
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Panoramica
Questo tutorial è una panoramica dei vincoli e dei regolarizzatori forniti dalla libreria TensorFlow Lattice (TFL). Qui usiamo stimatori fissi TFL su set di dati sintetici, ma tieni presente che tutto in questo tutorial può essere fatto anche con modelli costruiti da livelli TFL Keras.
Prima di procedere, assicurati che nel tuo runtime siano installati tutti i pacchetti richiesti (come importati nelle celle di codice sottostanti).
Impostare
Installazione del pacchetto TF Lattice:
pip install -q tensorflow-lattice
Importazione dei pacchetti richiesti:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valori predefiniti utilizzati in questa guida:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Set di dati di formazione per la classifica dei ristoranti
Immagina uno scenario semplificato in cui vogliamo determinare se gli utenti faranno clic o meno su un risultato di ricerca di un ristorante. L'attività consiste nel prevedere la percentuale di clic (CTR) in base alle funzioni di input:
- Votazione media (
avg_rating): una caratteristica numerica con valori nell'intervallo [1,5]. - Numero valutazioni (
num_reviews): Funzione numerico con valori limite massimo è 200, che utilizziamo come misura di tendenza. - Valutazione Dollar (
dollar_rating): una caratteristica categorica con i valori di stringa nel set { "D", "DD", "DDD", "DDDD"}.
Qui creiamo un dataset sintetico dove il vero CTR è dato dalla formula:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
dove \(b(\cdot)\) traduce ogni dollar_rating ad un valore di base:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Questa formula riflette i modelli tipici dell'utente. ad esempio, dato che tutto il resto è stato risolto, gli utenti preferiscono ristoranti con valutazioni a stelle più alte e i ristoranti "\$\$" riceveranno più clic di "\$", seguito da "\$\$\$" e "\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Diamo un'occhiata ai grafici di contorno di questa funzione CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
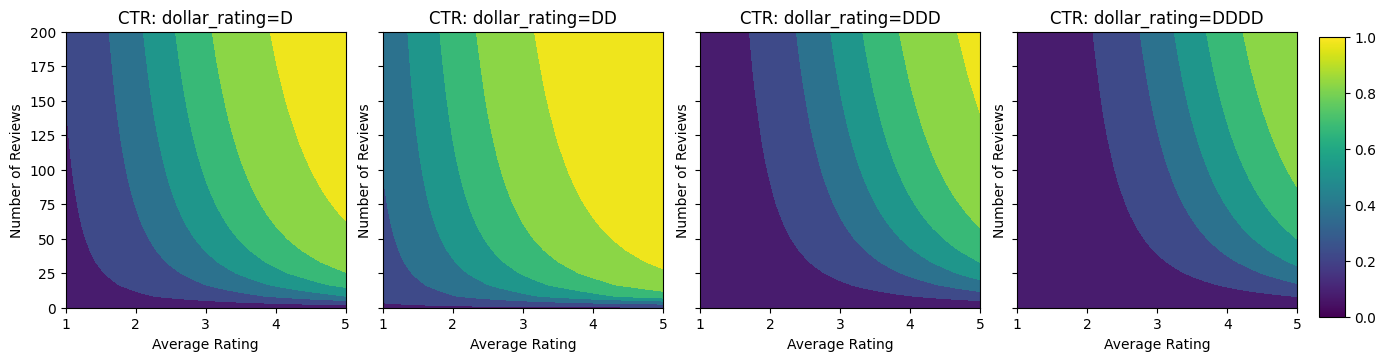
Preparazione dei dati
Ora dobbiamo creare i nostri set di dati sintetici. Iniziamo generando un set di dati simulato di ristoranti e le loro caratteristiche.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
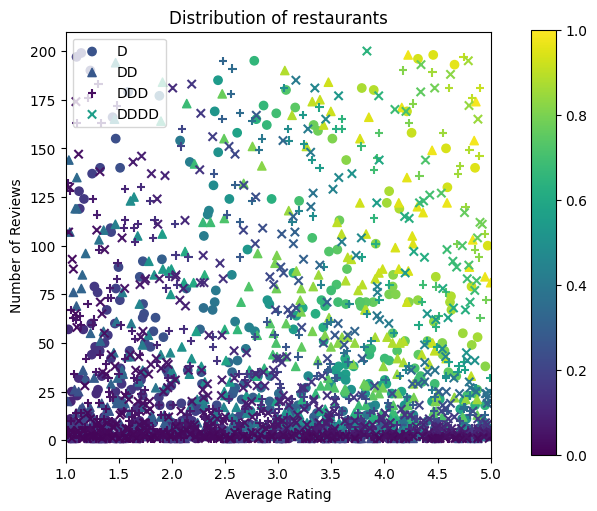
Produciamo i set di dati di addestramento, convalida e test. Quando un ristorante viene visualizzato nei risultati di ricerca, possiamo registrare il coinvolgimento dell'utente (clic o non clic) come punto di esempio.
In pratica, gli utenti spesso non passano attraverso tutti i risultati della ricerca. Ciò significa che gli utenti vedranno probabilmente solo i ristoranti già considerati "buoni" dall'attuale modello di classificazione in uso. Di conseguenza, i ristoranti "buoni" sono più frequentemente colpiti e sovrarappresentati nei set di dati di formazione. Quando si utilizzano più funzionalità, il set di dati di addestramento può presentare grandi lacune nelle parti "cattive" dello spazio delle funzionalità.
