
TensorFlow Lattice è una libreria che implementa modelli basati su reticolo flessibili, controllati e interpretabili. La libreria consente di inserire la conoscenza del dominio nel processo di apprendimento attraverso vincoli di forma dettati dal buon senso o da politiche. Questo viene fatto utilizzando una raccolta di livelli Keras in grado di soddisfare vincoli quali monotonicità, convessità e fiducia a coppie. La libreria fornisce anche modelli predefiniti facili da configurare.
Concetti
Questa sezione è una versione semplificata della descrizione in Tabelle di ricerca interpolate calibrate monotone , JMLR 2016.
Reticoli
Un reticolo è una tabella di ricerca interpolata che può approssimare relazioni input-output arbitrarie nei dati. Si sovrappone a una griglia regolare sullo spazio di input e apprende i valori per l'output nei vertici della griglia. Per un punto di prova \(x\), \(f(x)\) è interpolato linearmente dai valori del reticolo circostante \(x\).
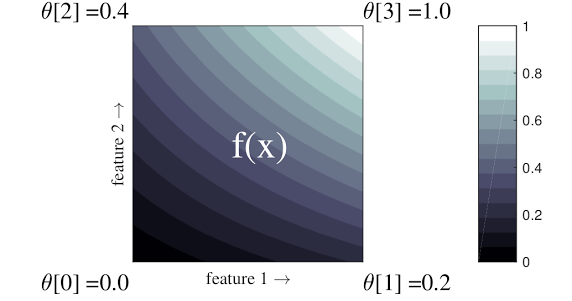
Il semplice esempio sopra è una funzione con 2 funzioni di input e 4 parametri:\(\theta=[0, 0.2, 0.4, 1]\), che sono i valori della funzione agli angoli dello spazio di input; il resto della funzione è interpolato da questi parametri.
La funzione \(f(x)\) può catturare interazioni non lineari tra caratteristiche. Si può pensare ai parametri del reticolo come all'altezza dei pali fissati nel terreno su una griglia regolare, e la funzione risultante è come un tessuto teso contro i quattro pali.
Con \(D\) caratteristiche e 2 vertici lungo ciascuna dimensione, avrà un reticolo regolare \(2^D\) parametri. Per adattare una funzione più flessibile, è possibile specificare un reticolo a grana più fine sullo spazio delle caratteristiche con più vertici lungo ciascuna dimensione. Le funzioni di regressione reticolare sono continue e differenziabili a tratti all'infinito.
Calibrazione
Supponiamo che il reticolo campione precedente rappresenti la felicità di un utente esperto con una caffetteria locale suggerita calcolata utilizzando le funzionalità:
- prezzo del caffè, compreso tra 0 e 20 dollari
- distanza dall'utente, compresa tra 0 e 30 chilometri
Vogliamo che il nostro modello impari la felicità degli utenti con il suggerimento di un bar locale. I modelli TensorFlow Lattice possono utilizzare funzioni lineari a tratti (con tfl.layers.PWLCalibration ) per calibrare e normalizzare le caratteristiche di input nell'intervallo accettato dal reticolo: da 0,0 a 1,0 nel reticolo di esempio sopra. Di seguito sono riportati esempi di funzioni di calibrazione con 10 punti chiave:
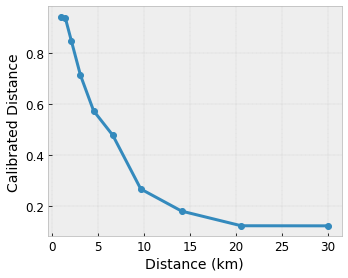
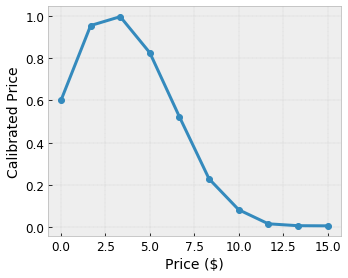
Spesso è una buona idea utilizzare i quantili delle caratteristiche come punti chiave di input. I modelli predefiniti di TensorFlow Lattice possono impostare automaticamente i punti chiave di input sui quantili della caratteristica.
