을 사용 중이거나 이미 TensorFlow Lite API에 이미 익숙하다면 스타터 모델과 지원 파일(해당되는 경우)을 다운로드하세요.
모델 설명
YAMNet은 오디오 파형을 입력으로 사용하고 AudioSet 온톨로지에서 521개의 오디오 이벤트 각각에 대해 독립적인 예측을 수행하는 오디오 이벤트 분류기입니다. 이 모델은 MobileNet v1 아키텍처를 사용하고 AudioSet 말뭉치를 사용하여 훈련되었습니다. 이 모델은 원래 TensorFlow Model Garden에서 릴리스되었으며, 여기에 모델 소스 코드, 원래 모델 체크포인트 및 자세한 문서가 있습니다.
동작 원리
TFLite로 변환된 YAMNet 모델에는 두 가지 버전이 있습니다.
YAMNet은 전이 학습, 웹 및 모바일 배포에 적합한 동적 입력 크기의 독창적인 오디오 분류 모델입니다. 또한 더 복잡한 출력도 가지고 있습니다.
YAMNet/분류는 더 간단한 고정 길이 프레임 입력(15600개 샘플)을 가진 양자화된 버전이며 521개 오디오 이벤트 클래스에 대한 단일 점수 벡터를 반환합니다.
입력
이 모델은 [-1.0, +1.0] 범위의 모노 16kHz 샘플로 표시되는 0.975초 파형을 포함하는 길이 15600의 1차원 float32 텐서 또는 NumPy 배열을 허용합니다.
출력
이 모델은 YAMNet에서 지원하는 AudioSet 온톨로지의 521개 클래스 각각에 대한 예측 점수를 포함하는 형상(1, 521)의 2차원 float32 텐서를 반환합니다. 점수 텐서의 열 인덱스(0-520)는 YAMNet 클래스 맵을 사용하여 해당 AudioSet 클래스 이름에 매핑되며, 이는 모델 파일에 패킹된 관련 파일 yamnet_label_list.txt로 사용할 수 있습니다. 사용 방법은 아래를 참조하세요.
적합한 용도
YAMNet은 다음과 같이 사용할 수 있습니다.
- 다양한 오디오 이벤트에 걸쳐 합리적인 기준을 제공하는 독립형 오디오 이벤트 분류기로 사용됩니다.
- 고수준 특성 추출기: YAMNet의 1024-D 임베딩 출력은 다른 모델의 입력 특성으로 사용될 수 있으며, 이는 다시 특정 작업에 대해 소량의 데이터로 훈련할 수 있습니다. 이를 통해 레이블이 지정된 많은 데이터가 필요하지 않고 대규모 모델을 처음부터 끝까지 훈련하지 않고도 전문화된 오디오 분류기를 빠르게 생성할 수 있습니다.
- 웜 스타트로 사용됩니다. YAMNet 모델 매개변수는 보다 빠른 미세 조정과 모델 탐색을 가능하게 하는 더 큰 모델의 일부를 초기화하는 데 사용할 수 있습니다.
한계
- YAMNet의 분류기 출력은 클래스 간에 보정되지 않았으므로 출력을 확률로 직접 처리할 수 없습니다. 주어진 작업에 대해 적절한 클래스별 점수 임계값 및 척도를 할당할 수 있는 작업별 데이터로 보정을 수행해야 할 개연성이 매우 높습니다.
- YAMNet은 수백만 개의 YouTube 동영상에 대해 훈련되었으며 이러한 동영상은 매우 다양하지만 주어진 작업에 대해 예상되는 평균 YouTube 동영상과 오디오 입력 간에 여전히 도메인 불일치가 있을 수 있습니다. 구축하는 모든 시스템에서 YAMNet을 사용할 수 있도록 하려면 어느 정도의 미세 조정 및 보정을 수행해야 합니다.
모델 사용자 정의
제공된 사전 훈련된 모델은 521개의 서로 다른 오디오 클래스를 감지하도록 훈련되었습니다. 전체 클래스 목록은 모델 리포지토리의 레이블 파일을 참조하세요.
전이 학습이라고 하는 기술을 사용하여 원래 세트에 없는 클래스를 인식하도록 모델을 다시 훈련할 수 있습니다. 예를 들어, 여러 새 노래를 감지하도록 모델을 다시 훈련할 수 있습니다. 이렇게 하려면 훈련하려는 새 레이블 각각에 대한 훈련 오디오 세트가 필요합니다. 권장되는 방법은 몇 줄의 코드로 사용자 정의 데이터세트를 사용하여 TensorFlow Lite 모델을 학습시키는 프로세스를 단순화하는 TensorFlow Lite Model Maker 라이브러리를 사용하는 것입니다. 필요한 훈련 데이터의 양과 시간을 줄이기 위해 전이 학습이 사용됩니다. 전이 학습의 예로 오디오 인식을 위한 전이 학습을 배울 수도 있습니다.
추가 자료 및 리소스
다음 리소스를 사용하여 오디오 분류와 관련된 개념에 대해 자세히 알아보세요.