Quando il modello viene utilizzato per la classificazione, viene spesso valutato su tutti i risultati rilevanti con una distribuzione più uniforme che non è ben rappresentata dal set di dati di addestramento. Un modello flessibile e complicato potrebbe fallire in questo caso a causa dell'overfitting dei punti dati sovrarappresentati e quindi della mancanza di generalizzabilità. Ci occupiamo di questo problema applicando la conoscenza di dominio per aggiungere vincoli di forma che guidano il modello per fare previsioni ragionevoli quando non li può raccogliere dal set di dati di addestramento.
In questo esempio, il set di dati di addestramento consiste principalmente di interazioni dell'utente con ristoranti buoni e popolari. Il set di dati di test ha una distribuzione uniforme per simulare l'impostazione di valutazione discussa sopra. Si noti che tale set di dati di test non sarà disponibile in un ambiente con problemi reali.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)

Definizione di input_fns utilizzato per la formazione e la valutazione:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Adattamento di alberi con gradiente potenziato
Partiamo subito con solo due caratteristiche: avg_rating e num_reviews .
Creiamo alcune funzioni ausiliarie per tracciare e calcolare metriche di convalida e test.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Possiamo adattare alberi decisionali con gradiente boost di TensorFlow sul set di dati:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021

Anche se il modello ha catturato la forma generale del vero CTR e ha metriche di convalida decenti, ha un comportamento controintuitivo in diverse parti dello spazio di input: il CTR stimato diminuisce all'aumentare della valutazione media o del numero di recensioni. Ciò è dovuto alla mancanza di punti campione in aree non ben coperte dal set di dati di addestramento. Il modello semplicemente non ha modo di dedurre il comportamento corretto esclusivamente dai dati.
Per risolvere questo problema, applichiamo il vincolo di forma che il modello deve produrre valori monotonicamente crescenti rispetto sia alla valutazione media che al numero di recensioni. Vedremo in seguito come implementarlo in TFL.
Adattare un DNN
Possiamo ripetere gli stessi passaggi con un classificatore DNN. Possiamo osservare un modello simile: non avere abbastanza punti campione con un piccolo numero di revisioni si traduce in un'estrapolazione senza senso. Si noti che anche se la metrica di convalida è migliore della soluzione ad albero, la metrica di test è molto peggiore.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022

Vincoli di forma
TensorFlow Lattice (TFL) si concentra sull'applicazione dei vincoli di forma per salvaguardare il comportamento del modello oltre i dati di addestramento. Questi vincoli di forma vengono applicati ai livelli TFL Keras. I loro dettagli possono essere trovati nel nostro giornale JMLR .
