
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
TFL Premade Агрегатные функции Модели быстро и легко способы построения TFL tf.keras.model экземпляров для изучения сложных функций агрегации. В этом руководстве описаны шаги, необходимые для создания готовой модели агрегированных функций TFL и ее обучения / тестирования.
Настраивать
Установка пакета TF Lattice:
pip install -q tensorflow-lattice pydot
Импорт необходимых пакетов:
import tensorflow as tf
import collections
import logging
import numpy as np
import pandas as pd
import sys
import tensorflow_lattice as tfl
logging.disable(sys.maxsize)
Скачивание набора данных Puzzles:
train_dataframe = pd.read_csv(
'https://raw.githubusercontent.com/wbakst/puzzles_data/master/train.csv')
train_dataframe.head()
test_dataframe = pd.read_csv(
'https://raw.githubusercontent.com/wbakst/puzzles_data/master/test.csv')
test_dataframe.head()
Извлечение и преобразование функций и меток
# Features:
# - star_rating rating out of 5 stars (1-5)
# - word_count number of words in the review
# - is_amazon 1 = reviewed on amazon; 0 = reviewed on artifact website
# - includes_photo if the review includes a photo of the puzzle
# - num_helpful number of people that found this review helpful
# - num_reviews total number of reviews for this puzzle (we construct)
#
# This ordering of feature names will be the exact same order that we construct
# our model to expect.
feature_names = [
'star_rating', 'word_count', 'is_amazon', 'includes_photo', 'num_helpful',
'num_reviews'
]
def extract_features(dataframe, label_name):
# First we extract flattened features.
flattened_features = {
feature_name: dataframe[feature_name].values.astype(float)
for feature_name in feature_names[:-1]
}
# Construct mapping from puzzle name to feature.
star_rating = collections.defaultdict(list)
word_count = collections.defaultdict(list)
is_amazon = collections.defaultdict(list)
includes_photo = collections.defaultdict(list)
num_helpful = collections.defaultdict(list)
labels = {}
# Extract each review.
for i in range(len(dataframe)):
row = dataframe.iloc[i]
puzzle_name = row['puzzle_name']
star_rating[puzzle_name].append(float(row['star_rating']))
word_count[puzzle_name].append(float(row['word_count']))
is_amazon[puzzle_name].append(float(row['is_amazon']))
includes_photo[puzzle_name].append(float(row['includes_photo']))
num_helpful[puzzle_name].append(float(row['num_helpful']))
labels[puzzle_name] = float(row[label_name])
# Organize data into list of list of features.
names = list(star_rating.keys())
star_rating = [star_rating[name] for name in names]
word_count = [word_count[name] for name in names]
is_amazon = [is_amazon[name] for name in names]
includes_photo = [includes_photo[name] for name in names]
num_helpful = [num_helpful[name] for name in names]
num_reviews = [[len(ratings)] * len(ratings) for ratings in star_rating]
labels = [labels[name] for name in names]
# Flatten num_reviews
flattened_features['num_reviews'] = [len(reviews) for reviews in num_reviews]
# Convert data into ragged tensors.
star_rating = tf.ragged.constant(star_rating)
word_count = tf.ragged.constant(word_count)
is_amazon = tf.ragged.constant(is_amazon)
includes_photo = tf.ragged.constant(includes_photo)
num_helpful = tf.ragged.constant(num_helpful)
num_reviews = tf.ragged.constant(num_reviews)
labels = tf.constant(labels)
# Now we can return our extracted data.
return (star_rating, word_count, is_amazon, includes_photo, num_helpful,
num_reviews), labels, flattened_features
train_xs, train_ys, flattened_features = extract_features(train_dataframe, 'Sales12-18MonthsAgo')
test_xs, test_ys, _ = extract_features(test_dataframe, 'SalesLastSixMonths')
# Let's define our label minimum and maximum.
min_label, max_label = float(np.min(train_ys)), float(np.max(train_ys))
min_label, max_label = float(np.min(train_ys)), float(np.max(train_ys))
Установка значений по умолчанию, используемых для обучения в этом руководстве:
LEARNING_RATE = 0.1
BATCH_SIZE = 128
NUM_EPOCHS = 500
MIDDLE_DIM = 3
MIDDLE_LATTICE_SIZE = 2
MIDDLE_KEYPOINTS = 16
OUTPUT_KEYPOINTS = 8
Конфигурации функций
Калибровка Характеристики и в-функции конфигурация устанавливаются с помощью tfl.configs.FeatureConfig . Конфигурации включают Feature монотонности ограничения, в-функцию упорядочению (см tfl.configs.RegularizerConfig ) и решетку размеры для решетчатых моделей.
