
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
Este tutorial é uma visão geral das restrições e regularizadores fornecidos pela biblioteca TensorFlow Lattice (TFL). Aqui, usamos estimadores enlatados TFL em conjuntos de dados sintéticos, mas observe que tudo neste tutorial também pode ser feito com modelos construídos a partir de camadas TFL Keras.
Antes de prosseguir, certifique-se de que seu tempo de execução tenha todos os pacotes necessários instalados (conforme importado nas células de código abaixo).
Configurar
Instalando o pacote TF Lattice:
pip install -q tensorflow-lattice
Importando pacotes necessários:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valores padrão usados neste guia:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Conjunto de dados de treinamento para classificação de restaurantes
Imagine um cenário simplificado em que queremos determinar se os usuários clicarão ou não em um resultado de pesquisa de restaurante. A tarefa é prever a taxa de cliques (CTR), dados os recursos de entrada:
- Classificação Média (
avg_rating): uma característica numérica com valores no intervalo [1,5]. - Número de comentários (
num_reviews): uma característica numérica com valores cobertas a 200, que usamos como medida de modismo. - Classificação Dollar (
dollar_rating): uma característica categórica com valores de cadeia no conjunto { "D", "DD", "DDD", "DDDD"}.
Aqui, criamos um conjunto de dados sintético onde o verdadeiro CTR é dado pela fórmula:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
onde \(b(\cdot)\) traduz cada dollar_rating a um valor de linha de base:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Esta fórmula reflete os padrões típicos do usuário. por exemplo, considerando todo o resto corrigido, os usuários preferem restaurantes com classificações mais altas de estrelas, e os restaurantes "\ $ \ $" receberão mais cliques do que "\ $", seguido por "\ $ \ $ \ $" e "\ $ \ $ \ $ \ $ ".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Vamos dar uma olhada nos gráficos de contorno dessa função CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
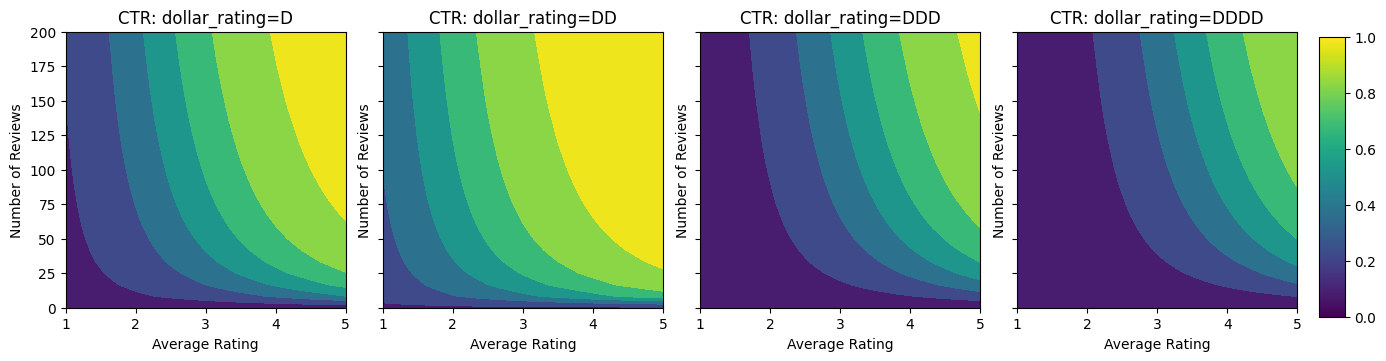
Preparando Dados
Agora precisamos criar nossos conjuntos de dados sintéticos. Começamos gerando um conjunto de dados simulado de restaurantes e suas características.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
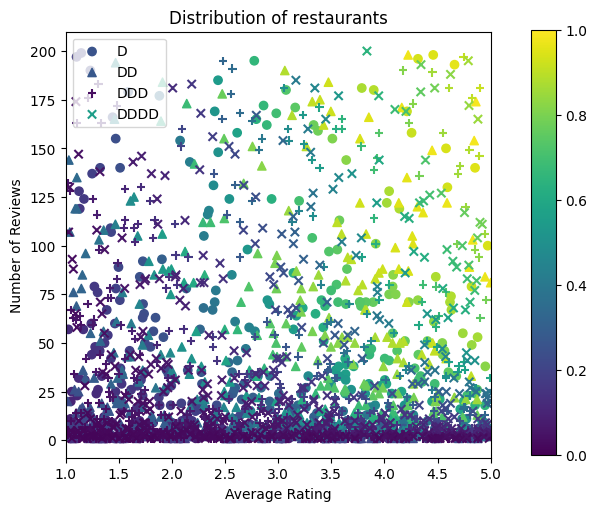
Vamos produzir os conjuntos de dados de treinamento, validação e teste. Quando um restaurante é visualizado nos resultados da pesquisa, podemos registrar o envolvimento do usuário (clique ou não clique) como um ponto de amostra.
