ML flexible, controlado e interpretable con modelos basados en celosías
import numpy as np import tensorflow as tf import tensorflow_lattice as tfl model = tf.keras.models.Sequential() model.add( tfl.layers.ParallelCombination([ # Monotonic piece-wise linear calibration with bounded output tfl.layers.PWLCalibration( monotonicity='increasing', input_keypoints=np.linspace(1., 5., num=20), output_min=0.0, output_max=1.0), # Diminishing returns tfl.layers.PWLCalibration( monotonicity='increasing', convexity='concave', input_keypoints=np.linspace(0., 200., num=20), output_min=0.0, output_max=2.0), # Partially monotonic categorical calibration: calib(0) <= calib(1) tfl.layers.CategoricalCalibration( num_buckets=4, output_min=0.0, output_max=1.0, monotonicities=[(0, 1)]), ])) model.add( tfl.layers.Lattice( lattice_sizes=[2, 3, 2], monotonicities=['increasing', 'increasing', 'increasing'], # Trust: model is more responsive to input 0 if input 1 increases edgeworth_trusts=(0, 1, 'positive'))) model.compile(...)
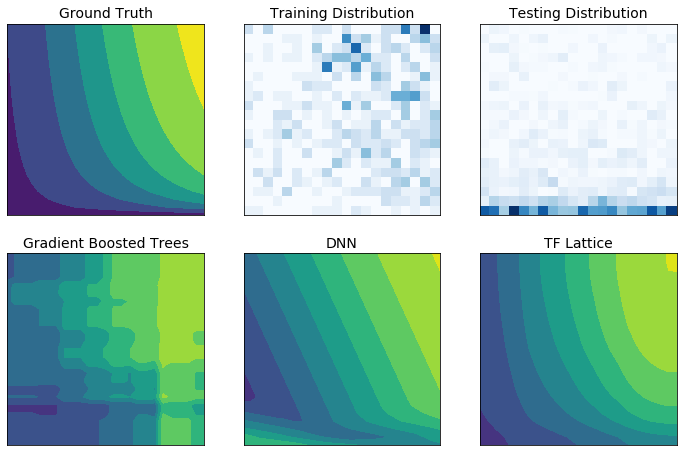
TensorFlow Lattice es una biblioteca que implementa modelos basados en celosías restringidos e interpretables. La biblioteca le permite inyectar conocimiento del dominio en el proceso de aprendizaje a través de restricciones de forma impulsadas por políticas o de sentido común. Esto se hace utilizando una colección de capas de Keras que pueden satisfacer restricciones como monotonicidad, convexidad y cómo interactúan las características. La biblioteca también proporciona modelos prefabricados fáciles de configurar.
Con TF Lattice puede utilizar el conocimiento del dominio para extrapolar mejor a las partes del espacio de entrada no cubiertas por el conjunto de datos de entrenamiento. Esto ayuda a evitar un comportamiento inesperado del modelo cuando la distribución de publicación es diferente de la distribución de entrenamiento.