
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Visão geral
Os estimadores prontos são maneiras rápidas e fáceis de treinar modelos TFL para casos de uso típicos. Este guia descreve as etapas necessárias para criar um estimador enlatado TFL.
Configurar
Instalando o pacote TF Lattice:
pip install tensorflow-lattice
Importando pacotes necessários:
import tensorflow as tf
import copy
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
from tensorflow import feature_column as fc
logging.disable(sys.maxsize)
Baixando o conjunto de dados UCI Statlog (Heart):
csv_file = tf.keras.utils.get_file(
'heart.csv', 'http://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
df = pd.read_csv(csv_file)
target = df.pop('target')
train_size = int(len(df) * 0.8)
train_x = df[:train_size]
train_y = target[:train_size]
test_x = df[train_size:]
test_y = target[train_size:]
df.head()
Definindo os valores padrão usados para treinamento neste guia:
LEARNING_RATE = 0.01
BATCH_SIZE = 128
NUM_EPOCHS = 500
PREFITTING_NUM_EPOCHS = 10
Colunas de recursos
Tal como para qualquer outro TF estimador, as necessidades de dados a ser transmitido para o estimador, que é, tipicamente, através de uma input_fn e analisado utilizando FeatureColumns .
# Feature columns.
# - age
# - sex
# - cp chest pain type (4 values)
# - trestbps resting blood pressure
# - chol serum cholestoral in mg/dl
# - fbs fasting blood sugar > 120 mg/dl
# - restecg resting electrocardiographic results (values 0,1,2)
# - thalach maximum heart rate achieved
# - exang exercise induced angina
# - oldpeak ST depression induced by exercise relative to rest
# - slope the slope of the peak exercise ST segment
# - ca number of major vessels (0-3) colored by flourosopy
# - thal 3 = normal; 6 = fixed defect; 7 = reversable defect
feature_columns = [
fc.numeric_column('age', default_value=-1),
fc.categorical_column_with_vocabulary_list('sex', [0, 1]),
fc.numeric_column('cp'),
fc.numeric_column('trestbps', default_value=-1),
fc.numeric_column('chol'),
fc.categorical_column_with_vocabulary_list('fbs', [0, 1]),
fc.categorical_column_with_vocabulary_list('restecg', [0, 1, 2]),
fc.numeric_column('thalach'),
fc.categorical_column_with_vocabulary_list('exang', [0, 1]),
fc.numeric_column('oldpeak'),
fc.categorical_column_with_vocabulary_list('slope', [0, 1, 2]),
fc.numeric_column('ca'),
fc.categorical_column_with_vocabulary_list(
'thal', ['normal', 'fixed', 'reversible']),
]
Os estimadores fixos TFL usam o tipo da coluna de feição para decidir que tipo de camada de calibração usar. Nós usamos um tfl.layers.PWLCalibration camada para colunas de recursos numéricos e uma tfl.layers.CategoricalCalibration camada para colunas recurso categóricas.
Observe que as colunas de recursos categóricas não são agrupadas por uma coluna de recursos de incorporação. Eles são alimentados diretamente no estimador.
Criando input_fn
Como para qualquer outro estimador, você pode usar um input_fn para alimentar dados para o modelo para treinamento e avaliação. Os estimadores TFL podem calcular automaticamente os quantis dos recursos e usá-los como pontos-chave de entrada para a camada de calibração PWL. Para isso, eles exigem a passagem de um feature_analysis_input_fn , que é semelhante à formação input_fn mas com uma única época ou uma sub-amostra dos dados.
train_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=NUM_EPOCHS,
num_threads=1)
# feature_analysis_input_fn is used to collect statistics about the input.
feature_analysis_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
# Note that we only need one pass over the data.
num_epochs=1,
num_threads=1)
test_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=test_x,
y=test_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=1,
num_threads=1)
# Serving input fn is used to create saved models.
serving_input_fn = (
tf.estimator.export.build_parsing_serving_input_receiver_fn(
feature_spec=fc.make_parse_example_spec(feature_columns)))
Configurações de recursos
Calibração recurso e configurações per-recurso são definidos usando tfl.configs.FeatureConfig . Configurações de recursos incluem restrições monotonicidade, regularização per-recurso (ver tfl.configs.RegularizerConfig ) e tamanhos de treliça para os modelos de treliça.
