
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
بررسی اجمالی
برآوردگرهای کنسرو شده راه های سریع و آسانی برای آموزش مدل های TFL برای موارد استفاده معمولی هستند. این راهنما مراحل مورد نیاز برای ایجاد یک برآوردگر کنسرو TFL را تشریح می کند.
برپایی
نصب پکیج TF Lattice:
pip install tensorflow-lattice
واردات بسته های مورد نیاز:
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
from tensorflow import feature_column as fc
logging.disable(sys.maxsize)
دانلود مجموعه داده UCI Statlog (Heart):
csv_file = tf.keras.utils.get_file(
'heart.csv', 'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
df = pd.read_csv(csv_file)
target = df.pop('target')
train_size = int(len(df) * 0.8)
train_x = df[:train_size]
train_y = target[:train_size]
test_x = df[train_size:]
test_y = target[train_size:]
df.head()
تنظیم مقادیر پیش فرض مورد استفاده برای آموزش در این راهنما:
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
ستون های ویژگی
همانطور که برای هر برآوردگر TF دیگر، نیازهای داده به برآوردگر، که معمولا از طریق یک input_fn منتقل می شود و تجزیه با استفاده از FeatureColumns .
# Feature columns.
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal 3 = normal; 6 = fixed defect; 7 = reversable defect
feature_columns = [
fc.numeric_column('age', default_value=-1),
fc.categorical_column_with_vocabulary_list('sex', [0, 1]),
fc.numeric_column('cp'),
fc.numeric_column('trestbps', default_value=-1),
fc.numeric_column('chol'),
fc.categorical_column_with_vocabulary_list('fbs', [0, 1]),
fc.categorical_column_with_vocabulary_list('restecg', [0, 1, 2]),
fc.numeric_column('thalach'),
fc.categorical_column_with_vocabulary_list('exang', [0, 1]),
fc.numeric_column('oldpeak'),
fc.categorical_column_with_vocabulary_list('slope', [0, 1, 2]),
fc.numeric_column('ca'),
fc.categorical_column_with_vocabulary_list(
'thal', ['normal', 'fixed', 'reversible']),
]
برآوردگرهای کنسرو TFL از نوع ستون ویژگی برای تصمیم گیری از نوع لایه کالیبراسیون استفاده می کنند. ما از یک tfl.layers.PWLCalibration لایه برای ستون ویژگی عددی و tfl.layers.CategoricalCalibration لایه برای ستون ویژگی قطعی.
توجه داشته باشید که ستونهای ویژگی طبقهبندی شده توسط یک ستون ویژگی جاسازی پیچیده نمیشوند. آنها مستقیماً به تخمینگر وارد می شوند.
ایجاد input_fn
همانند هر تخمینگر دیگری، میتوانید از input_fn برای تغذیه دادهها به مدل برای آموزش و ارزیابی استفاده کنید. برآوردگرهای TFL می توانند به طور خودکار چندک از ویژگی ها را محاسبه کرده و از آنها به عنوان نقاط کلیدی ورودی لایه کالیبراسیون PWL استفاده کنند. برای این کار، آنها نیاز به عبور از یک feature_analysis_input_fn ، که شبیه به آموزش input_fn اما با یک دوره یک یا نمونهای از داده ها.
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
num_threads=1)
# feature_analysis_input_fn is used to collect statistics about the input.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
# Note that we only need one pass over the data.
num_epochs=1,
num_threads=1)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=test_x,
y=test_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=1,
num_threads=1)
# Serving input fn is used to create saved models.
serving_input_fn = (
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=fc.make_parse_example_spec(feature_columns)))
تنظیمات ویژگی
کالیبراسیون ویژگی ها و تنظیمات هر ویژگی با استفاده از مجموعه ای tfl.configs.FeatureConfig . تنظیمات ویژگی ها عبارتند از محدودیت یکنواختی، در هر ویژگی تنظیم (نگاه کنید به tfl.configs.RegularizerConfig )، و اندازه شبکه برای مدل های شبکه.
اگر هیچ پیکربندی برای یک ویژگی ورودی تعریف شده است، تنظیمات پیش فرض در tfl.config.FeatureConfig استفاده شده است.
