
TensorFlow Lattice é uma biblioteca que implementa modelos baseados em rede flexíveis, controlados e interpretáveis. A biblioteca permite que você injete conhecimento de domínio no processo de aprendizagem por meio de restrições de forma orientadas por políticas ou de bom senso. Isso é feito usando uma coleção de camadas Keras que podem satisfazer restrições como monotonicidade, convexidade e confiança entre pares. A biblioteca também fornece modelos pré-fabricados fáceis de configurar.
Conceitos
Esta seção é uma versão simplificada da descrição em Monotonic Calibrated Interpolated Look-Up Tables , JMLR 2016.
Treliças
Uma rede é uma tabela de consulta interpolada que pode aproximar relações arbitrárias de entrada-saída em seus dados. Ele sobrepõe uma grade regular ao seu espaço de entrada e aprende valores para a saída nos vértices da grade. Para um ponto de teste \(x\), \(f(x)\) é interpolado linearmente a partir dos valores da rede em torno \(x\).
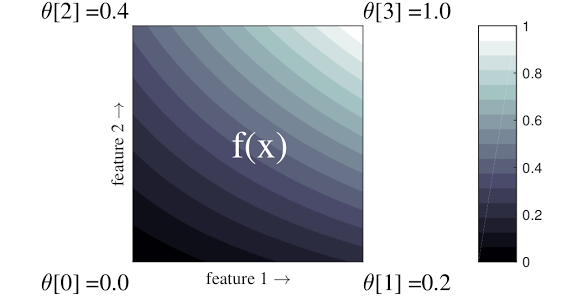
O exemplo simples acima é uma função com 2 recursos de entrada e 4 parâmetros:\(\theta=[0, 0.2, 0.4, 1]\), que são os valores da função nos cantos do espaço de entrada; o resto da função é interpolado a partir desses parâmetros.
A função \(f(x)\) pode capturar interações não lineares entre recursos. Você pode pensar nos parâmetros da rede como a altura dos postes colocados no solo em uma grade regular, e a função resultante é como um pano esticado contra os quatro postes.
Com \(D\) recursos e 2 vértices ao longo de cada dimensão, uma rede regular terá \(2^D\) parâmetros. Para ajustar uma função mais flexível, você pode especificar uma rede mais refinada sobre o espaço de recursos com mais vértices ao longo de cada dimensão. As funções de regressão de rede são contínuas e infinitamente diferenciáveis por partes.
Calibração
Digamos que a estrutura de amostra anterior represente a felicidade aprendida do usuário com uma cafeteria local sugerida, calculada usando recursos:
- preço do café, na faixa de 0 a 20 dólares
- distância até o usuário, na faixa de 0 a 30 quilômetros
Queremos que nosso modelo aprenda a felicidade do usuário com uma sugestão de cafeteria local. Os modelos do TensorFlow Lattice podem usar funções lineares por partes (com tfl.layers.PWLCalibration ) para calibrar e normalizar os recursos de entrada para o intervalo aceito pela rede: 0,0 a 1,0 no exemplo de rede acima. A seguir são mostrados exemplos de tais funções de calibrações com 10 pontos-chave:
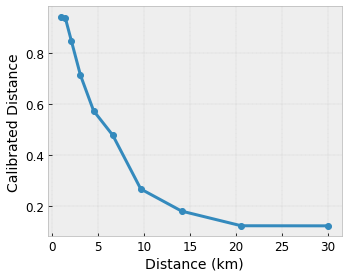

Muitas vezes é uma boa ideia usar os quantis dos recursos como pontos-chave de entrada. Os modelos pré-fabricados do TensorFlow Lattice podem definir automaticamente os pontos-chave de entrada para os quantis de recursos.
Para recursos categóricos, o TensorFlow Lattice fornece calibração categórica (com tfl.layers.CategoricalCalibration ) com saída semelhante vinculada para alimentar uma rede.
Conjuntos
O número de parâmetros de uma camada de rede aumenta exponencialmente com o número de recursos de entrada, portanto, não se adapta bem a dimensões muito altas. Para superar essa limitação, o TensorFlow Lattice oferece conjuntos de redes que combinam (em média) várias redes minúsculas , o que permite que o modelo cresça linearmente no número de recursos.
A biblioteca oferece duas variações desses conjuntos:
Random Tiny Lattices (RTL): Cada submodelo usa um subconjunto aleatório de recursos (com substituição).
