| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
Обзор
Одной из самых больших проблем автоматического распознавания речи является подготовка и дополнение аудиоданных. Анализ аудиоданных может быть во временной или частотной области, что добавляет дополнительные сложности по сравнению с другими источниками данных, такими как изображения.
В рамках TensorFlow экосистемы, tensorflow-io пакет предоставляет несколько полезного API , аудио , связанное что помогает замедлениям подготовки и увеличению аудиоданных.
Настраивать
Установите необходимые пакеты и перезапустите среду выполнения.
pip install tensorflow-io
использование
Прочитать аудиофайл
В TensorFlow IO, класс tfio.audio.AudioIOTensor позволяет считывать аудиофайл в ленивый загруженном IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
В приведенном выше примере, файл Flac brooklyn.flac от общедоступного аудиоклипа в Google Cloud .
ГКС адрес gs://cloud-samples-tests/speech/brooklyn.flac используется непосредственно , потому что ГКС является поддерживаемой файловой системой в TensorFlow. В дополнение к Flac формате WAV , Ogg , MP3 и MP4A также поддерживаются AudioIOTensor с автоматическим распознаванием формата файла.
AudioIOTensor ленив загружены так , только форму, DTYPE, а частота дискретизации показаны на начальном этапе. Форма AudioIOTensor представлена в виде [samples, channels] , что означает аудио клип вы загрузили моно канал с 28979 выборок в int16 .
Содержание аудиоклипа будет прочитано только по мере необходимости, либо путем преобразования AudioIOTensor в Tensor через to_tensor() , или хотя нарезки. Нарезка особенно полезна, когда требуется только небольшая часть большого аудиоклипа:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
Звук можно воспроизводить через:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
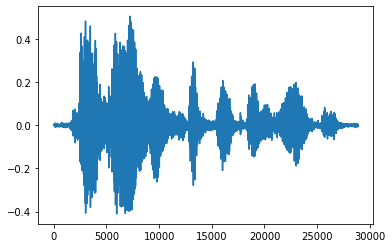
Удобнее преобразовать тензор в число с плавающей запятой и отобразить аудиоклип на графике:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
Убрать шум
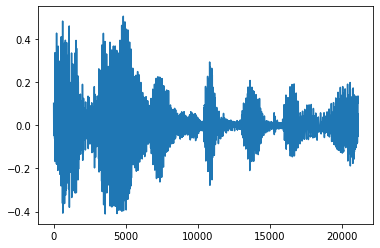
Иногда имеет смысл обрезать шум от звука, который может быть сделан через API tfio.audio.trim . Возвращенные из API является пара [start, stop] позиции segement:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
Постепенное появление и исчезновение
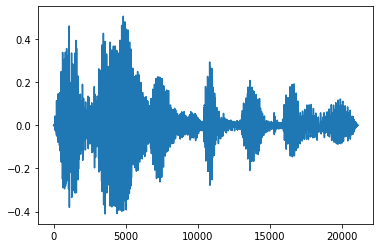
Одним из полезных приемов звукоинженерии является затухание, которое постепенно увеличивает или уменьшает звуковые сигналы. Это может быть сделано через tfio.audio.fade . tfio.audio.fade поддерживает различные формы фации , такие как linear , logarithmic или exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
Спектрограмма
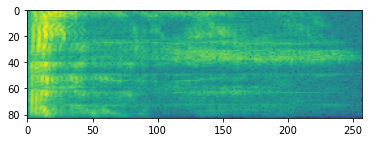
Усовершенствованная обработка звука часто работает при изменении частоты с течением времени. В tensorflow-io формы волны могут быть преобразованы в спектрограмме через tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
Также возможно дополнительное преобразование в разные масштабы:
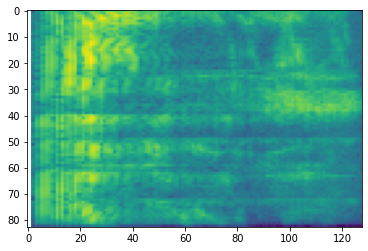
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
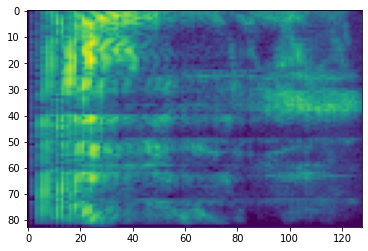
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
SpecAugment
В дополнение к вышеупомянутым API , подготовки данных и дополнения, tensorflow-io пакет также предоставляет расширенные спектрограммы аугментации, наиболее особенно частоты и времени Маскировка обсуждается в SpecAugment: (. Парк и др, 2019) Простой Augmentation данных Метод для автоматического распознавания речи .
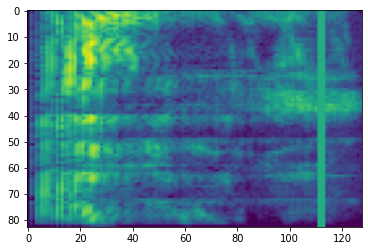
Маскировка частоты
В частотном маскирования, частотные каналы [f0, f0 + f) замаскированы , где f выбран из равномерного распределения от 0 к маске частотного параметра F и f0 выбирается из (0, ν − f) , где ν представляет собой число частотные каналы.
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
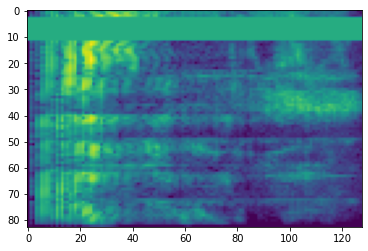
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
Маскировка времени
В время маскирования, t последовательных шагов по времени [t0, t0 + t) замаскированы , где t выбран из равномерного распределения от 0 до времени маски параметра T и t0 выбираются из [0, τ − t) , где τ представляет собой временные шаги.
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>