In questo tutorial usiamo stimatori fissi TF per coprire vari vincoli di forma, ma tieni presente che tutti questi passaggi possono essere eseguiti con modelli creati da livelli TFL Keras.
Come con qualsiasi altro stimatore tensorflow, TFL scatola stimatori usano includono colonne per definire il formato di ingresso e utilizzare un input_fn formazione per passare nei dati. L'utilizzo di stimatori fissi TFL richiede anche:
- un modello di configurazione: definizione dell'architettura modello e per-funzione vincoli di forma e regularizers.
- un'analisi caratteristica input_fn: un TF input_fn passaggio di dati per TFL inizializzazione.
Per una descrizione più approfondita, fare riferimento al tutorial sugli estimatori predefiniti o ai documenti API.
Monotonicità
Per prima cosa affrontiamo i problemi di monotonicità aggiungendo vincoli di forma di monotonicità a entrambe le caratteristiche.
Per indicare a TFL per far rispettare i vincoli di forma, specifichiamo i vincoli nella funzionalità configurazioni. Illustra il codice seguente come possiamo richiedere l'output di essere monotona crescente rispetto sia num_reviews e avg_rating impostando monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972

Utilizzando una CalibratedLatticeConfig crea un classificatore scatola che prima si applica un calibratore per ciascun ingresso (una funzione lineare a tratti per caratteristiche numeriche) seguito da uno strato di lattice per non lineare fusibile caratteristiche calibrate. Possiamo usare tfl.visualization per visualizzare il modello. In particolare, il grafico seguente mostra i due calibratori addestrati inclusi nel classificatore in scatola.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)

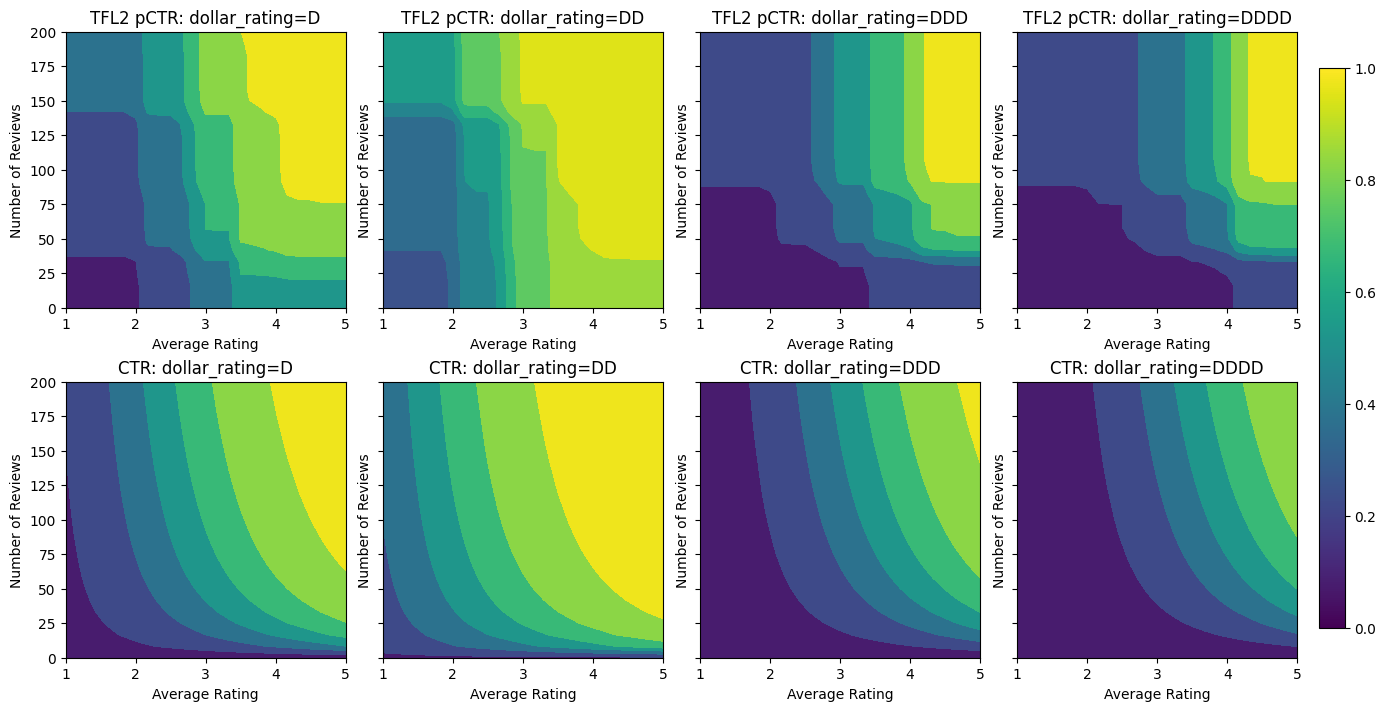
Con l'aggiunta dei vincoli, il CTR stimato aumenterà sempre all'aumentare della valutazione media o del numero di recensioni. Questo viene fatto assicurandosi che i calibratori e il reticolo siano monotoni.
Rendimenti decrescenti
Rendimenti decrescenti significa che il guadagno marginale di aumentare un certo valore caratteristica diminuisce man mano aumentiamo il valore. Nel nostro caso ci aspettiamo che il num_reviews funzione segue questo modello, in modo che possiamo configurare il suo calibratore di conseguenza. Si noti che possiamo scomporre i rendimenti decrescenti in due condizioni sufficienti:
- il calibratore è monotono crescente, e
- il calibratore è concavo.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
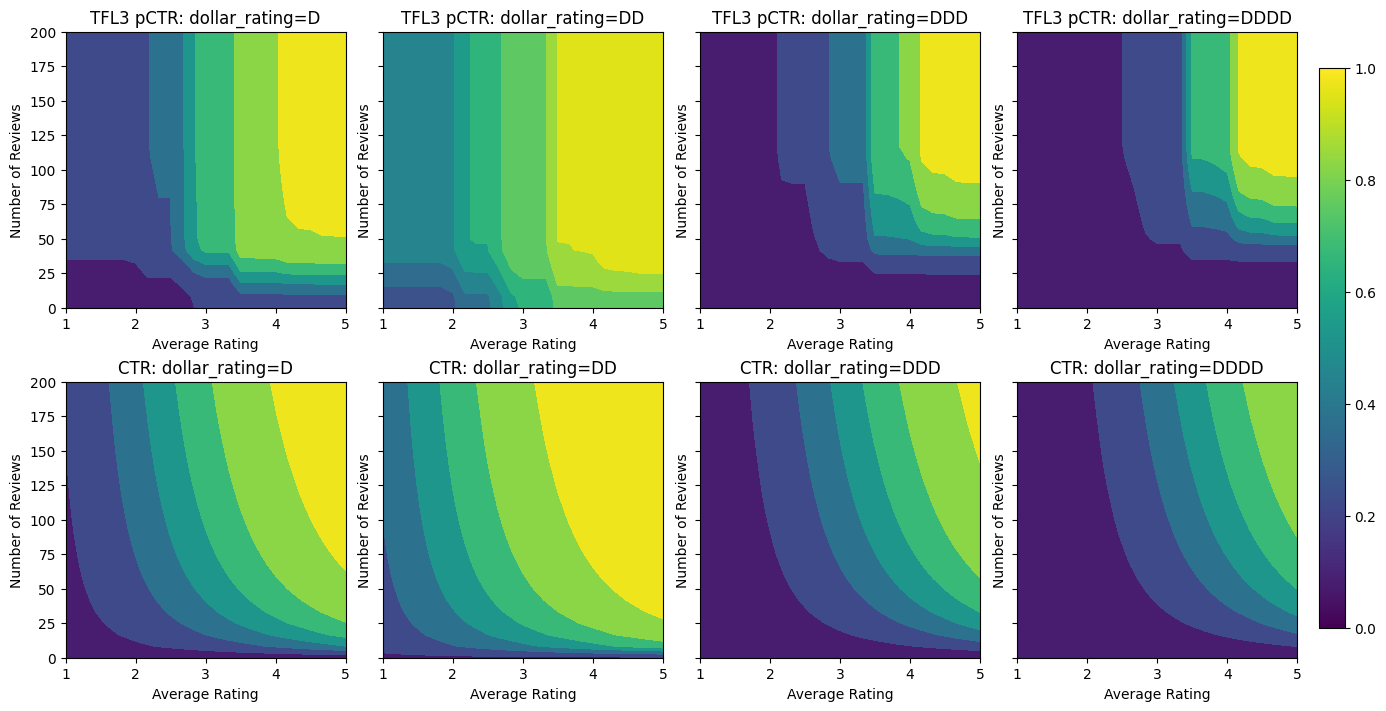

Nota come la metrica di test migliora aggiungendo il vincolo di concavità. Anche la trama della previsione assomiglia meglio alla verità fondamentale.