Per le funzionalità categoriali, TensorFlow Lattice fornisce la calibrazione categoriale (con tfl.layers.CategoricalCalibration ) con limiti di output simili da inserire in un reticolo.
Ensemble
Il numero di parametri di uno strato reticolare aumenta esponenzialmente con il numero di caratteristiche di input, quindi non si adatta bene a dimensioni molto elevate. Per superare questa limitazione, TensorFlow Lattice offre insiemi di reticoli che combinano (in media) diversi piccoli reticoli, consentendo al modello di crescere linearmente nel numero di caratteristiche.
La libreria fornisce due varianti di questi ensemble:
Random Tiny Lattices (RTL): ogni sottomodello utilizza un sottoinsieme casuale di funzionalità (con sostituzione).
Cristalli : l'algoritmo Cristalli addestra innanzitutto un modello di preadattamento che stima le interazioni delle caratteristiche a coppie. Quindi organizza l'insieme finale in modo tale che le caratteristiche con più interazioni non lineari si trovino negli stessi reticoli.
Perché TensorFlow Lattice?
Puoi trovare una breve introduzione a TensorFlow Lattice in questo post del blog TF .
Interpretabilità
Poiché i parametri di ogni livello sono l'output di quel livello, è facile analizzare, comprendere ed eseguire il debug di ogni parte del modello.
Modelli accurati e flessibili
Utilizzando reticoli a grana fine, è possibile ottenere funzioni arbitrariamente complesse con un singolo strato reticolare. L'utilizzo di più livelli di calibratori e reticoli spesso funziona bene nella pratica e può eguagliare o superare le prestazioni dei modelli DNN di dimensioni simili.
Vincoli di forma dettati dal senso comune
I dati di addestramento del mondo reale potrebbero non rappresentare sufficientemente i dati di runtime. Soluzioni ML flessibili come DNN o foreste spesso agiscono in modo inaspettato e persino selvaggio in parti dello spazio di input non coperte dai dati di addestramento. Questo comportamento è particolarmente problematico quando i vincoli politici o di equità possono essere violati.
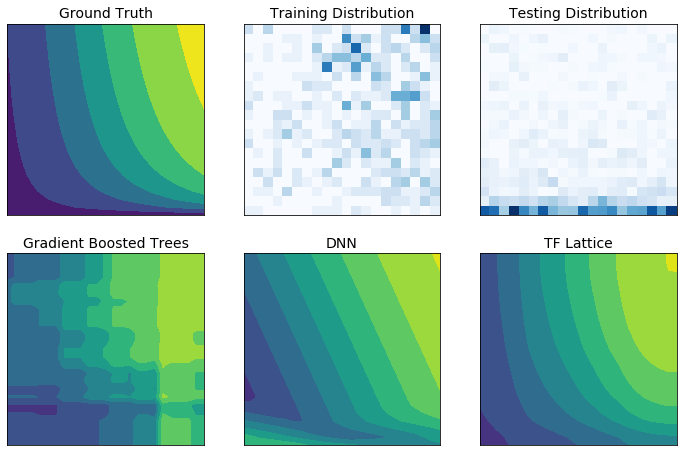
Anche se le forme comuni di regolarizzazione possono portare a un’estrapolazione più sensata, i regolatori standard non possono garantire un comportamento ragionevole del modello nell’intero spazio di input, specialmente con input ad alta dimensione. Il passaggio a modelli più semplici con comportamenti più controllati e prevedibili può comportare un grave costo per l’accuratezza del modello.
TF Lattice consente di continuare a utilizzare modelli flessibili, ma fornisce diverse opzioni per inserire la conoscenza del dominio nel processo di apprendimento attraverso vincoli di forma semanticamente significativi basati sul buon senso o basati su policy:
- Monotonia : è possibile specificare che l'output debba aumentare/diminuire solo rispetto a un input. Nel nostro esempio, potresti voler specificare che l'aumento della distanza da un bar dovrebbe solo diminuire la preferenza prevista dell'utente.