Cristais : O algoritmo Crystals primeiro treina um modelo de pré-ajuste que estima interações de recursos entre pares. Em seguida, ele organiza o conjunto final de forma que recursos com mais interações não lineares estejam nas mesmas redes.
Por que TensorFlow Malha?
Você pode encontrar uma breve introdução ao TensorFlow Lattice nesta postagem do TF Blog .
Interpretabilidade
Como os parâmetros de cada camada são a saída dessa camada, é fácil analisar, compreender e depurar cada parte do modelo.
Modelos Precisos e Flexíveis
Usando redes de granulação fina, você pode obter funções arbitrariamente complexas com uma única camada de rede. O uso de múltiplas camadas de calibradores e redes geralmente funciona bem na prática e pode corresponder ou superar modelos DNN de tamanhos semelhantes.
Restrições de forma de senso comum
Os dados de treinamento do mundo real podem não representar suficientemente os dados de tempo de execução. Soluções flexíveis de ML, como DNNs ou florestas, muitas vezes agem de forma inesperada e até mesmo descontrolada em partes do espaço de entrada não cobertas pelos dados de treinamento. Este comportamento é especialmente problemático quando as restrições políticas ou de justiça podem ser violadas.
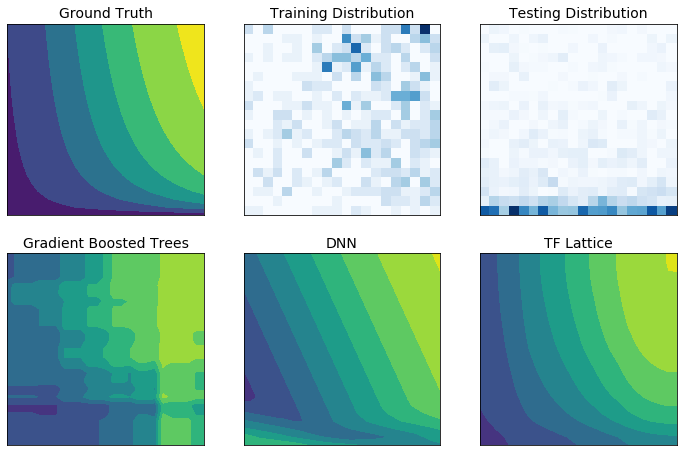
Embora formas comuns de regularização possam resultar em extrapolações mais sensatas, os regularizadores padrão não podem garantir um comportamento razoável do modelo em todo o espaço de entrada, especialmente com entradas de alta dimensão. Mudar para modelos mais simples com comportamento mais controlado e previsível pode ter um custo severo para a precisão do modelo.
O TF Lattice torna possível continuar usando modelos flexíveis, mas oferece várias opções para injetar conhecimento de domínio no processo de aprendizagem por meio de senso comum semanticamente significativo ou restrições de forma orientadas por políticas:
- Monotonicidade : você pode especificar que a saída só deve aumentar/diminuir em relação a uma entrada. Em nosso exemplo, você pode querer especificar que o aumento da distância até uma cafeteria deve apenas diminuir a preferência prevista do usuário.
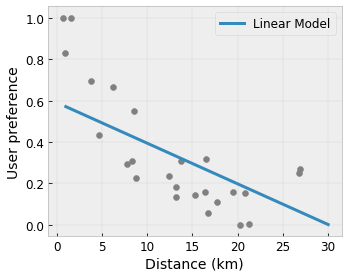
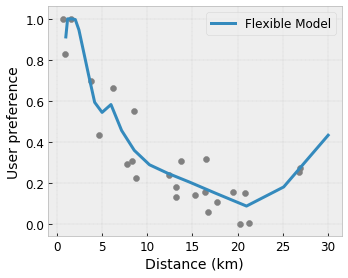
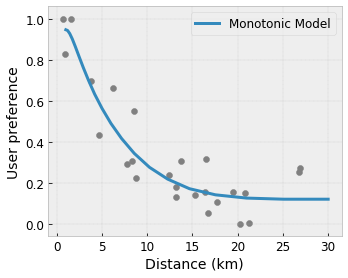
Convexidade/Concavidade : Você pode especificar que a forma da função pode ser convexa ou côncava. Misturado à monotonicidade, isso pode forçar a função a representar retornos decrescentes em relação a um determinado recurso.
Unimodalidade : você pode especificar que a função deve ter um pico ou vale único. Isso permite representar funções que possuem um ponto ideal em relação a um recurso.