Na prática, os usuários geralmente não passam por todos os resultados da pesquisa. Isso significa que os usuários provavelmente verão apenas restaurantes já considerados "bons" pelo modelo de classificação em uso. Como resultado, os "bons" restaurantes ficam mais frequentemente impressionados e sobre-representados nos conjuntos de dados de treinamento. Ao usar mais recursos, o conjunto de dados de treinamento pode ter grandes lacunas nas partes "ruins" do espaço do recurso.
Quando o modelo é usado para classificação, geralmente é avaliado em todos os resultados relevantes com uma distribuição mais uniforme que não é bem representada pelo conjunto de dados de treinamento. Um modelo flexível e complicado pode falhar neste caso devido ao sobreajuste dos pontos de dados super-representados e, portanto, falta generalizabilidade. Nós lidar com este problema, aplicando o conhecimento de domínio para adicionar forma restrições que orientam o modelo para fazer previsões razoáveis quando não pode pegá-los do conjunto de dados de treinamento.
Neste exemplo, o conjunto de dados de treinamento consiste principalmente em interações do usuário com restaurantes bons e populares. O conjunto de dados de teste tem uma distribuição uniforme para simular a configuração de avaliação discutida acima. Observe que esse conjunto de dados de teste não estará disponível em uma configuração de problema real.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Definindo input_fns usado para treinamento e avaliação:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Ajustando Árvores com Gradiente Impulsionado
Vamos começar com apenas duas características: avg_rating e num_reviews .
Criamos algumas funções auxiliares para plotar e calcular a validação e as métricas de teste.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Podemos ajustar árvores de decisão aumentadas por gradiente TensorFlow no conjunto de dados:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

Mesmo que o modelo tenha capturado a forma geral do CTR verdadeiro e tenha métricas de validação decentes, ele tem um comportamento contra-intuitivo em várias partes do espaço de entrada: o CTR estimado diminui à medida que a classificação média ou o número de avaliações aumenta. Isso se deve à falta de pontos de amostra em áreas não bem cobertas pelo conjunto de dados de treinamento. O modelo simplesmente não tem como deduzir o comportamento correto apenas a partir dos dados.
Para resolver esse problema, aplicamos a restrição de forma de que o modelo deve gerar valores monotonicamente crescentes em relação à avaliação média e ao número de avaliações. Veremos mais tarde como implementar isso no TFL.
Ajustando um DNN
Podemos repetir as mesmas etapas com um classificador DNN. Podemos observar um padrão semelhante: não ter pontos de amostra suficientes com pequeno número de avaliações resulta em extrapolação sem sentido. Observe que, embora a métrica de validação seja melhor do que a solução em árvore, a métrica de teste é muito pior.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Restrições de forma
O TensorFlow Lattice (TFL) se concentra em impor restrições de forma para proteger o comportamento do modelo além dos dados de treinamento. Essas restrições de forma são aplicadas às camadas TFL Keras. Seus detalhes podem ser encontrados no nosso papel JMLR .
Neste tutorial, usamos estimadores enlatados TF para cobrir várias restrições de forma, mas observe que todas essas etapas podem ser realizadas com modelos criados a partir de camadas TFL Keras.