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
# By default, input keypoints of pwl are quantiles of the feature.
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='cp',
pwl_calibration_num_keypoints=4,
# Keypoints can be uniformly spaced.
pwl_calibration_input_keypoints='uniform',
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='chol',
# Explicit input keypoint initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
monotonicity='increasing',
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='trestbps',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='thalach',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='oldpeak',
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
),
tfl.configs.FeatureConfig(
name='ca',
pwl_calibration_num_keypoints=4,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
),
]
مدل خطی کالیبره شده
برای ساخت یک TFL کنسرو برآوردگر، ساخت یک پیکربندی مدل از tfl.configs . یک مدل خطی کالیبره با استفاده از ساخته شده است tfl.configs.CalibratedLinearConfig . این کالیبراسیون تکهای خطی و طبقهای را روی ویژگیهای ورودی اعمال میکند، به دنبال آن یک ترکیب خطی و یک کالیبراسیون تکهای خطی خروجی اختیاری انجام میشود. هنگام استفاده از کالیبراسیون خروجی یا زمانی که مرزهای خروجی مشخص می شوند، لایه خطی میانگین وزنی را روی ورودی های کالیبره شده اعمال می کند.
این مثال یک مدل خطی مدرج بر روی 5 ویژگی اول ایجاد می کند. ما با استفاده از tfl.visualization به رسم نمودار مدل با توطئه های کالیبراتور است.
# Model config defines the model structure for the estimator.
model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=feature_configs,
use_bias=True,
output_calibration=True,
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated linear test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
2021-09-30 20:54:06.660239: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected Calibrated linear test AUC: 0.834586501121521
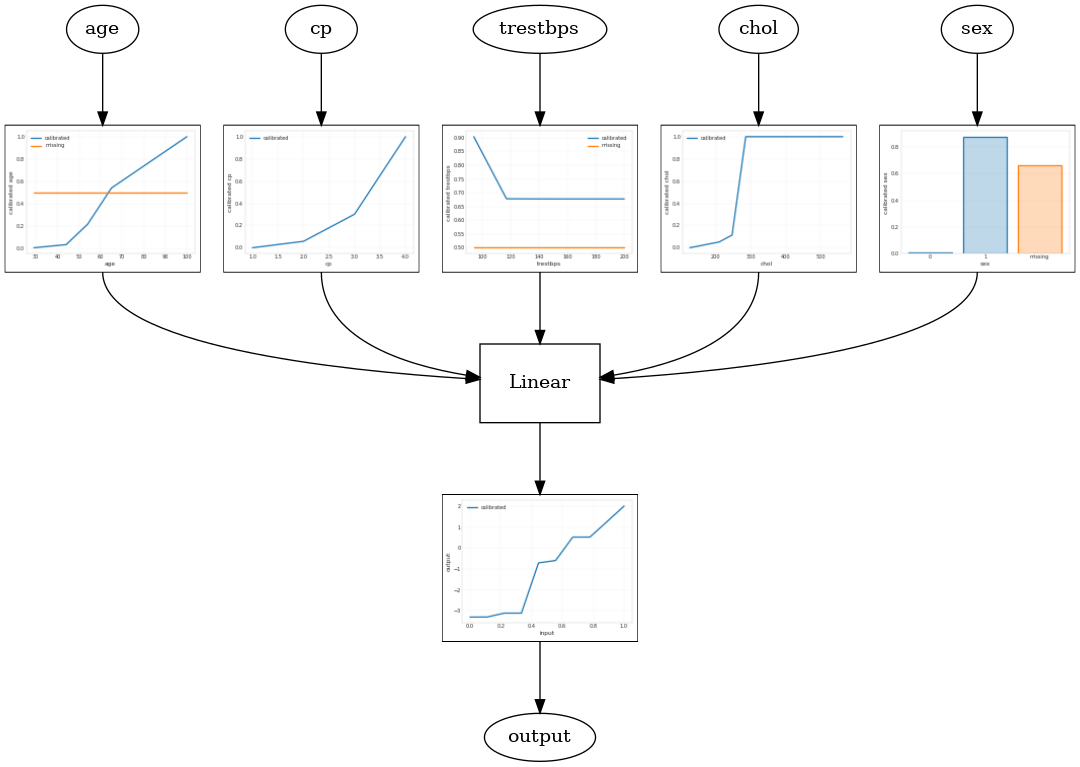
مدل شبکه کالیبره شده
مدل شبکه کالیبره با استفاده از ساخته شده است tfl.configs.CalibratedLatticeConfig . یک مدل شبکه کالیبرهشده، کالیبراسیون تکهای خطی و طبقهای را روی ویژگیهای ورودی اعمال میکند، به دنبال آن یک مدل شبکهای و یک کالیبراسیون تکهای خطی خروجی اختیاری اعمال میشود.
این مثال یک مدل شبکه کالیبره شده روی 5 ویژگی اول ایجاد می کند.