Se nenhuma configuração é definida para um recurso de entrada, a configuração padrão no tfl.config.FeatureConfig é usado.
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='age',
lattice_size=3,
# By default, input keypoints of pwl are quantiles of the feature.
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
pwl_calibration_clip_max=100,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_wrinkle', l2=0.1),
],
),
tfl.configs.FeatureConfig(
name='cp',
pwl_calibration_num_keypoints=4,
# Keypoints can be uniformly spaced.
pwl_calibration_input_keypoints='uniform',
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='chol',
# Explicit input keypoint initialization.
pwl_calibration_input_keypoints=[126.0, 210.0, 247.0, 286.0, 564.0],
monotonicity='increasing',
# Calibration can be forced to span the full output range by clamping.
pwl_calibration_clamp_min=True,
pwl_calibration_clamp_max=True,
# Per feature regularization.
regularizer_configs=[
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
],
),
tfl.configs.FeatureConfig(
name='fbs',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='trestbps',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='thalach',
pwl_calibration_num_keypoints=5,
monotonicity='decreasing',
),
tfl.configs.FeatureConfig(
name='restecg',
# Partial monotonicity: output(0) <= output(1), output(0) <= output(2)
monotonicity=[(0, 1), (0, 2)],
),
tfl.configs.FeatureConfig(
name='exang',
# Partial monotonicity: output(0) <= output(1)
monotonicity=[(0, 1)],
),
tfl.configs.FeatureConfig(
name='oldpeak',
pwl_calibration_num_keypoints=5,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='slope',
# Partial monotonicity: output(0) <= output(1), output(1) <= output(2)
monotonicity=[(0, 1), (1, 2)],
),
tfl.configs.FeatureConfig(
name='ca',
pwl_calibration_num_keypoints=4,
monotonicity='increasing',
),
tfl.configs.FeatureConfig(
name='thal',
# Partial monotonicity:
# output(normal) <= output(fixed)
# output(normal) <= output(reversible)
monotonicity=[('normal', 'fixed'), ('normal', 'reversible')],
),
]
Modelo Linear Calibrado
Para construir um estimador TFL enlatados, construir um modelo de configuração tfl.configs . Um modelo linear calibrada é construído usando tfl.configs.CalibratedLinearConfig . Ele aplica calibração linear por partes e categórica nos recursos de entrada, seguida por uma combinação linear e uma calibração linear por partes de saída opcional. Ao usar a calibração de saída ou quando os limites de saída são especificados, a camada linear aplicará a média ponderada nas entradas calibradas.