Vincolo della forma 2D: fiducia
Una valutazione a 5 stelle per un ristorante con solo una o due recensioni è probabilmente una valutazione inaffidabile (il ristorante potrebbe non essere effettivamente buono), mentre una valutazione a 4 stelle per un ristorante con centinaia di recensioni è molto più affidabile (il ristorante è probabilmente buono in questo caso). Possiamo vedere che il numero di recensioni di un ristorante influisce sulla fiducia che riponiamo nella sua valutazione media.
Possiamo esercitare i vincoli di fiducia TFL per informare il modello che il valore più grande (o più piccolo) di una caratteristica indica più affidamento o fiducia di un'altra caratteristica. Questo viene fatto impostando reflects_trust_in configurazione nella funzione di configurazione.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323

Il grafico seguente presenta la funzione reticolare addestrata. A causa del vincolo fiducia, ci aspettiamo che valori più grandi di calibrate num_reviews obbligherebbero pendenza maggiore rispetto calibrato avg_rating , risultando in un movimento più significativo nell'output reticolo.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
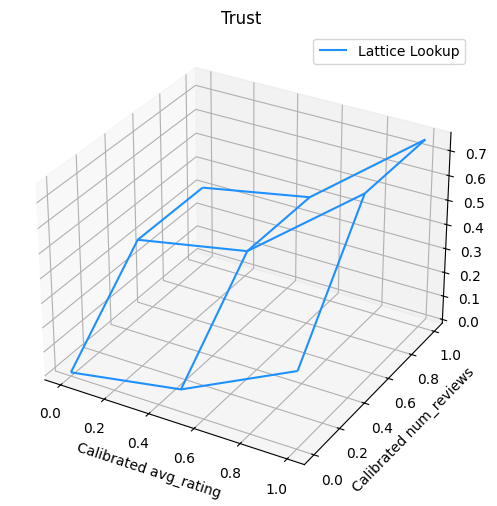
Calibratori leviganti
Diamo ora uno sguardo al calibratore di avg_rating . Sebbene sia in aumento monotono, i cambiamenti nelle sue pendenze sono bruschi e difficili da interpretare. Questo suggerisce che si potrebbe prendere in considerazione lisciatura questo calibratore utilizzando un setup regolarizzatore nelle regularizer_configs .
Qui si applica una wrinkle regolarizzatore per ridurre i cambiamenti nella curvatura. È inoltre possibile utilizzare il laplacian regolarizzatore per appiattire il calibratore e la hessian regolarizzatore per renderlo più lineare.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637


I calibratori ora sono lisci e il CTR stimato complessivo corrisponde meglio alla verità del terreno. Ciò si riflette sia nella metrica di prova che nei grafici di contorno.
Monotonicità parziale per calibrazione categoriale
Finora abbiamo utilizzato solo due delle funzioni numeriche nel modello. Qui aggiungeremo una terza funzionalità utilizzando un livello di calibrazione categoriale. Di nuovo iniziamo impostando le funzioni di supporto per la stampa e il calcolo metrico.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Coinvolgere la terza caratteristica, dollar_rating , è opportuno ricordare che le caratteristiche categoriali richiedono un trattamento leggermente diverso TFL, sia come colonna caratteristica e come caratteristica configurazione. Qui applichiamo il vincolo di monotonicità parziale secondo cui gli output per i ristoranti "DD" dovrebbero essere più grandi dei ristoranti "D" quando tutti gli altri input sono fissi. Questo viene fatto usando la monotonicity impostazione della funzione di configurazione.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056


Questo calibratore categorico mostra la preferenza dell'output del modello: DD > D > DDD > DDDD, che è coerente con la nostra configurazione. Notare che c'è anche una colonna per i valori mancanti. Sebbene non ci siano funzionalità mancanti nei nostri dati di addestramento e test, il modello ci fornisce un'imputazione per il valore mancante nel caso in cui si verificasse durante la pubblicazione del modello a valle.
Qui abbiamo anche tracciare la CTR previsto di questo modello condizione dollar_rating . Notare che tutti i vincoli richiesti sono soddisfatti in ciascuna delle sezioni.
Calibrazione dell'uscita
Per tutti i modelli TFL che abbiamo addestrato finora, lo strato reticolare (indicato come "Lattice" nel grafico del modello) emette direttamente la previsione del modello. A volte non siamo sicuri se l'output del reticolo debba essere ridimensionato per emettere gli output del modello:
- le caratteristiche sono \(log\) conta, mentre le etichette sono conteggi.
- il reticolo è configurato per avere pochissimi vertici ma la distribuzione delle etichette è relativamente complicata.
In questi casi possiamo aggiungere un altro calibratore tra l'output del reticolo e l'output del modello per aumentare la flessibilità del modello. Qui aggiungiamo un livello calibratore con 5 punti chiave al modello che abbiamo appena costruito. Aggiungiamo anche un regolarizzatore per il calibratore di uscita per mantenere la funzione fluida.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394


La metrica di test finale e i grafici mostrano come l'utilizzo di vincoli di buon senso può aiutare il modello a evitare comportamenti imprevisti ed estrapolare meglio l'intero spazio di input.
,| | | Visualizza la fonte su GitHub | |
Panoramica
Questo tutorial è una panoramica dei vincoli e dei regolarizzatori forniti dalla libreria TensorFlow Lattice (TFL). Qui usiamo stimatori fissi TFL su set di dati sintetici, ma tieni presente che tutto in questo tutorial può essere fatto anche con modelli costruiti da livelli TFL Keras.
Prima di procedere, assicurati che nel tuo runtime siano installati tutti i pacchetti richiesti (come importati nelle celle di codice sottostanti).