# This is calibrated lattice model: Inputs are calibrated, then combined
# non-linearly using a lattice layer.
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=feature_configs,
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-4),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated lattice test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
Calibrated lattice test AUC: 0.8427318930625916
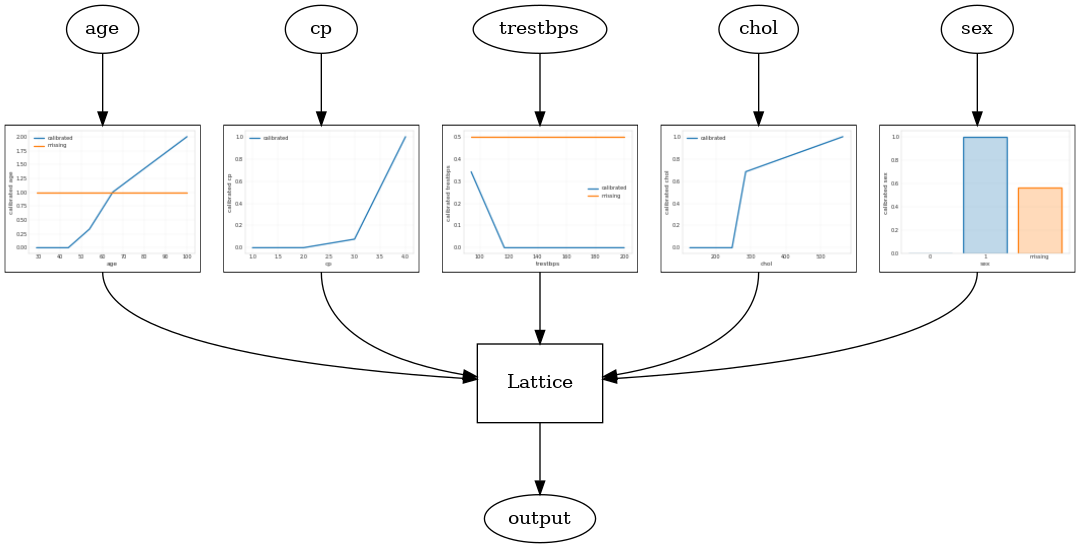
گروه مشبک کالیبره شده
وقتی تعداد ویژگیها زیاد است، میتوانید از یک مدل گروهی استفاده کنید، که شبکههای کوچکتر متعددی را برای زیرمجموعههای ویژگیها ایجاد میکند و بهجای ایجاد یک شبکه بزرگ، خروجی آنها را میانگین میگیرد. مدل های شبکه گروه با استفاده از ساخته tfl.configs.CalibratedLatticeEnsembleConfig . یک مدل مجموعه شبکه کالیبرهشده، کالیبراسیون تکهای خطی و طبقهای را روی ویژگی ورودی اعمال میکند، به دنبال آن مجموعهای از مدلهای شبکه و یک کالیبراسیون تکهای خطی خروجی اختیاری اعمال میشود.
گروه شبکه تصادفی
پیکربندی مدل زیر از یک زیرمجموعه تصادفی از ویژگی ها برای هر شبکه استفاده می کند.
# This is random lattice ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
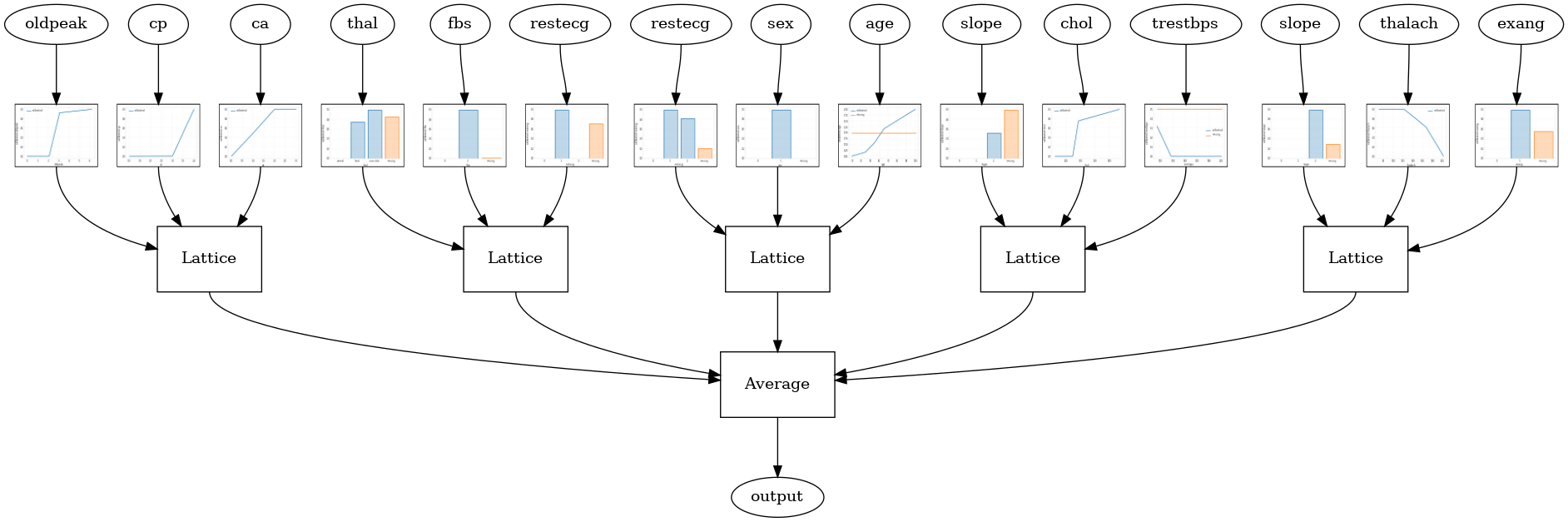
