| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
স্বয়ংক্রিয় স্পিচ রিকগনিশনের সবচেয়ে বড় চ্যালেঞ্জগুলির মধ্যে একটি হল অডিও ডেটা তৈরি এবং বৃদ্ধি করা। অডিও ডেটা বিশ্লেষণ সময় বা ফ্রিকোয়েন্সি ডোমেনে হতে পারে, যা চিত্রের মতো অন্যান্য ডেটা উত্সের তুলনায় অতিরিক্ত জটিল যোগ করে।
TensorFlow বাস্তুতন্ত্রের একটি অংশ হিসেবে tensorflow-io প্যাকেজ বেশ কিছু দরকারী অডিও সংক্রান্ত API গুলি সাহায্য করে প্রস্তুতি এবং অডিও তথ্য বৃদ্ধি টুকটাক প্রদান করে।
সেটআপ
প্রয়োজনীয় প্যাকেজ ইনস্টল করুন এবং রানটাইম পুনরায় চালু করুন
pip install tensorflow-io
ব্যবহার
একটি অডিও ফাইল পড়ুন
TensorFlow আই সালে, বর্গ tfio.audio.AudioIOTensor আপনি একটি অলস লোড মধ্যে একটি অডিও ফাইল পড়ার অনুমতি দেয় IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
উপরের উদাহরণে, Flac ফাইল brooklyn.flac একটি সর্বজনীনভাবে অ্যাক্সেসযোগ্য অডিও ক্লিপ থেকে Google মেঘ ।
GCS ঠিকানা gs://cloud-samples-tests/speech/brooklyn.flac সরাসরি ব্যবহার করা হয় কারণ GCS TensorFlow একটি সমর্থিত ফাইলের সিস্টেম। ছাড়াও Flac ফরম্যাট, WAV , Ogg , MP3 , এবং MP4A এছাড়াও দ্বারা সমর্থিত AudioIOTensor স্বয়ংক্রিয় ফাইল ফরম্যাট সনাক্তকরণ সঙ্গে।
AudioIOTensor অলস লোড তাই শুধুমাত্র আকৃতি, dtype, এবং নমুনা হার প্রাথমিকভাবে দেখানো হয়। আকৃতি AudioIOTensor হিসাবে প্রতিনিধিত্ব করা হয় [samples, channels] , যার মানে অডিও ক্লিপ আপনি লোড সঙ্গে মনো চ্যানেল 28979 নমুনা int16 ।
অডিও ক্লিপ বিষয়বস্তুর শুধুমাত্র হিসাবে প্রয়োজন পড়তে হবে, হয় রূপান্তর দ্বারা AudioIOTensor করার Tensor মাধ্যমে to_tensor() অথবা slicing যদিও। স্লাইসিং বিশেষত উপযোগী যখন একটি বড় অডিও ক্লিপের একটি ছোট অংশের প্রয়োজন হয়:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
অডিওটি এর মাধ্যমে চালানো যেতে পারে:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
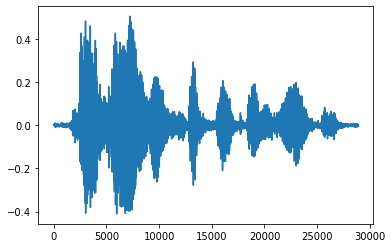
টেনসরকে ফ্লোট নম্বরে রূপান্তর করা এবং গ্রাফে অডিও ক্লিপ দেখানো আরও সুবিধাজনক:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
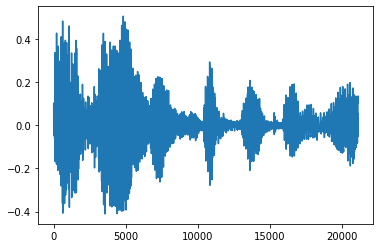
শব্দ ছাঁটা
