| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Panoramica
Una delle maggiori sfide nel riconoscimento vocale automatico è la preparazione e l'aumento dei dati audio. L'analisi dei dati audio potrebbe essere nel dominio del tempo o della frequenza, il che aggiunge ulteriore complessità rispetto ad altre fonti di dati come le immagini.
Come parte dell'ecosistema tensorflow, tensorflow-io pacchetto fornisce un bel paio di API relative all'audio utili che aiuta allentamento la preparazione e l'aumento dei dati audio.
Impostare
Installa i pacchetti richiesti e riavvia il runtime
pip install tensorflow-io
Utilizzo
Leggi un file audio
In tensorflow IO, classe tfio.audio.AudioIOTensor consente di leggere un file audio in un pigro-caricato IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
Nell'esempio di cui sopra, il file Flac brooklyn.flac è da un clip audio accessibile al pubblico in Google Cloud .
L'indirizzo GCS gs://cloud-samples-tests/speech/brooklyn.flac sono utilizzati direttamente a causa GCS è un file system supportato in tensorflow. Oltre a Flac formato, WAV , Ogg , MP3 , e MP4A sono supportati anche da AudioIOTensor con rilevazione automatica formato di file.
AudioIOTensor è pigro-caricato così solo modellare, dtype e frequenza di campionamento sono presenti inizialmente. La forma della AudioIOTensor è rappresentato come [samples, channels] , cioè la clip audio caricata sia mono canale 28979 campioni in int16 .
Il contenuto della clip audio sarà letto solo quando necessario, o convertendo AudioIOTensor a Tensor attraverso to_tensor() , o attraverso affettare. Lo Slicing è particolarmente utile quando è necessaria solo una piccola porzione di una clip audio di grandi dimensioni:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
L'audio può essere riprodotto tramite:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
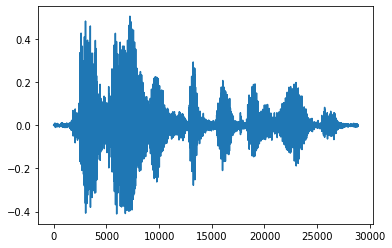
È più conveniente convertire il tensore in numeri float e mostrare la clip audio nel grafico:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
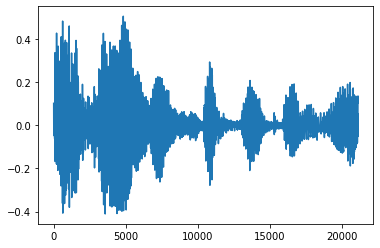
Taglia il rumore
A volte ha senso per tagliare il rumore dal audio, che potrebbe essere fatto attraverso API tfio.audio.trim . Restituito dall'API è una coppia di [start, stop] posizione del segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
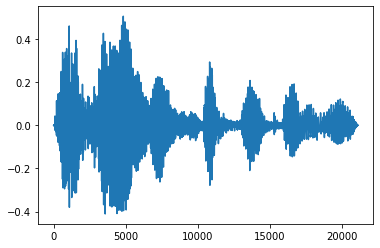
Dissolvenza in entrata e in chiusura
Un'utile tecnica di ingegneria audio è la dissolvenza, che aumenta o diminuisce gradualmente i segnali audio. Questo può essere fatto attraverso tfio.audio.fade . tfio.audio.fade supporta diverse forme di dissolvenze come linear , logarithmic o exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
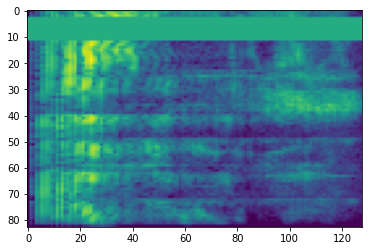
Spettrogramma
L'elaborazione audio avanzata spesso funziona sulle variazioni di frequenza nel tempo. In tensorflow-io una forma d'onda può essere convertito in spettrogramma attraverso tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
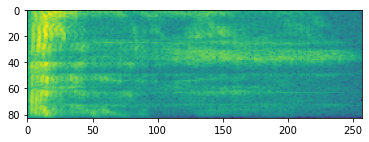
Sono inoltre possibili ulteriori trasformazioni a diverse scale:
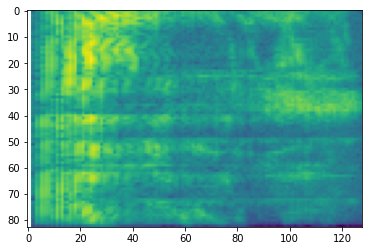
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
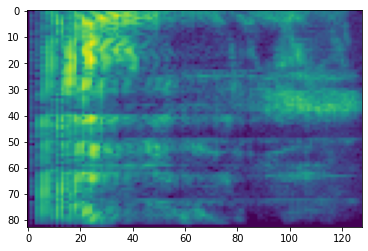
SpecAugment
In aggiunta a quanto sopra API di preparazione dei dati e di aumento citate, tensorflow-io pacchetto fornisce anche potenziamenti spettrogramma avanzati, in particolare tempo e frequenza Masking discusso in SpecAugment: (. Parco et al, 2019) Un metodo semplice dei dati di incremento per il riconoscimento vocale automatico .
Mascheramento di frequenza
Nel mascheramento frequenza, canali di frequenza [f0, f0 + f) sono mascherati dove f è scelto da una distribuzione uniforme da 0 alla maschera frequenza parametro F , e f0 è scelto tra (0, ν − f) dove ν è il numero di canali di frequenza.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
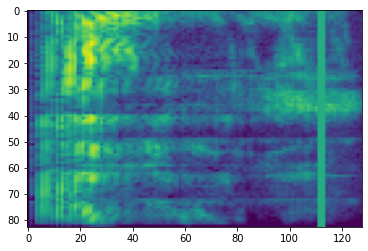
Mascheramento del tempo
In tempo di mascheratura, t fasi temporali consecutivi [t0, t0 + t) sono mascherati dove t è scelto da una distribuzione uniforme da 0 alla maschera parametro tempo T , e t0 è scelto tra [0, τ − t) dove τ è il passi temporali.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>