Confiança em pares : esta restrição funciona em um par de recursos e sugere que um recurso de entrada reflete semanticamente a confiança em outro recurso. Por exemplo, um número maior de avaliações deixa você mais confiante na classificação média por estrelas de um restaurante. O modelo será mais sensível em relação à classificação por estrelas (ou seja, terá uma inclinação maior em relação à classificação) quando o número de avaliações for maior.
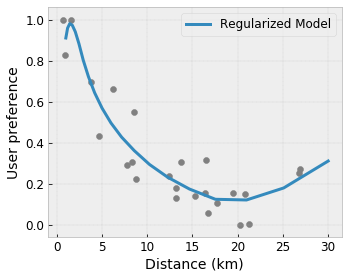
Flexibilidade controlada com regularizadores
Além das restrições de forma, a estrutura do TensorFlow fornece vários regularizadores para controlar a flexibilidade e suavidade da função para cada camada.
Regularizador Laplaciano : As saídas dos vértices/pontos-chave da rede/calibração são regularizadas em relação aos valores de seus respectivos vizinhos. Isso resulta em uma função mais plana .
Regularizador Hessiano : Penaliza a primeira derivada da camada de calibração PWL para tornar a função mais linear .
Regularizador de rugas : Penaliza a segunda derivada da camada de calibração PWL para evitar mudanças repentinas na curvatura. Isso torna a função mais suave.
Regularizador de Torção : As saídas da rede serão regularizadas para evitar torção entre os recursos. Em outras palavras, o modelo será regularizado no sentido da independência entre as contribuições dos recursos.
Misture e combine com outras camadas Keras
Você pode usar camadas TF Lattice em combinação com outras camadas Keras para construir modelos parcialmente restritos ou regularizados. Por exemplo, camadas de calibração de rede ou PWL podem ser usadas na última camada de redes mais profundas que incluem incorporações ou outras camadas Keras.
Artigos
- Ética Deontológica por Restrições de Forma de Monotonicidade , Serena Wang, Maya Gupta, Conferência Internacional sobre Inteligência Artificial e Estatística (AISTATS), 2020
- Restrições de forma para funções de conjunto , Andrew Cotter, Maya Gupta, H. Jiang, Erez Louidor, Jim Muller, Taman Narayan, Serena Wang, Tao Zhu. Conferência Internacional sobre Aprendizado de Máquina (ICML), 2019
- Restrições de forma de retornos decrescentes para interpretabilidade e regularização , Maya Gupta, Dara Bahri, Andrew Cotter, Kevin Canini, Advances in Neural Information Processing Systems (NeurIPS), 2018
- Redes de rede profunda e funções monotônicas parciais , Seungil You, Kevin Canini, David Ding, Jan Pfeifer, Maya R. Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2017
- Funções monotônicas rápidas e flexíveis com conjuntos de redes , Mahdi Milani Fard, Kevin Canini, Andrew Cotter, Jan Pfeifer, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2016
- Tabelas de consulta interpoladas calibradas monotônicas , Maya Gupta, Andrew Cotter, Jan Pfeifer, Konstantin Voevodski, Kevin Canini, Alexander Mangylov, Wojciech Moczydlowski, Alexander van Esbroeck, Journal of Machine Learning Research (JMLR), 2016
- Regressão otimizada para avaliação eficiente de funções , Eric Garcia, Raman Arora, Maya R. Gupta, IEEE Transactions on Image Processing, 2012
- Regressão em rede , Eric Garcia, Maya Gupta, Avanços em sistemas de processamento de informações neurais (NeurIPS), 2009
Tutoriais e documentos de API
Para arquiteturas de modelos comuns, você pode usar modelos pré-fabricados Keras . Você também pode criar modelos personalizados usando camadas TF Lattice Keras ou misturar e combinar com outras camadas Keras. Confira a documentação completa da API para obter detalhes.
,TensorFlow Lattice é uma biblioteca que implementa modelos baseados em rede flexíveis, controlados e interpretáveis. A biblioteca permite que você injete conhecimento de domínio no processo de aprendizagem por meio de restrições de forma orientadas por políticas ou de bom senso. Isso é feito usando uma coleção de camadas Keras que podem satisfazer restrições como monotonicidade, convexidade e confiança entre pares. A biblioteca também fornece modelos pré-fabricados fáceis de configurar.
Conceitos
Esta seção é uma versão simplificada da descrição em Monotonic Calibrated Interpolated Look-Up Tables , JMLR 2016.
