| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
Một trong những bí quyết lớn nhất trong Nhận dạng giọng nói tự động là chuẩn bị và tăng cường dữ liệu âm thanh. Phân tích dữ liệu âm thanh có thể trong miền thời gian hoặc miền tần số, điều này thêm phức tạp hơn so với các nguồn dữ liệu khác như hình ảnh.
Là một phần của hệ sinh thái TensorFlow, tensorflow-io gói cung cấp khá nhiều các API âm thanh hữu ích liên quan mà giúp giảm bớt việc chuẩn bị và tăng thêm của dữ liệu âm thanh.
Thành lập
Cài đặt các Gói cần thiết và khởi động lại thời gian chạy
pip install tensorflow-io
Cách sử dụng
Đọc tệp âm thanh
Trong TensorFlow IO, lớp tfio.audio.AudioIOTensor cho phép bạn đọc một tập tin âm thanh vào một lười biếng-nạp IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
Trong ví dụ trên, file Flac brooklyn.flac là từ một clip âm thanh truy cập công khai trong google đám mây .
Địa chỉ GCS gs://cloud-samples-tests/speech/brooklyn.flac được sử dụng trực tiếp vì GCS là một hệ thống tập tin được hỗ trợ trong TensorFlow. Ngoài Flac định dạng, WAV , Ogg , MP3 , và MP4A cũng được hỗ trợ bởi AudioIOTensor với tự động phát hiện định dạng tập tin.
AudioIOTensor là lười biếng-nạp nên chỉ định hình, dtype, và tỷ lệ mẫu được hiển thị ban đầu. Hình dạng của AudioIOTensor được biểu diễn dưới dạng [samples, channels] , có nghĩa là các clip âm thanh bạn nạp là mono kênh với 28979 mẫu trong int16 .
Nội dung của clip âm thanh sẽ chỉ được đọc khi cần thiết, hoặc bằng cách chuyển đổi AudioIOTensor để Tensor qua to_tensor() , hoặc mặc dù cắt. Tính năng Slicing đặc biệt hữu ích khi chỉ cần một phần nhỏ của đoạn âm thanh lớn:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
Âm thanh có thể được phát qua:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
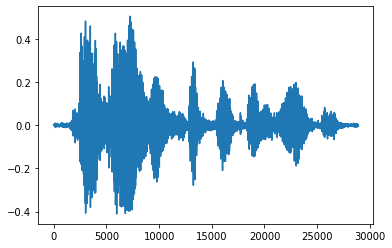
Sẽ thuận tiện hơn khi chuyển đổi tensor thành số thực và hiển thị đoạn âm thanh trong biểu đồ:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
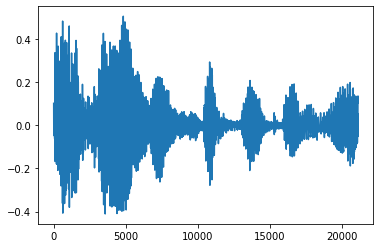
Loại bỏ tiếng ồn
Đôi khi nó làm cho tinh thần để cắt tiếng ồn từ âm thanh, có thể được thực hiện thông qua API tfio.audio.trim . Trở về từ API là một cặp [start, stop] vị trí của segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
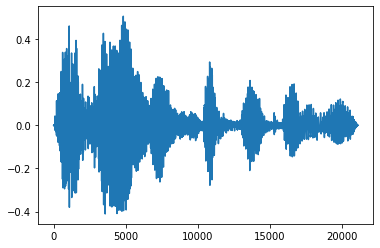
Fade In và Fade Out
Một kỹ thuật kỹ thuật âm thanh hữu ích là làm mờ dần, làm tăng hoặc giảm dần tín hiệu âm thanh. Điều này có thể được thực hiện thông qua tfio.audio.fade . tfio.audio.fade hỗ trợ hình dạng khác nhau của fades như linear , logarithmic , hoặc exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
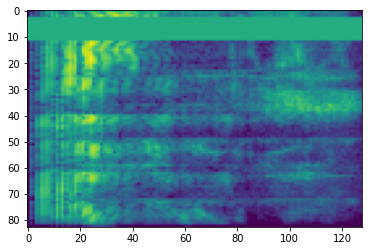
Quang phổ
Xử lý âm thanh nâng cao thường hoạt động trên sự thay đổi tần số theo thời gian. Trong tensorflow-io một dạng sóng có thể được chuyển đổi sang ảnh phổ thông qua tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
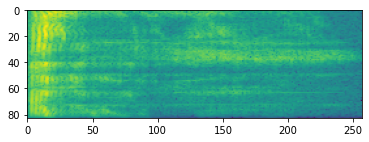
Chuyển đổi bổ sung sang các quy mô khác nhau cũng có thể:
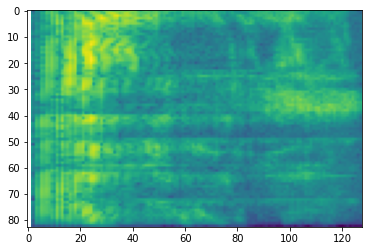
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
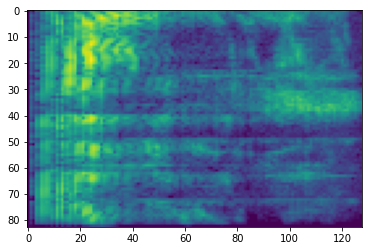
SpecAugment
Ngoài việc trên các API chuẩn bị dữ liệu và tăng thêm đã đề cập, tensorflow-io gói cũng cung cấp augmentations ảnh phổ tiên tiến, đáng chú ý nhất Frequency và Time Masking thảo luận trong SpecAugment: (. Vườn et al, 2019) Một đơn giản Phương pháp dữ liệu Augmentation cho Speech Recognition tự động .
Mặt nạ tần số
Trong mặt nạ tần, kênh tần số [f0, f0 + f) được đeo mặt nạ nơi f được chọn từ một phân bố đều từ 0 đến mặt nạ tần số tham số F , và f0 được chọn từ (0, ν − f) nơi ν là số các kênh tần số.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
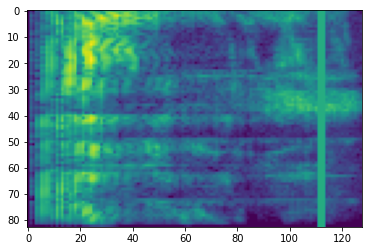
Mặt nạ thời gian
Trong thời gian mặt nạ, t bước thời gian liên tiếp [t0, t0 + t) được đeo mặt nạ nơi t được chọn từ một phân bố đều từ 0 đến mặt nạ thời gian tham số T , và t0 được chọn từ [0, τ − t) nơi τ là các bước thời gian.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>