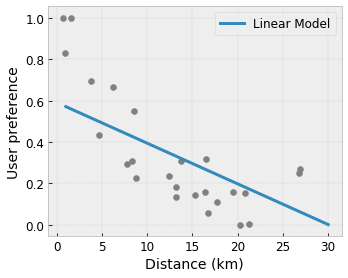
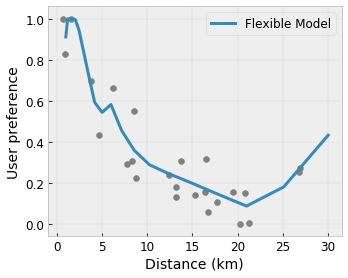
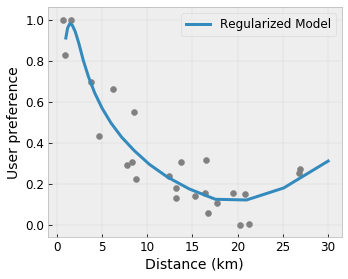
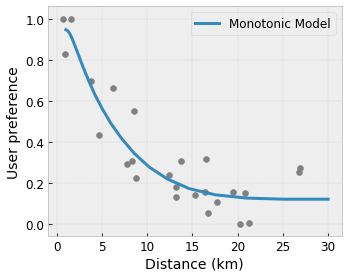
Convessità/Concavità : è possibile specificare che la forma della funzione può essere convessa o concava. Combinato con la monotonicità, ciò può costringere la funzione a rappresentare rendimenti decrescenti rispetto a una determinata caratteristica.
Unimodalità : è possibile specificare che la funzione debba avere un picco o una valle univoci. Ciò consente di rappresentare funzioni che hanno un punto debole rispetto a una funzionalità.
Fiducia a coppie : questo vincolo funziona su una coppia di funzionalità e suggerisce che una funzionalità di input riflette semanticamente la fiducia in un'altra funzionalità. Ad esempio, un numero maggiore di recensioni ti rende più sicuro della valutazione media in stelle di un ristorante. Il modello sarà più sensibile rispetto alla valutazione in stelle (ovvero avrà una pendenza maggiore rispetto alla valutazione) quando il numero di recensioni sarà maggiore.
Flessibilità controllata con regolaizzatori
Oltre ai vincoli di forma, il reticolo TensorFlow fornisce una serie di regolatori per controllare la flessibilità e la fluidità della funzione per ogni livello.
Regolarizzatore laplaciano : gli output dei vertici/punti chiave del reticolo/calibrazione vengono regolarizzati rispetto ai valori dei rispettivi vicini. Ciò si traduce in una funzione più piatta .
Regolarizzatore dell'Assia : penalizza la derivata prima dello strato di calibrazione PWL per rendere la funzione più lineare .
Wrinkle Regularizer : penalizza la derivata seconda dello strato di calibrazione PWL per evitare cambiamenti improvvisi nella curvatura. Rende la funzione più fluida.
Regolarizzatore di torsione : le uscite del reticolo verranno regolarizzate per prevenire la torsione tra le caratteristiche. In altre parole, il modello verrà regolarizzato verso l'indipendenza tra i contributi delle caratteristiche.
Mescola e abbina con altri strati Keras
È possibile utilizzare i layer TF Lattice in combinazione con altri layer Keras per costruire modelli parzialmente vincolati o regolarizzati. Ad esempio, i livelli di calibrazione reticolo o PWL possono essere utilizzati nell'ultimo livello di reti più profonde che includono incorporamenti o altri livelli Keras.