Treliças
Uma rede é uma tabela de consulta interpolada que pode aproximar relações arbitrárias de entrada-saída em seus dados. Ele sobrepõe uma grade regular ao seu espaço de entrada e aprende valores para a saída nos vértices da grade. Para um ponto de teste \(x\), \(f(x)\) é interpolado linearmente a partir dos valores da rede em torno \(x\).
O exemplo simples acima é uma função com 2 recursos de entrada e 4 parâmetros:\(\theta=[0, 0.2, 0.4, 1]\), que são os valores da função nos cantos do espaço de entrada; o resto da função é interpolado a partir desses parâmetros.
A função \(f(x)\) pode capturar interações não lineares entre recursos. Você pode pensar nos parâmetros da rede como a altura dos postes colocados no solo em uma grade regular, e a função resultante é como um pano esticado contra os quatro postes.
Com \(D\) recursos e 2 vértices ao longo de cada dimensão, uma rede regular terá \(2^D\) parâmetros. Para ajustar uma função mais flexível, você pode especificar uma rede mais refinada sobre o espaço de recursos com mais vértices ao longo de cada dimensão. As funções de regressão de rede são contínuas e infinitamente diferenciáveis por partes.
Calibração
Digamos que a estrutura de amostra anterior represente a felicidade aprendida do usuário com uma cafeteria local sugerida, calculada usando recursos:
- preço do café, na faixa de 0 a 20 dólares
- distância até o usuário, na faixa de 0 a 30 quilômetros
Queremos que nosso modelo aprenda a felicidade do usuário com uma sugestão de cafeteria local. Os modelos do TensorFlow Lattice podem usar funções lineares por partes (com tfl.layers.PWLCalibration ) para calibrar e normalizar os recursos de entrada para o intervalo aceito pela rede: 0,0 a 1,0 no exemplo de rede acima. A seguir são mostrados exemplos de tais funções de calibrações com 10 pontos-chave:
Muitas vezes é uma boa ideia usar os quantis dos recursos como pontos-chave de entrada. Os modelos pré-fabricados do TensorFlow Lattice podem definir automaticamente os pontos-chave de entrada para os quantis de recursos.
Para recursos categóricos, o TensorFlow Lattice fornece calibração categórica (com tfl.layers.CategoricalCalibration ) com saída semelhante vinculada para alimentar uma rede.
Conjuntos
O número de parâmetros de uma camada de rede aumenta exponencialmente com o número de recursos de entrada, portanto, não se adapta bem a dimensões muito altas. Para superar essa limitação, o TensorFlow Lattice oferece conjuntos de redes que combinam (em média) várias redes minúsculas , o que permite que o modelo cresça linearmente no número de recursos.
A biblioteca oferece duas variações desses conjuntos:
Random Tiny Lattices (RTL): Cada submodelo usa um subconjunto aleatório de recursos (com substituição).
Cristais : O algoritmo Crystals primeiro treina um modelo de pré-ajuste que estima interações de recursos entre pares. Em seguida, ele organiza o conjunto final de forma que recursos com mais interações não lineares estejam nas mesmas redes.
Por que TensorFlow Malha?
Você pode encontrar uma breve introdução ao TensorFlow Lattice nesta postagem do TF Blog .
Interpretabilidade
Como os parâmetros de cada camada são a saída dessa camada, é fácil analisar, compreender e depurar cada parte do modelo.
Modelos Precisos e Flexíveis
Usando redes de granulação fina, você pode obter funções arbitrariamente complexas com uma única camada de rede. O uso de múltiplas camadas de calibradores e redes geralmente funciona bem na prática e pode corresponder ou superar modelos DNN de tamanhos semelhantes.
Restrições de forma de senso comum
Os dados de treinamento do mundo real podem não representar suficientemente os dados de tempo de execução. Soluções flexíveis de ML, como DNNs ou florestas, muitas vezes agem de forma inesperada e até mesmo descontrolada em partes do espaço de entrada não cobertas pelos dados de treinamento. Este comportamento é especialmente problemático quando as restrições políticas ou de justiça podem ser violadas.
Embora formas comuns de regularização possam resultar em extrapolações mais sensatas, os regularizadores padrão não podem garantir um comportamento razoável do modelo em todo o espaço de entrada, especialmente com entradas de alta dimensão. Mudar para modelos mais simples com comportamento mais controlado e previsível pode ter um custo severo para a precisão do modelo.