Обратите внимание, что мы должны полностью указать конфигурацию функции для любой функции, которую мы хотим, чтобы наша модель распознавала. В противном случае у модели не будет возможности узнать, что такая функция существует. Для моделей агрегации эти функции будут автоматически рассматриваться и должным образом обрабатываться как оборванные.
Вычислить квантили
Хотя по умолчанию для pwl_calibration_input_keypoints в tfl.configs.FeatureConfig является «квантилями», для моделей предварительно сделанных мы должны вручную определить входные ключевые точки. Для этого мы сначала определяем нашу собственную вспомогательную функцию для вычисления квантилей.
def compute_quantiles(features,
num_keypoints=10,
clip_min=None,
clip_max=None,
missing_value=None):
# Clip min and max if desired.
if clip_min is not None:
features = np.maximum(features, clip_min)
features = np.append(features, clip_min)
if clip_max is not None:
features = np.minimum(features, clip_max)
features = np.append(features, clip_max)
# Make features unique.
unique_features = np.unique(features)
# Remove missing values if specified.
if missing_value is not None:
unique_features = np.delete(unique_features,
np.where(unique_features == missing_value))
# Compute and return quantiles over unique non-missing feature values.
return np.quantile(
unique_features,
np.linspace(0., 1., num=num_keypoints),
interpolation='nearest').astype(float)
Определение конфигураций наших функций
Теперь, когда мы можем вычислить наши квантили, мы определяем конфигурацию функции для каждой функции, которую мы хотим, чтобы наша модель принимала в качестве входных данных.
# Feature configs are used to specify how each feature is calibrated and used.
feature_configs = [
tfl.configs.FeatureConfig(
name='star_rating',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['star_rating'], num_keypoints=5),
),
tfl.configs.FeatureConfig(
name='word_count',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['word_count'], num_keypoints=5),
),
tfl.configs.FeatureConfig(
name='is_amazon',
lattice_size=2,
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='includes_photo',
lattice_size=2,
num_buckets=2,
),
tfl.configs.FeatureConfig(
name='num_helpful',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['num_helpful'], num_keypoints=5),
# Larger num_helpful indicating more trust in star_rating.
reflects_trust_in=[
tfl.configs.TrustConfig(
feature_name="star_rating", trust_type="trapezoid"),
],
),
tfl.configs.FeatureConfig(
name='num_reviews',
lattice_size=2,
monotonicity='increasing',
pwl_calibration_num_keypoints=5,
pwl_calibration_input_keypoints=compute_quantiles(
flattened_features['num_reviews'], num_keypoints=5),
)
]
Модель агрегатной функции
Для построения модели Premade TFL, сначала построить конфигурацию модели из tfl.configs . Совокупная модель функции построена с использованием tfl.configs.AggregateFunctionConfig . Он применяет кусочно-линейную и категориальную калибровку, за которой следует решеточная модель для каждого измерения неровного входа. Затем он применяет слой агрегирования к выходным данным для каждого измерения. Затем следует дополнительная выходная кусочно-линейная калибровка.
# Model config defines the model structure for the aggregate function model.
aggregate_function_model_config = tfl.configs.AggregateFunctionConfig(
feature_configs=feature_configs,
middle_dimension=MIDDLE_DIM,
middle_lattice_size=MIDDLE_LATTICE_SIZE,
middle_calibration=True,
middle_calibration_num_keypoints=MIDDLE_KEYPOINTS,
middle_monotonicity='increasing',
output_min=min_label,
output_max=max_label,
output_calibration=True,
output_calibration_num_keypoints=OUTPUT_KEYPOINTS,
output_initialization=np.linspace(
min_label, max_label, num=OUTPUT_KEYPOINTS))