Carte
- Etica deontologica per vincoli di forma monotonica , Serena Wang, Maya Gupta, Conferenza internazionale sull'intelligenza artificiale e la statistica (AISTATS), 2020
- Vincoli di forma per funzioni di insieme , Andrew Cotter, Maya Gupta, H. Jiang, Erez Louidor, Jim Muller, Taman Narayan, Serena Wang, Tao Zhu. Conferenza internazionale sull'apprendimento automatico (ICML), 2019
- Rendimenti decrescenti: vincoli di forma per l'interpretabilità e la regolarizzazione , Maya Gupta, Dara Bahri, Andrew Cotter, Kevin Canini, Advances in Neural Information Processing Systems (NeurIPS), 2018
- Reti reticolari profonde e funzioni monotone parziali , Seungil You, Kevin Canini, David Ding, Jan Pfeifer, Maya R. Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2017
- Funzioni monotone veloci e flessibili con insiemi di reticoli , Mahdi Milani Fard, Kevin Canini, Andrew Cotter, Jan Pfeifer, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2016
- Tabelle di ricerca interpolate calibrate monotoniche , Maya Gupta, Andrew Cotter, Jan Pfeifer, Konstantin Voevodski, Kevin Canini, Alexander Mangylov, Wojciech Moczydlowski, Alexander van Esbroeck, Journal of Machine Learning Research (JMLR), 2016
- Regressione ottimizzata per una valutazione efficiente delle funzioni , Eric Garcia, Raman Arora, Maya R. Gupta, IEEE Transactions on Image Processing, 2012
- Regressione reticolare , Eric Garcia, Maya Gupta, Progressi nei sistemi di elaborazione delle informazioni neurali (NeurIPS), 2009
Tutorial e documentazione API
Per le architetture di modelli comuni, è possibile utilizzare i modelli predefiniti di Keras . Puoi anche creare modelli personalizzati utilizzando i livelli TF Lattice Keras o combinarli e abbinarli con altri livelli Keras. Consulta la documentazione API completa per i dettagli.
,TensorFlow Lattice è una libreria che implementa modelli basati su reticolo flessibili, controllati e interpretabili. La libreria consente di inserire la conoscenza del dominio nel processo di apprendimento attraverso vincoli di forma dettati dal buon senso o da politiche. Questo viene fatto utilizzando una raccolta di livelli Keras in grado di soddisfare vincoli quali monotonicità, convessità e fiducia a coppie. La libreria fornisce anche modelli predefiniti facili da configurare.
Concetti
Questa sezione è una versione semplificata della descrizione in Tabelle di ricerca interpolate calibrate monotone , JMLR 2016.
Reticoli
Un reticolo è una tabella di ricerca interpolata che può approssimare relazioni input-output arbitrarie nei dati. Si sovrappone a una griglia regolare sullo spazio di input e apprende i valori per l'output nei vertici della griglia. Per un punto di prova \(x\), \(f(x)\) è interpolato linearmente dai valori del reticolo circostante \(x\).
Il semplice esempio sopra è una funzione con 2 funzioni di input e 4 parametri:\(\theta=[0, 0.2, 0.4, 1]\), che sono i valori della funzione agli angoli dello spazio di input; il resto della funzione è interpolato da questi parametri.
La funzione \(f(x)\) può catturare interazioni non lineari tra caratteristiche. Si può pensare ai parametri del reticolo come all'altezza dei pali fissati nel terreno su una griglia regolare, e la funzione risultante è come un tessuto teso contro i quattro poli.
Con \(D\) caratteristiche e 2 vertici lungo ciascuna dimensione, avrà un reticolo regolare \(2^D\) parametri. Per adattare una funzione più flessibile, è possibile specificare un reticolo a grana più fine sullo spazio delle caratteristiche con più vertici lungo ciascuna dimensione. Le funzioni di regressione reticolare sono continue e differenziabili a tratti all'infinito.