Tal como acontece com qualquer outro estimador TensorFlow, TFL enlatados estimadores usar colunas recurso para definir o formato de entrada e usar um input_fn treinamento para passar os dados. O uso de estimadores enlatados TFL também requer:
- um modelo de configuração: definir a arquitectura do modelo e constrangimentos e regularizers por recurso-forma.
- um input_fn análise característica: a TF input_fn passar dados para a inicialização TFL.
Para uma descrição mais completa, consulte o tutorial de estimadores enlatados ou os documentos da API.
Monotonicidade
Primeiro, tratamos das preocupações com a monotonicidade adicionando restrições de forma de monotonicidade a ambos os recursos.
Instruir TFL para impor restrições forma, especificamos as restrições nas configurações de recursos. Os seguintes mostra o código como podemos exigir que a saída seja monótona crescente no que diz respeito a ambos os num_reviews e avg_rating definindo monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

Usando um CalibratedLatticeConfig cria um classificador enlatado que primeiro aplica-se um calibrador para cada entrada (uma função linear inteligente para características numéricas), seguida por uma camada de rede de não-linearmente fusível as características calibrados. Podemos usar tfl.visualization para visualizar o modelo. Em particular, o gráfico a seguir mostra os dois calibradores treinados incluídos no classificador pronto.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

Com as restrições adicionadas, a CTR estimada sempre aumentará conforme a avaliação média aumenta ou o número de avaliações aumenta. Isso é feito certificando-se de que os calibradores e a rede são monotônicos.
Rendimentos decrescentes
Retornos decrescentes significa que o ganho marginal de aumentar um determinado valor recurso irá diminuir à medida que aumentar o valor. No nosso caso, nós esperamos que o num_reviews recurso segue esse padrão, para que possamos configurar o seu calibrador em conformidade. Observe que podemos decompor os retornos decrescentes em duas condições suficientes:
- o calibrador está aumentando monotonicialmente, e
- o calibrador é côncavo.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
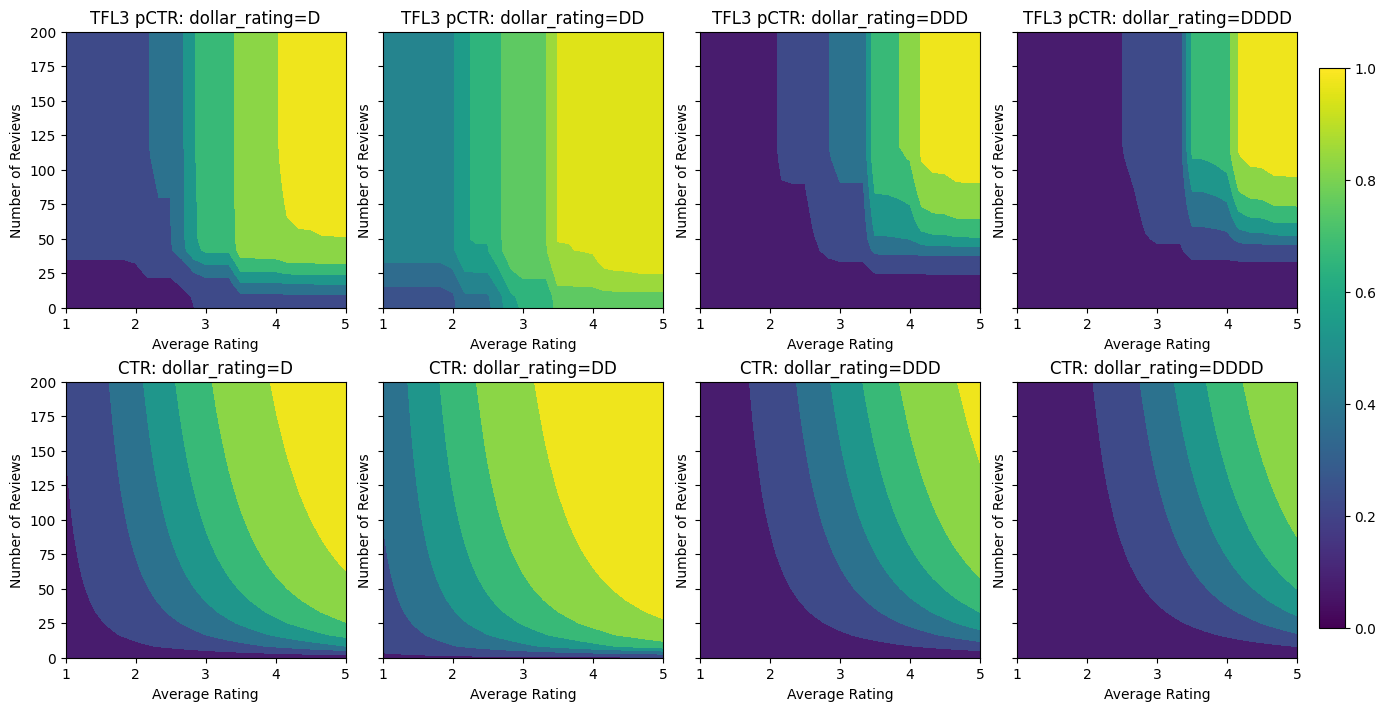

Observe como a métrica de teste melhora ao adicionar a restrição de concavidade. O gráfico de previsão também se assemelha melhor à verdade básica.
