| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
अवलोकन
स्वचालित वाक् पहचान में सबसे बड़ी चुनौतियों में से एक ऑडियो डेटा की तैयारी और वृद्धि है। ऑडियो डेटा विश्लेषण समय या आवृत्ति डोमेन में हो सकता है, जो छवियों जैसे अन्य डेटा स्रोतों की तुलना में अतिरिक्त जटिल जोड़ता है।
TensorFlow पारिस्थितिकी तंत्र का एक हिस्सा के रूप में, tensorflow-io पैकेज काफी कुछ उपयोगी ऑडियो से संबंधित एपीआई में मदद करता है कि तैयारी और ऑडियो डेटा की वृद्धि को कम करती है।
सेट अप
आवश्यक पैकेज स्थापित करें, और रनटाइम को पुनरारंभ करें
pip install tensorflow-io
प्रयोग
एक ऑडियो फ़ाइल पढ़ें
TensorFlow आईओ में, वर्ग tfio.audio.AudioIOTensor आप एक आलसी-लोडेड में एक ऑडियो फ़ाइल को पढ़ने के लिए अनुमति देता है IOTensor :
import tensorflow as tf
import tensorflow_io as tfio
audio = tfio.audio.AudioIOTensor('gs://cloud-samples-tests/speech/brooklyn.flac')
print(audio)
<AudioIOTensor: shape=[28979 1], dtype=<dtype: 'int16'>, rate=16000>
उपरोक्त उदाहरण में, Flac फ़ाइल brooklyn.flac में एक सार्वजनिक रूप से सुलभ ऑडियो क्लिप से है google क्लाउड ।
GCS पता gs://cloud-samples-tests/speech/brooklyn.flac सीधे उपयोग किया जाता है क्योंकि GCS TensorFlow में समर्थित फ़ाइल प्रणाली है। के अलावा Flac प्रारूप, WAV , Ogg , MP3 , और MP4A भी द्वारा समर्थित हैं AudioIOTensor स्वत: फ़ाइल स्वरूप का पता लगाने के साथ।
AudioIOTensor आलसी-लोडेड इसलिए केवल आकार, dtype है, और नमूना दर शुरू में दिखाए जाते हैं। के आकार AudioIOTensor के रूप में प्रस्तुत किया जाता है [samples, channels] , जिसका अर्थ है ऑडियो क्लिप आप लोड के साथ मोनो चैनल है 28979 में नमूने int16 ।
ऑडियो क्लिप की सामग्री के रूप में ही की जरूरत पढ़ा जाएगा, या तो परिवर्तित करके AudioIOTensor को Tensor के माध्यम से to_tensor() या टुकड़ा करने की क्रिया है, हालांकि। स्लाइसिंग विशेष रूप से तब उपयोगी होती है जब एक बड़े ऑडियो क्लिप के केवल एक छोटे हिस्से की आवश्यकता होती है:
audio_slice = audio[100:]
# remove last dimension
audio_tensor = tf.squeeze(audio_slice, axis=[-1])
print(audio_tensor)
tf.Tensor([16 39 66 ... 56 81 83], shape=(28879,), dtype=int16)
ऑडियो के माध्यम से चलाया जा सकता है:
from IPython.display import Audio
Audio(audio_tensor.numpy(), rate=audio.rate.numpy())
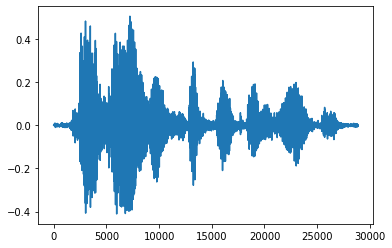
टेंसर को फ्लोट नंबरों में बदलना और ग्राफ़ में ऑडियो क्लिप दिखाना अधिक सुविधाजनक है:
import matplotlib.pyplot as plt
tensor = tf.cast(audio_tensor, tf.float32) / 32768.0
plt.figure()
plt.plot(tensor.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd3eb72d0>]
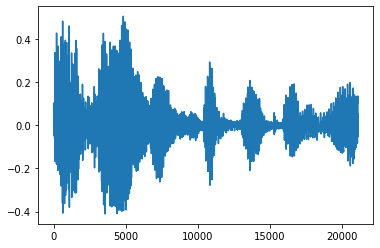
शोर ट्रिम करें
कभी कभी यह ऑडियो, जो एपीआई के माध्यम से किया जा सकता है से शोर ट्रिम करने के लिए समझ में आता है tfio.audio.trim । एपीआई से लौटे की एक जोड़ी है [start, stop] segement की स्थिति:
position = tfio.audio.trim(tensor, axis=0, epsilon=0.1)
print(position)
start = position[0]
stop = position[1]
print(start, stop)
processed = tensor[start:stop]