Calibrazione
Supponiamo che il reticolo campione precedente rappresenti la felicità di un utente esperto con una caffetteria locale suggerita calcolata utilizzando le funzionalità:
- prezzo del caffè, compreso tra 0 e 20 dollari
- distanza dall'utente, compresa tra 0 e 30 chilometri
Vogliamo che il nostro modello impari la felicità degli utenti con il suggerimento di un bar locale. I modelli TensorFlow Lattice possono utilizzare funzioni lineari a tratti (con tfl.layers.PWLCalibration ) per calibrare e normalizzare le caratteristiche di input nell'intervallo accettato dal reticolo: da 0,0 a 1,0 nel reticolo di esempio sopra. Di seguito sono riportati esempi di funzioni di calibrazione con 10 punti chiave:
Spesso è una buona idea utilizzare i quantili delle caratteristiche come punti chiave di input. I modelli predefiniti di TensorFlow Lattice possono impostare automaticamente i punti chiave di input sui quantili della caratteristica.
Per le funzionalità categoriali, TensorFlow Lattice fornisce la calibrazione categoriale (con tfl.layers.CategoricalCalibration ) con limiti di output simili da inserire in un reticolo.
Ensemble
Il numero di parametri di uno strato reticolare aumenta esponenzialmente con il numero di caratteristiche di input, quindi non si adatta bene a dimensioni molto elevate. Per superare questa limitazione, TensorFlow Lattice offre insiemi di reticoli che combinano (in media) diversi piccoli reticoli, consentendo al modello di crescere linearmente nel numero di caratteristiche.
La libreria fornisce due varianti di questi ensemble:
Random Tiny Lattices (RTL): ogni sottomodello utilizza un sottoinsieme casuale di funzionalità (con sostituzione).
Cristalli : l'algoritmo Cristalli addestra innanzitutto un modello di preadattamento che stima le interazioni delle caratteristiche a coppie. Quindi organizza l'insieme finale in modo tale che le caratteristiche con più interazioni non lineari si trovino negli stessi reticoli.
Perché TensorFlow Lattice?
Puoi trovare una breve introduzione a TensorFlow Lattice in questo post del blog TF .
Interpretabilità
Poiché i parametri di ogni livello sono l'output di quel livello, è facile analizzare, comprendere ed eseguire il debug di ogni parte del modello.
Modelli accurati e flessibili
Utilizzando reticoli a grana fine, è possibile ottenere funzioni arbitrariamente complesse con un singolo strato reticolare. L'utilizzo di più livelli di calibratori e reticoli spesso funziona bene nella pratica e può eguagliare o superare le prestazioni dei modelli DNN di dimensioni simili.
Vincoli di forma dettati dal senso comune
I dati di addestramento del mondo reale potrebbero non rappresentare sufficientemente i dati di runtime. Soluzioni ML flessibili come DNN o foreste spesso agiscono in modo inaspettato e persino selvaggio in parti dello spazio di input non coperte dai dati di addestramento. Questo comportamento è particolarmente problematico quando i vincoli politici o di equità possono essere violati.
Anche se le forme comuni di regolarizzazione possono portare a un’estrapolazione più sensata, i regolarizzatori standard non possono garantire un comportamento ragionevole del modello nell’intero spazio di input, specialmente con input ad alta dimensione. Il passaggio a modelli più semplici con comportamenti più controllati e prevedibili può comportare un grave costo per l’accuratezza del modello.
TF Lattice consente di continuare a utilizzare modelli flessibili, ma fornisce diverse opzioni per inserire la conoscenza del dominio nel processo di apprendimento attraverso vincoli di forma semanticamente significativi basati sul buon senso o basati su policy:
- Monotonia : è possibile specificare che l'output debba aumentare/diminuire solo rispetto a un input. Nel nostro esempio, potresti voler specificare che l'aumento della distanza da un bar dovrebbe solo diminuire la preferenza prevista dell'utente.
Convessità/Concavità : è possibile specificare che la forma della funzione può essere convessa o concava. Combinato con la monotonicità, ciò può costringere la funzione a rappresentare rendimenti decrescenti rispetto a una determinata caratteristica.