Impostare
Installazione del pacchetto TF Lattice:
pip install -q tensorflow-lattice
Importazione dei pacchetti richiesti:
import tensorflow as tf
from IPython.core.pylabtools import figsize
import itertools
import logging
import matplotlib
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Valori predefiniti utilizzati in questa guida:
NUM_EPOCHS = 1000
BATCH_SIZE = 64
LEARNING_RATE=0.01
Set di dati di formazione per la classifica dei ristoranti
Immagina uno scenario semplificato in cui vogliamo determinare se gli utenti faranno clic o meno su un risultato di ricerca di un ristorante. L'attività consiste nel prevedere la percentuale di clic (CTR) in base alle funzioni di input:
- Votazione media (
avg_rating): una caratteristica numerica con valori nell'intervallo [1,5]. - Numero valutazioni (
num_reviews): Funzione numerico con valori limite massimo è 200, che utilizziamo come misura di tendenza. - Valutazione Dollar (
dollar_rating): una caratteristica categorica con i valori di stringa nel set { "D", "DD", "DDD", "DDDD"}.
Qui creiamo un dataset sintetico dove il vero CTR è dato dalla formula:
\[ CTR = 1 / (1 + exp\{\mbox{b(dollar_rating)}-\mbox{avg_rating}\times log(\mbox{num_reviews}) /4 \}) \]
dove \(b(\cdot)\) traduce ogni dollar_rating ad un valore di base:
\[ \mbox{D}\to 3,\ \mbox{DD}\to 2,\ \mbox{DDD}\to 4,\ \mbox{DDDD}\to 4.5. \]
Questa formula riflette i modelli tipici dell'utente. ad esempio, dato che tutto il resto è stato risolto, gli utenti preferiscono ristoranti con valutazioni a stelle più alte e i ristoranti "\$\$" riceveranno più clic di "\$", seguito da "\$\$\$" e "\$\$\$ \$".
def click_through_rate(avg_ratings, num_reviews, dollar_ratings):
dollar_rating_baseline = {"D": 3, "DD": 2, "DDD": 4, "DDDD": 4.5}
return 1 / (1 + np.exp(
np.array([dollar_rating_baseline[d] for d in dollar_ratings]) -
avg_ratings * np.log1p(num_reviews) / 4))
Diamo un'occhiata ai grafici di contorno di questa funzione CTR.
def color_bar():
bar = matplotlib.cm.ScalarMappable(
norm=matplotlib.colors.Normalize(0, 1, True),
cmap="viridis",
)
bar.set_array([0, 1])
return bar
def plot_fns(fns, split_by_dollar=False, res=25):
"""Generates contour plots for a list of (name, fn) functions."""
num_reviews, avg_ratings = np.meshgrid(
np.linspace(0, 200, num=res),
np.linspace(1, 5, num=res),
)
if split_by_dollar:
dollar_rating_splits = ["D", "DD", "DDD", "DDDD"]
else:
dollar_rating_splits = [None]
if len(fns) == 1:
fig, axes = plt.subplots(2, 2, sharey=True, tight_layout=False)
else:
fig, axes = plt.subplots(
len(dollar_rating_splits), len(fns), sharey=True, tight_layout=False)
axes = axes.flatten()
axes_index = 0
for dollar_rating_split in dollar_rating_splits:
for title, fn in fns:
if dollar_rating_split is not None:
dollar_ratings = np.repeat(dollar_rating_split, res**2)
values = fn(avg_ratings.flatten(), num_reviews.flatten(),
dollar_ratings)
title = "{}: dollar_rating={}".format(title, dollar_rating_split)
else:
values = fn(avg_ratings.flatten(), num_reviews.flatten())
subplot = axes[axes_index]
axes_index += 1
subplot.contourf(
avg_ratings,
num_reviews,
np.reshape(values, (res, res)),
vmin=0,
vmax=1)
subplot.title.set_text(title)
subplot.set(xlabel="Average Rating")
subplot.set(ylabel="Number of Reviews")
subplot.set(xlim=(1, 5))
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
figsize(11, 11)
plot_fns([("CTR", click_through_rate)], split_by_dollar=True)
Preparazione dei dati
Ora dobbiamo creare i nostri set di dati sintetici. Iniziamo generando un set di dati simulato di ristoranti e le loro caratteristiche.
def sample_restaurants(n):
avg_ratings = np.random.uniform(1.0, 5.0, n)
num_reviews = np.round(np.exp(np.random.uniform(0.0, np.log(200), n)))
dollar_ratings = np.random.choice(["D", "DD", "DDD", "DDDD"], n)
ctr_labels = click_through_rate(avg_ratings, num_reviews, dollar_ratings)
return avg_ratings, num_reviews, dollar_ratings, ctr_labels
np.random.seed(42)
avg_ratings, num_reviews, dollar_ratings, ctr_labels = sample_restaurants(2000)
figsize(5, 5)
fig, axs = plt.subplots(1, 1, sharey=False, tight_layout=False)
for rating, marker in [("D", "o"), ("DD", "^"), ("DDD", "+"), ("DDDD", "x")]:
plt.scatter(
x=avg_ratings[np.where(dollar_ratings == rating)],
y=num_reviews[np.where(dollar_ratings == rating)],
c=ctr_labels[np.where(dollar_ratings == rating)],
vmin=0,
vmax=1,
marker=marker,
label=rating)
plt.xlabel("Average Rating")
plt.ylabel("Number of Reviews")
plt.legend()
plt.xlim((1, 5))
plt.title("Distribution of restaurants")
_ = fig.colorbar(color_bar(), cax=fig.add_axes([0.95, 0.2, 0.01, 0.6]))
Produciamo i set di dati di addestramento, convalida e test. Quando un ristorante viene visualizzato nei risultati di ricerca, possiamo registrare il coinvolgimento dell'utente (clic o non clic) come punto di esempio.