Este exemplo cria um modelo linear calibrado nos primeiros 5 recursos. Usamos tfl.visualization para traçar o gráfico modelo com as parcelas do calibrador.
# Model config defines the model structure for the estimator.
model_config = tfl.configs.CalibratedLinearConfig(
feature_configs=feature_configs,
use_bias=True,
output_calibration=True,
regularizer_configs=[
# Regularizer for the output calibrator.
tfl.configs.RegularizerConfig(name='output_calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated linear test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
2021-09-30 20:54:06.660239: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected Calibrated linear test AUC: 0.834586501121521
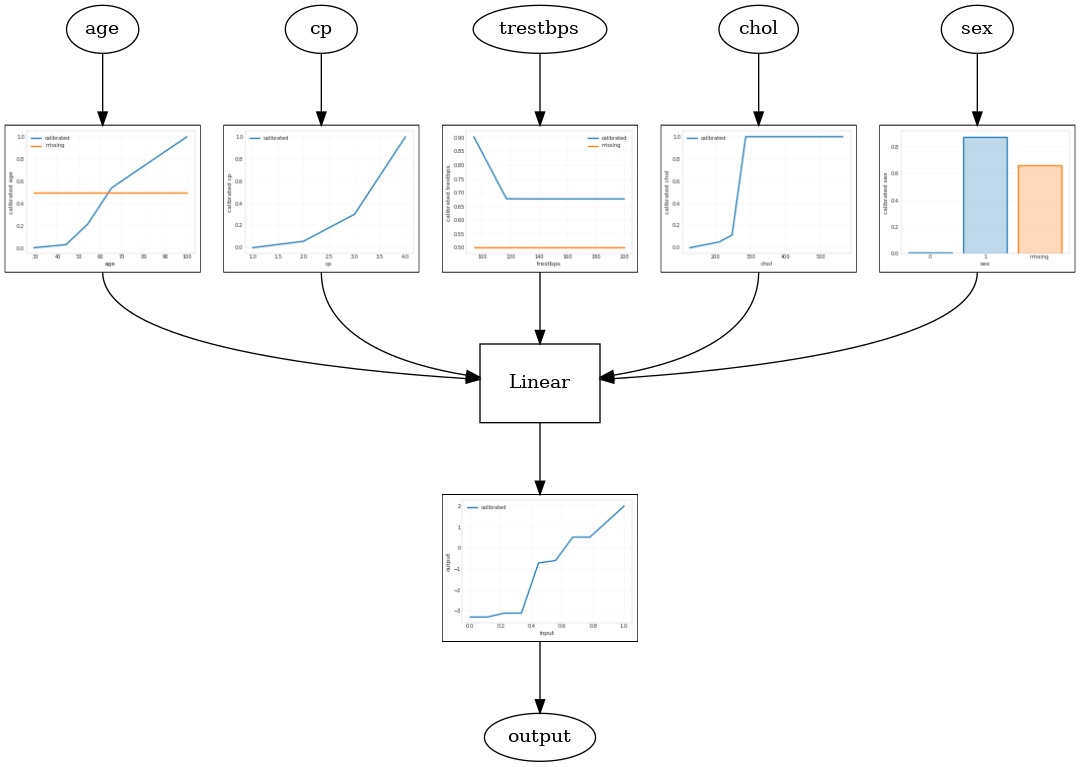
Modelo Calibrado de Malha
Um modelo de rede calibrada é construído usando tfl.configs.CalibratedLatticeConfig . Um modelo de rede calibrado aplica calibração linear por partes e categórica nos recursos de entrada, seguido por um modelo de rede e uma calibração linear por partes de saída opcional.
Este exemplo cria um modelo de rede calibrado nos primeiros 5 recursos.
# This is calibrated lattice model: Inputs are calibrated, then combined
# non-linearly using a lattice layer.
model_config = tfl.configs.CalibratedLatticeConfig(
feature_configs=feature_configs,
regularizer_configs=[
# Torsion regularizer applied to the lattice to make it more linear.
tfl.configs.RegularizerConfig(name='torsion', l2=1e-4),
# Globally defined calibration regularizer is applied to all features.
tfl.configs.RegularizerConfig(name='calib_hessian', l2=1e-4),
])
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns[:5],
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Calibrated lattice test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph)
Calibrated lattice test AUC: 0.8427318930625916
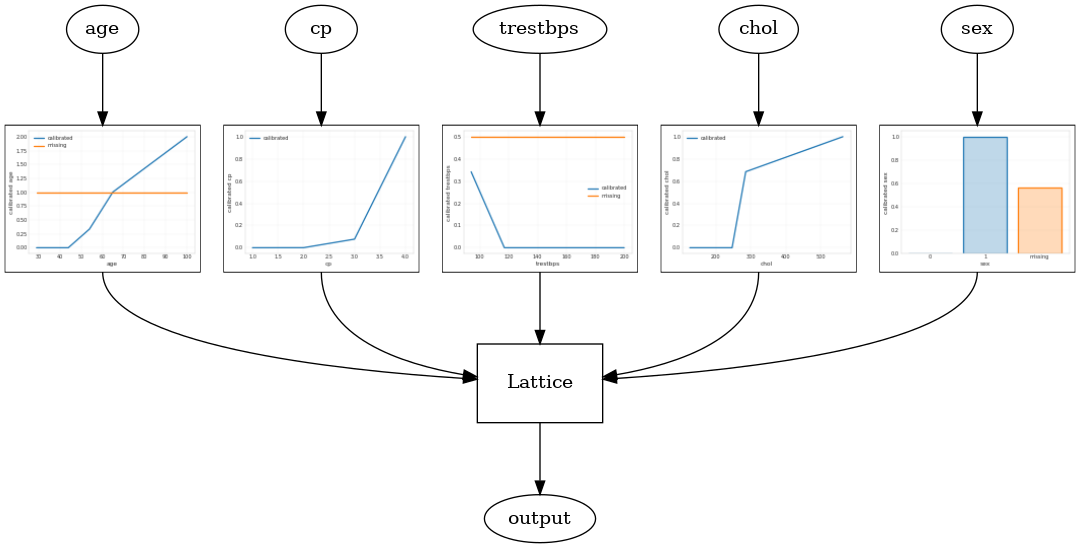
Conjunto de Malha Calibrado
Quando o número de recursos é grande, você pode usar um modelo de conjunto, que cria várias redes menores para subconjuntos de recursos e calcula a média de sua saída em vez de criar apenas uma única rede enorme. Modelos lattice Ensemble são construídos usando tfl.configs.CalibratedLatticeEnsembleConfig . Um modelo de conjunto de rede calibrado aplica calibração linear por partes e categórica no recurso de entrada, seguido por um conjunto de modelos de rede e uma calibração linear por partes de saída opcional.