Restrição de forma 2D: confiança
Uma avaliação de 5 estrelas para um restaurante com apenas uma ou duas avaliações é provavelmente uma avaliação não confiável (o restaurante pode não ser bom), enquanto uma avaliação de 4 estrelas para um restaurante com centenas de avaliações é muito mais confiável (o restaurante é provavelmente bom neste caso). Podemos ver que o número de avaliações de um restaurante afeta o quanto confiamos em sua avaliação média.
Podemos exercitar as restrições de confiança do TFL para informar ao modelo que o valor maior (ou menor) de um recurso indica mais confiança ou confiança de outro recurso. Isto é feito através da criação reflects_trust_in configuração no config recurso.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
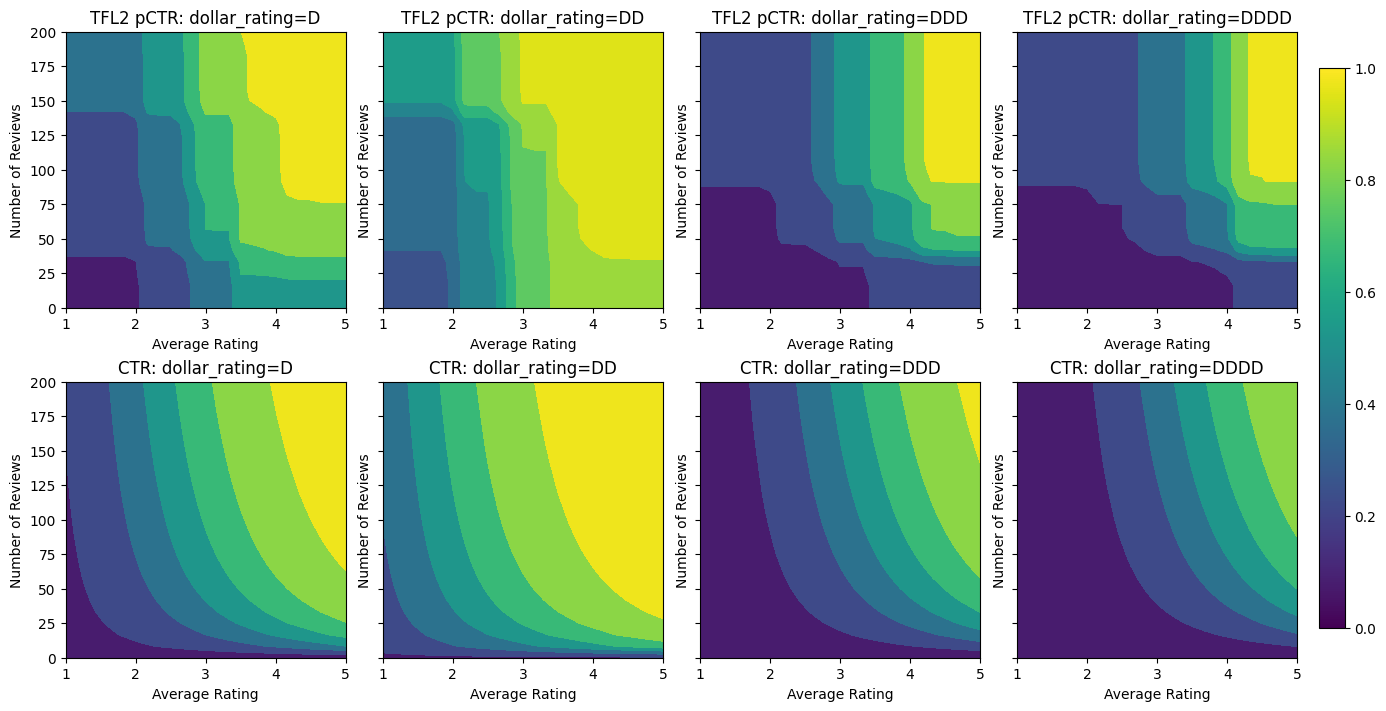

O gráfico a seguir apresenta a função de rede treinada. Devido à restrição confiança, espera-se que maiores valores de calibrados num_reviews forçaria maior inclinação em relação ao calibrado avg_rating , resultando em um movimento mais significativo na saída da estrutura.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
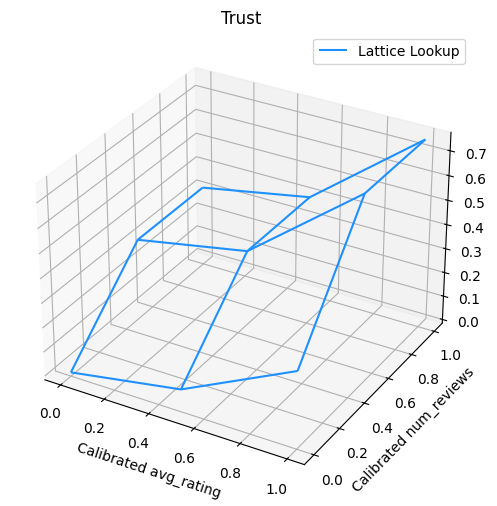
Calibradores de suavização
Vamos agora dar uma olhada no calibrador de avg_rating . Embora seja monotonicamente crescente, as mudanças em suas inclinações são abruptas e difíceis de interpretar. Isso sugere que pode querer considerar suavização este calibrador usando uma configuração regularizer nas regularizer_configs .
Aqui nós aplicamos uma wrinkle regularizer para reduzir alterações na curvatura. Você também pode usar o laplacian regularizer para achatar o calibrador eo hessian regularizer para torná-lo mais linear.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