In pratica, gli utenti spesso non passano attraverso tutti i risultati della ricerca. Ciò significa che gli utenti vedranno probabilmente solo i ristoranti già considerati "buoni" dall'attuale modello di classificazione in uso. Di conseguenza, i ristoranti "buoni" sono più frequentemente colpiti e sovrarappresentati nei set di dati di formazione. Quando si utilizzano più funzionalità, il set di dati di addestramento può presentare grandi lacune nelle parti "cattive" dello spazio delle funzionalità.
Quando il modello viene utilizzato per la classificazione, viene spesso valutato su tutti i risultati rilevanti con una distribuzione più uniforme che non è ben rappresentata dal set di dati di addestramento. Un modello flessibile e complicato potrebbe fallire in questo caso a causa dell'overfitting dei punti dati sovrarappresentati e quindi della mancanza di generalizzabilità. Ci occupiamo di questo problema applicando la conoscenza di dominio per aggiungere vincoli di forma che guidano il modello per fare previsioni ragionevoli quando non li può raccogliere dal set di dati di addestramento.
In questo esempio, il set di dati di addestramento consiste principalmente di interazioni dell'utente con ristoranti buoni e popolari. Il set di dati di test ha una distribuzione uniforme per simulare l'impostazione di valutazione discussa sopra. Si noti che tale set di dati di test non sarà disponibile in un ambiente con problemi reali.
def sample_dataset(n, testing_set):
(avg_ratings, num_reviews, dollar_ratings, ctr_labels) = sample_restaurants(n)
if testing_set:
# Testing has a more uniform distribution over all restaurants.
num_views = np.random.poisson(lam=3, size=n)
else:
# Training/validation datasets have more views on popular restaurants.
num_views = np.random.poisson(lam=ctr_labels * num_reviews / 50.0, size=n)
return pd.DataFrame({
"avg_rating": np.repeat(avg_ratings, num_views),
"num_reviews": np.repeat(num_reviews, num_views),
"dollar_rating": np.repeat(dollar_ratings, num_views),
"clicked": np.random.binomial(n=1, p=np.repeat(ctr_labels, num_views))
})
# Generate datasets.
np.random.seed(42)
data_train = sample_dataset(500, testing_set=False)
data_val = sample_dataset(500, testing_set=False)
data_test = sample_dataset(500, testing_set=True)
# Plotting dataset densities.
figsize(12, 5)
fig, axs = plt.subplots(1, 2, sharey=False, tight_layout=False)
for ax, data, title in [(axs[0], data_train, "training"),
(axs[1], data_test, "testing")]:
_, _, _, density = ax.hist2d(
x=data["avg_rating"],
y=data["num_reviews"],
bins=(np.linspace(1, 5, num=21), np.linspace(0, 200, num=21)),
density=True,
cmap="Blues",
)
ax.set(xlim=(1, 5))
ax.set(ylim=(0, 200))
ax.set(xlabel="Average Rating")
ax.set(ylabel="Number of Reviews")
ax.title.set_text("Density of {} examples".format(title))
_ = fig.colorbar(density, ax=ax)
Definizione di input_fns utilizzato per la formazione e la valutazione:
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
shuffle=False,
)
# feature_analysis_input_fn is used for TF Lattice estimators.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_train,
y=data_train["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
val_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_val,
y=data_val["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=data_test,
y=data_test["clicked"],
batch_size=BATCH_SIZE,
num_epochs=1,
shuffle=False,
)
Adattamento di alberi con gradiente potenziato
Partiamo subito con solo due caratteristiche: avg_rating e num_reviews .
Creiamo alcune funzioni ausiliarie per tracciare e calcolare metriche di convalida e test.
def analyze_two_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def two_d_pred(avg_ratings, num_reviews):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
def two_d_click_through_rate(avg_ratings, num_reviews):
return np.mean([
click_through_rate(avg_ratings, num_reviews,
np.repeat(d, len(avg_ratings)))
for d in ["D", "DD", "DDD", "DDDD"]
],
axis=0)
figsize(11, 5)
plot_fns([("{} Estimated CTR".format(name), two_d_pred),
("CTR", two_d_click_through_rate)],
split_by_dollar=False)
Possiamo adattare alberi decisionali con gradiente boost di TensorFlow sul set di dati:
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
gbt_estimator = tf.estimator.BoostedTreesClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
n_batches_per_layer=1,
max_depth=2,
n_trees=50,
learning_rate=0.05,
config=tf.estimator.RunConfig(tf_random_seed=42),
)
gbt_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(gbt_estimator, "GBT")
Validation AUC: 0.6333084106445312 Testing AUC: 0.774649977684021
Anche se il modello ha catturato la forma generale del vero CTR e ha metriche di convalida decenti, ha un comportamento controintuitivo in diverse parti dello spazio di input: il CTR stimato diminuisce all'aumentare della valutazione media o del numero di recensioni. Ciò è dovuto alla mancanza di punti campione in aree non ben coperte dal set di dati di addestramento. Il modello semplicemente non ha modo di dedurre il comportamento corretto esclusivamente dai dati.
Per risolvere questo problema, applichiamo il vincolo di forma che il modello deve produrre valori monotonicamente crescenti rispetto sia alla valutazione media che al numero di recensioni. Vedremo in seguito come implementarlo in TFL.