Random Lattice Ensemble
A configuração do modelo a seguir usa um subconjunto aleatório de recursos para cada rede.
# This is random lattice ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
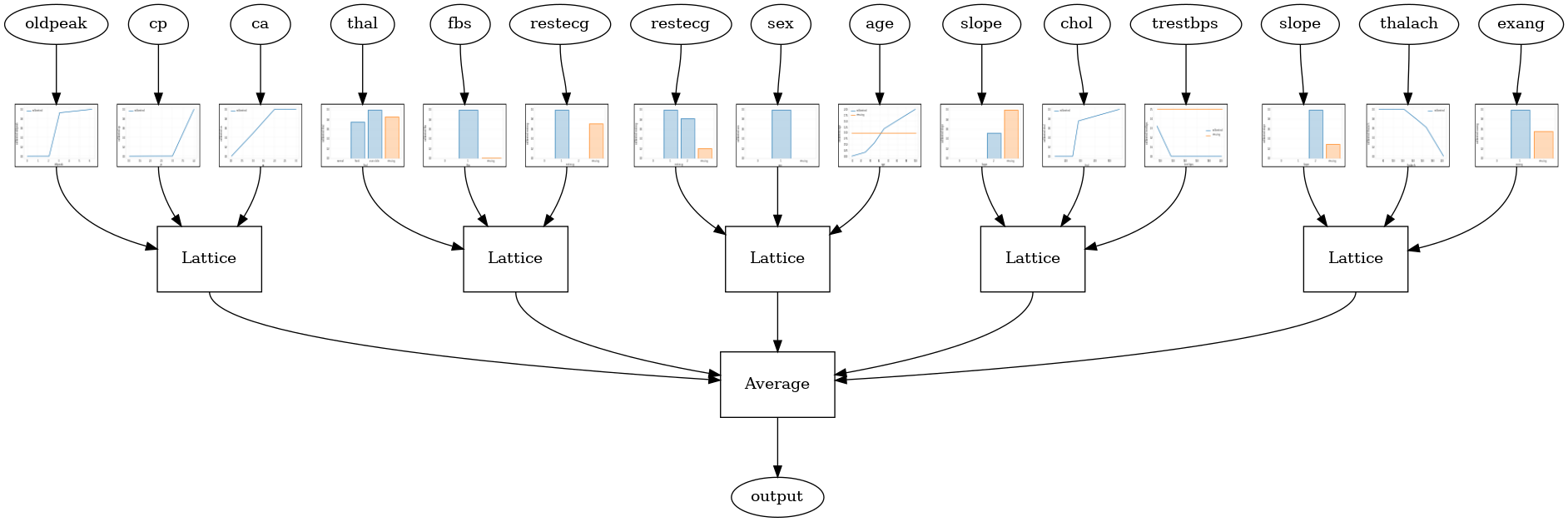
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.9003759026527405
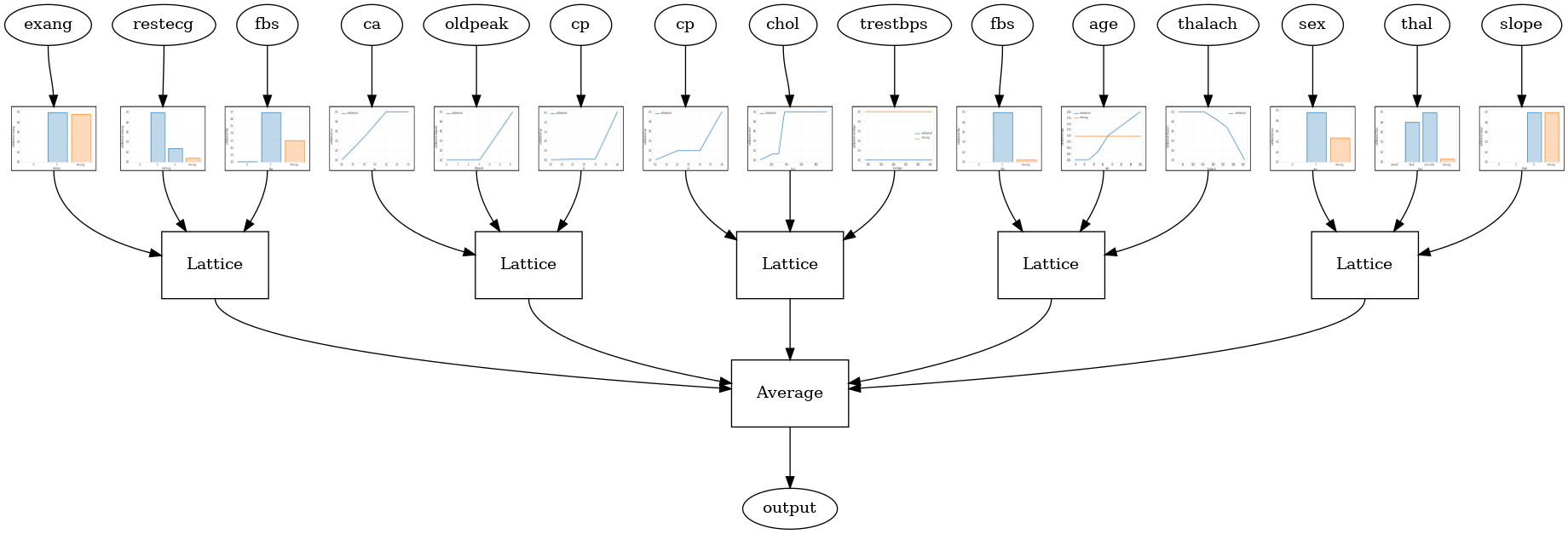
RTL Layer Random Lattice Ensemble
O seguinte modelo de configuração usa um tfl.layers.RTL camada que utiliza um subconjunto aleatório de características para cada estrutura. Notamos que tfl.layers.RTL suporta apenas restrições monotonicidade e deve ter o mesmo tamanho da estrutura para todos os recursos e sem regularização per-recurso. Note que usando um tfl.layers.RTL camada permite dimensionar a conjuntos muito maiores do que usando separados tfl.layers.Lattice casos.
# Make sure our feature configs have the same lattice size, no per-feature
# regularization, and only monotonicity constraints.
rtl_layer_feature_configs = copy.deepcopy(feature_configs)
for feature_config in rtl_layer_feature_configs:
feature_config.lattice_size = 2
feature_config.unimodality = 'none'
feature_config.reflects_trust_in = None
feature_config.dominates = None
feature_config.regularizer_configs = None