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.9003759026527405
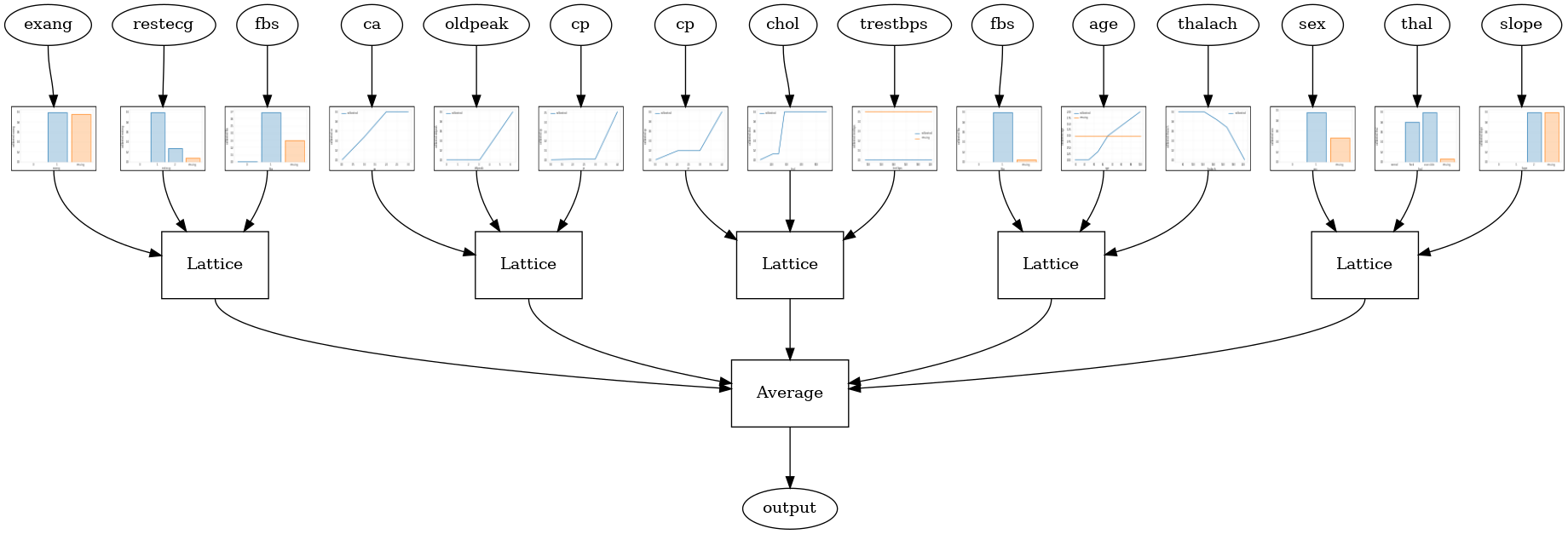
گروه شبکه تصادفی لایه RTL
مدل پیکربندی زیر با استفاده از یک tfl.layers.RTL لایه است که با استفاده از یک زیر مجموعه تصادفی از امکانات را برای هر یک از شبکه. توجه داشته باشید که tfl.layers.RTL تنها پشتیبانی از محدودیت های یکنواختی و باید به اندازه شبکه همان برای تمام ویژگی های و تنظیم هر ویژگی را دارند. توجه داشته باشید که با استفاده از یک tfl.layers.RTL لایه اجازه می دهد تا شما را به گروه بسیار بزرگ تر از با استفاده جداگانه مقیاس tfl.layers.Lattice موارد.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is RTL layer ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
lattices='rtl_layer',
feature_configs=rtl_layer_feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.8903509378433228
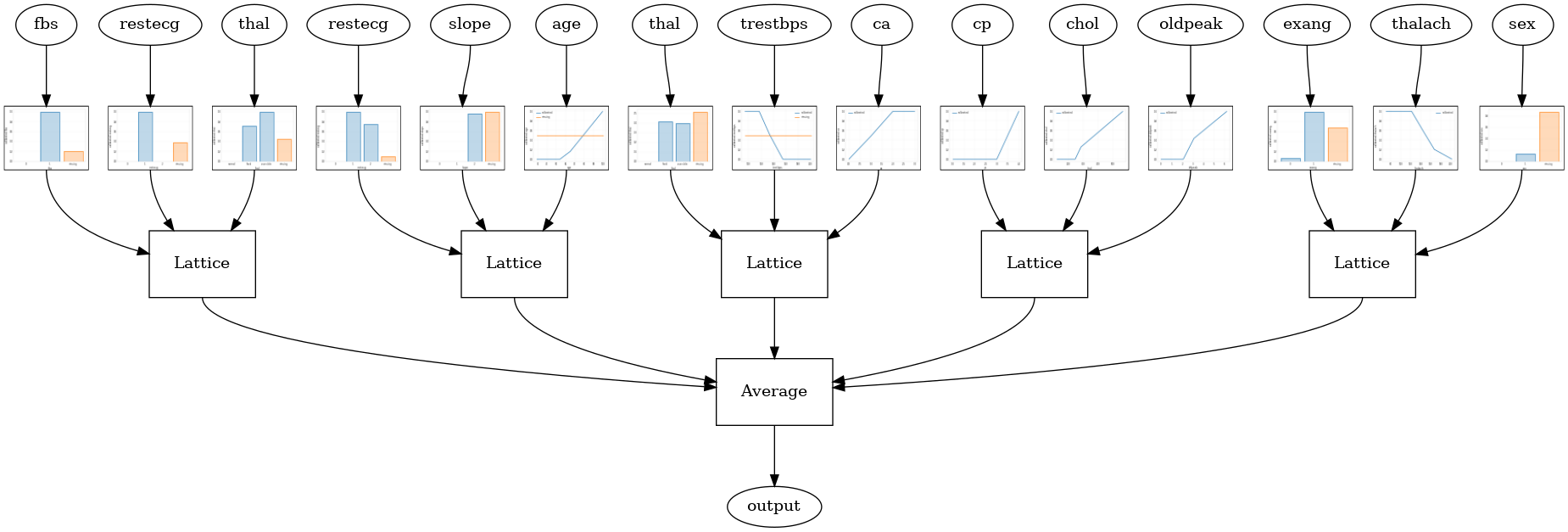
گروه کریستال توری
TFL همچنین یک الگوریتم آرایش ویژگی اکتشافی، به نام فراهم می کند کریستال . کریستال الگوریتم قطار ابتدا مدل prefitting که برآوردهای دو به دو فعل و انفعالات ویژگی. سپس مجموعه نهایی را طوری ترتیب میدهد که ویژگیهایی با برهمکنشهای غیرخطی بیشتر در شبکههای مشابه باشند.
برای مدل های کریستال، شما همچنین نیاز به ارائه یک prefitting_input_fn است که برای آموزش مدل prefitting، همانطور که در بالا توضیح داده شد. مدل پیش ساخته نیازی به آموزش کامل ندارد، بنابراین چند دوره کافی است.
prefitting_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=PREFITTING_NUM_EPOCHS,
num_threads=1)
بعد از آن شما می توانید یک مدل کریستال با تنظیم ایجاد lattice='crystals' در پیکربندی مدل.
# This is Crystals ensemble model with separate calibration: model output is
# the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
# prefitting_input_fn is required to train the prefitting model.
prefitting_input_fn=prefitting_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
prefitting_optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Crystals ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Crystals ensemble test AUC: 0.8840851783752441
شما می توانید کالیبراتورهای ویژگی با جزئیات بیشتر با استفاده از رسم tfl.visualization ماژول.
_ = tfl.visualization.plot_feature_calibrator(model_graph, "age")
_ = tfl.visualization.plot_feature_calibrator(model_graph, "restecg")