Os calibradores agora estão suaves e o CTR estimado geral corresponde melhor à realidade. Isso se reflete na métrica de teste e nos gráficos de contorno.
Monotonicidade parcial para calibração categórica
Até agora, usamos apenas dois dos recursos numéricos no modelo. Aqui, adicionaremos um terceiro recurso usando uma camada de calibração categórica. Mais uma vez, começamos configurando funções auxiliares para plotagem e cálculo métrico.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Para envolver a terceira característica, dollar_rating , devemos lembrar que as características categóricas requerem um tratamento um pouco diferente em TFL, tanto como uma coluna de recurso e como uma configuração recurso. Aqui, impomos a restrição de monotonicidade parcial de que as saídas para restaurantes "DD" devem ser maiores do que restaurantes "D" quando todas as outras entradas são fixas. Isso é feito usando o monotonicity ajuste na configuração característica.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Este calibrador categórico mostra a preferência da saída do modelo: DD> D> DDD> DDDD, que é consistente com nossa configuração. Observe que também há uma coluna para valores ausentes. Embora não haja nenhum recurso ausente em nossos dados de treinamento e teste, o modelo nos fornece uma imputação para o valor ausente, caso isso aconteça durante a veiculação do modelo downstream.
Aqui também traçar a CTR prevista deste modelo condicionando a dollar_rating . Observe que todas as restrições exigidas são atendidas em cada uma das fatias.