# This is RTL layer ensemble model with separate calibration:
# model output is the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
lattices='rtl_layer',
feature_configs=rtl_layer_feature_configs,
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Random ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Random ensemble test AUC: 0.8903509378433228
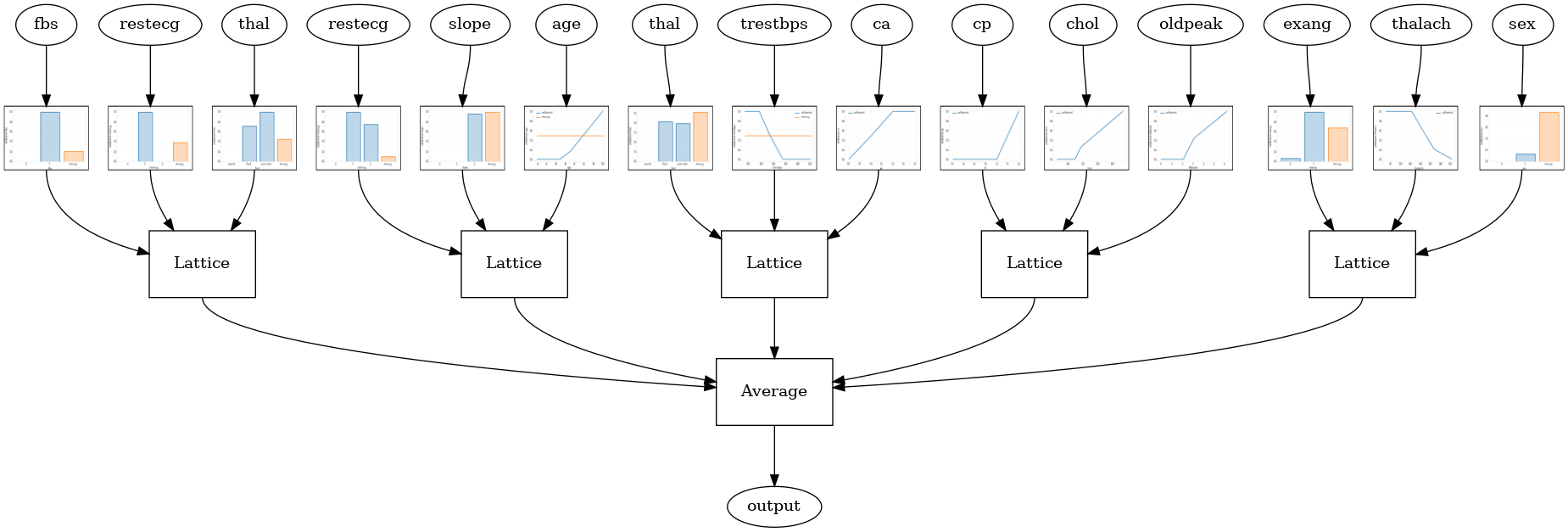
Conjunto de retículas de cristais
TFL também fornece um algoritmo de acordo função heurística, chamado de Cristais . Os cristais algoritmo primeiros trens um modelo prefitting que as estimativas aos pares interações metragens. Em seguida, ele organiza o conjunto final de forma que os recursos com mais interações não lineares estejam nas mesmas redes.
Para os modelos de cristais, você também precisará fornecer um prefitting_input_fn que é usado para treinar o modelo prefitting, como descrito acima. O modelo de prefitting não precisa ser totalmente treinado, portanto, algumas épocas devem ser suficientes.
prefitting_input_fn = tf.compat.v1.estimator.inputs.pandas_input_fn(
x=train_x,
y=train_y,
shuffle=False,
batch_size=BATCH_SIZE,
num_epochs=PREFITTING_NUM_EPOCHS,
num_threads=1)
Você pode, então, criar um modelo de cristal, definindo lattice='crystals' no modelo de configuração.
# This is Crystals ensemble model with separate calibration: model output is
# the average output of separately calibrated lattices.
model_config = tfl.configs.CalibratedLatticeEnsembleConfig(
