
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Możesz użyć warstw TFL Keras do konstruowania modeli Keras z monotonicznością i innymi ograniczeniami kształtu. Ten przykład buduje i trenuje skalibrowany model sieci dla zestawu danych serca UCI przy użyciu warstw TFL.
W skalibrowanej kratowego modelu każda cecha jest przekształcany przez tfl.layers.PWLCalibration lub tfl.layers.CategoricalCalibration warstwy, a wyniki są nieliniowo fuzji stosując tfl.layers.Lattice .
Ustawiać
Instalowanie pakietu TF Lattice:
pip install -q tensorflow-lattice pydot
Importowanie wymaganych pakietów:
import tensorflow as tf
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
from tensorflow import feature_column as fc
logging.disable(sys.maxsize)
Pobieranie zbioru danych UCI Statlog (Heart):
# UCI Statlog (Heart) dataset.
csv_file = tf.keras.utils.get_file(
'heart.csv', 'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
training_data_df = pd.read_csv(csv_file).sample(
frac=1.0, random_state=41).reset_index(drop=True)
training_data_df.head()
Ustawianie wartości domyślnych używanych do szkolenia w tym przewodniku:
LEARNING_RATE = 0.1
BATCH_SIZE = 128
NUM_EPOCHS = 100
Sekwencyjny model Keras
Ten przykład tworzy model Sequential Keras i używa tylko warstw TFL.
Kratowe warstwy spodziewać input[i] , aby znajdować się w [0, lattice_sizes[i] - 1.0] , więc musimy zdefiniować kratownica rozmiary przed warstw kalibracji, dzięki czemu możemy prawidłowo określić zakres wyjściowy warstw kalibracji.
# Lattice layer expects input[i] to be within [0, lattice_sizes[i] - 1.0], so
lattice_sizes = [3, 2, 2, 2, 2, 2, 2]
Używamy tfl.layers.ParallelCombination warstwy do warstwy razem grupę kalibracyjnych, które muszą być wykonywane równolegle, w celu umożliwienia tworzenia sekwencyjnego model.
combined_calibrators = tfl.layers.ParallelCombination()
Tworzymy warstwę kalibracyjną dla każdego obiektu i dodajemy ją do równoległej warstwy kombinacji. Dla funkcji liczbowych używamy tfl.layers.PWLCalibration , a kategoryczne funkcji używamy tfl.layers.CategoricalCalibration .
# ############### age ###############
calibrator = tfl.layers.PWLCalibration(
# Every PWLCalibration layer must have keypoints of piecewise linear
# function specified. Easiest way to specify them is to uniformly cover
# entire input range by using numpy.linspace().
input_keypoints=np.linspace(
training_data_df['age'].min(), training_data_df['age'].max(), num=5),
# You need to ensure that input keypoints have same dtype as layer input.
# You can do it by setting dtype here or by providing keypoints in such
# format which will be converted to desired tf.dtype by default.
dtype=tf.float32,
# Output range must correspond to expected lattice input range.
output_min=0.0,
output_max=lattice_sizes[0] - 1.0,
)
combined_calibrators.append(calibrator)
# ############### sex ###############
# For boolean features simply specify CategoricalCalibration layer with 2
# buckets.
calibrator = tfl.layers.CategoricalCalibration(
num_buckets=2,
output_min=0.0,
output_max=lattice_sizes[1] - 1.0,
# Initializes all outputs to (output_min + output_max) / 2.0.
kernel_initializer='constant')
combined_calibrators.append(calibrator)
# ############### cp ###############
calibrator = tfl.layers.PWLCalibration(
# Here instead of specifying dtype of layer we convert keypoints into
# np.float32.
input_keypoints=np.linspace(1, 4, num=4, dtype=np.float32),
output_min=0.0,
output_max=lattice_sizes[2] - 1.0,
monotonicity='increasing',
# You can specify TFL regularizers as a tuple ('regularizer name', l1, l2).
kernel_regularizer=('hessian', 0.0, 1e-4))
combined_calibrators.append(calibrator)
