| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
סקירה כללית
אחד האתגרים הגדולים ביותר בזיהוי דיבור אוטומטי הוא הכנה והגדלה של נתוני אודיו. ניתוח נתוני אודיו יכול להיות בתחום זמן או תדירות, מה שמוסיף מורכבות נוספת בהשוואה למקורות נתונים אחרים כגון תמונות.
כחלק האקולוגי TensorFlow, tensorflow-io חבילה מספקת APIs שימושי למדי כמה קשור שמע כי עוזר להקל על הכנת הגדלת נתון אודיו.
להכין
התקן את החבילות הנדרשות והפעל מחדש את זמן הריצה
pip install tensorflow-io
נוֹהָג
קרא קובץ שמע
בשנת TensorFlow IO, בכיתה tfio.audio.AudioIOTensor מאפשר לך לקרוא קובץ אודיו לתוך עצלן טעון IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
בדוגמה לעיל, קובץ Flac brooklyn.flac הוא מ- קליפ אודיו נגיש לציבור Google Cloud .
כתוב GCS gs://cloud-samples-tests/speech/brooklyn.flac משמש במישרין בגלל GCS היא מערכת קבצים נתמכת ב TensorFlow. בנוסף Flac פורמט, WAV , Ogg , MP3 , ו MP4A נתמכים גם על ידי AudioIOTensor עם זיהוי פורמט קובץ אוטומטי.
AudioIOTensor הוא עצלן טעון כל כך רק לעצב, dtype, ואת קצב דגימה מוצגים בתחילה. הצורה של AudioIOTensor מיוצגת [samples, channels] , מה שאומר קליפ אודיו שטען מונו ערוץ עם 28979 דגימות ב int16 .
התוכן של קליפ אודיו יקראו רק לפי הצורך, בין אם על ידי המרת AudioIOTensor כדי Tensor דרך to_tensor() , או על פי חיתוך. חיתוך שימושי במיוחד כאשר יש צורך רק בחלק קטן מקטע שמע גדול:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
ניתן להשמיע את האודיו באמצעות:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
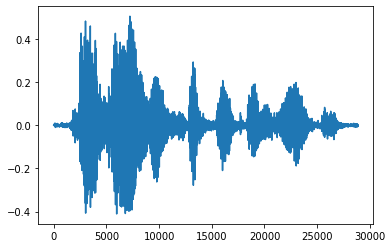
זה יותר נוח להמיר טנזור למספרי צפים ולהראות את קטע האודיו בגרף:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
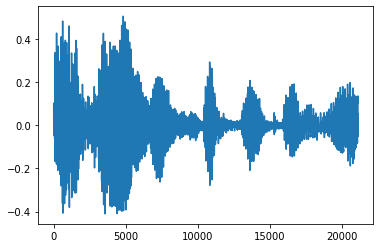
חתוך את הרעש
לפעמים זה הגיוני לקצץ את הרעש מן אודיו, אשר יכול להיעשות באמצעות API tfio.audio.trim . חזר מן API הוא זוג [start, stop] עמדת segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
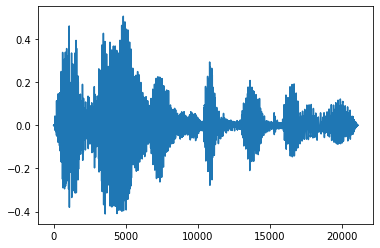
Fade In ו Fade Out
טכניקת הנדסת שמע שימושית אחת היא דהייה, אשר מגדילה או מקטינה בהדרגה את אותות השמע. ניתן לעשות זאת באמצעות tfio.audio.fade . tfio.audio.fade תומך צורות שונות של דוהה כגון linear , logarithmic , או exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
ספקטרוגרם
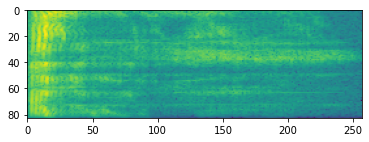
עיבוד אודיו מתקדם עובד לרוב על שינויים בתדרים לאורך זמן. בשנת tensorflow-io צורת גל ניתן להמיר ספקטרוגרמה דרך tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
טרנספורמציה נוספת לסולמות שונים אפשרית גם היא:
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
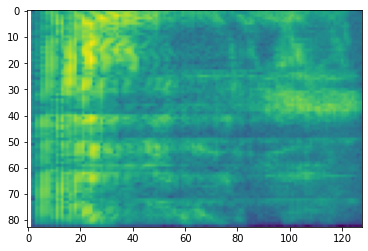
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
SpecAugment
בנוסף לומר לעיל הכנת נתונים שהוזכרה ו- APIs הגדלה, tensorflow-io חבילה מספקת גם augmentations ספקטרוגרמה מתקדם, תדירות בראש ובראשונה זו ושעת המיסוך שנדון SpecAugment: (. פרק ואח, 2019) שיטת הגדלת נתונים פשוט עבור זיהוי דיבור אוטומטי .
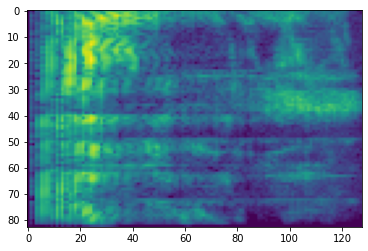
מיסוך תדרים
בשנת מיסוך תדרים, ערוצי תדר [f0, f0 + f) הם רעולי פנים שבו f נבחר מתוך התפלגות אחידה בין 0 ל המסכה תדירות פרמטר F , ו f0 נבחר מן (0, ν − f) שבו ν הוא מספר ערוצי תדר.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
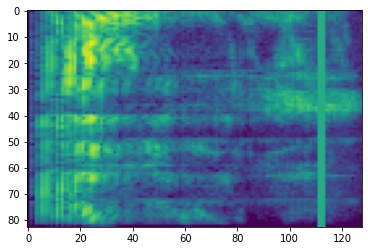
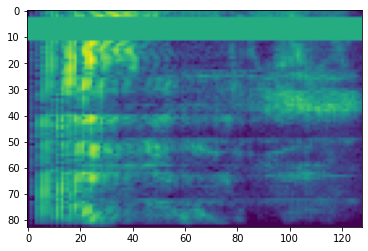
מסיכת זמן
בשנת מיסוך זמן, t צעדים זמן רצופים [t0, t0 + t) מחופשים שבו t נבחר מתוך התפלגות אחידה בין 0 ל המסכה זמן פרמטר T , ו t0 נבחר מ [0, τ − t) שבו τ הוא צעדי זמן.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>