কখনও কখনও এটি অডিও, যা API এর মাধ্যমে প্রয়োগ করা যেতে পারে থেকে গোলমাল ছাঁটা ইন্দ্রিয় তোলে tfio.audio.trim । API থেকে ফিরল একজোড়া হয় [start, stop] segement অবস্থান:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
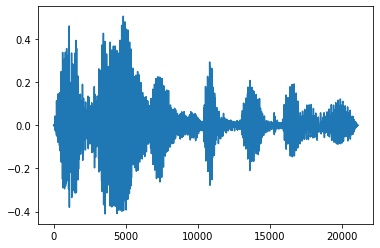
ফেইড ইন এবং ফেড আউট
একটি দরকারী অডিও ইঞ্জিনিয়ারিং কৌশল হল বিবর্ণ, যা ধীরে ধীরে অডিও সংকেত বাড়ায় বা হ্রাস করে। এই মাধ্যমে এটি করা যাবে tfio.audio.fade । tfio.audio.fade যেমন ঝরে পড়ে বিভিন্ন আকার সমর্থন linear , logarithmic , অথবা exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
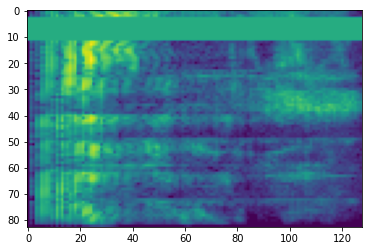
স্পেকট্রোগ্রাম
উন্নত অডিও প্রক্রিয়াকরণ প্রায়ই সময়ের সাথে ফ্রিকোয়েন্সি পরিবর্তনের উপর কাজ করে। ইন tensorflow-io তরঙ্গাকৃতি মাধ্যমে বর্ণালির আলোকক চিত্র বা রেখা চিত্র কাজে রূপান্তরিত হতে পারে tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
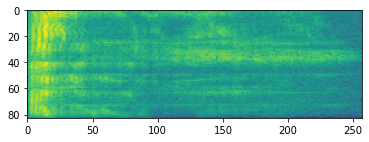
বিভিন্ন স্কেলে অতিরিক্ত রূপান্তরও সম্ভব:
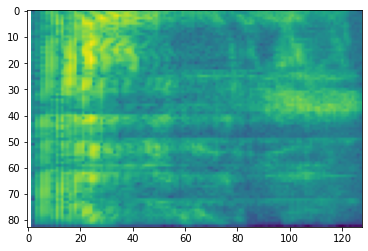
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
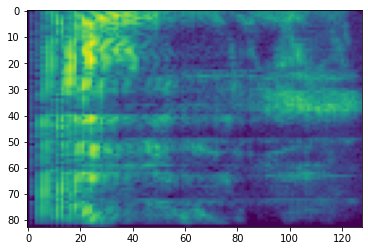
SpecAugment
উল্লিখিত তথ্য প্রস্তুতি এবং বৃদ্ধি API গুলি উপরে ছাড়াও tensorflow-io প্যাকেজ উন্নত বর্ণালির আলোকক চিত্র বা রেখা চিত্র বর্দ্ধকসমূহের মধ্যে উল্লেখযোগ্য ফ্রিকোয়েন্সি প্রদান করে এবং সময় কাচ আলোচনা SpecAugment: (। পার্ক এট, 2019) স্বয়ংক্রিয় বিবৃতি শনাক্ত করার জন্য একটি সহজ ডেটা বর্ধক পদ্ধতি ।
ফ্রিকোয়েন্সি মাস্কিং
ফ্রিকোয়েন্সি মাস্কিং, পৌনঃপুনিকতা চ্যানেলে [f0, f0 + f) ছদ্মবেশী হয় যেখানে f থেকে একটি অভিন্ন বিতরণ থেকে নির্বাচিত 0 ফ্রিকোয়েন্সি মাস্ক পরামিতির F , এবং f0 থেকে নির্বাচিত (0, ν − f) যেখানে ν সংখ্যা ফ্রিকোয়েন্সি চ্যানেল।
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
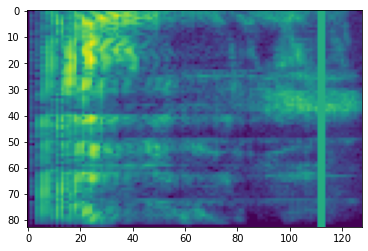
সময় মাস্কিং
সময় মাস্কিং সালে t পরপর সময় পদক্ষেপ [t0, t0 + t) ছদ্মবেশী হয় যেখানে t থেকে একটি অভিন্ন বিতরণ থেকে নির্বাচিত 0 প্যারামিটার সময় মাস্ক থেকে T , এবং t0 থেকে নির্বাচিত [0, τ − t) যেখানে τ হয় সময় পদক্ষেপ
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>