# ############### trestbps ###############
calibrator = tfl.layers.PWLCalibration(
# Alternatively, you might want to use quantiles as keypoints instead of
# uniform keypoints
input_keypoints=np.quantile(training_data_df['trestbps'],
np.linspace(0.0, 1.0, num=5)),
dtype=tf.float32,
# Together with quantile keypoints you might want to initialize piecewise
# linear function to have 'equal_slopes' in order for output of layer
# after initialization to preserve original distribution.
kernel_initializer='equal_slopes',
output_min=0.0,
output_max=lattice_sizes[3] - 1.0,
# You might consider clamping extreme inputs of the calibrator to output
# bounds.
clamp_min=True,
clamp_max=True,
monotonicity='increasing')
combined_calibrators.append(calibrator)
# ############### chol ###############
calibrator = tfl.layers.PWLCalibration(
# Explicit input keypoint initialization.
input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
dtype=tf.float32,
output_min=0.0,
output_max=lattice_sizes[4] - 1.0,
# Monotonicity of calibrator can be decreasing. Note that corresponding
# lattice dimension must have INCREASING monotonicity regardless of
# monotonicity direction of calibrator.
monotonicity='decreasing',
# Convexity together with decreasing monotonicity result in diminishing
# return constraint.
convexity='convex',
# You can specify list of regularizers. You are not limited to TFL
# regularizrs. Feel free to use any :)
kernel_regularizer=[('laplacian', 0.0, 1e-4),
tf.keras.regularizers.l1_l2(l1=0.001)])
combined_calibrators.append(calibrator)
# ############### fbs ###############
calibrator = tfl.layers.CategoricalCalibration(
num_buckets=2,
output_min=0.0,
output_max=lattice_sizes[5] - 1.0,
# For categorical calibration layer monotonicity is specified for pairs
# of indices of categories. Output for first category in pair will be
# smaller than output for second category.
#
# Don't forget to set monotonicity of corresponding dimension of Lattice
# layer to '1'.
monotonicities=[(0, 1)],
# This initializer is identical to default one('uniform'), but has fixed
# seed in order to simplify experimentation.
kernel_initializer=tf.keras.initializers.RandomUniform(
minval=0.0, maxval=lattice_sizes[5] - 1.0, seed=1))
combined_calibrators.append(calibrator)
# ############### restecg ###############
calibrator = tfl.layers.CategoricalCalibration(
num_buckets=3,
output_min=0.0,
output_max=lattice_sizes[6] - 1.0,
# Categorical monotonicity can be partial order.
monotonicities=[(0, 1), (0, 2)],
# Categorical calibration layer supports standard Keras regularizers.
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=0.001),
kernel_initializer='constant')
combined_calibrators.append(calibrator)
Następnie tworzymy warstwę sieciową, aby nieliniowo łączyć wyjścia kalibratorów.
Zauważ, że musimy określić monotoniczność sieci, która będzie wzrastać dla wymaganych wymiarów. Kompozycja z kierunkiem monotoniczności w kalibracji da w wyniku prawidłowy kierunek monotoniczności od końca do końca. Obejmuje to częściową monotoniczność warstwy kalibracji kategorii.
lattice = tfl.layers.Lattice(
lattice_sizes=lattice_sizes,
monotonicities=[
'increasing', 'none', 'increasing', 'increasing', 'increasing',
'increasing', 'increasing'
],
output_min=0.0,
output_max=1.0)
Następnie możemy stworzyć model sekwencyjny, korzystając z połączonych kalibratorów i warstw siatki.
model = tf.keras.models.Sequential()
model.add(combined_calibrators)
model.add(lattice)
Trening działa tak samo, jak każdy inny model Keras.
features = training_data_df[[
'age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg'
]].values.astype(np.float32)
target = training_data_df[['target']].values.astype(np.float32)
model.compile(
loss=tf.keras.losses.mean_squared_error,
optimizer=tf.keras.optimizers.Adagrad(learning_rate=LEARNING_RATE))
model.fit(
features,
target,
batch_size=BATCH_SIZE,
epochs=NUM_EPOCHS,
validation_split=0.2,
shuffle=False,
verbose=0)
model.evaluate(features, target)
10/10 [==============================] - 0s 1ms/step - loss: 0.1551 0.15506614744663239
Funkcjonalny model Keras
Ten przykład używa funkcjonalnego API do budowy modelu Keras.
Jak wspomniano w poprzednim rozdziale, kratowe warstwy oczekiwać input[i] , aby znajdować się w [0, lattice_sizes[i] - 1.0] , więc musimy zdefiniować kratownica rozmiary przed warstw kalibracji, dzięki czemu możemy prawidłowo określić zakres wyjściowy warstwy kalibracyjne.