plt.figure()
plt.plot(processed.numpy())
tf.Tensor([ 2398 23546], shape=(2,), dtype=int64) tf.Tensor(2398, shape=(), dtype=int64) tf.Tensor(23546, shape=(), dtype=int64) [<matplotlib.lines.Line2D at 0x7fbdd3dce9d0>]
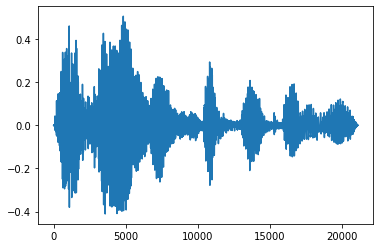
फेड इन और फेड आउट
एक उपयोगी ऑडियो इंजीनियरिंग तकनीक फीका है, जो धीरे-धीरे ऑडियो सिग्नल को बढ़ाती या घटाती है। इस के माध्यम से किया जा सकता है tfio.audio.fade । tfio.audio.fade जैसे fades की अलग अलग आकार का समर्थन करता है linear , logarithmic , या exponential :
fade = tfio.audio.fade(
processed, fade_in=1000, fade_out=2000, mode="logarithmic")
plt.figure()
plt.plot(fade.numpy())
[<matplotlib.lines.Line2D at 0x7fbdd00d9b10>]
spectrogram
उन्नत ऑडियो प्रोसेसिंग अक्सर समय के साथ आवृत्ति परिवर्तनों पर काम करती है। में tensorflow-io एक तरंग के माध्यम से spectrogram में बदला जा सकता tfio.audio.spectrogram :
# Convert to spectrogram
spectrogram = tfio.audio.spectrogram(
fade, nfft=512, window=512, stride=256)
plt.figure()
plt.imshow(tf.math.log(spectrogram).numpy())
<matplotlib.image.AxesImage at 0x7fbdd005add0>
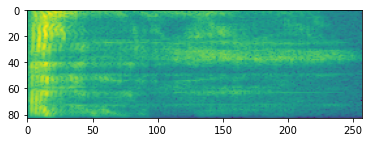
विभिन्न पैमानों पर अतिरिक्त परिवर्तन भी संभव है:
# Convert to mel-spectrogram
mel_spectrogram = tfio.audio.melscale(
spectrogram, rate=16000, mels=128, fmin=0, fmax=8000)
plt.figure()
plt.imshow(tf.math.log(mel_spectrogram).numpy())
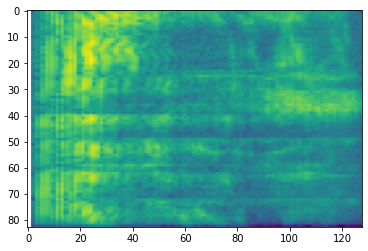
# Convert to db scale mel-spectrogram
dbscale_mel_spectrogram = tfio.audio.dbscale(
mel_spectrogram, top_db=80)
plt.figure()
plt.imshow(dbscale_mel_spectrogram.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb20bd10>
विशेष वृद्धि
उल्लेख डेटा तैयार करने और वृद्धि एपीआई से ऊपर, के अलावा tensorflow-io पैकेज भी उन्नत spectrogram augmentations, सबसे विशेष रूप से आवृत्ति प्रदान करता है और समय मास्किंग में चर्चा SpecAugment: (। पार्क एट अल, 2019) स्वचालित वाक् पहचान के लिए एक सरल डाटा विस्तार विधि ।
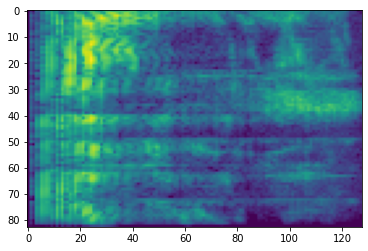
आवृत्ति मास्किंग
आवृत्ति मास्किंग, आवृत्ति चैनलों में [f0, f0 + f) से छुपाया जाता है जहां f से एक समान वितरण से चुना जाता है 0 आवृत्ति मुखौटा पैरामीटर के लिए F , और f0 से चुना जाता है (0, ν − f) जहां ν की संख्या है आवृत्ति चैनल।
# Freq masking
freq_mask = tfio.audio.freq_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(freq_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb155cd0>
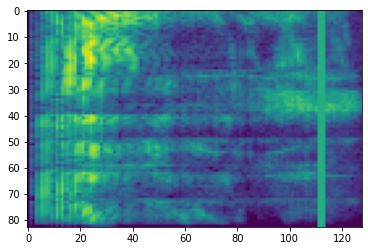
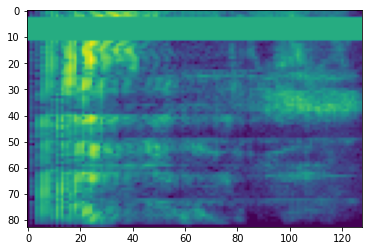
टाइम मास्किंग
समय मास्किंग में, t लगातार समय चरणों [t0, t0 + t) से छुपाया जाता है जहां t से एक समान वितरण से चुना जाता है 0 पैरामीटर समय मुखौटा करने के लिए T , और t0 से चुना जाता है [0, τ − t) जहां τ है समय कदम।
# Time masking
time_mask = tfio.audio.time_mask(dbscale_mel_spectrogram, param=10)
plt.figure()
plt.imshow(time_mask.numpy())
<matplotlib.image.AxesImage at 0x7fbcfb0d9bd0>