Adattare un DNN
Possiamo ripetere gli stessi passaggi con un classificatore DNN. Possiamo osservare un modello simile: non avere abbastanza punti campione con un piccolo numero di revisioni si traduce in un'estrapolazione senza senso. Si noti che anche se la metrica di convalida è migliore della soluzione ad albero, la metrica di test è molto peggiore.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
dnn_estimator = tf.estimator.DNNClassifier(
feature_columns=feature_columns,
# Hyper-params optimized on validation set.
hidden_units=[16, 8, 8],
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
dnn_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(dnn_estimator, "DNN")
Validation AUC: 0.6696228981018066 Testing AUC: 0.750156044960022
Vincoli di forma
TensorFlow Lattice (TFL) si concentra sull'applicazione dei vincoli di forma per salvaguardare il comportamento del modello oltre i dati di addestramento. Questi vincoli di forma vengono applicati ai livelli TFL Keras. I loro dettagli possono essere trovati nel nostro giornale JMLR .
In questo tutorial usiamo stimatori fissi TF per coprire vari vincoli di forma, ma tieni presente che tutti questi passaggi possono essere eseguiti con modelli creati da livelli TFL Keras.
Come con qualsiasi altro stimatore tensorflow, TFL scatola stimatori usano includono colonne per definire il formato di ingresso e utilizzare un input_fn formazione per passare nei dati. L'utilizzo di stimatori fissi TFL richiede anche:
- un modello di configurazione: definizione dell'architettura modello e per-funzione vincoli di forma e regularizers.
- un'analisi caratteristica input_fn: un TF input_fn passaggio di dati per TFL inizializzazione.
Per una descrizione più approfondita, fare riferimento al tutorial sugli estimatori predefiniti o ai documenti API.
Monotonicità
Per prima cosa affrontiamo i problemi di monotonicità aggiungendo vincoli di forma di monotonicità a entrambe le caratteristiche.
Per indicare a TFL per far rispettare i vincoli di forma, specifichiamo i vincoli nella funzionalità configurazioni. Illustra il codice seguente come possiamo richiedere l'output di essere monotona crescente rispetto sia num_reviews e avg_rating impostando monotonicity="increasing" .
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
Validation AUC: 0.6565533876419067 Testing AUC: 0.7784258723258972
Utilizzando una CalibratedLatticeConfig crea un classificatore scatola che prima si applica un calibratore per ciascun ingresso (una funzione lineare a tratti per caratteristiche numeriche) seguito da uno strato di lattice per non lineare fusibile caratteristiche calibrate. Possiamo usare tfl.visualization per visualizzare il modello. In particolare, il grafico seguente mostra i due calibratori addestrati inclusi nel classificatore in scatola.
def save_and_visualize_lattice(tfl_estimator):
saved_model_path = tfl_estimator.export_saved_model(
"/tmp/TensorFlow_Lattice_101/",
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=tf.feature_column.make_parse_example_spec(
feature_columns)))
model_graph = tfl.estimators.get_model_graph(saved_model_path)
figsize(8, 8)
tfl.visualization.draw_model_graph(model_graph)
return model_graph
_ = save_and_visualize_lattice(tfl_estimator)
Con l'aggiunta dei vincoli, il CTR stimato aumenterà sempre all'aumentare della valutazione media o del numero di recensioni. Questo viene fatto assicurandosi che i calibratori e il reticolo siano monotoni.
Rendimenti decrescenti
Rendimenti decrescenti significa che il guadagno marginale di aumentare un certo valore caratteristica diminuisce man mano aumentiamo il valore. Nel nostro caso ci aspettiamo che il num_reviews funzione segue questo modello, in modo che possiamo configurare il suo calibratore di conseguenza. Si noti che possiamo scomporre i rendimenti decrescenti in due condizioni sufficienti:
- il calibratore è monotono crescente, e
- il calibratore è concavo.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891247272491455
Nota come la metrica di test migliora aggiungendo il vincolo di concavità. Anche la trama della previsione assomiglia meglio alla verità fondamentale.
Vincolo della forma 2D: fiducia
Una valutazione a 5 stelle per un ristorante con solo una o due recensioni è probabilmente una valutazione inaffidabile (il ristorante potrebbe non essere effettivamente buono), mentre una valutazione a 4 stelle per un ristorante con centinaia di recensioni è molto più affidabile (il ristorante è probabilmente buono in questo caso). Possiamo vedere che il numero di recensioni di un ristorante influisce sulla fiducia che riponiamo nella sua valutazione media.
Possiamo esercitare i vincoli di fiducia TFL per informare il modello che il valore più grande (o più piccolo) di una caratteristica indica più affidamento o fiducia di un'altra caratteristica. Questo viene fatto impostando reflects_trust_in configurazione nella funzione di configurazione.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
# Larger num_reviews indicating more trust in avg_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
model_graph = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6409633755683899 Testing AUC: 0.7891043424606323
Il grafico seguente presenta la funzione reticolare addestrata. A causa del vincolo fiducia, ci aspettiamo che valori più grandi di calibrate num_reviews obbligherebbero pendenza maggiore rispetto calibrato avg_rating , risultando in un movimento più significativo nell'output reticolo.
lat_mesh_n = 12
lat_mesh_x, lat_mesh_y = tfl.test_utils.two_dim_mesh_grid(
lat_mesh_n**2, 0, 0, 1, 1)
lat_mesh_fn = tfl.test_utils.get_hypercube_interpolation_fn(
model_graph.output_node.weights.flatten())
lat_mesh_z = [
lat_mesh_fn([lat_mesh_x.flatten()[i],
lat_mesh_y.flatten()[i]]) for i in range(lat_mesh_n**2)
]
trust_plt = tfl.visualization.plot_outputs(
(lat_mesh_x, lat_mesh_y),
{"Lattice Lookup": lat_mesh_z},
figsize=(6, 6),
)
trust_plt.title("Trust")
trust_plt.xlabel("Calibrated avg_rating")
trust_plt.ylabel("Calibrated num_reviews")
trust_plt.show()
Calibratori leviganti
Diamo ora uno sguardo al calibratore di avg_rating . Sebbene sia in aumento monotono, i cambiamenti nelle sue pendenze sono bruschi e difficili da interpretare. Questo suggerisce che si potrebbe prendere in considerazione lisciatura questo calibratore utilizzando un setup regolarizzatore nelle regularizer_configs .