# An AggregateFunction premade model constructed from the given model config.
aggregate_function_model = tfl.premade.AggregateFunction(
aggregate_function_model_config)
# Let's plot our model.
tf.keras.utils.plot_model(
aggregate_function_model, show_layer_names=False, rankdir='LR')
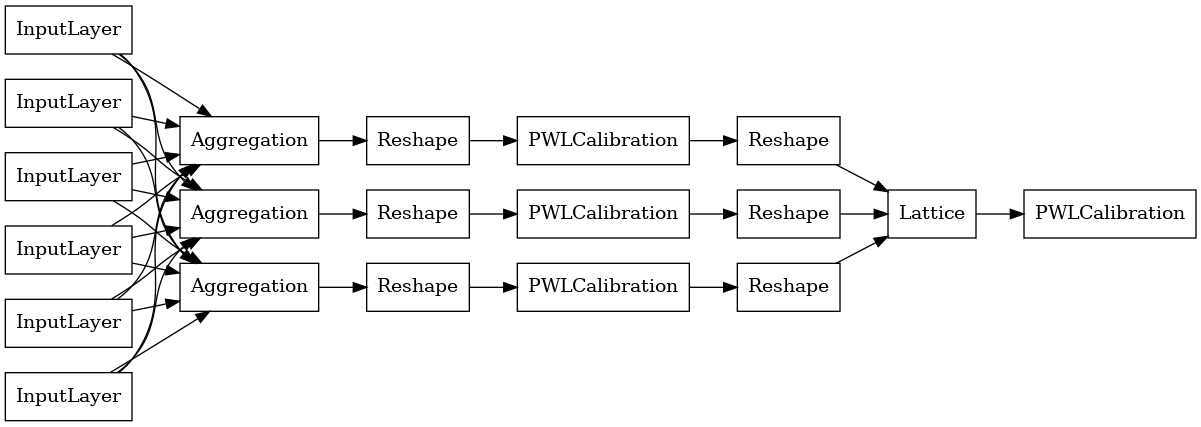
Выходные данные каждого уровня агрегации - это усредненные выходные данные калиброванной решетки по неровным входам. Вот модель, используемая внутри первого слоя агрегации:
aggregation_layers = [
layer for layer in aggregate_function_model.layers
if isinstance(layer, tfl.layers.Aggregation)
]
tf.keras.utils.plot_model(
aggregation_layers[0].model, show_layer_names=False, rankdir='LR')
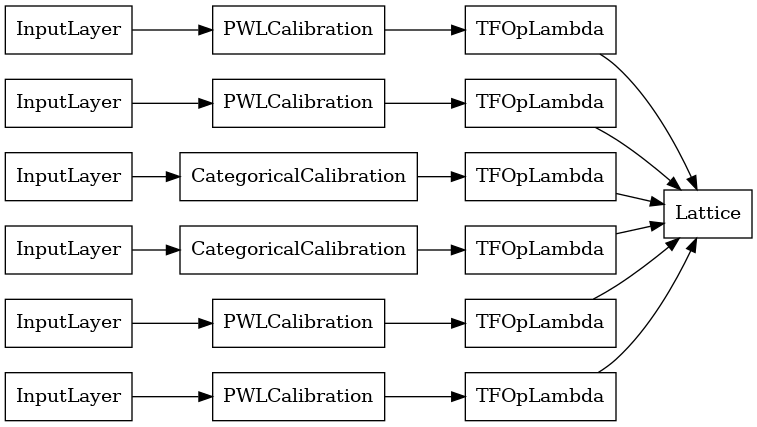
Теперь, как и с любой другой tf.keras.Model , мы собираем и подобрать модель для наших данных.
aggregate_function_model.compile(
loss='mae',
optimizer=tf.keras.optimizers.Adam(LEARNING_RATE))
aggregate_function_model.fit(
train_xs, train_ys, epochs=NUM_EPOCHS, batch_size=BATCH_SIZE, verbose=False)
<tensorflow.python.keras.callbacks.History at 0x7fee7d3033c8>
После обучения нашей модели мы можем оценить ее на нашем тестовом наборе.
print('Test Set Evaluation...')
print(aggregate_function_model.evaluate(test_xs, test_ys))
Test Set Evaluation... 7/7 [==============================] - 2s 3ms/step - loss: 53.4633 53.4632682800293