# We are going to have 2-d embedding as one of lattice inputs.
lattice_sizes = [3, 2, 2, 3, 3, 2, 2]
Dla każdego obiektu musimy utworzyć warstwę wejściową, a następnie warstwę kalibracyjną. Dla funkcji liczbowych używamy tfl.layers.PWLCalibration i kategorycznych funkcji używamy tfl.layers.CategoricalCalibration .
model_inputs = []
lattice_inputs = []
# ############### age ###############
age_input = tf.keras.layers.Input(shape=[1], name='age')
model_inputs.append(age_input)
age_calibrator = tfl.layers.PWLCalibration(
# Every PWLCalibration layer must have keypoints of piecewise linear
# function specified. Easiest way to specify them is to uniformly cover
# entire input range by using numpy.linspace().
input_keypoints=np.linspace(
training_data_df['age'].min(), training_data_df['age'].max(), num=5),
# You need to ensure that input keypoints have same dtype as layer input.
# You can do it by setting dtype here or by providing keypoints in such
# format which will be converted to desired tf.dtype by default.
dtype=tf.float32,
# Output range must correspond to expected lattice input range.
output_min=0.0,
output_max=lattice_sizes[0] - 1.0,
monotonicity='increasing',
name='age_calib',
)(
age_input)
lattice_inputs.append(age_calibrator)
# ############### sex ###############
# For boolean features simply specify CategoricalCalibration layer with 2
# buckets.
sex_input = tf.keras.layers.Input(shape=[1], name='sex')
model_inputs.append(sex_input)
sex_calibrator = tfl.layers.CategoricalCalibration(
num_buckets=2,
output_min=0.0,
output_max=lattice_sizes[1] - 1.0,
# Initializes all outputs to (output_min + output_max) / 2.0.
kernel_initializer='constant',
name='sex_calib',
)(
sex_input)
lattice_inputs.append(sex_calibrator)
# ############### cp ###############
cp_input = tf.keras.layers.Input(shape=[1], name='cp')
model_inputs.append(cp_input)
cp_calibrator = tfl.layers.PWLCalibration(
# Here instead of specifying dtype of layer we convert keypoints into
# np.float32.
input_keypoints=np.linspace(1, 4, num=4, dtype=np.float32),
output_min=0.0,
output_max=lattice_sizes[2] - 1.0,
monotonicity='increasing',
# You can specify TFL regularizers as tuple ('regularizer name', l1, l2).
kernel_regularizer=('hessian', 0.0, 1e-4),
name='cp_calib',
)(
cp_input)
lattice_inputs.append(cp_calibrator)
# ############### trestbps ###############
trestbps_input = tf.keras.layers.Input(shape=[1], name='trestbps')
model_inputs.append(trestbps_input)
trestbps_calibrator = tfl.layers.PWLCalibration(
# Alternatively, you might want to use quantiles as keypoints instead of
# uniform keypoints
input_keypoints=np.quantile(training_data_df['trestbps'],
np.linspace(0.0, 1.0, num=5)),
dtype=tf.float32,
# Together with quantile keypoints you might want to initialize piecewise
# linear function to have 'equal_slopes' in order for output of layer
# after initialization to preserve original distribution.
kernel_initializer='equal_slopes',
output_min=0.0,
output_max=lattice_sizes[3] - 1.0,
# You might consider clamping extreme inputs of the calibrator to output
# bounds.
clamp_min=True,
clamp_max=True,
monotonicity='increasing',
name='trestbps_calib',
)(
trestbps_input)
lattice_inputs.append(trestbps_calibrator)
# ############### chol ###############
chol_input = tf.keras.layers.Input(shape=[1], name='chol')
model_inputs.append(chol_input)
chol_calibrator = tfl.layers.PWLCalibration(
# Explicit input keypoint initialization.
input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
output_min=0.0,
output_max=lattice_sizes[4] - 1.0,
# Monotonicity of calibrator can be decreasing. Note that corresponding
# lattice dimension must have INCREASING monotonicity regardless of
# monotonicity direction of calibrator.
monotonicity='decreasing',
# Convexity together with decreasing monotonicity result in diminishing
# return constraint.
convexity='convex',
# You can specify list of regularizers. You are not limited to TFL
# regularizrs. Feel free to use any :)
kernel_regularizer=[('laplacian', 0.0, 1e-4),
tf.keras.regularizers.l1_l2(l1=0.001)],
name='chol_calib',
)(
chol_input)
lattice_inputs.append(chol_calibrator)
# ############### fbs ###############
fbs_input = tf.keras.layers.Input(shape=[1], name='fbs')
model_inputs.append(fbs_input)