feature_configs=feature_configs,
lattices='crystals',
num_lattices=5,
lattice_rank=3)
# A CannedClassifier is constructed from the given model config.
estimator = tfl.estimators.CannedClassifier(
feature_columns=feature_columns,
model_config=model_config,
feature_analysis_input_fn=feature_analysis_input_fn,
# prefitting_input_fn is required to train the prefitting model.
prefitting_input_fn=prefitting_input_fn,
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
prefitting_optimizer=tf.keras.optimizers.Adam(LEARNING_RATE),
config=tf.estimator.RunConfig(tf_random_seed=42))
estimator.train(input_fn=train_input_fn)
results = estimator.evaluate(input_fn=test_input_fn)
print('Crystals ensemble test AUC: {}'.format(results['auc']))
saved_model_path = estimator.export_saved_model(estimator.model_dir,
serving_input_fn)
model_graph = tfl.estimators.get_model_graph(saved_model_path)
tfl.visualization.draw_model_graph(model_graph, calibrator_dpi=15)
Crystals ensemble test AUC: 0.8840851783752441
Você pode plotar calibradores recurso com mais detalhes usando o tfl.visualization módulo.
_ = tfl.visualization.plot_feature_calibrator(model_graph, "age")
_ = tfl.visualization.plot_feature_calibrator(model_graph, "restecg")