Calibração de saída
Para todos os modelos TFL que treinamos até agora, a camada de rede (indicada como "Rede" no gráfico do modelo) produz diretamente a previsão do modelo. Às vezes, não temos certeza se a saída da rede deve ser redimensionada para emitir as saídas do modelo:
- os recursos são \(log\) contagens enquanto os rótulos são contagens.
- a rede é configurada para ter poucos vértices, mas a distribuição do rótulo é relativamente complicada.
Nesses casos, podemos adicionar outro calibrador entre a saída da rede e a saída do modelo para aumentar a flexibilidade do modelo. Aqui, vamos adicionar uma camada de calibrador com 5 pontos-chave ao modelo que acabamos de construir. Também adicionamos um regularizador para o calibrador de saída para manter a função suave.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


A métrica de teste final e os gráficos mostram como o uso de restrições de bom senso pode ajudar o modelo a evitar comportamento inesperado e extrapolar melhor para todo o espaço de entrada.
,| | | Ver fonte no GitHub | |
Visão geral
Este tutorial é uma visão geral das restrições e regularizadores fornecidos pela biblioteca TensorFlow Lattice (TFL). Aqui, usamos estimadores enlatados TFL em conjuntos de dados sintéticos, mas observe que tudo neste tutorial também pode ser feito com modelos construídos a partir de camadas TFL Keras.
Antes de prosseguir, certifique-se de que seu tempo de execução tenha todos os pacotes necessários instalados (conforme importado nas células de código abaixo).
Configurar
Instalando o pacote TF Lattice:
pip install -q tensorflow-lattice
Importando pacotes necessários:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valores padrão usados neste guia:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Conjunto de dados de treinamento para classificação de restaurantes
Imagine um cenário simplificado em que queremos determinar se os usuários clicarão ou não em um resultado de pesquisa de restaurante. A tarefa é prever a taxa de cliques (CTR), dados os recursos de entrada:
- Classificação Média (
avg_rating): uma característica numérica com valores no intervalo [1,5]. - Número de comentários (
num_reviews): uma característica numérica com valores cobertas a 200, que usamos como medida de modismo. - Classificação Dollar (
dollar_rating): uma característica categórica com valores de cadeia no conjunto { "D", "DD", "DDD", "DDDD"}.
Aqui, criamos um conjunto de dados sintético onde o verdadeiro CTR é dado pela fórmula:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
onde \(b(\cdot)\) traduz cada dollar_rating a um valor de linha de base:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Esta fórmula reflete os padrões típicos do usuário. por exemplo, considerando todo o resto corrigido, os usuários preferem restaurantes com classificações mais altas de estrelas, e os restaurantes "\ $ \ $" receberão mais cliques do que "\ $", seguido por "\ $ \ $ \ $" e "\ $ \ $ \ $ \ $ ".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Vamos dar uma olhada nos gráficos de contorno dessa função CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Preparando Dados
Agora precisamos criar nossos conjuntos de dados sintéticos. Começamos gerando um conjunto de dados simulado de restaurantes e suas características.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
Vamos produzir os conjuntos de dados de treinamento, validação e teste. Quando um restaurante é visualizado nos resultados da pesquisa, podemos registrar o envolvimento do usuário (clique ou não clique) como um ponto de amostra.
Na prática, os usuários geralmente não passam por todos os resultados da pesquisa. Isso significa que os usuários provavelmente verão apenas restaurantes já considerados "bons" pelo modelo de classificação em uso. Como resultado, os "bons" restaurantes ficam mais frequentemente impressionados e sobre-representados nos conjuntos de dados de treinamento. Ao usar mais recursos, o conjunto de dados de treinamento pode ter grandes lacunas nas partes "ruins" do espaço do recurso.
Quando o modelo é usado para classificação, geralmente é avaliado em todos os resultados relevantes com uma distribuição mais uniforme que não é bem representada pelo conjunto de dados de treinamento. Um modelo flexível e complicado pode falhar neste caso devido ao sobreajuste dos pontos de dados super-representados e, portanto, falta generalizabilidade. Nós lidar com este problema, aplicando o conhecimento de domínio para adicionar forma restrições que orientam o modelo para fazer previsões razoáveis quando não pode pegá-los do conjunto de dados de treinamento.