O TF Lattice torna possível continuar usando modelos flexíveis, mas oferece várias opções para injetar conhecimento de domínio no processo de aprendizagem por meio de senso comum semanticamente significativo ou restrições de forma orientadas por políticas:
- Monotonicidade : você pode especificar que a saída só deve aumentar/diminuir em relação a uma entrada. Em nosso exemplo, você pode querer especificar que o aumento da distância até uma cafeteria deve apenas diminuir a preferência prevista do usuário.
Convexidade/Concavidade : Você pode especificar que a forma da função pode ser convexa ou côncava. Misturado à monotonicidade, isso pode forçar a função a representar retornos decrescentes em relação a um determinado recurso.
Unimodalidade : você pode especificar que a função deve ter um pico ou vale único. Isso permite representar funções que possuem um ponto ideal em relação a um recurso.
Confiança em pares : esta restrição funciona em um par de recursos e sugere que um recurso de entrada reflete semanticamente a confiança em outro recurso. Por exemplo, um número maior de avaliações deixa você mais confiante na classificação média por estrelas de um restaurante. O modelo será mais sensível em relação à classificação por estrelas (ou seja, terá uma inclinação maior em relação à classificação) quando o número de avaliações for maior.
Flexibilidade controlada com regularizadores
Além das restrições de forma, a estrutura do TensorFlow fornece vários regularizadores para controlar a flexibilidade e suavidade da função para cada camada.
Regularizador Laplaciano : As saídas dos vértices/pontos-chave da rede/calibração são regularizadas em relação aos valores de seus respectivos vizinhos. Isso resulta em uma função mais plana .
Regularizador Hessiano : Penaliza a primeira derivada da camada de calibração PWL para tornar a função mais linear .
Regularizador de rugas : Penaliza a segunda derivada da camada de calibração PWL para evitar mudanças repentinas na curvatura. Isso torna a função mais suave.
Regularizador de Torção : As saídas da rede serão regularizadas para evitar torção entre os recursos. Em outras palavras, o modelo será regularizado no sentido da independência entre as contribuições dos recursos.
Misture e combine com outras camadas Keras
Você pode usar camadas TF Lattice em combinação com outras camadas Keras para construir modelos parcialmente restritos ou regularizados. Por exemplo, camadas de calibração de rede ou PWL podem ser usadas na última camada de redes mais profundas que incluem incorporações ou outras camadas Keras.
Artigos
- Ética Deontológica por Restrições de Forma de Monotonicidade , Serena Wang, Maya Gupta, Conferência Internacional sobre Inteligência Artificial e Estatística (AISTATS), 2020
- Restrições de forma para funções de conjunto , Andrew Cotter, Maya Gupta, H. Jiang, Erez Louidor, Jim Muller, Taman Narayan, Serena Wang, Tao Zhu. Conferência Internacional sobre Aprendizado de Máquina (ICML), 2019
- Restrições de forma de retornos decrescentes para interpretabilidade e regularização , Maya Gupta, Dara Bahri, Andrew Cotter, Kevin Canini, Advances in Neural Information Processing Systems (NeurIPS), 2018
- Redes de rede profunda e funções monotônicas parciais , Seungil You, Kevin Canini, David Ding, Jan Pfeifer, Maya R. Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2017
- Funções monotônicas rápidas e flexíveis com conjuntos de redes , Mahdi Milani Fard, Kevin Canini, Andrew Cotter, Jan Pfeifer, Maya Gupta, Advances in Neural Information Processing Systems (NeurIPS), 2016
- Tabelas de consulta interpoladas calibradas monotônicas , Maya Gupta, Andrew Cotter, Jan Pfeifer, Konstantin Voevodski, Kevin Canini, Alexander Mangylov, Wojciech Moczydlowski, Alexander van Esbroeck, Journal of Machine Learning Research (JMLR), 2016
- Regressão otimizada para avaliação eficiente de funções , Eric Garcia, Raman Arora, Maya R. Gupta, IEEE Transactions on Image Processing, 2012
- Regressão em rede , Eric Garcia, Maya Gupta, Avanços em sistemas de processamento de informações neurais (NeurIPS), 2009
Tutoriais e documentos de API
Para arquiteturas de modelos comuns, você pode usar modelos pré-fabricados Keras . Você também pode criar modelos personalizados usando camadas TF Lattice Keras ou misturar e combinar com outras camadas Keras. Confira a documentação completa da API para obter detalhes.