Unimodalità : è possibile specificare che la funzione debba avere un picco o una valle univoci. Ciò consente di rappresentare funzioni che hanno un punto debole rispetto a una funzionalità.
Fiducia a coppie : questo vincolo funziona su una coppia di funzionalità e suggerisce che una funzionalità di input riflette semanticamente la fiducia in un'altra funzionalità. Ad esempio, un numero maggiore di recensioni ti rende più sicuro della valutazione media in stelle di un ristorante. Il modello sarà più sensibile rispetto alla valutazione in stelle (ovvero avrà una pendenza maggiore rispetto alla valutazione) quando il numero di recensioni sarà maggiore.
Flessibilità controllata con regolaizzatori
Oltre ai vincoli di forma, il reticolo TensorFlow fornisce una serie di regolatori per controllare la flessibilità e la fluidità della funzione per ciascun livello.
Regolarizzatore laplaciano : gli output dei vertici/punti chiave del reticolo/calibrazione vengono regolarizzati rispetto ai valori dei rispettivi vicini. Ciò si traduce in una funzione più piatta .
Regolarizzatore dell'Assia : penalizza la derivata prima dello strato di calibrazione PWL per rendere la funzione più lineare .
Wrinkle Regularizer : penalizza la derivata seconda dello strato di calibrazione PWL per evitare cambiamenti improvvisi nella curvatura. Rende la funzione più fluida.
Regolarizzatore di torsione : le uscite del reticolo verranno regolarizzate per prevenire la torsione tra le caratteristiche. In altre parole, il modello verrà regolarizzato verso l'indipendenza tra i contributi delle caratteristiche.
Mescola e abbina con altri strati Keras
È possibile utilizzare i layer TF Lattice in combinazione con altri layer Keras per costruire modelli parzialmente vincolati o regolarizzati. Ad esempio, i livelli di calibrazione reticolo o PWL possono essere utilizzati nell'ultimo livello di reti più profonde che includono incorporamenti o altri livelli Keras.
Carte
- Etica deontologica per vincoli di forma monotonica , Serena Wang, Maya Gupta, Conferenza internazionale sull'intelligenza artificiale e la statistica (AISTATS), 2020
- Vincoli di forma per funzioni di insieme , Andrew Cotter, Maya Gupta, H. Jiang, Erez Louidor, Jim Muller, Taman Narayan, Serena Wang, Tao Zhu. Conferenza internazionale sull'apprendimento automatico (ICML), 2019
- Rendimenti decrescenti: vincoli di forma per l'interpretabilità e la regolarizzazione , Maya Gupta, Dara Bahri, Andrew Cotter, Kevin Canini, Advances in Neural Information Processing Systems (NeurIPS), 2018
- Reti reticolari profonde e funzioni monotone parziali , Seungil You, Kevin Canini, David Ding, Jan Pfeifer, Maya R. Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2017
- Funzioni monotone veloci e flessibili con insiemi di reticoli , Mahdi Milani Fard, Kevin Canini, Andrew Cotter, Jan Pfeifer, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2016
- Tabelle di ricerca interpolate calibrate monotoniche , Maya Gupta, Andrew Cotter, Jan Pfeifer, Konstantin Voevodski, Kevin Canini, Alexander Mangylov, Wojciech Moczydlowski, Alexander van Esbroeck, Journal of Machine Learning Research (JMLR), 2016
- Regressione ottimizzata per una valutazione efficiente delle funzioni , Eric Garcia, Raman Arora, Maya R. Gupta, IEEE Transactions on Image Processing, 2012
- Regressione reticolare , Eric Garcia, Maya Gupta, Progressi nei sistemi di elaborazione delle informazioni neurali (NeurIPS), 2009
Tutorial e documentazione API
Per le architetture di modelli comuni, è possibile utilizzare i modelli predefiniti di Keras . Puoi anche creare modelli personalizzati utilizzando i livelli TF Lattice Keras o combinarli e abbinarli con altri livelli Keras. Consulta la documentazione API completa per i dettagli.