fbs_calibrator = tfl.layers.CategoricalCalibration(
num_buckets=2,
output_min=0.0,
output_max=lattice_sizes[5] - 1.0,
# For categorical calibration layer monotonicity is specified for pairs
# of indices of categories. Output for first category in pair will be
# smaller than output for second category.
#
# Don't forget to set monotonicity of corresponding dimension of Lattice
# layer to '1'.
monotonicities=[(0, 1)],
# This initializer is identical to default one ('uniform'), but has fixed
# seed in order to simplify experimentation.
kernel_initializer=tf.keras.initializers.RandomUniform(
minval=0.0, maxval=lattice_sizes[5] - 1.0, seed=1),
name='fbs_calib',
)(
fbs_input)
lattice_inputs.append(fbs_calibrator)
# ############### restecg ###############
restecg_input = tf.keras.layers.Input(shape=[1], name='restecg')
model_inputs.append(restecg_input)
restecg_calibrator = tfl.layers.CategoricalCalibration(
num_buckets=3,
output_min=0.0,
output_max=lattice_sizes[6] - 1.0,
# Categorical monotonicity can be partial order.
monotonicities=[(0, 1), (0, 2)],
# Categorical calibration layer supports standard Keras regularizers.
kernel_regularizer=tf.keras.regularizers.l1_l2(l1=0.001),
kernel_initializer='constant',
name='restecg_calib',
)(
restecg_input)
lattice_inputs.append(restecg_calibrator)
Następnie tworzymy warstwę sieciową, aby nieliniowo łączyć wyjścia kalibratorów.
Zauważ, że musimy określić monotoniczność sieci, która będzie wzrastać dla wymaganych wymiarów. Kompozycja z kierunkiem monotoniczności w kalibracji da w wyniku prawidłowy kierunek monotoniczności od końca do końca. Obejmuje częściową monotoniczności tfl.layers.CategoricalCalibration warstwy.
lattice = tfl.layers.Lattice(
lattice_sizes=lattice_sizes,
monotonicities=[
'increasing', 'none', 'increasing', 'increasing', 'increasing',
'increasing', 'increasing'
],
output_min=0.0,
output_max=1.0,
name='lattice',
)(
lattice_inputs)
Aby zwiększyć elastyczność modelu, dodajemy warstwę kalibracji wyjściowej.
model_output = tfl.layers.PWLCalibration(
input_keypoints=np.linspace(0.0, 1.0, 5),
name='output_calib',
)(
lattice)
Możemy teraz stworzyć model za pomocą wejść i wyjść.
model = tf.keras.models.Model(
inputs=model_inputs,
outputs=model_output)
tf.keras.utils.plot_model(model, rankdir='LR')
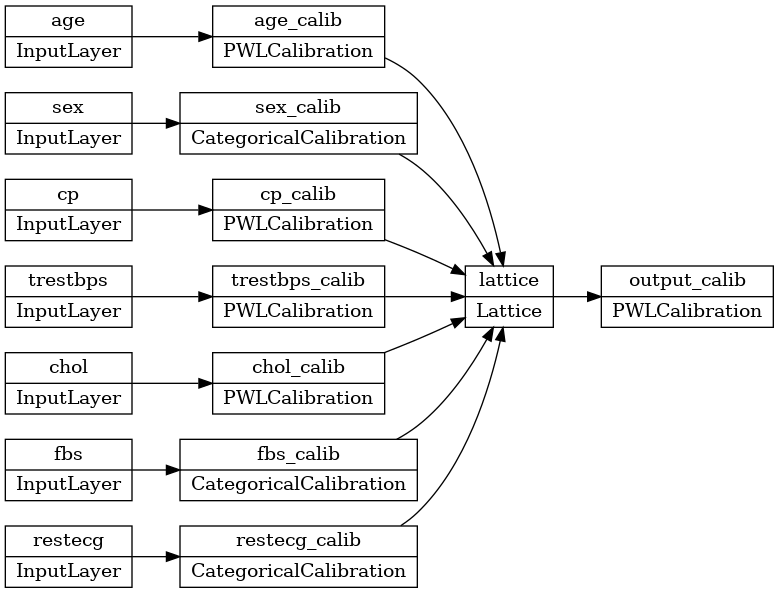
Trening działa tak samo, jak każdy inny model Keras. Zauważ, że w naszej konfiguracji funkcje wejściowe są przekazywane jako osobne tensory.
feature_names = ['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg']
features = np.split(
training_data_df[feature_names].values.astype(np.float32),
indices_or_sections=len(feature_names),
axis=1)
target = training_data_df[['target']].values.astype(np.float32)
model.compile(
loss=tf.keras.losses.mean_squared_error,
optimizer=tf.keras.optimizers.Adagrad(LEARNING_RATE))
model.fit(
features,
target,
batch_size=BATCH_SIZE,
epochs=NUM_EPOCHS,
validation_split=0.2,
shuffle=False,
verbose=0)
model.evaluate(features, target)
10/10 [==============================] - 0s 1ms/step - loss: 0.1590 0.15900751948356628