| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ภาพรวม
หนึ่งในความท้าทายที่ใหญ่ที่สุดในการรู้จำเสียงอัตโนมัติคือการเตรียมและเพิ่มข้อมูลเสียง การวิเคราะห์ข้อมูลเสียงอาจอยู่ในโดเมนเวลาหรือความถี่ ซึ่งเพิ่มความซับซ้อนเพิ่มเติมเมื่อเปรียบเทียบกับแหล่งข้อมูลอื่นๆ เช่น รูปภาพ
ในฐานะที่เป็นส่วนหนึ่งของระบบนิเวศ TensorFlow ให้ tensorflow-io แพคเกจให้ค่อนข้าง APIs ที่เกี่ยวข้องกับเสียงไม่กี่ที่มีประโยชน์ที่ช่วยบรรเทาการเตรียมและการเพิ่มขึ้นของข้อมูลเสียง
ติดตั้ง
ติดตั้งแพ็คเกจที่จำเป็น และรีสตาร์ทรันไทม์
pip install tensorflow-io
การใช้งาน
อ่านไฟล์เสียง
ใน TensorFlow IO ชั้น tfio.audio.AudioIOTensor ช่วยให้คุณอ่านไฟล์เสียงเป็นขี้เกียจโหลด IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
ในตัวอย่างข้างต้น Flac ไฟล์ brooklyn.flac มาจากคลิปเสียงที่สาธารณชนสามารถเข้าถึงใน Google Cloud
ที่อยู่ GCS gs://cloud-samples-tests/speech/brooklyn.flac ถูกนำมาใช้โดยตรงเพราะ GCS เป็นระบบไฟล์ที่สนับสนุนใน TensorFlow นอกจากนี้ในการ Flac รูปแบบ WAV , Ogg , MP3 และ MP4A ได้รับการสนับสนุนโดย AudioIOTensor มีการตรวจสอบรูปแบบไฟล์อัตโนมัติ
AudioIOTensor เป็นคนขี้เกียจโหลดเพื่อให้รูปร่างเท่านั้น dtype และอัตราตัวอย่างมีการแสดงครั้งแรก รูปร่างของ AudioIOTensor จะแสดงเป็น [samples, channels] ซึ่งหมายความว่าคลิปเสียงที่คุณโหลดเป็นช่องทางขาวดำที่มี 28979 ตัวอย่างใน int16
เนื้อหาของคลิปเสียงเท่านั้นที่จะสามารถอ่านได้ตามต้องการไม่ว่าจะโดยการแปลง AudioIOTensor เพื่อ Tensor ผ่าน to_tensor() หรือแม้หั่น การแบ่งส่วนมีประโยชน์อย่างยิ่งเมื่อต้องการเพียงส่วนเล็ก ๆ ของคลิปเสียงขนาดใหญ่เท่านั้น:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
สามารถเล่นเสียงผ่าน:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
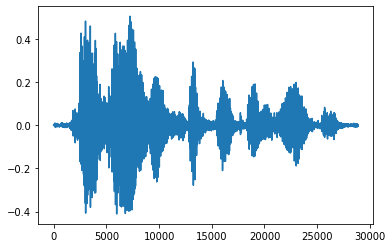
จะสะดวกกว่าในการแปลงเทนเซอร์เป็นจำนวนทศนิยมและแสดงคลิปเสียงในกราฟ:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
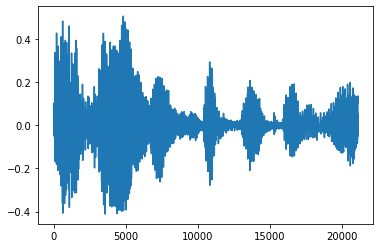
ตัดเสียงรบกวน