Neste exemplo, o conjunto de dados de treinamento consiste principalmente em interações do usuário com restaurantes bons e populares. O conjunto de dados de teste tem uma distribuição uniforme para simular a configuração de avaliação discutida acima. Observe que esse conjunto de dados de teste não estará disponível em uma configuração de problema real.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
Definindo input_fns usado para treinamento e avaliação:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Ajustando Árvores com Gradiente Impulsionado
Vamos começar com apenas duas características: avg_rating e num_reviews .
Criamos algumas funções auxiliares para plotar e calcular a validação e as métricas de teste.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Podemos ajustar árvores de decisão aumentadas por gradiente TensorFlow no conjunto de dados:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
Mesmo que o modelo tenha capturado a forma geral do CTR verdadeiro e tenha métricas de validação decentes, ele tem um comportamento contra-intuitivo em várias partes do espaço de entrada: o CTR estimado diminui à medida que a classificação média ou o número de avaliações aumenta. Isso se deve à falta de pontos de amostra em áreas não bem cobertas pelo conjunto de dados de treinamento. O modelo simplesmente não tem como deduzir o comportamento correto apenas a partir dos dados.
Para resolver esse problema, aplicamos a restrição de forma de que o modelo deve gerar valores monotonicamente crescentes em relação à avaliação média e ao número de avaliações. Veremos mais tarde como implementar isso no TFL.
Ajustando um DNN
Podemos repetir as mesmas etapas com um classificador DNN. Podemos observar um padrão semelhante: não ter pontos de amostra suficientes com pequeno número de avaliações resulta em extrapolação sem sentido. Observe que, embora a métrica de validação seja melhor do que a solução em árvore, a métrica de teste é muito pior.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
Restrições de forma
O TensorFlow Lattice (TFL) se concentra em impor restrições de forma para proteger o comportamento do modelo além dos dados de treinamento. Essas restrições de forma são aplicadas às camadas TFL Keras. Seus detalhes podem ser encontrados no nosso papel JMLR .
Neste tutorial, usamos estimadores enlatados TF para cobrir várias restrições de forma, mas observe que todas essas etapas podem ser realizadas com modelos criados a partir de camadas TFL Keras.
Tal como acontece com qualquer outro estimador TensorFlow, TFL enlatados estimadores usar colunas recurso para definir o formato de entrada e usar um input_fn treinamento para passar os dados. O uso de estimadores enlatados TFL também requer:
- um modelo de configuração: definir a arquitectura do modelo e constrangimentos e regularizers por recurso-forma.
- um input_fn análise característica: a TF input_fn passar dados para a inicialização TFL.
Para uma descrição mais completa, consulte o tutorial de estimadores enlatados ou os documentos da API.
Monotonicidade
Primeiro, tratamos das preocupações com a monotonicidade adicionando restrições de forma de monotonicidade a ambos os recursos.
Instruir TFL para impor restrições forma, especificamos as restrições nas configurações de recursos. Os seguintes mostra o código como podemos exigir que a saída seja monótona crescente no que diz respeito a ambos os num_reviews e avg_rating definindo monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
Usando um CalibratedLatticeConfig cria um classificador enlatado que primeiro aplica-se um calibrador para cada entrada (uma função linear inteligente para características numéricas), seguida por uma camada de rede de não-linearmente fusível as características calibrados. Podemos usar tfl.visualization para visualizar o modelo. Em particular, o gráfico a seguir mostra os dois calibradores treinados incluídos no classificador pronto.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
Com as restrições adicionadas, a CTR estimada sempre aumentará conforme a avaliação média aumenta ou o número de avaliações aumenta. Isso é feito certificando-se de que os calibradores e a rede são monotônicos.
Rendimentos decrescentes
Retornos decrescentes significa que o ganho marginal de aumentar um determinado valor recurso irá diminuir à medida que aumentar o valor. No nosso caso, nós esperamos que o num_reviews recurso segue esse padrão, para que possamos configurar o seu calibrador em conformidade. Observe que podemos decompor os retornos decrescentes em duas condições suficientes:
- o calibrador está aumentando monotonicialmente, e
- o calibrador é côncavo.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
Observe como a métrica de teste melhora ao adicionar a restrição de concavidade. O gráfico de previsão também se assemelha melhor à verdade básica.