Qui si applica una wrinkle regolarizzatore per ridurre i cambiamenti nella curvatura. È inoltre possibile utilizzare il laplacian regolarizzatore per appiattire il calibratore e la hessian regolarizzatore per renderlo più lineare.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
)
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_two_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.6465646028518677 Testing AUC: 0.7948372960090637
I calibratori ora sono lisci e il CTR stimato complessivo corrisponde meglio alla verità del terreno. Ciò si riflette sia nella metrica di prova che nei grafici di contorno.
Monotonicità parziale per calibrazione categoriale
Finora abbiamo utilizzato solo due delle funzioni numeriche nel modello. Qui aggiungeremo una terza funzionalità utilizzando un livello di calibrazione categoriale. Di nuovo iniziamo impostando le funzioni di supporto per la stampa e il calcolo metrico.
def analyze_three_d_estimator(estimator, name):
# Extract validation metrics.
metric = estimator.evaluate(input_fn=val_input_fn)
print("Validation AUC: {}".format(metric["auc"]))
metric = estimator.evaluate(input_fn=test_input_fn)
print("Testing AUC: {}".format(metric["auc"]))
def three_d_pred(avg_ratings, num_reviews, dollar_rating):
results = estimator.predict(
tf.compat.v1.estimator.inputs.pandas_input_fn(
x=pd.DataFrame({
"avg_rating": avg_ratings,
"num_reviews": num_reviews,
"dollar_rating": dollar_rating,
}),
shuffle=False,
))
return [x["logistic"][0] for x in results]
figsize(11, 22)
plot_fns([("{} Estimated CTR".format(name), three_d_pred),
("CTR", click_through_rate)],
split_by_dollar=True)
Coinvolgere la terza caratteristica, dollar_rating , è opportuno ricordare che le caratteristiche categoriali richiedono un trattamento leggermente diverso TFL, sia come colonna caratteristica e come caratteristica configurazione. Qui applichiamo il vincolo di monotonicità parziale secondo cui gli output per i ristoranti "DD" dovrebbero essere più grandi dei ristoranti "D" quando tutti gli altri input sono fissi. Questo viene fatto usando la monotonicity impostazione della funzione di configurazione.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7699775695800781 Testing AUC: 0.8594040274620056
Questo calibratore categorico mostra la preferenza dell'output del modello: DD > D > DDD > DDDD, che è coerente con la nostra configurazione. Notare che c'è anche una colonna per i valori mancanti. Sebbene non ci siano funzionalità mancanti nei nostri dati di addestramento e test, il modello ci fornisce un'imputazione per il valore mancante nel caso in cui si verificasse durante la pubblicazione del modello a valle.
Qui abbiamo anche tracciare la CTR previsto di questo modello condizione dollar_rating . Notare che tutti i vincoli richiesti sono soddisfatti in ciascuna delle sezioni.
Calibrazione dell'uscita
Per tutti i modelli TFL che abbiamo addestrato finora, lo strato reticolare (indicato come "Lattice" nel grafico del modello) emette direttamente la previsione del modello. A volte non siamo sicuri se l'output del reticolo debba essere ridimensionato per emettere gli output del modello:
- le caratteristiche sono \(log\) conta, mentre le etichette sono conteggi.
- il reticolo è configurato per avere pochissimi vertici ma la distribuzione delle etichette è relativamente complicata.
In questi casi possiamo aggiungere un altro calibratore tra l'output del reticolo e l'output del modello per aumentare la flessibilità del modello. Qui aggiungiamo un livello calibratore con 5 punti chiave al modello che abbiamo appena costruito. Aggiungiamo anche un regolarizzatore per il calibratore di uscita per mantenere la funzione fluida.
feature_columns = [
tf.feature_column.numeric_column("num_reviews"),
tf.feature_column.numeric_column("avg_rating"),
tf.feature_column.categorical_column_with_vocabulary_list(
"dollar_rating",
vocabulary_list=["D", "DD", "DDD", "DDDD"],
dtype=tf.string,
default_value=0),
]
model_config = tfl.configs.CalibratedLatticeConfig(
output_calibration=True,
output_calibration_num_keypoints=5,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="output_calib_wrinkle", l2=0.1),
],
feature_configs=[
tfl.configs.FeatureConfig(
name="num_reviews",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_convexity="concave",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="avg_rating", trust_type="edgeworth"),
],
),
tfl.configs.FeatureConfig(
name="avg_rating",
lattice_size=2,
monotonicity="increasing",
pwl_calibration_num_keypoints=20,
regularizer_configs=[
tfl.configs.RegularizerConfig(name="calib_wrinkle", l2=1.0),
],
),
tfl.configs.FeatureConfig(
name="dollar_rating",
lattice_size=2,
pwl_calibration_num_keypoints=4,
# Here we only specify one monotonicity:
# `D` resturants has smaller value than `DD` restaurants
monotonicity=[("D", "DD")],
),
])
tfl_estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42),
)
tfl_estimator.train(input_fn=train_input_fn)
analyze_three_d_estimator(tfl_estimator, "TF Lattice")
_ = save_and_visualize_lattice(tfl_estimator)
Validation AUC: 0.7697908878326416 Testing AUC: 0.861327052116394
La metrica di test finale e i grafici mostrano come l'utilizzo di vincoli di buon senso può aiutare il modello a evitare comportamenti imprevisti ed estrapolare meglio l'intero spazio di input.