บางครั้งก็ทำให้รู้สึกถึงการตัดเสียงรบกวนจากเสียงซึ่งสามารถทำได้ผ่าน API ได้ tfio.audio.trim กลับมาจาก API เป็นคู่ [start, stop] ตำแหน่งของ segement นี้:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
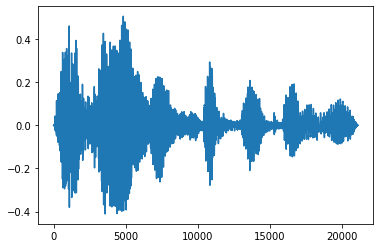
เฟดอินและเฟดออก
เทคนิคทางวิศวกรรมเสียงที่มีประโยชน์อย่างหนึ่งคือการจาง ซึ่งจะค่อยๆ เพิ่มหรือลดสัญญาณเสียง ซึ่งสามารถทำได้ผ่าน tfio.audio.fade tfio.audio.fade สนับสนุนรูปทรงที่แตกต่างกันของจางหายไปเช่น linear , logarithmic หรือ exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
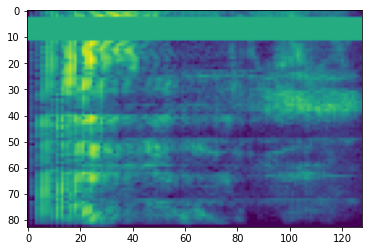
สเปกโตรแกรม
การประมวลผลเสียงขั้นสูงมักจะทำงานกับการเปลี่ยนแปลงความถี่เมื่อเวลาผ่านไป ใน tensorflow-io รูปคลื่นสามารถแปลง spectrogram ผ่าน tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
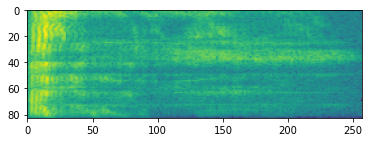
นอกจากนี้ยังสามารถแปลงเพิ่มเติมเป็นเครื่องชั่งต่างๆ ได้:
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
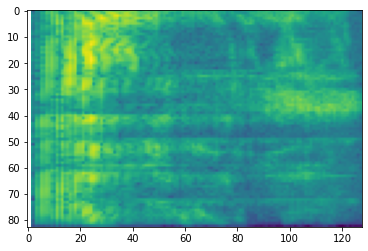
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
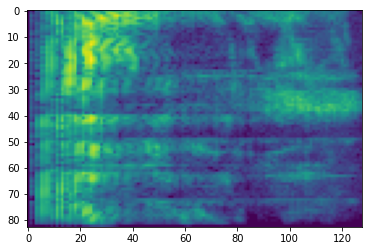
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
SpecAugment
นอกจากนี้ยังมีข้อมูลดังกล่าวข้างต้นที่กล่าวถึงการเตรียมการและการเสริม APIs, tensorflow-io แพคเกจยังให้ augmentations spectrogram ขั้นสูงสะดุดตาที่สุดความถี่และเวลากาวที่กล่าวไว้ใน SpecAugment: วิธีการที่ง่ายข้อมูลเสริมสำหรับการรู้จำเสียงอัตโนมัติ (. พาร์ค, et al, 2019)
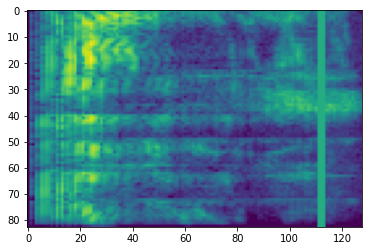
การกำบังความถี่
ในกำบังความถี่ช่องความถี่ [f0, f0 + f) จะสวมหน้ากากที่ f ถูกเลือกจากเครื่องแบบกระจายจาก 0 ไปยังหน้ากากความถี่พารามิเตอร์ F และ f0 ถูกเลือกจาก (0, ν − f) ที่ ν คือจำนวนของ ช่องความถี่
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
การกำบังเวลา
ในกำบังเวลา t ขั้นตอนเวลาติดต่อกัน [t0, t0 + t) จะสวมหน้ากากที่ t ได้รับการแต่งตั้งจากเครื่องแบบกระจายจาก 0 ไปยังหน้ากากเวลาพารามิเตอร์ T และ t0 ถูกเลือกจาก [0, τ − t) ที่ τ คือ ขั้นตอนเวลา
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>