Restrição de forma 2D: confiança
Uma avaliação de 5 estrelas para um restaurante com apenas uma ou duas avaliações é provavelmente uma avaliação não confiável (o restaurante pode não ser bom), enquanto uma avaliação de 4 estrelas para um restaurante com centenas de avaliações é muito mais confiável (o restaurante é provavelmente bom neste caso). Podemos ver que o número de avaliações de um restaurante afeta o quanto confiamos em sua avaliação média.
Podemos exercitar as restrições de confiança do TFL para informar ao modelo que o valor maior (ou menor) de um recurso indica mais confiança ou confiança de outro recurso. Isto é feito através da criação reflects_trust_in configuração no config recurso.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
O gráfico a seguir apresenta a função de rede treinada. Devido à restrição confiança, espera-se que maiores valores de calibrados num_reviews forçaria maior inclinação em relação ao calibrado avg_rating , resultando em um movimento mais significativo na saída da estrutura.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Calibradores de suavização
Vamos agora dar uma olhada no calibrador de avg_rating . Embora seja monotonicamente crescente, as mudanças em suas inclinações são abruptas e difíceis de interpretar. Isso sugere que pode querer considerar suavização este calibrador usando uma configuração regularizer nas regularizer_configs .
Aqui nós aplicamos uma wrinkle regularizer para reduzir alterações na curvatura. Você também pode usar o laplacian regularizer para achatar o calibrador eo hessian regularizer para torná-lo mais linear.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
Os calibradores agora estão suaves e o CTR estimado geral corresponde melhor à realidade. Isso se reflete na métrica de teste e nos gráficos de contorno.
Monotonicidade parcial para calibração categórica
Até agora, usamos apenas dois dos recursos numéricos no modelo. Aqui, adicionaremos um terceiro recurso usando uma camada de calibração categórica. Mais uma vez, começamos configurando funções auxiliares para plotagem e cálculo métrico.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Para envolver a terceira característica, dollar_rating , devemos lembrar que as características categóricas requerem um tratamento um pouco diferente em TFL, tanto como uma coluna de recurso e como uma configuração recurso. Aqui, impomos a restrição de monotonicidade parcial de que as saídas para restaurantes "DD" devem ser maiores do que restaurantes "D" quando todas as outras entradas são fixas. Isso é feito usando o monotonicity ajuste na configuração característica.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
Este calibrador categórico mostra a preferência da saída do modelo: DD> D> DDD> DDDD, que é consistente com nossa configuração. Observe que também há uma coluna para valores ausentes. Embora não haja nenhum recurso ausente em nossos dados de treinamento e teste, o modelo nos fornece uma imputação para o valor ausente, caso isso aconteça durante a veiculação do modelo downstream.
Aqui também traçar a CTR prevista deste modelo condicionando a dollar_rating . Observe que todas as restrições exigidas são atendidas em cada uma das fatias.
Calibração de saída
Para todos os modelos TFL que treinamos até agora, a camada de rede (indicada como "Rede" no gráfico do modelo) produz diretamente a previsão do modelo. Às vezes, não temos certeza se a saída da rede deve ser redimensionada para emitir as saídas do modelo:
- os recursos são \(log\) contagens enquanto os rótulos são contagens.
- a rede é configurada para ter poucos vértices, mas a distribuição do rótulo é relativamente complicada.
Nesses casos, podemos adicionar outro calibrador entre a saída da rede e a saída do modelo para aumentar a flexibilidade do modelo. Aqui, vamos adicionar uma camada de calibrador com 5 pontos-chave ao modelo que acabamos de construir. Também adicionamos um regularizador para o calibrador de saída para manter a função suave.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
A métrica de teste final e os gráficos mostram como o uso de restrições de bom senso pode ajudar o modelo a evitar comportamento inesperado e extrapolar melhor para todo o espaço de entrada.